
近日,第 2024 届 ECCV 联合举办的 AIM Workshop 大赛公布比赛结果,在视频显著性预测赛道上,火山引擎多媒体实验室凭借自研的显著性检测算法获得冠军,技术能力达到行业领先水平。
大赛背景

AIM (Advances in Image Manipulation) 2024 是新兴的计算机视觉国际竞赛,每年在模式识别和机器视觉顶级国际会议 ECCV 上举行。该比赛旨在鼓励学者和研究人员探索计算机视觉中图像分析、增强和恢复的新技术和方法,并且促进学术交流,在计算机视觉领域获得了广泛的关注和参与,吸引了众多高校和业界知名公司参加。
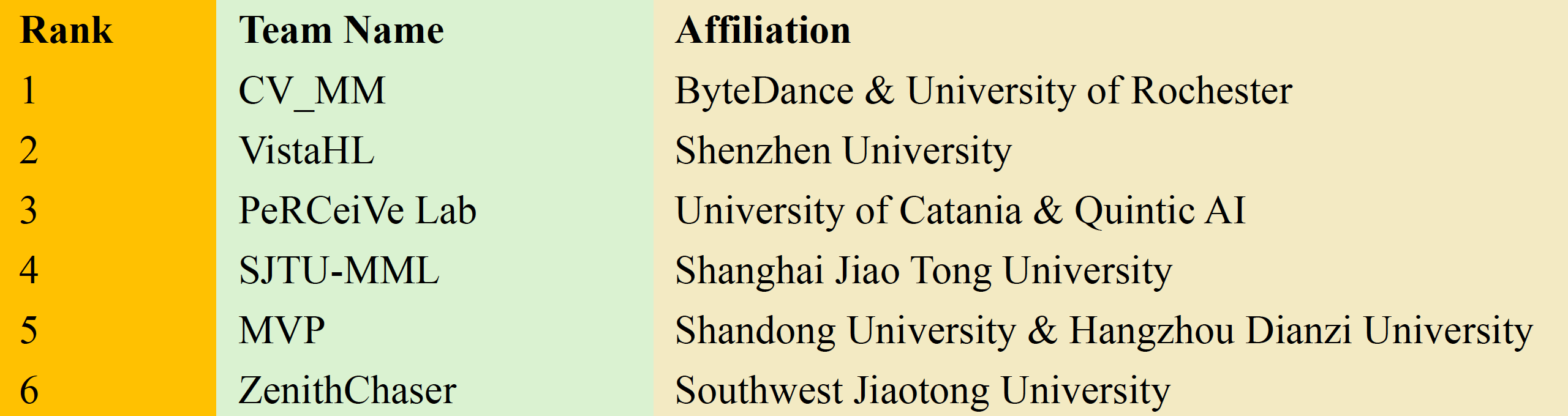
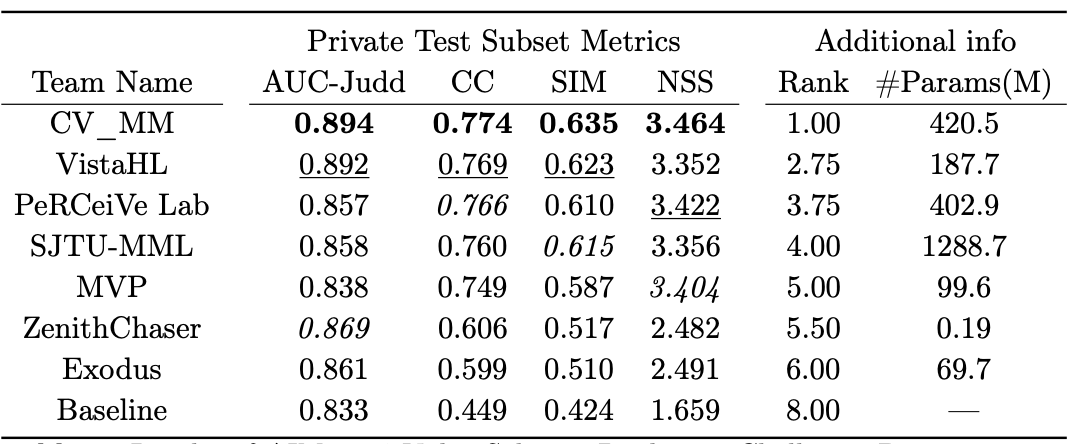
显著性预测任务旨在模拟人类视觉系统,预测图片/视频中人眼关注的区域,为下游各类计算机视觉任务提供引导和辅助信息。视频显著性预测赛道要求参赛者基于 1500 个视频 87w 帧共超过 4000 名用户的眼动追踪数据进行模型训练和验证,视频内容来自 youtube 和 vimeo 等网站,内容上涵盖了 PGC 长视频片段/UGC 短视频,语义上包含了游戏、动画、运动、vlog、电视节目等多个场景。最终排名由模型在验证集上的 AUC_J、CC、SIM、NSS 四项指标单项排名来加权得到,自研方案四项指标排名均取得第一,性能全面领先其他队伍方案。
冠军算法介绍
显著性预测任务面临的主要挑战:
眼动数据标注成本高,开源数据集规模有限,无法进行充分的预训练,因而容易导致模型鲁棒性不足。
人眼的运动和聚焦既受到颜色、对比度等底层图像信号的刺激,也受到大脑感知系统对于场景的理解和推导的影响,因此对于语义复杂的场景,显著性预测难度大大增加
随着观看时间的推移,显著区域会产生迁移,并具有一定延时性,需要对其时域特征进行良好的建模
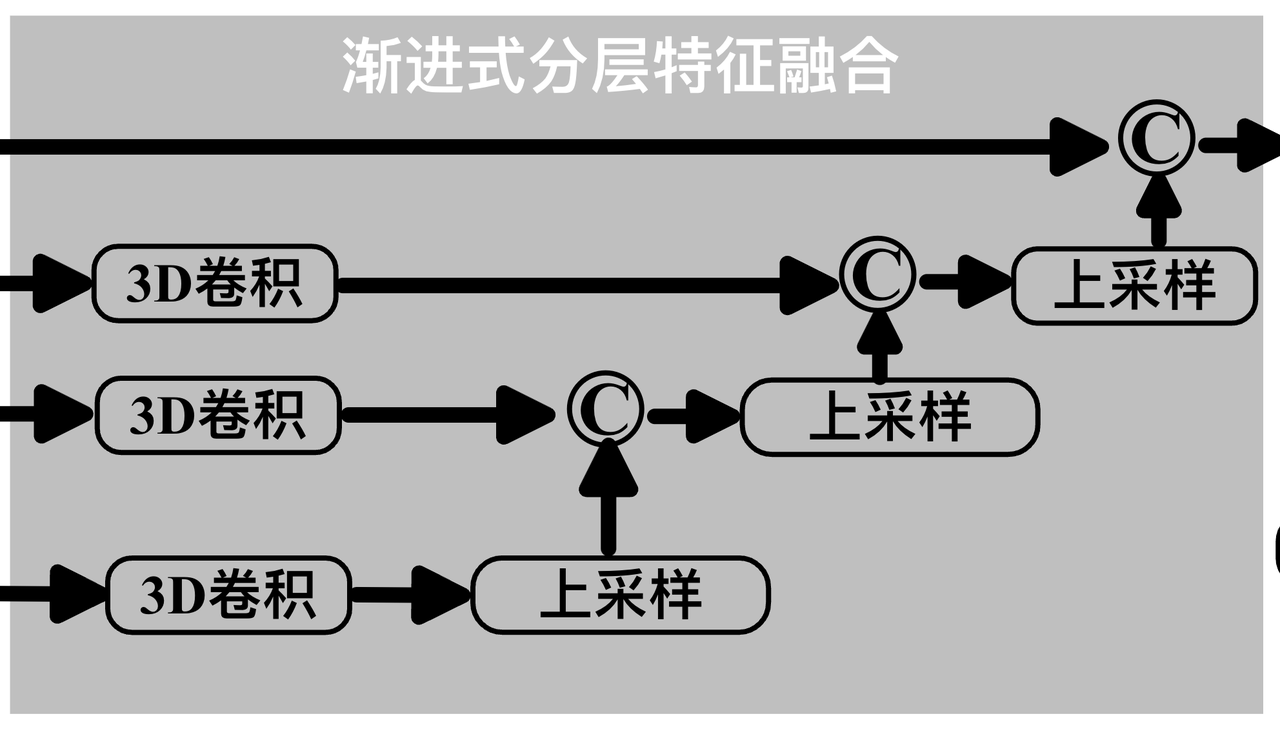
此前方案大部分使用了基于 image 的骨干网络来进行特征提取,时域建模使用 LSTM/GRU 或者 3D 卷积来进行。团队沿用了 encoder-decoder 架构,整体结构如下图,输入一组 RGB 视频帧,最终输出显著性图谱。显著性图谱以灰度图表示,像素范围 0-255,数值越高代表显著性程度越高。其中,特征编码器为视觉编码器提取视频序列的多层级特征。特征解码器包含特征上采样模块、时序注意力模块、3D 卷积、上采样、2D 卷积、Sigmoid 等模块。

