
微博之前的 HTTP API 网关基于 NGINX 搭建,所有路由规则存放在 NGINX conf 配置文件中,带来一系列问题:升级步骤长,对服务增、删、改或跟踪问题时,不够灵活且难以排查问题。经过一番调研之后,我们选择了最接近预期、基于云原生的微服务 API 网关:Apache APISIX,借助其动态、高效、稳定等特性以满足业务的快速响应要求。
1 背景说明
在微博,运维同学要创建一个 API 服务,他需要先在 nginx conf 配置文件里面写好,提交到 git 代码仓库里面去,等其它负责上线的运维同学 CheckOut 之后,确认审核成功,才能它们推送部署到线上去,继而粗暴通知 NGINX 重新加载,这才算服务变更成功。
整个处理流程较长,效率较低,无法满足低代码化的 DevOps 运维趋势。因此,我们期待有一个管理后台入口,运维同学在 UI 界面上就可以操作所有的 http api 路由等配置。
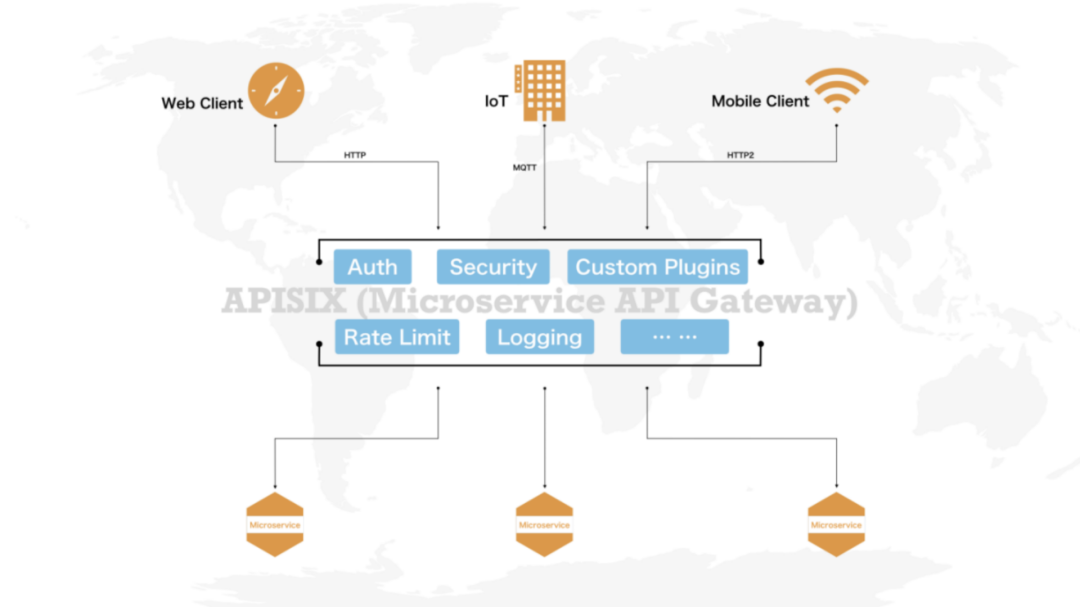
经过一番调研之后,我们选择了最接近期盼的基于云原生的微服务 API 网关:Apache APISIX。比较看重的点,有这么几个:
基于 NGINX ,技术栈前后统一,后期灰度升级、安全、稳定性等有保障;
内置统一控制面,多台代理服务统一管理;
动态 API 调用,即可完成常见资源的修改实时生效,相比传统 NGINX 配置 + reload 方式进步明显;
路由选项丰富,满足微博路由需求;
较好扩展性,支持 Consul kv 难度不大;
性能表现也不错。
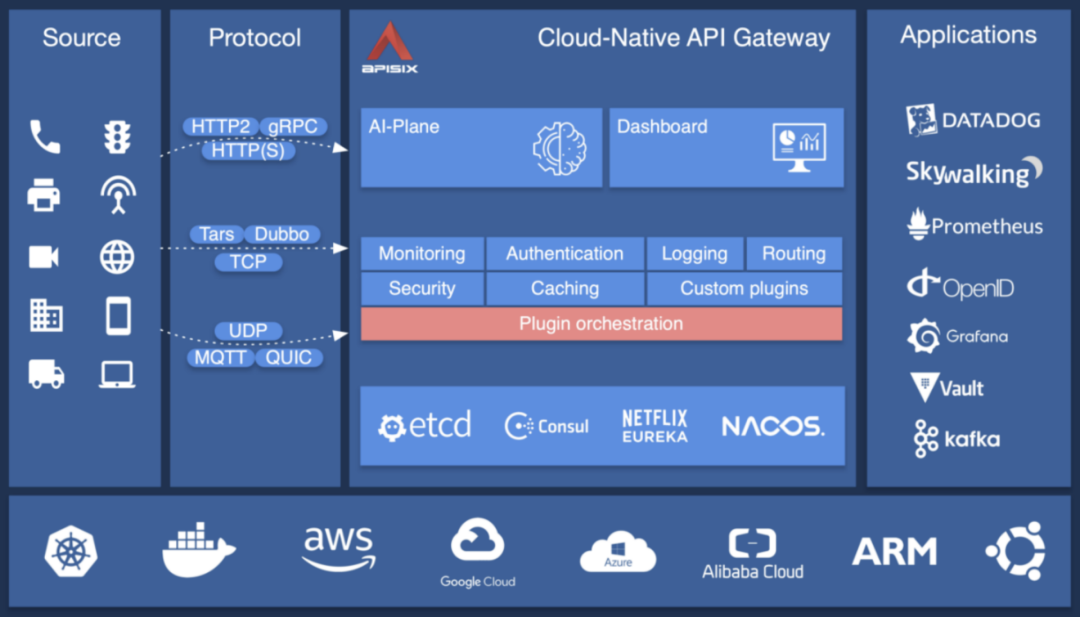
2 为什么选择定制化开发?
实际业务情况下,我们是没办法直接使用 Apache APISIX 的,原因有以下几点:
Apache APISIX 不支持 SaaS 多租户,实际需要运维的业务线上层应用有很多,每个业务线的开发或运维同学只需要管理维护自己的各种 rules、upstreams 等规则,彼此之间不相关联;
当把路由规则发布到线上后,如果出现问题则需要快速的回滚支持;
当新建或者编辑现有的路由规则时,我们不太放心直接发布到线上,这时就需要它能够支持灰度发布到指定网关实例上,用于仿真或局部测试;
需要 API 网关能够支持 Consul KV 方式的服务注册和发现机制;
上述这些需求目前 Apache APISIX 都没有内置支持,所以只能通过定制开发才能让 Apache APISIX 真正在微博内部使用起来。
3 在 Apache APISIX 的控制面,我们改了些什么?
