
近年来,随着数据科学、数据湖分析等场景的兴起,对数据读取和传输速度提出更高的要求。而 JDBC/ODBC 作为与数据库交互的主流标准,在应对大规模数据读取和传输时显得力不从心,无法满足高性能、低延迟等数据处理需求。为提供更高效的数据传输方案,Apache Doris 在 2.1 版本中基于 Arrow Flight SQL 协议实现了高速数据传输链路,使得数据传输性能实现百倍飞跃。
基于 Arrow Flight SQL 的高速数据传输链路
在 Apache Doris 中,查询结果以列存格式的 Block 组织。在之前版本中,如需将这些数据通过 MySQL Client 或 JDBC/ODBC 驱动传输至目标客户端时,需要先将 Block 序列化为行存格式的 Bytes,如果目标客户端是类似 Pandas 的列存数据科学组件或列存数据库,还需将行存格式的 Bytes 再反序列化为列存格式,而序列化/反序列化操作是一个非常耗时的过程。
在 Apache Doris 2.1 版本 中,我们基于 Arrow Flight SQL **构建了高速数据传输链路,它支持主流语言通过 SQL 从 Doris 高速读取大规模数据,极大提升了其他系统与 Apache Doris 间数据传输效率。**若目标客户端同样支持 Arrow 列存格式,整体传输过程将完全避免序列化/反序列化操作,彻底消除因此带来时间及性能损耗。此外,依赖于 Arrow Flight 多节点和多核架构特性,实现了数据传输的完全并行化,极大提高了数据吞吐能力。
以 Python 读取 Apache Doris 中数据为例,Apache Doris 先将列存的 Block 快速转换为列存的 Arrow RecordBatch,随后在 Python 客户端中,将 Arrow RecordBatch 转换为同样列存的 Pandas DataFrame 中,转换速度极快,保障了数据传输的时效性。
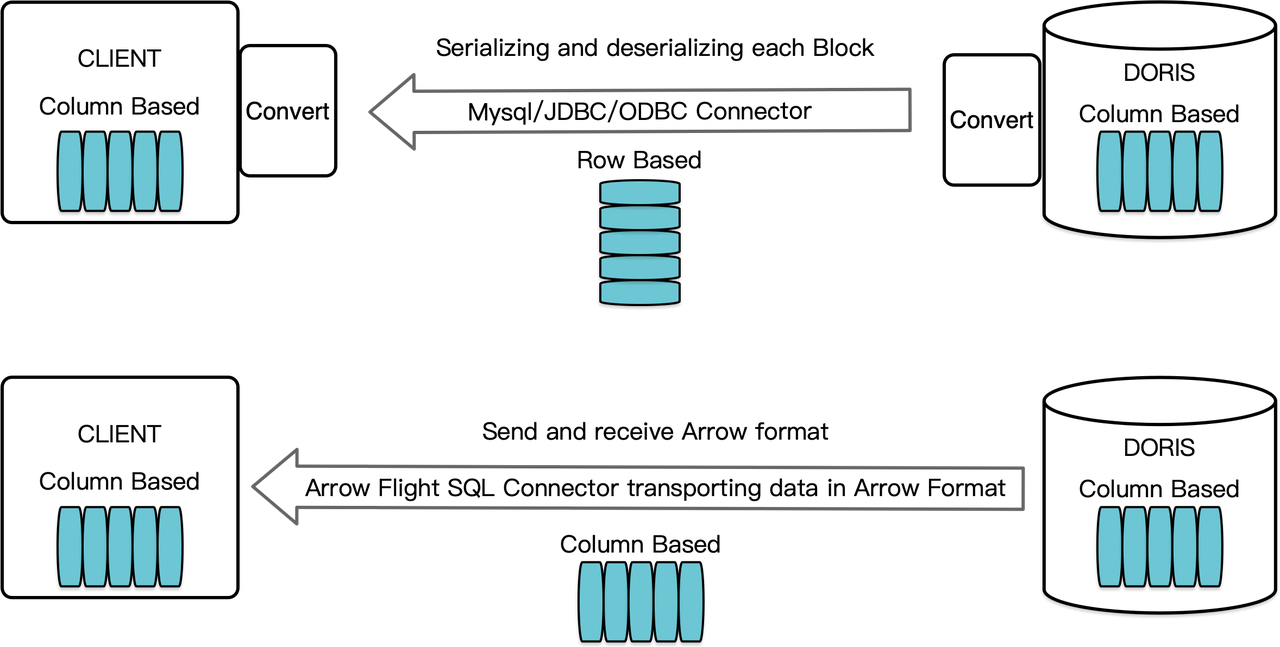
不仅如此,Arrow Flight SQL 还提供了通用的 JDBC 驱动,支持与同样遵循 Arrow Flight SQL 协议的数据库无缝交互,这不仅增强了 Apache Doris 的兼容性,还为其拓展了更广泛的应用场景。
性能测试
为了直观地展示引入 Arrow Flight SQL 后对数据传输性能的提升效果,我们特地对 Python 使用 Pymysql、Pandas 以及 Arrow Flight SQL 这三种方式读取 Apache Doris 中数据的耗时进行了对比。测试数据集如下:

分别使用 Pymysql、Pandas、Arrow Flight SQL 对不同类型数据的传输进行了测试,测试结果如下:
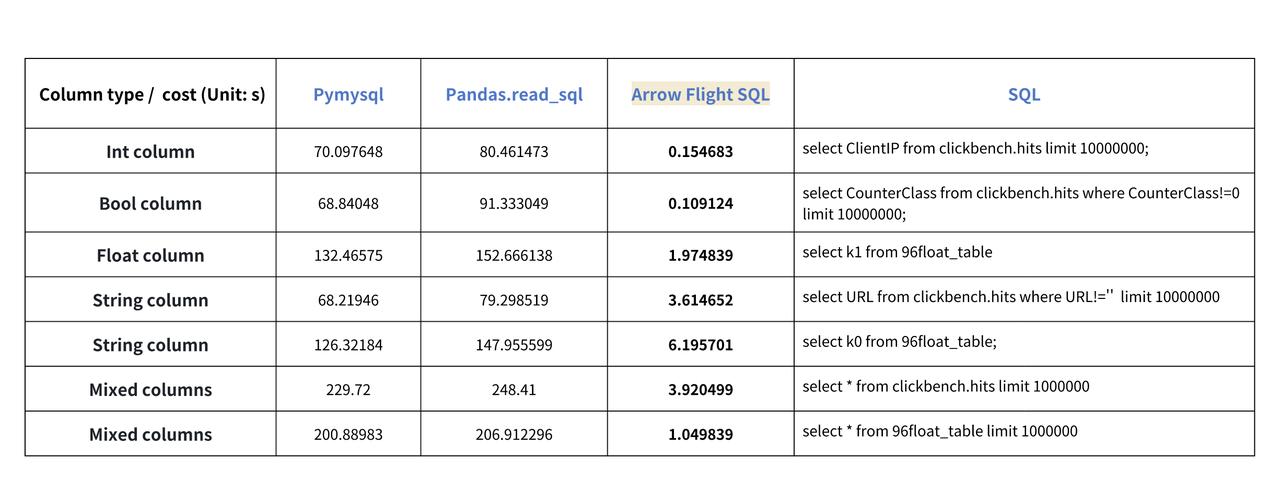
从测试结果来看,Arrow Flight SQL 在所有列类型的传输上都展现出了显著的性能优势。**在绝大多数读取场景中,Arrow Flight SQL 的性能提升超 20 倍,而在部分场景中甚至实现了百倍的性能飞跃,**为大数据处理和分析提供了强有力的保障。
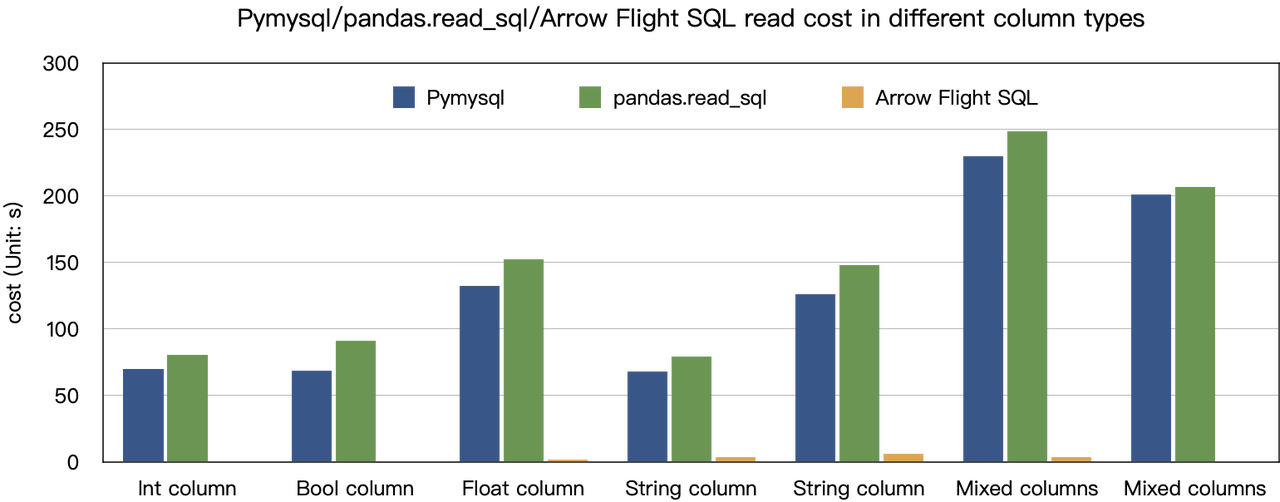
使用介绍
Apache Doris 支持 Arrow Flight SQL 后,我们得以利用 Python 的 ADBC Driver 轻松连接 Doris,实现数据的极速读取。接下来,我们将使用 Python(版本要求 >= 3.9)的 ADBC Driver 执行一系列常见的数据库语法操作,包括 DDL、DML、设置 Session 变量以及 Show 语句等。
01 安装 Library
Library 被发布在 PyPI,可通过以下方式简单安装:
pip install adbc_driver_managerpip install adbc_driver_flightsql在代码中import 以下模块/库来使用已安装的 Library:
import adbc_driver_managerimport adbc_driver_flightsql.dbapi as flight_sql02 连接 Doris
创建与 Doris Arrow Flight SQL 服务交互的客户端。需提供 Doris FE 的 Host、Arrow Flight Port 、登陆用户名以及密码,并进行以下配置。
修改 Doris FE 和 BE 的配置参数:
修改
fe/conf/fe.conf中arrow_flight_sql_port为一个可用端口,如 9090。修改
be/conf/be.conf中arrow_flight_port为一个可用端口,如 9091。
假设 Doris 实例中 FE 和 BE 的 Arrow Flight SQL 服务将分别在端口 9090 和 9091 上运行,且 Doris 用户名/密码为“user”/“pass”,那么连接过程如下所示:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={ adbc_driver_manager.DatabaseOptions.USERNAME.value: "user", adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass", })cursor = conn.cursor()连接完成后,可以通过 SQL 使返回的 Cursor 与 Doris 交互,执行例如建表、获取元数据、导入数据、查询等操作。
