
在当今快速发展的科技时代,计算能力的重要性毋庸置疑。无论是在人工智能、深度学习还是高性能计算领域,算力的强弱决定了创新的速度与效果。作为 NVIDIA 最新推出的顶级显卡,H20 以其强大的硬件配置和卓越的实际表现,吸引了众多关注。
本文将深入探讨算力的概念、评估方法,以及在现代计算任务中的应用,特别是如何利用 NVIDIA H20 显卡来最大化算力优势。我们将结合理论与实际数据,全面分析 H20 的独特价值与未来发展方向。
算力的概念与历史演进
1.1 算力的定义与基本概念
算力,或计算能力,是指计算设备在单位时间内所能完成的计算量。通常情况下,算力以每秒浮点运算次数(FLOPS)来衡量,这是浮点运算能力的标准单位。FLOPS 代表每秒能进行的浮点数运算的次数,因此 FLOPS 越高,设备的计算能力越强。
在实际应用中,计算任务的种类繁多,从科学计算到深度学习模型训练,从金融数据分析到自动驾驶系统,各类任务对算力的需求各不相同。计算能力不仅仅是一个硬件性能指标,更是决定技术可行性和应用效果的重要因素。随着科技的进步,计算任务变得越来越复杂,数据量也在不断增加,因此对高算力的需求变得日益迫切。
1.2 算力的发展历程
计算能力的发展可以追溯到计算机的早期历史。从最初的机械计算机到电子计算机,再到现代的超级计算机,计算能力的提升伴随着硬件技术的飞跃。早期的计算设备如 ENIAC,每秒只能完成几千次简单的加法运算,而今天的超级计算机每秒可以完成数千万亿次浮点运算。
随着时间的推移,计算设备从单一处理器发展到多核处理器,再到并行计算和分布式计算。尤其是在图形处理单元(GPU)领域,NVIDIA 等公司通过不断优化硬件架构,显著提升了计算能力。现代 GPU 如 H20 显卡,不仅在图形处理上表现优异,在并行计算、深度学习和科学模拟等领域也展现了强大的算力。
1.3 计算能力的重要性
计算能力是现代科技发展的基础。从物理模拟到分子建模,从图像识别到自然语言处理,强大的计算能力使得这些复杂任务得以实现。特别是在人工智能领域,深度学习模型的训练依赖于海量的数据和复杂的计算,因此对算力的要求极高。
在金融领域,高速交易系统依赖于实时的数据分析和决策,这些操作需要在微秒级别内完成,因此需要极高的计算能力。同样,在自动驾驶领域,车辆需要在短时间内处理来自多个传感器的数据,并做出驾驶决策,这也需要强大的算力支持。可以说,算力不仅是硬件性能的体现,更是推动科技进步的重要引擎。
算力的评估与衡量方法
2.1 评估算力的标准与方法
评估算力涉及多个方面,包括理论计算能力、实际执行效率和任务特定的表现。以下是几种常用的评估标准:
#1. FLOPS(每秒浮点运算次数)
FLOPS 是评估计算能力的最直接指标,它表示硬件在一秒钟内能够完成的浮点运算次数。计算能力越高,硬件处理数据和执行任务的速度就越快。FLOPS 通常分为单精度(FP32)、双精度(FP64)和混合精度(FP16、BFLOAT16 等)不同类型,根据任务的不同,使用的精度类型也会不同。
#2. 带宽(Bandwidth)
带宽指的是在单位时间内能够传输的数据量。内存带宽是决定计算设备性能的关键因素之一,尤其是在需要处理大量数据的任务中。高带宽可以有效减少数据传输的瓶颈,从而提高整体计算效率。在 GPU 计算中,带宽不仅影响数据加载的速度,也直接影响到模型训练的速度。
#3. 延迟(Latency)
延迟是指从输入数据到获得输出结果所需要的时间。低延迟有助于减少数据传输和处理过程中的等待时间,特别是在并行计算中,减少延迟可以显著提高计算效率。延迟通常是并行计算系统的瓶颈,尤其是在大规模数据处理或多 GPU 协同工作时。
