
5 月 28 日,浪潮信息发布“源 2.0-M32”开源大模型。“源 2.0-M32”在基于“源 2.0”系列大模型已有工作基础上,创新性地提出和采用了“基于注意力机制的门控网络”技术,构建包含 32 个专家(Expert)的混合专家模型(MoE),并大幅提升了模型算力效率,模型运行时激活参数为 37 亿,在业界主流基准评测中性能全面对标 700 亿参数的 LLaMA3 开源大模型。
大模型技术解读
在算法层面,源 2.0-M32 提出并采用了一种新型的算法结构:基于注意力机制的门控网络(Attention Router),针对 MoE 模型核心的专家调度策略,这种新的算法结构关注专家模型之间的协同性度量,有效解决传统门控网络下,选择两个或多个专家参与计算时关联性缺失的问题,使得专家之间协同处理数据的水平大为提升。源 2.0-M32 采用源 2.0-2B 为基础模型设计,沿用并融合局部过滤增强的注意力机制(LFA, Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确,进而提升了模型精度。
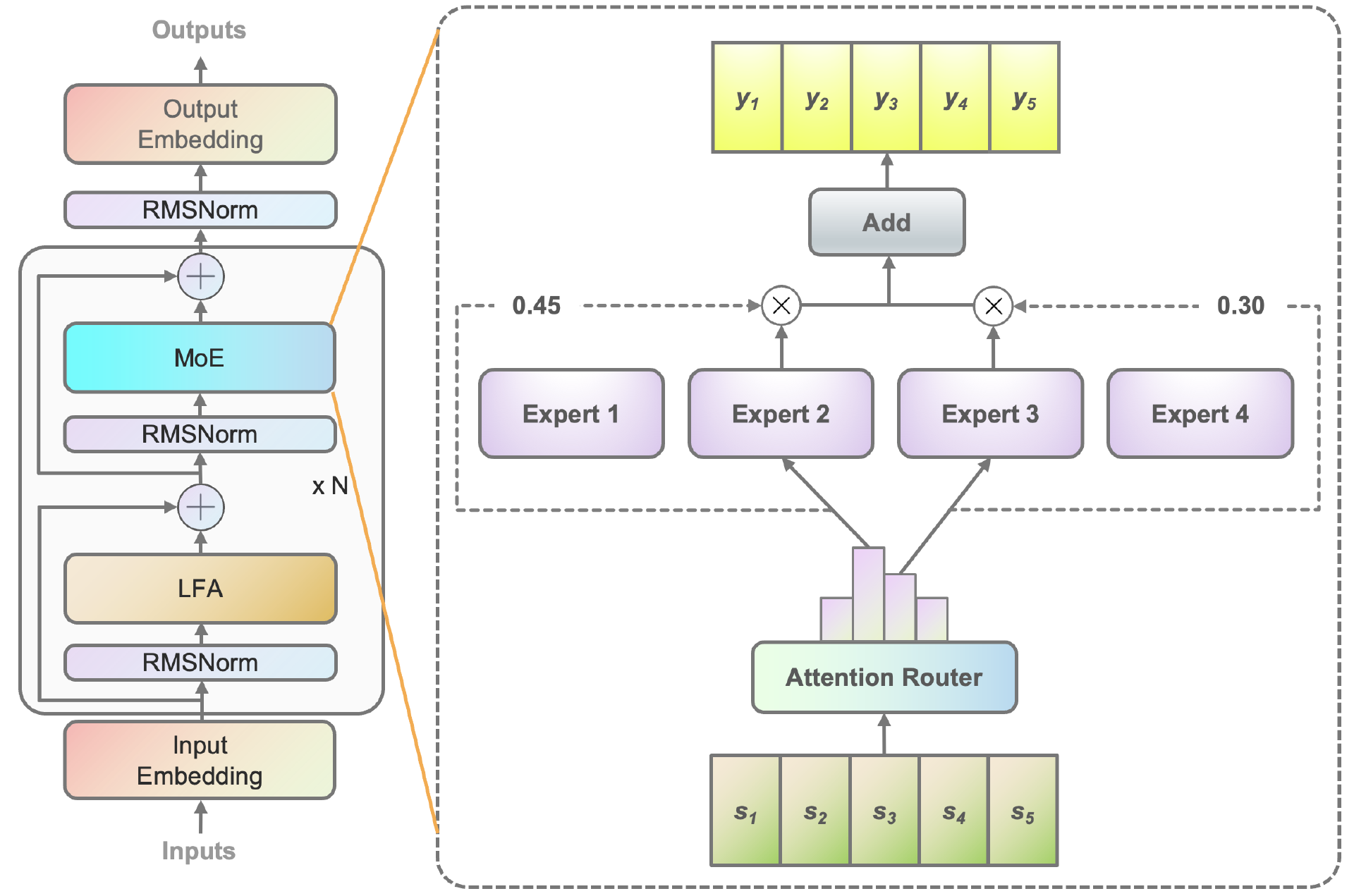
Figure1- 基于注意力机制的门控网络(Attention Router)
在数据层面,源 2.0-M32 基于 2 万亿的 token 进行训练、覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。大幅扩展代码数据占比至 47.5%,从 6 类最流行的代码扩充至 619 类,并通过对代码中英文注释的翻译,将中文代码数据量增大至 1800 亿 token。结合高效的数据清洗流程,满足大模型训练“丰富性、全面性、高质量”的数据集需求。基于这些数据的整合和扩展,源 2.0-M32 在代码生成、代码理解、代码推理、数学求解等方面有着出色的表现。
在算力层面,源 2.0-M32 采用了流水并行的方法,综合运用流水线并行+数据并行的策略,显著降低了大模型对芯片间 P2P 带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。针对 MoE 模型的稀疏专家计算,采用合并矩阵乘法的方法,模算效率得到大幅提升。
基于在算法、数据和算力方面全面创新,源 2.0-M32 的性能得以大幅提升,在多个业界主流的评测任务中,展示出了较为先进的能力表现,在 MATH(数学竞赛)、ARC-C(科学推理)榜单上超越了拥有 700 亿参数的 LLaMA3 大模型。
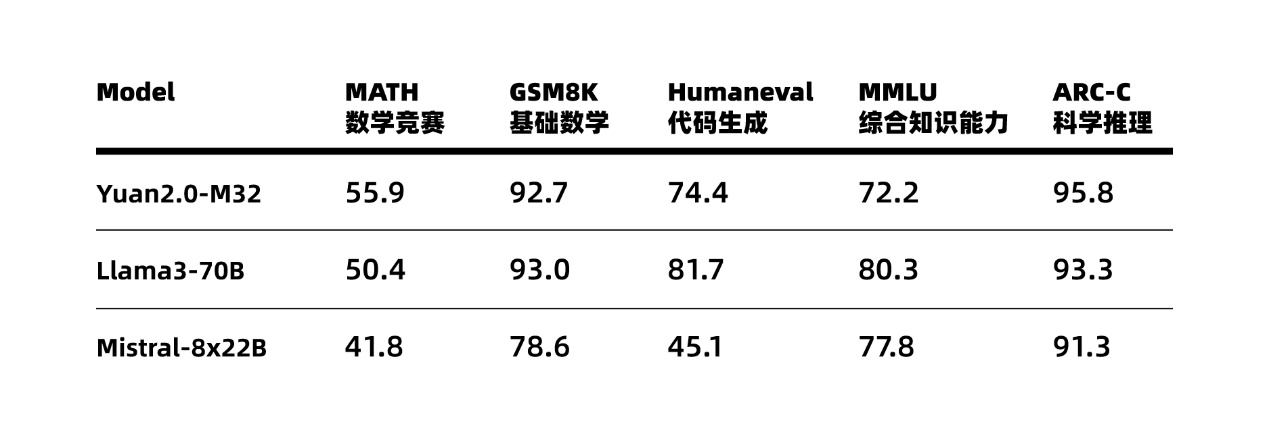
Figure2 源 2.0-M32 业界主流评测任务表现
源 2.0-M32 大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。在模型推理运行阶段,M32 处理每 token 所需算力为 7.4GFLOPs,而 LLaMA3-70B 所需算力为 140GFLOPs。在模型微调训练阶段,对 1 万条平均长度为 1024 token 的样本进行全量微调,M32 消耗算力约 0.0026PD(PetaFLOPs/s-day),而 LLaMA3 消耗算力约为 0.05PD。M32 凭借特别优化设计的模型架构,在仅激活 37 亿参数的情况下,取得了和 700 亿参数 LLaMA3 相当的性能水平,而所消耗算力仅为 LLaMA3 的 1/19,从而实现了更高的模算效率。