编码器的选择上,选取了针对 video 的视频基础模型 UMT(Unmasked Teacher)来作为 encoder,其网络使用预训练的 vision Transformer (ViT)。通过分别提取 ViT 不同块的输出(第 5,11,17,23),可得到不同层级的视频特征,这些特征包含丰富的底层细节和高层语义信息,同时也建模了视频不同帧间的时序关系。
解码器的设计上,采用了类似 U-Net 的分层上采样结构,在使用 3D 卷积对编码器特征进行时域降维的同时,进行不同尺度的空域上采样,并将不同层级的特征进行融合。此外,团队引入了时序注意力模块,以应对显著性的时域延迟和场景切换问题。这种设计不仅提升了模型对视频内容的理解能力,也为捕捉动态变化提供了有效支持。
数据处理方面,采用了基于视频内容的 train/val 划分策略,根据内容特性对数据集进行分组,然后按比例从每个组采样数据来组成最终的训练集。考虑到 UMT 的输入分辨率较小(224x224),对标签中的注视点信息进行了膨胀处理(dilate),减少其在下采样过程中的信息丢失,同时清除了离群点以加快收敛速度。
训练策略方面,通过 SIM 指标将数据划分为简单样本和困难样本,通过增加模型在困难样本上的损失权重,模型得以更加关注那些在训练过程中表现不佳的样本,有效提升了模型的整体性能和泛化能力。
总结
火山引擎多媒体实验室在视频显著性预测领域实现了突破性的进展,并获得了该赛道冠军。显著性预测技术的迭代升级可以帮助技术人员更为准确地预测用户观看行为,为用户观看体验的优化提供重要指引,也有助于推动视频行业向着更加智能化、高效化的方向发展。基于显著性预测的 ROI 编码和 ROI 区域增强方案已广泛应用于直播、点播及图片等内部业务场景,并通过火山引擎相关产品面向企业开放。
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、大数据、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。