我们定制开发时,使用的 Apache APISIX 1.5 版本,Dashboard 也是和 1.5 相匹配的。
定制开发的目标简单清晰,即完全零代码、UI 化,所有七层 HTTP API 服务的创建、编辑、更新、上下线等所有行为都必须在 Dashboard 上面完成。因此实际环境下,我们禁止开发和运维同学直接调用 APISIX Admin API,假如略过 Dashboard 直接调用 APISIX Admin API,就会导致网关操作没办法在 UI 层面上审计,无法走工作流,自然也就没有多少安全性可言。
有一种情况稍微特殊,运维需要调用 API 完成服务的批量导入等,可以调用 H5 Dashboard 的 API 来完成,从而遵守统一的工作流。
3.1 支持 SaaS 化服务
企业层面有完整的产品线、业务线数据库,每一个具体产品线、业务线可使用一个 saas_id 值表示。然后在创建网关配置数据插入 ETCD 之前,塞入一个 saas_id 值,在逻辑属性上所有的数据便有了 SaaS 归属。
用户、角色和实际操作的产品线就有了如下对应关联:
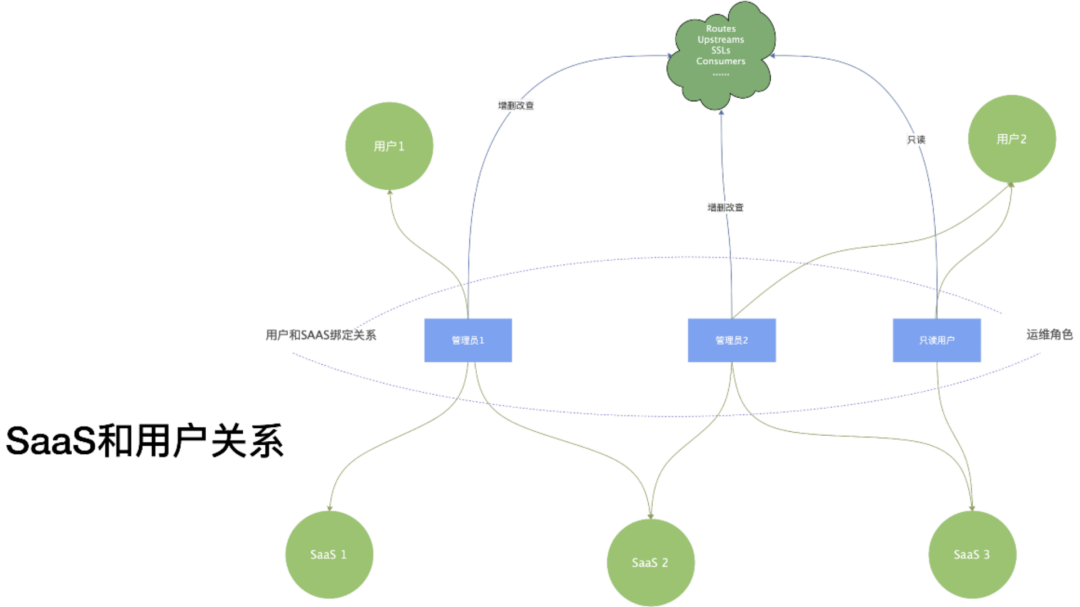
一个用户可以被分派承担不同运维角色去管理维护不同的产品线服务。
管理员角色很好理解,操作维护服务核心角色,针对服务增 / 删 / 改 / 查等;除此之外,我们还有只读用户的概念,只读用户一般是用于查看服务配置、查看工作流、调试等等。