浪潮信息人工智能首席科学家吴韶华表示:当前业界大模型在性能不断提升的同时,也面临着所消耗算力大幅攀升的问题,对企业落地应用大模型带来了极大的困难和挑战。源 2.0-M32 是浪潮信息在大模型领域持续耕耘的最新探索成果,通过在算法、数据、算力等方面的全面创新,M32 不仅可以提供与业界领先开源大模型相当的性能,更可以大幅降低大模型所需算力消耗。大幅提升的模算效率将为企业开发应用生成式 AI 提供模型高性能、算力低门槛的高效路径。
技术创新点剖析:
Llama 系列模型的精度从 Llama1 到 Llama3 显著提升,Llama3 的精度处于领先地位,特别是其 700 亿参数的模型在每个 Token 的推理和算力上达到 140GFLOPS。尽管如此,Llama3 在推理时的算力开销较大,也就是说单位算力下的精度表现较差。
在采访环节,吴韶华回答了记者问,关于 32 个专家的优势及挑战,吴韶华解释道,当前很多大模型工作采用 8 个专家的架构,但浪潮信息选择 32 个专家,核心原因是模算效率。实验表明,在他们的 LFA 加上 Attention Router 架构中,专家数量从 8 增加到 32 时,精度显著提升,而算力开销保持不变。这是因为激活专家的数量仅为 2 个。此外,单个专家参数量为 2B,这样控制模型参数量有利于企业应用的模算效率。结果显示,这一选择在相同精度下实现了低算力消耗。
同时,由于激活的专家数量为 2 个,通过 Attention Router 机制考虑专家间协同,专家数量的增加使得每个专家或专家组能够学习更多有针对性的信息。

模算效率与成本控制也是此次大模型发布的关键讨论点。吴韶华强调,算力是当前大模型发展的核心瓶颈。MoE 结构模型通过扩展专家数量,在固定算力下获得更高精度。在多元芯片的使用上,浪潮信息的 EPAI 软件提供相关工具,支持多元算力架构,降低用户迁移设备的难度和成本。这些创新措施有助于降低用户试错成本,实现应用落地。
高模算效率意味着在单位算力投入下获得更高的精度回报,这对于大模型训练和推理都非常有利。“源 2.0-M32”模型旨在通过创新算法提升精度并降低同等精度下的算力开销,大幅提升基础模型的模算效率。“源 2.0-M32”是一个包含 32 个专家的混合专家模型,采用了 Attention Router 结构来调度专家,实现高效计算。在模型训练和推理过程中,“源 2.0-M32”表现出色,Attention Router 结构主要是通过建模专家之间的协同关系来提升模型精度。