#4. 能效比(Efficiency Ratio)
能效比是单位功耗下的计算能力。高能效比意味着在相同的功耗下,硬件能够提供更高的计算能力,这对于数据中心和高性能计算集群尤为重要。在实际应用中,能效比不仅影响计算成本,还影响系统的冷却和维护需求。
2.2 模型训练和推理中的算力评估
在深度学习和机器学习中,算力的评估往往与具体的任务需求挂钩。以下是几种常见的评估标准:
#1. 训练速度(Training Speed)
# 评估单位与计算方式 #
单位 :训练速度通常以每秒处理的样本数(Samples per Second, SPS)或每秒处理的 tokens 数(Tokens per Second, TPS)来衡量。
计算方式 :SPS 和 TPS 的计算方式如下:
SPS = 处理的样本总数 / 训练时间(秒)
TPS = 处理的 tokens 总数 / 训练时间(秒)
在计算过程中,样本数指的是输入数据的批次(Batch Size),而 tokens 数通常用于自然语言处理(NLP)模型的训练,指的是输入文本被分割后的最小单位(如词语或子词)。
# 重要性与实际应用 #
训练速度是衡量计算设备在模型训练过程中效率的关键指标。更高的训练速度意味着模型可以在更短的时间内处理更多的数据,从而加速模型的整体训练进程。这对于处理大型数据集或复杂模型(如深度神经网络、卷积神经网络等)尤为重要。
在实际应用中,提升训练速度有助于:
缩短模型的开发周期。
提高资源的利用率,减少计算成本。
在相同时间内进行更多实验,从而优化模型效果。
特别是在深度学习领域,使用更大的批次处理数据可以显著提高 SPS 或 TPS,而高效的硬件如 NVIDIA H20 显卡能够支持更大的批次大小和更快的数据处理,从而提升训练速度。
#2. 模型收敛性(Convergence)
# 评估单位与计算方式 #
单位 :模型收敛性没有统一的度量单位,但通常以训练轮数(Epochs)、迭代次数(Iterations),或达到某个性能指标所需的时间来衡量。
计算方式 :
收敛速度 = 目标性能指标 / 训练时间(秒)
或者使用收敛的轮数来衡量,即训练到模型性能稳定为止所需的训练轮数或迭代次数。
例如,在一个深度学习任务中,收敛速度可以通过模型达到一定的准确率或损失函数值所需的时间来表示。更少的训练轮数或迭代次数意味着更快的收敛速度。
# 重要性与实际应用 #
收敛性是衡量模型在训练过程中逐步逼近最优解的能力。算力越强,通常收敛速度越快,因为高算力设备可以支持更大的批次大小、更复杂的优化算法和更快的数据处理速度。这对于研究和开发时间有限的项目至关重要,因为加快收敛速度可以更快地得到有效的模型。
在实际应用中,收敛性与以下因素密切相关:
优化算法:如 Adam、SGD 等优化算法的选择和调整,直接影响模型的收敛速度。
批次大小:更大的批次大小通常会加快收敛速度,但需要足够的显存支持,这也是高算力设备的优势。
学习率:调整学习率可以帮助模型更快地达到收敛状态,但需要精细的调试以避免过拟合或欠拟合。
使用像 NVIDIA H20 这样具备高算力和大显存的设备,可以在保证计算精度的同时,加快模型的收敛速度。
#3. 推理速度(Inference Speed)
# 评估单位与计算方式 #
单位 :推理速度通常以每秒处理的样本数(Samples per Second, SPS)或每秒处理的 tokens 数(Tokens per Second, TPS)来衡量,类似于训练速度。
计算方式 :SPS 和 TPS 的计算方式如下:
SPS = 处理的样本总数 / 推理时间(秒)
TPS = 处理的 tokens 总数 / 推理时间(秒)