03 建表与获取元数据
将 Query 传递给 cursor.execute()函数,执行建表与获取元数据操作:
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")print(cursor.fetchallarrow().to_pandas())cursor.execute("create database arrow_flight_sql;")print(cursor.fetchallarrow().to_pandas())cursor.execute("show databases;")print(cursor.fetchallarrow().to_pandas())cursor.execute("use arrow_flight_sql;")print(cursor.fetchallarrow().to_pandas())cursor.execute("""CREATE TABLE arrow_flight_sql_test ( k0 INT, k1 DOUBLE, K2 varchar(32) NULL DEFAULT "" COMMENT "", k3 DECIMAL(27,9) DEFAULT "0", k4 BIGINT NULL DEFAULT '10', k5 DATE, ) DISTRIBUTED BY HASH(k5) BUCKETS 5 PROPERTIES("replication_num" = "1");""")print(cursor.fetchallarrow().to_pandas())cursor.execute("show create table arrow_flight_sql_test;")print(cursor.fetchallarrow().to_pandas())如果 StatusResult 返回 0 ,则说明 Query 执行成功(这样设计的原因是为了兼容 JDBC)。
StatusResult0 0 StatusResult0 0 Database0 __internal_schema1 arrow_flight_sql.. ...507 udf_auth_db[508 rows x 1 columns] StatusResult0 0 StatusResult0 0 Table Create Table0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...04 导入数据
执行 INSERT INTO,向所创建表中导入少量测试数据:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES ('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'), ('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'), ('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'), ('3', 4, "ID", 4, 4, '2023-10-22'), ('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")print(cursor.fetchallarrow().to_pandas())如下所示则证明导入成功:
StatusResult0 0如果需要导入大批量数据到 Doris,可以使用 pydoris 执行 Stream Load 来实现。
05 执行查询
接着对上面导入的表进行查询查询,包括聚合、排序、Set Session Variable 等操作。
cursor.execute("select * from arrow_flight_sql_test order by k0;")print(cursor.fetchallarrow().to_pandas())cursor.execute("set exec_mem_limit=2000;")print(cursor.fetchallarrow().to_pandas())cursor.execute("show variables like \"%exec_mem_limit%\";")print(cursor.fetchallarrow().to_pandas())cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")print(cursor.fetchallarrow().to_pandas())结果如下所示:
k0 k1 K2 k3 k4 k50 0 0.10000 ID 0.000100000 9999999999 2023-10-211 1 0.20000 ID_1 1.000000010 0 2023-10-212 2 3.40000 ID_1 3.100000000 123456 2023-10-223 3 4.00000 ID 4.000000000 4 2023-10-224 4 122345.54321 ID 122345.543210000 5 2023-10-22[5 rows x 6 columns] StatusResult0 0 Variable_name Value Default_Value Changed0 exec_mem_limit 2000 2147483648 1 k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_30 2023-10-22 122352.94321 3 40784.2144033331 2023-10-21 0.30000 2 0.500050005[2 rows x 5 columns]06 完整代码