3.2 新增路由发布审核工作流
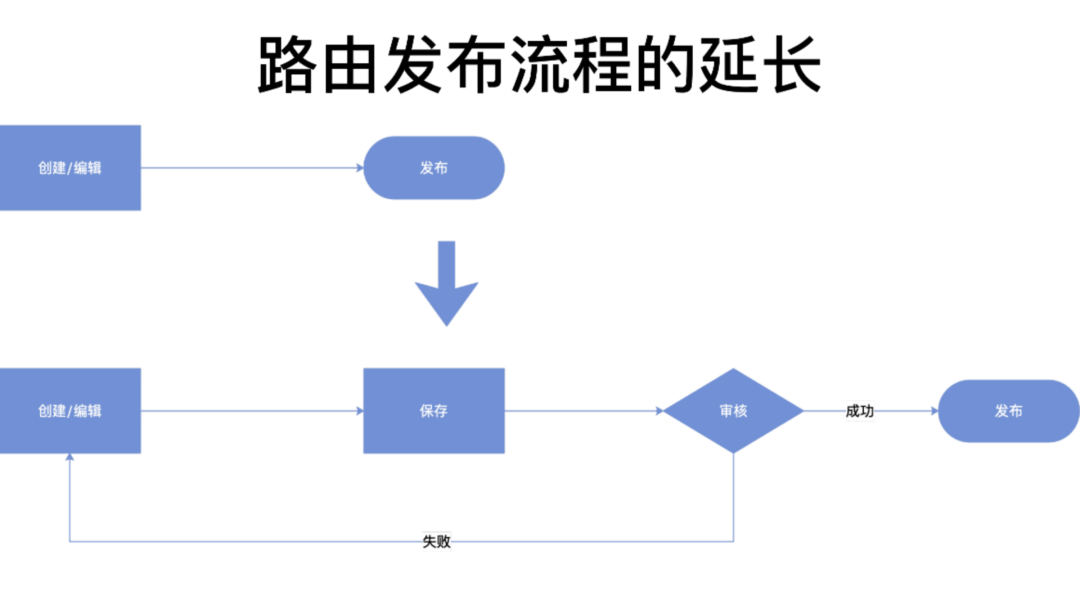
在开源版本中,创建或修改完一个路由之后就可以直接发布。
而在我们的定制版本中,路由创建或修改之后,还需要经过审核工作流处理之后才能发布,处理流程虽然有所拉长,但我们认为在企业层面审核授权后的发布行为才更可信。
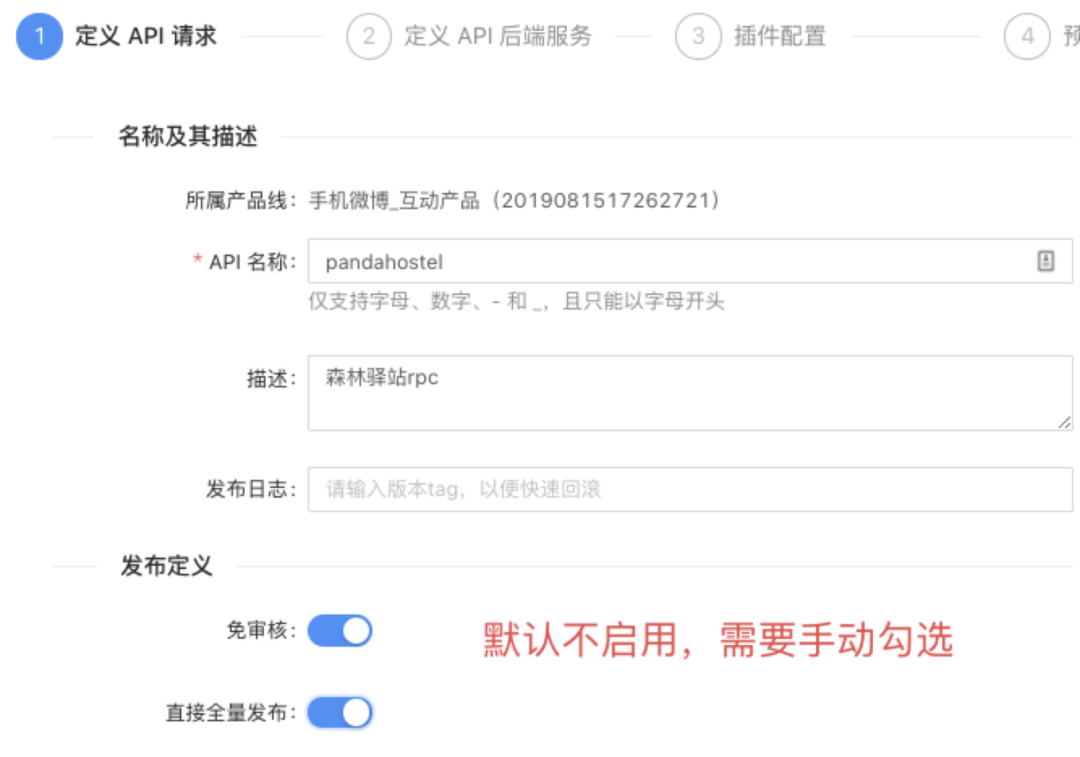
在创建路由规则时,默认情况下必须要经过审核。为了兼顾效率,新服务录入的时候,可选择免审、快速发布通道,直接点击发布按钮。
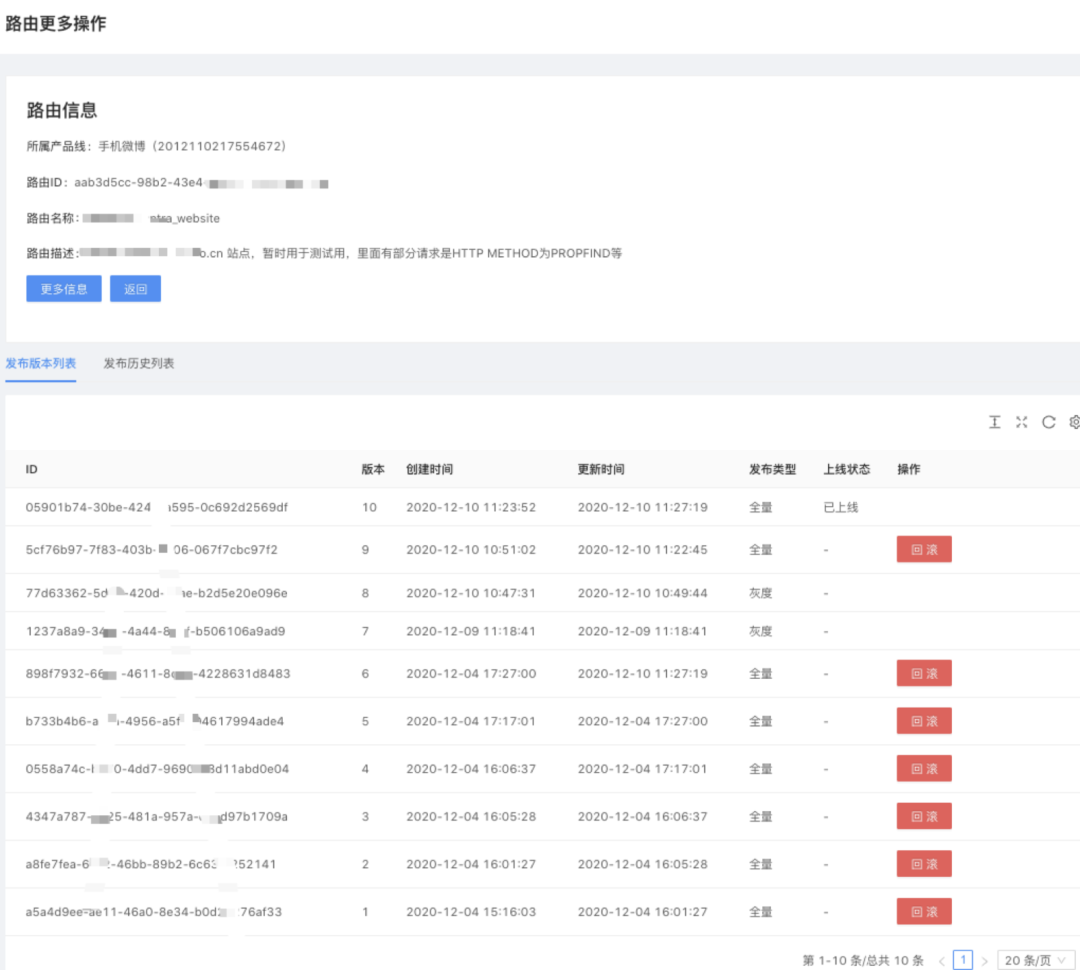
当一个重要 API 路由某次调整规则发布上线后出现问题时,可以选择该路由规则上一个版本进行快速回滚,粒度为单个路由的回滚,不会影响到其它路由规则。
单条路由回滚内部处理流程如下图示。
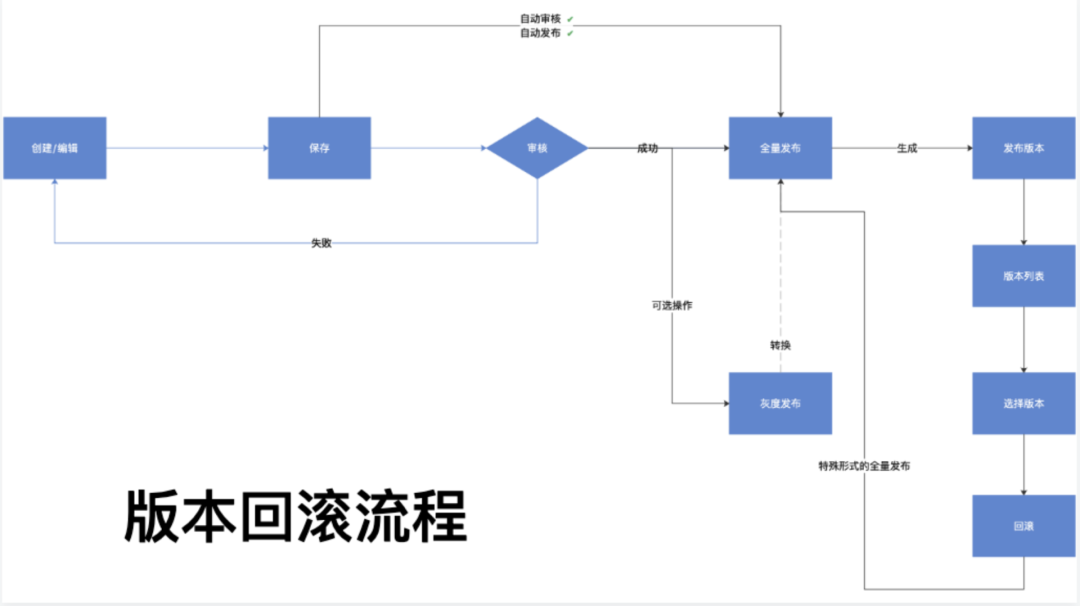
我们需要为单个路由的每次发布建立版本数据库存储。这样我们在审核之后进行全量发布,每发布一次会就会产生一个版本号,以及对应的完整配置数据;然后版本列表越积越多。当我们需要回滚的时候去版本列表里面选择一个对应版本回滚即可;某种意义上来讲,回滚其实是一个特殊形式的全量发布。
