
今年的双 11,实时计算处理的流量洪峰创纪录地达到了每秒 40 亿条的记录,数据体量也达到了惊人的每秒 7TB,基于 Flink 的流批一体数据应用开始在阿里巴巴最核心的数据业务场景崭露头角,并在稳定性、性能和效率方面都经受住了严苛的生产考验。本文深度解析“流批一体”在阿里核心数据场景首次落地的实践经验,回顾“流批一体”大数据处理技术的发展历程。
随着 11 月 11 日 12 点钟声的敲响,2020 年双 11 的 GMV 数字定格在了 4982 亿,在 Flink 实时计算技术的驱动下全程保持了丝般顺滑滚动,基于 Flink 的阿里巴巴实时计算平台也圆满完成了今年双 11 整体经济体的实时数据任务保障,再次平稳度过全年大考。
除了 GMV 媒体大屏之外,Flink 还支持了诸如搜索推荐实时机器学习,广告实时反作弊,菜鸟订单状态实时跟踪反馈,云服务器的实时攻击探测以及大量基础设施的监控报警等等重要业务。实时业务量和数据量每年都在大幅增长,今年的实时计算峰值达到了创纪录的每秒 40 亿条记录,数据体量也达到了惊人的 7 TB 每秒,相当于一秒钟需要读完 500 万本《新华字典》。
截止目前,我们的实时计算作业数达到了 35000 多个,集群总计算规模也达到了超过 150 万核,在中国乃至世界范围内都处于领先水平。至此,Flink 已经支持了阿里经济体所有的实时计算需求,实现了全链路数据实时化,第一时间为消费者、商家以及运营人员带来了数据的价值。
但今年 Flink 技术演进带来的价值不仅于此,基于 Flink 的流批一体数据应用也开始在阿里巴巴最核心的数据业务场景崭露头角,并在稳定性、性能和效率方面都经受住了严苛的生产考验。

“流批一体”在阿里核心数据场景首次落地
事实上,Flink 流批一体技术很早就在阿里巴巴内部开始应用了。Flink 在阿里的发展始于搜索推荐场景,因此搜索引擎的索引构建以及机器学习的特征工程都已经是基于 Flink 的 批流一体架构。今年双 11,Flink 更进一步,利用流批一体计算能力,助力数据中台实现更加精准的实时离线交叉数据分析和业务决策。
阿里的数据报表分为实时和离线两种,前者在诸如双 11 大促场景下的作用尤为明显,可以为商家、运营以及管理层提供各种维度的实时数据信息,并帮助其及时作出决策,提升平台和业务效率。例如:在典型的营销数据实时分析场景,运营和决策层需要对比大促当天某个时间段和历史某个时间段的数据结果(比如大促当天 10 点的成交额和昨天 10 点成交额的对比),从而判断当前营销的效果,以及是否需要进行调控、如何调控等策略。
在上面这种营销数据分析场景下,实际上需要两套数据分析结果,一套是基于批处理技术在每天晚上计算出的离线数据报表,一套是基于流处理技术算出当天的实时数据报表,然后针对实时和历史数据进行对比分析,根据对比结果进行相关决策。离线和实时报表分别是基于批和流两种不同计算引擎产出,即批和流分离的架构不仅会有两套开发成本,更难以解决的是数据逻辑和口径对齐问题,很难保证两套技术开发出的数据统计结果是一致的。因此,理想的解决方案就是利用一套流批一体的计算引擎进行数据分析,这样离线和实时报表将天然一致。鉴于 Flink 流批一体计算技术的不断成熟,以及前期在搜索推荐场景的成功落地,今年双 11 数据平台开发团队也展示出坚定的信心和信任,与 Flink 实时计算团队并肩作战,共同推动实时计算平台技术升级,第一次让基于 Flink 的流批一体数据处理技术在双 11 最核心的数据场景顺利落地。
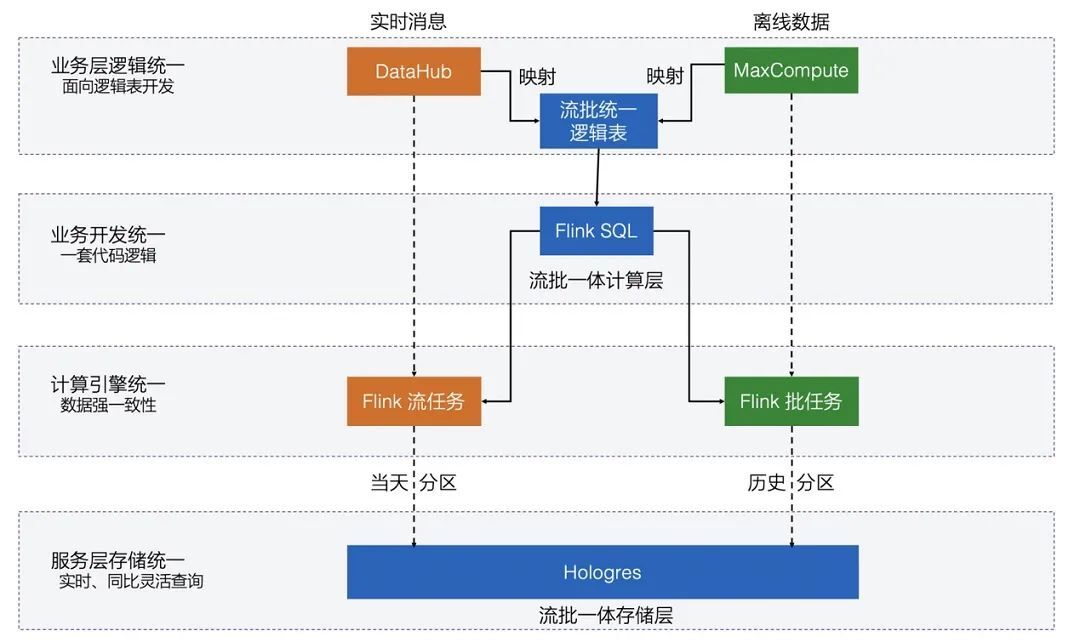