# Doris Arrow Flight SQL Test# step 1, library is released on PyPI and can be easily installed.# pip install adbc_driver_manager# pip install adbc_driver_flightsqlimport adbc_driver_managerimport adbc_driver_flightsql.dbapi as flight_sql# step 2, create a client that interacts with the Doris Arrow Flight SQL service.# Modify arrow_flight_sql_port in fe/conf/fe.conf to an available port, such as 9090.# Modify arrow_flight_port in be/conf/be.conf to an available port, such as 9091.conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={ adbc_driver_manager.DatabaseOptions.USERNAME.value: "root", adbc_driver_manager.DatabaseOptions.PASSWORD.value: "", })cursor = conn.cursor()# interacting with Doris via SQL using Cursordef execute(sql): print("\n### execute query: ###\n " + sql) cursor.execute(sql) print("### result: ###") print(cursor.fetchallarrow().to_pandas())# step3, execute DDL statements, create database/table, show stmt.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")execute("show databases;")execute("create database arrow_flight_sql;")execute("show databases;")execute("use arrow_flight_sql;")execute("""CREATE TABLE arrow_flight_sql_test ( k0 INT, k1 DOUBLE, K2 varchar(32) NULL DEFAULT "" COMMENT "", k3 DECIMAL(27,9) DEFAULT "0", k4 BIGINT NULL DEFAULT '10', k5 DATE, ) DISTRIBUTED BY HASH(k5) BUCKETS 5 PROPERTIES("replication_num" = "1");""")execute("show create table arrow_flight_sql_test;")# step4, insert intoexecute("""INSERT INTO arrow_flight_sql_test VALUES ('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'), ('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'), ('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'), ('3', 4, "ID", 4, 4, '2023-10-22'), ('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")# step5, execute queries, aggregation, sort, set session variableexecute("select * from arrow_flight_sql_test order by k0;")execute("set exec_mem_limit=2000;")execute("show variables like \"%exec_mem_limit%\";")execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")# step6, close cursor cursor.close()大规模数据传输场景应用示例
01 Python