3.3 支持灰度发布
我们定制开发的灰度发布功能和一般社区理解的灰度发布有所不同,相比全量部署的风险有所降低。当某一个路由规则的变更较大时,我们可以选择只在特定有限数量的网关实例上发布并生效,而不是在所有网关实例上发布生效,从而缩小发布范围,降低风险,快速试错。
虽然灰度发布是一个低频的行为,但和全量发布之间依然存在状态的转换。
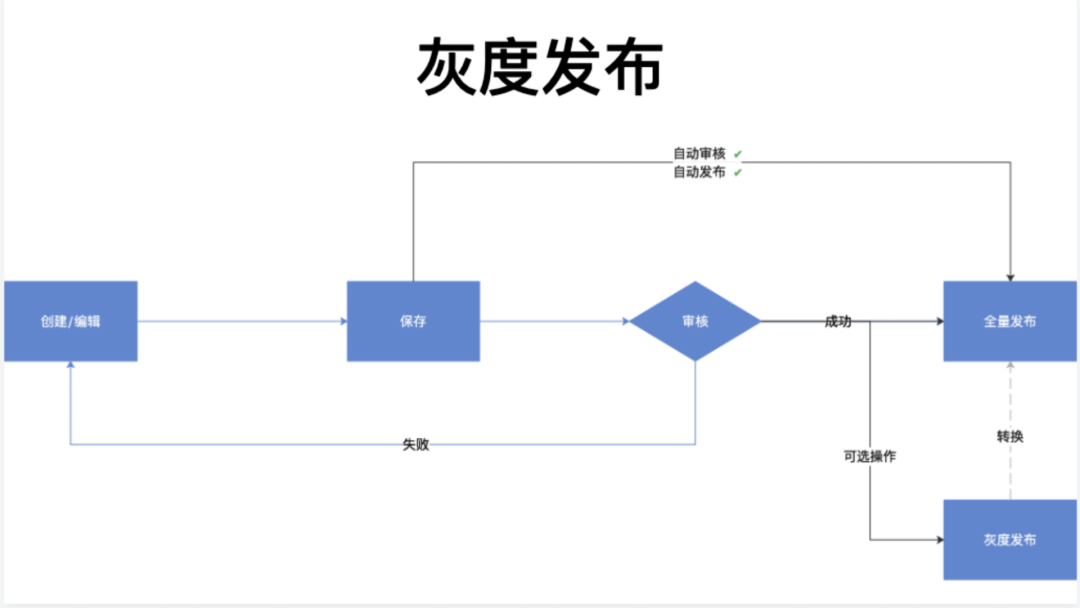
当灰度发布的占比减少到 0% 的时候,就是全量发布的状态;灰度发布上升到 100% 的情况下,就是下一次的全量发布,这就是它的状态转换。
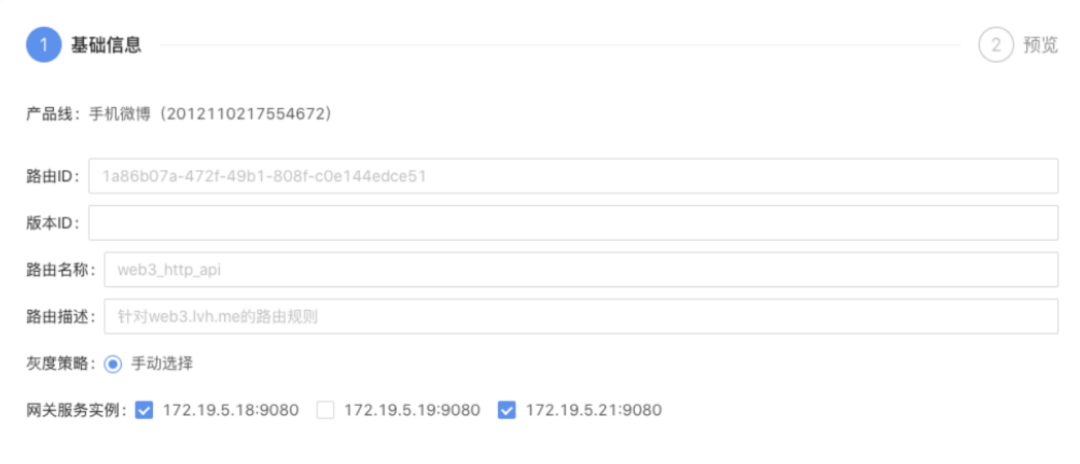
上图为在操作灰度发布选择具体的网关实例时的截图。
灰度发布完整功能除了管理后台支持,还需要在网关实例上暴露出一些 API 支持。

灰度发布 API 固定 URI, 统一路径为 /admin/services/gray/{SAAS_ID}/routes。不同 HTTP Method 呈现不同业务含义,POST 表示创建,停止灰度是 DELETE,查看就是 GET。
3.3.1 启动流程
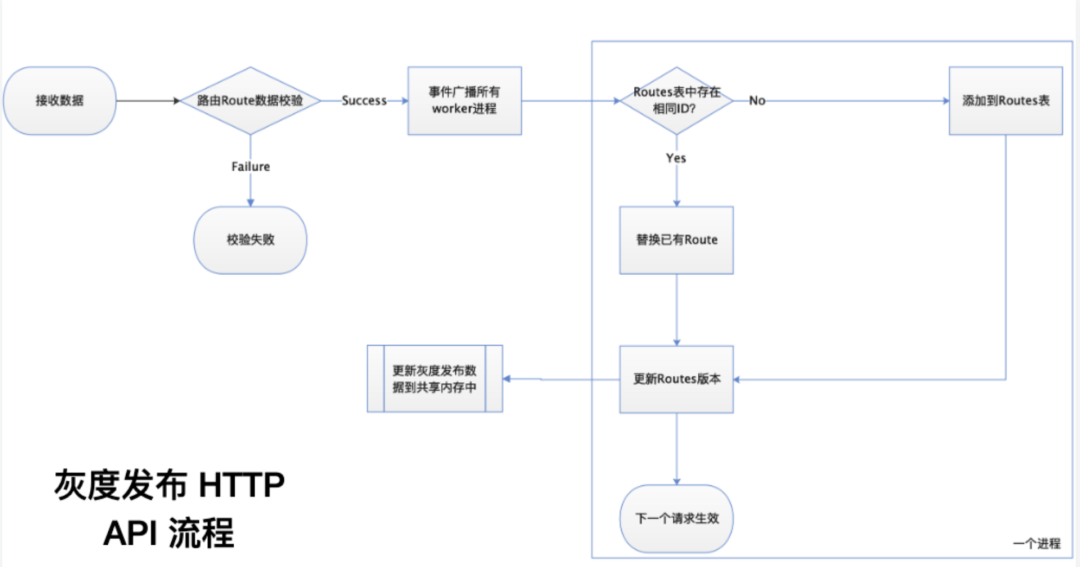