推理速度评估的是模型在实际应用中的响应时间,特别是在实时或近实时的应用中(如自动驾驶、语音识别、在线推荐系统等)。
# 重要性与实际应用 #
推理速度是决定模型在生产环境中表现的关键指标之一。特别是在需要实时处理和响应的应用中,推理速度直接影响系统的用户体验和效能。
推理速度越快,系统的响应时间就越短,这对于以下场景尤为重要:
自动驾驶:车辆必须在极短时间内处理传感器数据并作出驾驶决策。
实时翻译与语音识别:需要在用户发出命令后迅速给出响应。
在线推荐系统:实时分析用户行为并推荐个性化内容。
NVIDIA H20 显卡在推理任务中的表现尤为出色,特别是在 FP8 低精度计算中,能够在保持高效能的同时,提供极快的推理速度。
#4. 精度与效率的平衡
# 评估单位与计算方式 #
单位 :精度通常以百分比(%)或数值(如损失值、准确率等)来表示;效率则以处理速度或能效比(FLOPS/Watt)来衡量。
计算方式 :
精度 = 模型在测试数据集上的性能指标(如准确率、F1 分数等)
效率 = 计算资源消耗 / 达到目标性能所需的时间或能量。
在深度学习中,精度和效率往往需要进行权衡。例如,高精度计算通常需要更多的计算资源和时间,而低精度计算则可以在速度和资源占用上实现更高的效率。
# 重要性与实际应用 #
在实际应用中,精度与效率的平衡是设计和部署 AI 系统时必须考虑的重要因素。虽然追求更高的精度是许多 AI 任务的目标,但在某些场景下,高精度并不是唯一的考量。例如:
边缘计算设备:受限于计算资源和能耗,可能需要在精度和效率之间做出妥协。
实时应用:如语音助手或实时翻译,更快的响应速度可能比绝对精度更重要。
低成本部署:在大规模部署中,能够以更低的成本达到“足够好”的精度,可能比追求极限精度更具现实意义。
NVIDIA H20 显卡提供了多种浮点运算模式(如 FP16、FP8),允许开发者根据任务需求选择合适的精度和效率组合。例如,在训练阶段使用 FP16 混合精度可以提高训练速度,而在推理阶段使用 FP8 可以进一步优化性能,同时保持足够的预测精度。
Part 3 NVIDIA H20 显卡的深入解析
3.1 H20 显卡的硬件架构与技术创新
NVIDIA H20 显卡基于最新的 Hopper 架构,在图形计算和并行计算领域引领了新一轮的技术革命。与前几代基于 Ampere 架构的显卡相比,H20 在多个方面进行了大幅升级。尤其是在 FP32、FP16 以及新增的 FP8 精度计算能力上,H20 展现了其在各种复杂计算任务中的卓越性能。
根据提供的图表,H20 在 FP32 单精度浮点运算中达到了 44 TFLOPS,这远高于基于 Ampere 架构的前代产品的 19.5 TFLOPS。这一提升对于需要高精度计算的任务,如媒体处理、物理模拟等,具有重大意义。
在 FP16 和 FP8 的 Tensor Core 性能上,H20 也大幅领先于前代产品。在 FP16 运算中,H20 达到了 148 TFLOPS,而在 FP8 的 8bit 浮点数据类型运算中,H20 的性能更是达到了 296 TFLOPS。这使得 H20 在处理需要大量并行计算的任务时,如深度学习模型的训练和推理,具备了极大的优势。
3.2 显存与带宽的优越性
H20 显卡配备了 96GB 的 HBM3 显存,这是当前显存配置的顶级标准。这种显存不仅在容量上远超前代产品(80GB HBM2e),在内存带宽上也达到了惊人的 4 TB/s,是前代产品带宽的近两倍。如此高的内存带宽使得 H20 显卡在处理大规模数据集和高分辨率任务时,能够更快地进行数据传输,减少处理延迟。