在 Python 中,通过 ADBC Driver 连接到已支持 Arrow Flight SQL 的 Doris 后,可以使用多种 ADBC API 从 Doris 加载 Clickbench 数据集到 Python。具体如下:
#!/usr/bin/env python# -*- coding: utf-8 -*-import adbc_driver_managerimport adbc_driver_flightsql.dbapi as flight_sqlimport pandasfrom datetime import datetimemy_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"my_db_kwargs = { adbc_driver_manager.DatabaseOptions.USERNAME.value: "root", adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",}sql = "select * from clickbench.hits limit 1000000;"# PEP 249 (DB-API 2.0) API wrapper for the ADBC Driver Manager.def dbapi_adbc_execute_fetchallarrow(): conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs) cursor = conn.cursor() start_time = datetime.now() cursor.execute(sql) arrow_data = cursor.fetchallarrow() dataframe = arrow_data.to_pandas() print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data))) print(dataframe.info(memory_usage='deep')) print(dataframe)# ADBC reads data into pandas dataframe, which is faster than fetchallarrow first and then to_pandas.def dbapi_adbc_execute_fetch_df(): conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs) cursor = conn.cursor() start_time = datetime.now() cursor.execute(sql) dataframe = cursor.fetch_df() print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time)) print(dataframe.info(memory_usage='deep')) print(dataframe)# Can read multiple partitions in parallel.def dbapi_adbc_execute_partitions(): conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs) cursor = conn.cursor() start_time = datetime.now() partitions, schema = cursor.adbc_execute_partitions(sql) cursor.adbc_read_partition(partitions[0]) arrow_data = cursor.fetchallarrow() dataframe = arrow_data.to_pandas() print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions))) print(dataframe.info(memory_usage='deep')) print(dataframe)dbapi_adbc_execute_fetchallarrow()dbapi_adbc_execute_fetch_df()dbapi_adbc_execute_partitions()执行结果如下(忽略重复输出),从 Doris 加载 100 万行 105 列 780M 的 Clickbench 数据集,仅用时 3s 。
################## dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000<class 'pandas.core.frame.DataFrame'>RangeIndex: 1000000 entries, 0 to 999999Columns: 105 entries, CounterID to CLIDdtypes: int16(48), int32(19), int64(6), object(32)memory usage: 2.4 GBNone CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0[1000000 rows x 105 columns]################## dbapi_adbc_execute_fetch_df, cost:0:00:03.611664################## dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1################## low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000################## low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -102 JDBC