从网关层面发布一个 API,接收数据后 worker 进程校验发送来的数据的合法性,合法数据会通过事件广播给所有的 worker 进程。随后调用灰度发布 API ,添加完灰度规则,在下一个请求被处理时生效。
3.3.2 停用流程
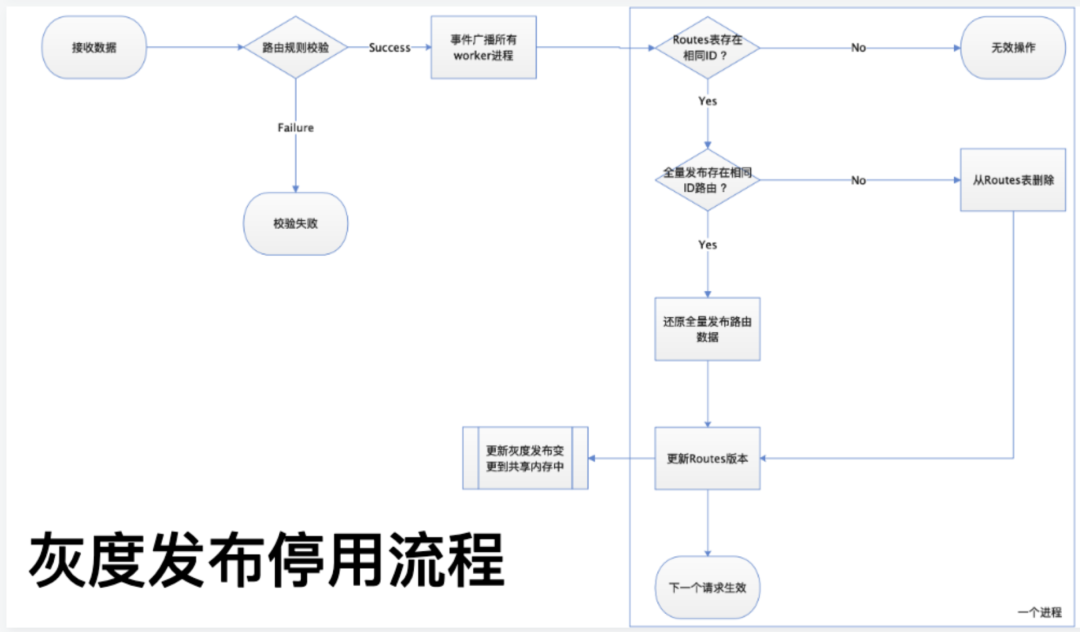
停用流程和灰度分布流程基本一致,通过 DELETE 的方法调用灰度发布的 API,广播给所有的 work 进程,每个 work 接收到需要停用的灰度的 ID 值后在 route 表里进行检测。若 route 表里存在就删除,然后尝试从 ETCD 里面还原出来。如果灰度停用了,要保证原先存在 ETCD 能够还原出来,不能影响到正常服务。
3.4 支持快速导入
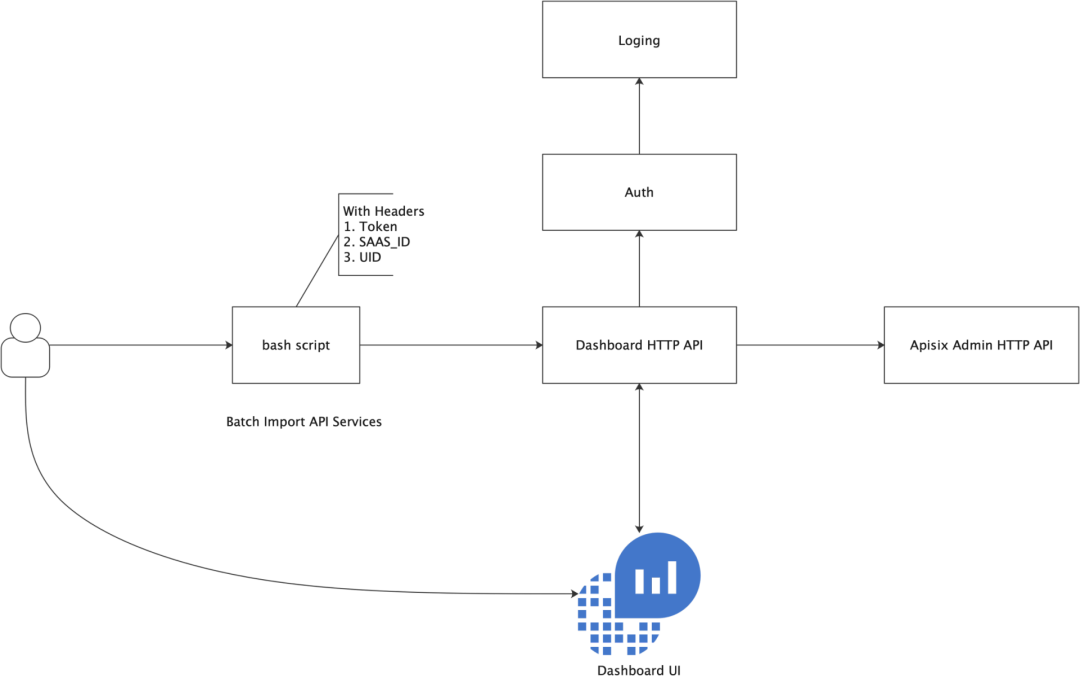
除了在管理页面支持创建路由之外,很多运维同学还是比较习惯使用脚本导入。我们有大量的 HTTP API 服务,这些服务要是一个一个手动录入,会非常耗时。如果通过脚本导入,则能够降低很多服务迁移阻力。
通过为管理后台暴露出 Go Impport HTTP API,运维同学可以在现成的 Bash Script 脚本文件中填写分配的 token、SaaS ID 以及相关的 UID 等,从而较为快速地导入服务到管理后台中。导入服务后续操作依然还是需要在管理后台 H5 界面上完成。
4 在 Apache APISIX 的数据面,我们改了些什么?