对于大模型训练和深度学习应用来说,显存的大小和带宽直接决定了硬件能否有效载入和处理训练数据。H20 显卡凭借其 96GB 的显存,可以轻松应对需要大批量数据的任务,同时其 4TB/s 的带宽也确保了这些数据能够快速传输到 GPU 进行处理,这对于需要高效处理数据的任务如自动驾驶、图像识别等尤为重要。
3.3 H20 的计算能力与实际表现
通过分析 H20 的计算能力图表,我们可以看到它在 FP8、FP16 等精度下的强劲表现。特别是在处理需要高效浮点运算的任务时,H20 的 Tensor Core 能够提供前所未有的计算性能。例如,在 8bit 浮点数数据类型的 FP8 精度运算中,H20 的性能达到了 296 TFLOPS,适合用于量化训练和模型推理等场景。
NVLink 互联带宽方面,H20 也进行了显著的提升。相比前代产品的 600GB/s 和 400GB/s,H20 的 NVLink 带宽高达 900GB/s。这意味着多个 H20 显卡在多卡互联时可以通过更高效的方式进行数据交换,减少了多 GPU 协同工作的延迟,从而提高了整体计算效率。
3.4 浮点运算模式的选择与 H20 的应用场景
在 NVIDIA H20 显卡中,不同的浮点运算模式为各种计算任务提供了灵活的选择。H20 显卡支持从双精度(FP64)到最新的 FP8 低精度运算模式,覆盖了从高精度科学计算到高效推理任务的广泛应用需求。
双精度运算模式(FP64):通常用于需要极高精度的科学和工程计算,如流体力学模拟、气候预测等领域。
单精度运算模式(FP32):是深度学习领域的主力,特别是在训练大型 AI 模型时,FP32 能够提供足够的精度和较高的计算效率。
半精度运算模式(FP16):近年来在深度学习加速方面获得了广泛应用,尤其是在卷积神经网络(CNN)等任务中,FP16 能够显著提高训练速度并减少显存占用。
低精度运算模式(FP8 和 INT8):随着量化技术的发展,FP8 和 INT8 在推理任务中的应用越来越多,H20 显卡的 296 TFLOPS FP8 算力使其在大规模模型推理中占据了显著优势。
3.5 不同 GPU 型号的选择:SXM、PCIe、NVLink
为了满足不同用户的需求,NVIDIA 为 H20 显卡提供了多种型号,包括 SXM、PCIe 和 NVLink。这些型号的区别在于其硬件架构和连接方式,进而决定了它们在不同应用场景中的适用性。
SXM 版:通过 SXM 模块设计,可以实现 8 块 GPU 的紧密互联,主要应用于高密度 GPU 服务器集群,如 NVIDIA 的 DGX 系统。这种设计不依赖传统的 PCIe 接口,而是通过 NVSwitch 实现更高的带宽和更低的延迟,特别适合用于超大规模 AI 训练和科学模拟任务。
PCIe 版:沿用了传统的 PCIe 接口,提供了更为灵活的部署方式。它支持与主板和 CPU 之间的直接通信,适用于传统的 GPU 服务器和通用计算任务。每两块 GPU 通过 NVLink Bridge 进行连接,虽然在带宽上不如 SXM 版,但在扩展性和兼容性上具有一定的优势。
NVLink 版:专为需要超高带宽的数据密集型任务设计。它提供了高达 7.8 TB/s 的传输带宽,适用于需要实时处理大量数据的大规模语言模型(LLM)训练任务。通过 NVLink 接口,多个 H20 显卡可以实现高速数据交换,减少计算过程中数据传输的瓶颈,提升整体计算效率。
通过结合这些不同型号的特点和应用场景,用户可以根据自己的具体需求选择最适合的 GPU 类型,从而在不同的计算任务中最大化地发挥 H20 显卡的性能优势。
Part 4 H20 在模型训练与推理中的实际应用
4.1 通过 Llama2 模型探讨 H20 的应用