M32 模型的训练数据筛选与优化也是核心技术点,吴韶华详细介绍了浪潮信息在训练数据方面的策略。浪潮信息从源 1.0 开始构建了互联网自然语言文库,并开发了一套数据清洗平台。对于稀缺数据(如中文数学数据),通过数据合成工具补充。M32 模型引入了大量代码数据和互联网数据,提升数据的多样性和质量。代码数据不仅对模型的代码能力有益,还能帮助解决数学问题和推理问题。最终,源 2.0-M32 模型在精度和算力开销方面优于 Llama3。
在应用落地方面,源 2.0-M32 增强了小样本学习能力,通过少量样本就能显著提升模型能力。相较于微调而言,这是一种轻量化支撑大模型应用落地的有效技术。
MoE 模型对企业开发应用和大模型普惠的影响也逐渐展现,吴韶华向大家介绍说,MoE 模型除了提升算力效率外,还能提高精度,降低使用成本,增强模型能力。MoE 模型通过激活少量专家,保持算力开销低,同时允许训练更多 Token,进一步提升精度。对于终端用户来说,关键在于解决实际问题和降低使用成本。例如,在智能客服等应用中,用户更愿意花费较少的钱解决具体问题,而不会购买高成本的大模型。
最后,吴韶华补充了大模型落地与微调的观点,大模型在应用落地时需要进行微调,这是由于预训练阶段的数据和模型能力存在局限性。微调能有效应对不同的行业需求,但算力需求较大。同时,推理阶段也是算力开销大户,因此高效的模型结构和更强的能力在实际应用中具有优势。浪潮信息通过内部实际应用场景,如客服、软件研发、运维等,不断积累经验,提升模型能力,满足更多用户需求。
回顾与展望:
回顾大模型的发展历史,我们可以看到,2020 年 GPT-3 的发布点燃了大模型的热潮。从 2020 年到 2022 年,业界在大模型能力上进行了广泛的探索。例如,2022 年推出了 GPT 强化学习方法,使大模型与人的意图对齐,建立了良好的发展思路。同年末,ChatGPT 问世,引发了大模型应用的热潮,成为增长最快且被广泛接受的大模型应用。此后,Llama 系列模型陆续推出,2024 年大模型的发展速度进一步加快。
浪潮信息的大模型研究始于 2020 年 GPT-3 发布后。2021 年,他们发布了第一个大模型“源 1.0”,拥有 2457 亿参数。2022 年,进行了应用落地探索,运用了检索类技术和 RAG 技术。2023 年,发布了“源 2.0”,并推出了“源 2.0-M32”混合专家结构模型。
关于大模型推广及触达用户,吴韶华介绍了浪潮信息大模型落地的两个方向:外部客户和内部需求。对外,浪潮信息通过与合作伙伴在 EPAI 平台上合作,提供开源模型支持,增强用户体验。对内,浪潮信息在多个业务场景中应用大模型,解决内部需求问题的同时积累经验,提升算法和工具性能,从而更好地服务外部客户。
未来,M32 开源大模型配合企业大模型开发平台 EPAI(Enterprise Platform of AI),将助力企业实现更快的技术迭代与高效的应用落地,为人工智能产业的发展提供坚实的底座和成长的土壤,加速产业智能化进程。
最后,吴韶华宣布,浪潮信息已在 GitHub 和 Hugging Face 上开源了代码和模型,并发表了相关论文。
源 2.0-M32 将持续采用全面开源策略,全系列模型参数和代码均可免费下载使用。
代码开源链接:https://github.com/IEIT-Yuan/Yuan2.0-M32