基于 Apache APISIX 数据面定制开发需要遵循一些代码路径规则。其中,Apache APISIX 网关的代码和定制代码分开存放不同路径,两者协同工作,各自可独立迭代。
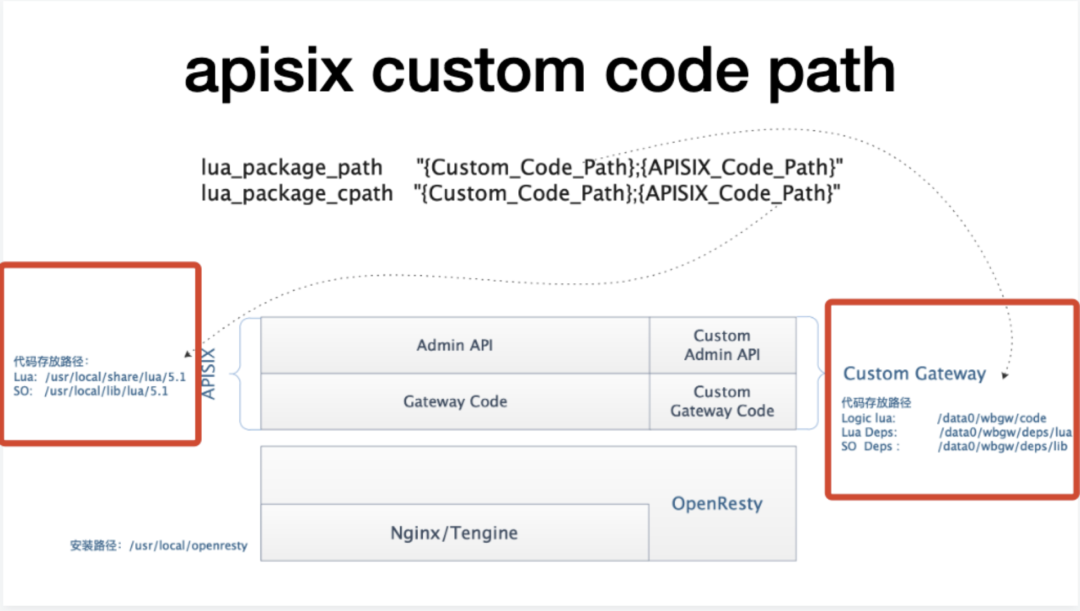
4.1 安装包的修改
因此打包时,不但有定制代码,还需要把依赖、配置等全部打包到一起进行分发。至于输出的格式,要么选择 Docker,要么打到一个 tar 包中,按需选择。
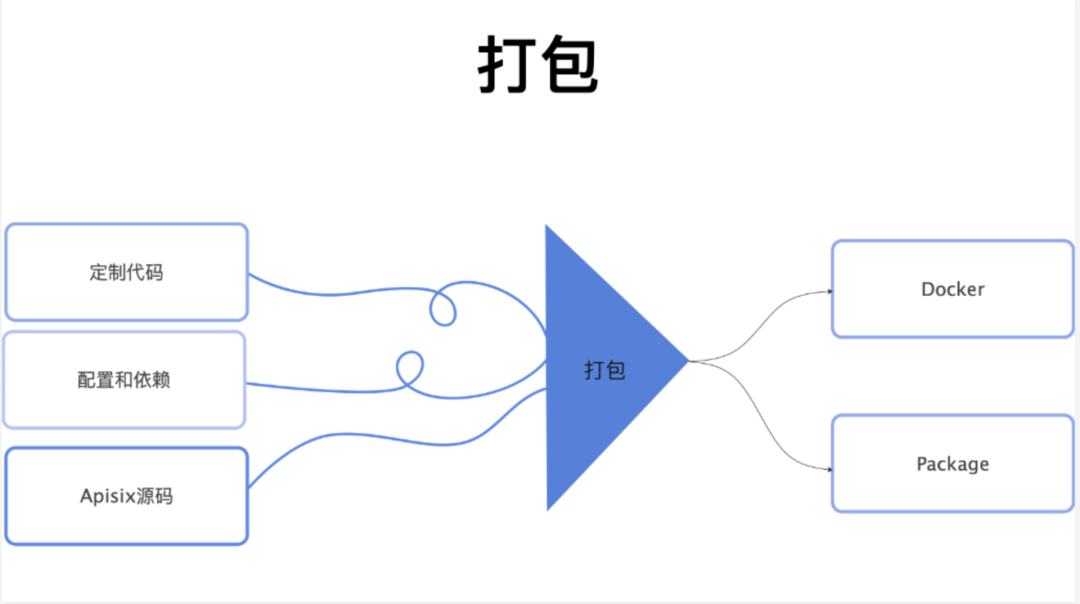
4.2 代码的定制开发
有些定制模块需要在被初始化时优先加载,这样对 Apache APISIX 的代码入侵就变得很小,只需要修改 NGINX.conf 文件。

比如,需要为 upstream 对象塞入一个 saas_id 属性字段,可以在初始化时调用如下方法。
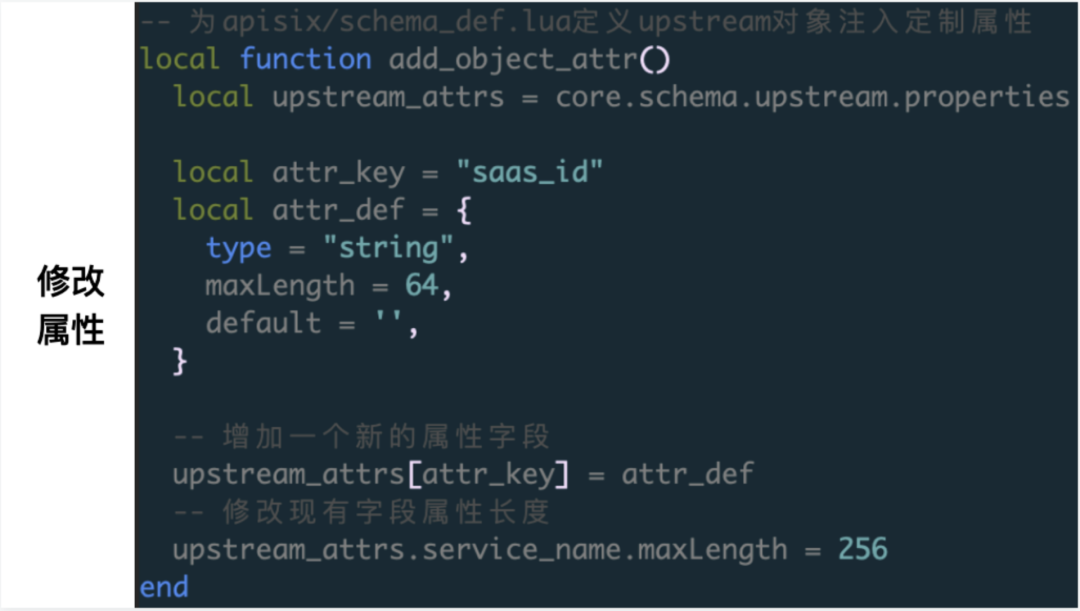
类似修改等,需要在 init_worker_by_lua_* 阶段完成调用,完成初始化。
另外一种情况:如何直接重写当前已有模块的实现。比如有一个 debug 模块,现在需要对它的初始化逻辑进行重构,即对 init_worker 函数进行重写。
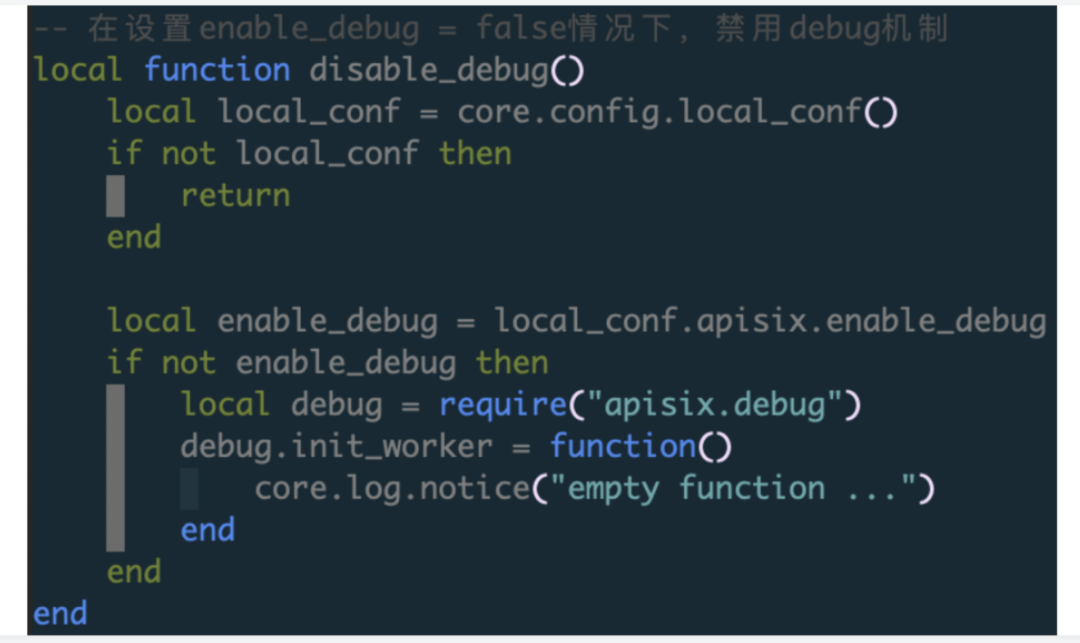
这种方式的好处在于,既能保证 API 原始的物理文件不动,又能加入自定义的 API 具体逻辑的重写,从而降低了后期代码管理的成本,也为后续升级带来很大的便利。
在生产环境下若有类似需求,可以参考以上做法。
4.3 支持 Consul KV 方式服务发现