为了更好地理解 H20 显卡在实际应用中的表现,我们可以借助 Llama2-70B 模型的训练和推理数据来分析其性能。根据提供的图表,H20 显卡在不同精度(FP8 和 FP16)以及不同输入输出长度下展现了卓越的计算能力。
在图表中,HGX H20 模块在处理 LLAMA2_70B 模型时,在 FP8 精度下,输入长度为 2048、输出长度为 128 的配置中,H20 的吞吐量达到了 1.2244595*A tokens/秒。而在输入长度为 128、输出长度为 2048 的配置中,FP8 精度下的吞吐量更是高达 2.0981547*B tokens/秒。这表明在高精度和复杂模型的训练和推理任务中,H20 显卡能够提供极为高效的计算性能。
相比之下,HGX A1XX 模块在相同配置下,使用 FP16 精度的表现明显不如 H20。这进一步证实了 H20 显卡在处理大规模语言模型时的优势。特别是在需要处理复杂输入输出关系的推理任务中,H20 的高带宽和 Tensor Core 的强大性能,使其能够在更短的时间内完成推理,提供更高的吞吐量。
4.2 H20 在推理任务中的独特优势
推理任务中,吞吐量和响应速度是两个关键指标。H20 显卡凭借其 FP8 精度的计算能力,在处理 LLAMA2_70B 等大规模模型时,能够提供更高的 tokens 处理速度。结合前面的数据分析,H20 在推理任务中的表现不仅仅体现在其计算能力上,还得益于其大容量的显存和超高的内存带宽,这些因素共同作用,使得 H20 能够在处理复杂推理任务时,保持高效和准确的性能输出。
通过 NVLink 的高带宽支持,多个 H20 显卡在多卡集群中可以实现高效的数据交换和协同计算,这对于需要实时处理和分析数据的任务来说,至关重要。例如,在自动驾驶系统中,H20 显卡可以通过快速处理传感器数据并作出决策,从而提高系统的安全性和反应速度。
4.3 H20 的 GEMM 性能分析
在矩阵乘法(GEMM)任务中,浮点运算性能是评估 GPU 计算能力的重要指标之一。以下是从表格中筛选出的伊迪雅 H20 在不同浮点精度下的 GEMM 性能数据,并对其进行详细分析。
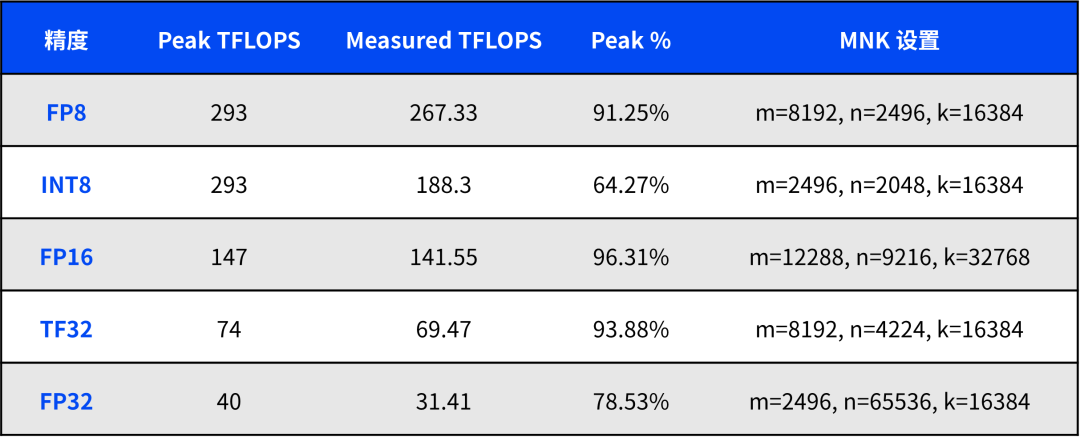
分析与解读
# FP8 精度 #
峰值性能:293 TFLOPS
实测性能:267.33 TFLOPS
峰值百分比:91.25%
FP8 精度下,伊迪雅 H20 的实测性能达到了 267.33 TFLOPS,占峰值性能的 91.25%。这一结果表明在低精度浮点运算中,伊迪雅 H20 的表现非常接近其理论最大值,表明其硬件设计在 FP8 运算任务中的效率极高,适合用于大规模模型推理和量化训练等场景。
# INT8 精度 #
峰值性能:293 TFLOPS
实测性能:188.30 TFLOPS
峰值百分比:64.27%
在 INT8 精度下,伊迪雅 H20 的实测性能为 188.30 TFLOPS,占峰值性能的 64.27%。虽然相对于 FP8 的表现有所下降,但 INT8 仍然提供了高效的计算能力。INT8 精度广泛应用于需要处理大量数据的推理任务,尤其在资源受限的环境下,可以在降低计算复杂度的同时,保持合理的精度。
# FP16 精度 #
峰值性能:147 TFLOPS
实测性能:141.55 TFLOPS
峰值百分比:96.31%
在 FP16 精度下,伊迪雅 H20 几乎达到了其峰值性能,实测值为 141.55 TFLOPS,占峰值的 96.31%。这表明伊迪雅 H20 在 FP16 运算中能够充分发挥其硬件潜力,非常适合用于深度学习训练任务,特别是卷积神经网络(CNN)和递归神经网络(RNN)等对计算速度要求较高的模型。