Arrow Flight SQL 协议的开源 JDBC 驱动兼容标准的 JDBC API,可用于大多数 BI 工具通过 JDBC 访问 Doris,并支持高速传输 Apache Arrow 数据。使用方法与通过 MySQL 协议的 JDBC 驱动连接 Doris 类似,只需将链接 URL 中的jdbc:mysql 换成 jdbc:arrow-flight-sql,查询返回的结果依然是 JDBC 的 ResultSet 数据结构。
import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.Statement;Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false" + "&cachePrepStmts=true&useSSL=false&useEncryption=false";String USER = "root";String PASS = "";Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);Statement stmt = conn.createStatement();ResultSet resultSet = stmt.executeQuery("show tables;");while (resultSet.next()) { String col1 = resultSet.getString(1); System.out.println(col1);}resultSet.close();stmt.close();conn.close();03 JAVA
与 Python 类似,JAVA 也可以直接创建 ADBC Client 读取 Doris 中数据。在这过程中,首先需获取 FlightInfo,随后连接每一个 Endpoint 拉取数据。
// method oneAdbcStatement stmt = connection.createStatement()stmt.setSqlQuery("SELECT * FROM " + tableName)// executeQuery, two steps:// 1. Execute Query and get returned FlightInfo;// 2. Create FlightInfoReader to sequentially traverse each Endpoint;QueryResult queryResult = stmt.executeQuery()// method twoAdbcStatement stmt = connection.createStatement()stmt.setSqlQuery("SELECT * FROM " + tableName)// Execute Query and parse each Endpoint in FlightInfo, and use the Location and Ticket to construct a PartitionDescriptorpartitionResult = stmt.executePartitioned();partitionResult.getPartitionDescriptors()//Create ArrowReader for each PartitionDescriptor to read dataArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))04 Spark
对于 Spark,除了可以通过 JDBC 和 JAVA 方式连接 Flight SQL Server 外,还可以使用开源的 Spark-Flight-Connector ,该组件支持 Spark 作为 Client 读写 Flight SQL Server。其原因是 Arrow 数据格式与 Doris 中的 Block 数据格式的转换速度非常快,**相较于 CSV 与 Block 格式之间的转换,其速度提升了 10 倍之多,**并且 Arrow 数据格式对 Map、Array 等复杂类型的支持也更加出色。
结束语
目前,已有多家社区企业用户验证并使用 Arrow Flight SQL 从 Doris 加载数据到 Python、Spark、Flink,测试结果说明,该方式的读取速度相较于以往有了显著的提升。未来,Apache Doris 计划支持 Arrow Flight SQL 写入,届时由主流编程语言构建的系统均可借助 ADBC 客户端来读写 Doris,实现高速的数据交互;并计划利用 Arrow Flight 的并行化能力实现多 BE 并行读取,还可以借助 Arrow Flight SQL 实现 Doris 和 Doris、 Spark 和 Doris 之间的联邦查询。