当前微博很多服务采用 Consul KV 的方式作为服务注册和发现机制。以前 Apache APISIX 是不支持 Consul KV 方式服务发现机制的,就需要在网关层添加一个 consul_kv.lua 模块,同时也需要在管理后台提供 UI 界面支持,如下:
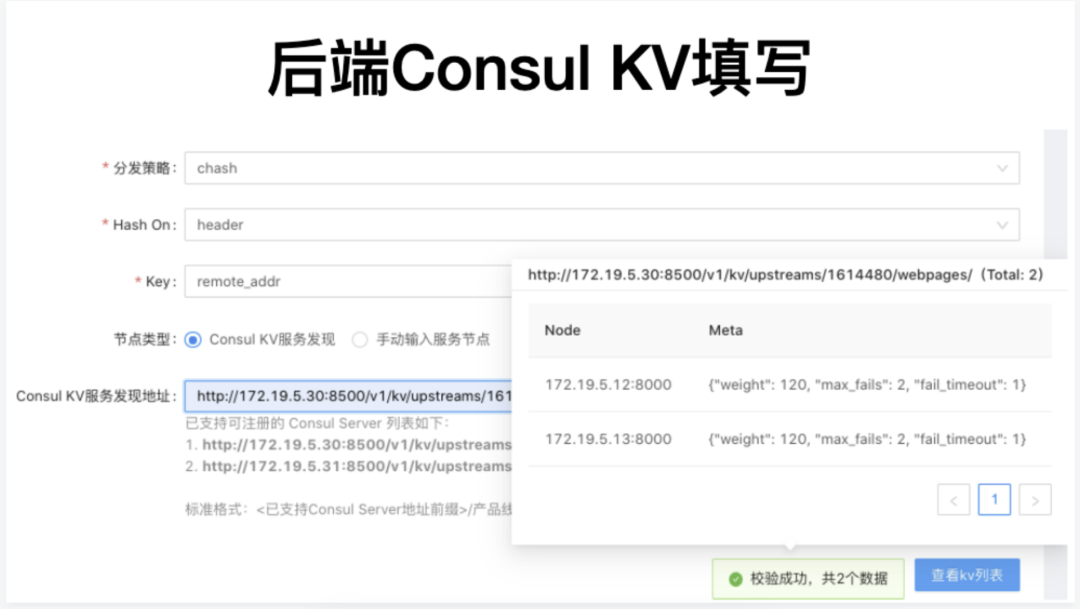
在控制台中的 upstream 列表中,填写的所有东西一目了然,鼠标移动到注册服务地址上,就会自动呈现所有注册节点的元数据,极大方便了运维同学日常操作。
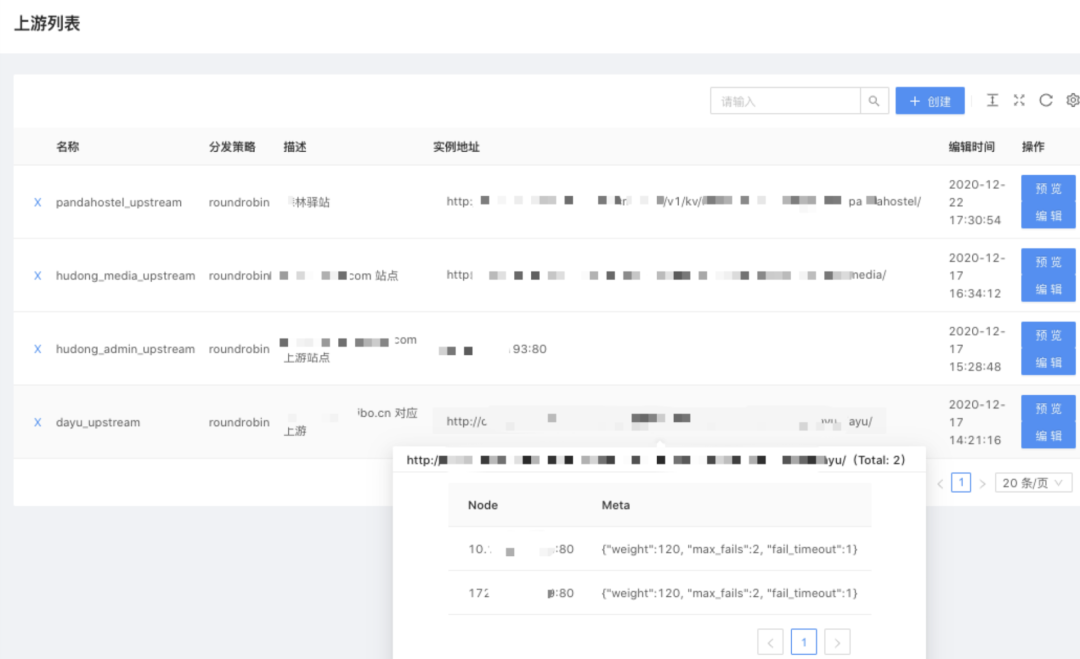
consul_kv.lua 模块在网关层的配置方式较为简单,同时支持多个不同 Consul 集群连接,当然这也是实际环境要求使然。

目前这部分代码已被合并到 APISIX master 分支中,2.4版本已包含。
该模块的进程模型采用订阅发布模式,每一个网关实例有且只有一个进程去长连接轮询多个的 Consul 服务集群,一旦有了新数据就会一一广播分发到所有业务子进程。
5 定制化过程中的一些思考
5.1 迁移成本高
在运维层面其实面临一个问题,就是迁移成本的问题。
任何一个新事物出现,用于替换现有的基础,都不会一马平川,而是需要经过一段时间慢慢熟悉、增进认知,然后不停试错,慢慢向前推进,逐渐消除大家心中的各种疑惑。只有在稳定运行一段时间,各种问题都得到解决之后,才会进入下一步较为快速的替换阶段。毫无疑问,当前 APISIX 在微博的使用还处于逐步推进的阶段,我们还在不断熟悉、学习并深入了解,同时解决各种各样的迁移问题,以期找到最佳实践路径。