# TF32 精度 #
峰值性能:74 TFLOPS
实测性能:69.47 TFLOPS
峰值百分比:93.88%
TF32 是一种介于 FP16 和 FP32 之间的浮点精度模式,旨在提供比 FP32 更高的计算效率,同时保留一定的计算精度。在这一模式下,伊迪雅 H20 的实测性能为 69.47 TFLOPS,占峰值性能的 93.88%。这一表现说明 TF32 是一个平衡精度和效率的理想选择,特别是在要求较高的科学计算和 AI 模型训练中,能够显著提升计算速度。
# FP32 精度 #
峰值性能:40 TFLOPS
实测性能:31.41 TFLOPS
峰值百分比:78.53%
在 FP32 精度下,伊迪雅 H20 的实测性能为 31.41 TFLOPS,占峰值性能的 78.53%。虽然相对其他精度模式的效率稍低,但 FP32 依然是许多 AI 模型和科学计算任务的首选精度模式,特别是在需要高精度结果的场景中,FP32 的稳定表现非常重要。
H20 在不同精度下的 GEMM 性能分析,我们可以看到其在多种运算模式中的强大表现。无论是在高效推理任务中的 FP8 和 INT8,还是在深度学习训练中的 FP16 和 TF32,伊迪雅 H20 都能够提供接近其理论峰值的实际性能。这表明 H20 显卡不仅具备出色的硬件设计,还能在实际应用中充分发挥其计算能力,适合于从 AI 模型训练到大规模推理等广泛应用场景。
Part 5 NVIDIA H20 与 H100 的深入对比
5.1 H100 显卡的优势与应用场景
NVIDIA H100 显卡是目前市场上最强大的 GPU 之一,其高达 1979 TFLOP 的理论计算能力,使得 H100 在处理高精度计算任务时具备无可比拟的优势。H100 显卡的性能密度高达 19.4,远超 H20 显卡的 2.9,这使得 H100 在单位面积内能够提供更高的计算能力,特别适用于空间受限但需要高性能的计算环境。
在实际应用中,H100 显卡主要应用于高精度科学计算、复杂 AI 模型训练和大规模数据分析等领域。对于那些需要极致性能的用户,H100 显卡无疑是最佳选择。例如,在气候模拟、分子动力学和高精度物理模拟等任务中,H100 显卡可以显著加快计算速度,减少模拟时间。
5.2 H20 显卡的核心价值与独特优势
尽管 H20 显卡在理论计算能力上不如 H100,但其在实际应用中的表现依然出色。特别是在大规模低精度模型训练和推理中,H20 凭借其高显存、大带宽和较低的成本,展现了极高的性价比。对于那些需要处理大量数据且对计算精度要求不高的任务,如自然语言处理、推荐系统、图像识别等,H20 显卡是一个非常具有竞争力的选择。
H20 显卡的核心价值在于其出色的内存管理和高效的计算能力,特别是在 FP8 精度下,H20 显卡能够以更少的节点数量完成训练任务,从而降低整体计算成本。这使得 H20 显卡在一些预算敏感的项目中,成为了性价比最高的解决方案。
Part 6 H20 在工业领域的广泛应用
除了在 AI 研究中的广泛应用外,H20 显卡在工业领域也展现了巨大的应用潜力。无论是在自动驾驶、智能制造,还是金融科技和医疗健康,H20 显卡都能够通过其强大的计算能力,为各类复杂的计算任务提供解决方案。
在自动驾驶领域,H20 显卡的高带宽和低延迟使得其能够实时处理来自多个传感器的数据,并做出驾驶决策。智能制造领域的复杂工艺模拟和优化,同样可以通过 H20 显卡的高算力得到加速。而在金融科技领域,H20 显卡的快速数据处理能力可以显著提升高频交易系统的响应速度,降低市场风险。