举一个例子,在迁移过程中,需要一一将 nginx.conf 文件中的各种上游以及路由等规则导入到网关系统管理后台中,这是一个非常枯燥的手动操作过程,因此我们开发了快速导入接口,提供 bash script 脚本一键录入等功能来简化这个过程。
同时我们也会遇到 NGINX 各种复杂变量判断语句,目前主要是发现一个解决一个,不断积累经验。
5.2定制化程度高,导致后续升级成本较高
无论是 Apache APISIX 还是 Apache APISIX Dashboard,我们都做了很多定制化开发。这导致升级最新版 Dashboard 较为困难。不过,我们定制开发所选择的 Dashboard 版本基本功能都已具备,满足日常用途倒也足够了。
针对 Apache APISIX 的定制开发,则可以很轻松地升级,目前已经完成了若干个小版本的升级。
5.3 反哺社区
最后我们聊聊社区,我们也在想怎么把社区感兴趣的功能反哺给 Apache APISIX 社区,让大家一起使用和修改。
我们进行定制开发的驱动力主要来自微博内部的实际需求,与 Apache APISIX 社区推动的演进有一些出入,这是客观存在的事实。但除去一些包含敏感数据的代码,企业和社区总会在一些比较通用的功能代码层面存在共同需求,企业和开源社区可以一起推动使之进化得更为稳定成熟。比如通用的 Consul KV 服务发现模块、一些高可用配置文件的处理,以及其它问题的修复等。
这些共同需求一般会在企业内部打磨一段时间,直到完全满足内部需求之后,再逐步提交到社区开源代码分支里,但这也需要一个过程。
作者介绍:
聂永,微博基础架构师,开源爱好者, QCon 大会讲师,爱折腾追求 Geek。