今年由 Flink 团队和数据平台团队共同推动的流批一体计算框架在双 11 数据核心场景成功首秀,也得到了阿里数据中台负责人朋新宇在业务层的认可:流批一体在技术上,实现了哪怕是多个计算处理模式,也只需要撰写一套代码就能兼容。在计算速度上比其他框架快 1 倍、查询快 4 倍,给小二们搭建数据报表提升了 4-10 倍的速度。同时,由于"一体化"的特性,能实现实时与离线数据的完全一致。

除了在业务开发效率和计算性能上的进步,流批一体计算架构也让集群资源利用率得到大幅提升。阿里的 Flink 实时集群经过最近几年的高速扩展,已经达到了百万核 CPU 的计算规模,上面运行着数万个 Flink 实时计算任务。白天是实时数据业务的高峰期,晚上业务低峰期计算资源出现空闲,正好可以为离线批任务提供免费的计算资源。批和流一套引擎,运行在一套资源底座上,天然的削峰填谷,自然的混布,不仅节省了开发成本,同时也大幅节省了运维成本和资源成本。今年双 11,基于 Flink 的流批一体数据业务,没有额外申请任何资源,批模式全部复用 Flink 实时计算集群,集群利用率大幅提升,为业务方节省了大量的资源开销,高效的资源模式也为后续更多业务创新提供了沃土。
“流批一体”,Flink 十年磨一剑
接下来让我们从技术角度聊一下“流批一体”大数据处理技术的发展历程。这要从开源大数据技术的鼻祖 Hadoop 开始谈起,10 多年前 Hadoop 作为第一代开源大数据技术出现,MapReduce 作为第一代批处理技术解决了大规模数据处理问题,Hive 的出现更是让用户可以用 SQL 的方式进行大规模数据的计算。但随着大数据业务场景的逐步发展,很多应用都对数据实时化产生了越来越强烈的需求,例如:社交媒体,电商交易,金融风控等行业。在这个需求背景下,Storm 作为第一代大数据流处理技术应运而生,Storm 在架构上和 Hadoop / Hive 完全不同,它是完全基于消息的流式计算模型,可以在毫秒级延迟情况下并发处理海量数据,因此 Storm 弥补了 Hadoop MapReduce 和 Hive 在时效性上的不足。就这样大数据计算在批和流两个方向都有了各自不同的主流引擎,并呈现出泾渭分明的格局,大数据处理技术经历完了第一个时代。
随后大数据处理技术来到了第二个时代, Spark 和 Flink 两款计算引擎在新时代陆续登场。Spark 相对于 Hadoop 和 Hive,具备更加完善的批处理表达能力和更加优秀的性能,这让 Spark 社区迅速发展,并逐步超越了 老牌的 Hadoop 和 Hive,成为批处理技术领域的主流技术。但 Spark 并未止步于批处理技术,很快 Spark 也推出了流计算解决方案,即 Spark Streaming,并不断进行改进完善。但大家都知道 Spark 的核心引擎是面向“批处理”概念的,不是一款纯流式计算引擎,在时效性等问题上无法提供极致的流批一体体验。但 Spark 基于一套核心引擎技术,同时实现流和批两种计算语义的理念是非常先进的,与其具备相同流批一体理念的还有另一款新引擎 Flink。Flink 正式亮相比 Spark 稍微晚一些,但其前身是来自德国柏林工业大学 2009 年的研究项目 Stratosphere,至今也有 10 年之久。Flink 的理念和目标也是利用一套计算引擎同时支持流和批两种计算模式,但它和 Spark 相比选择了不同的实现路线。Flink 选择了面向“流处理”的引擎架构,并认为“批”其实是一种“有限流”,基于流为核心的引擎实现流批一体更加自然,并且不会有架构瓶颈,我们可以认为 Flink 选择了 ”batch on streaming“ 的架构,不同于 Spark 选择的 “streaming on batch” 架构。
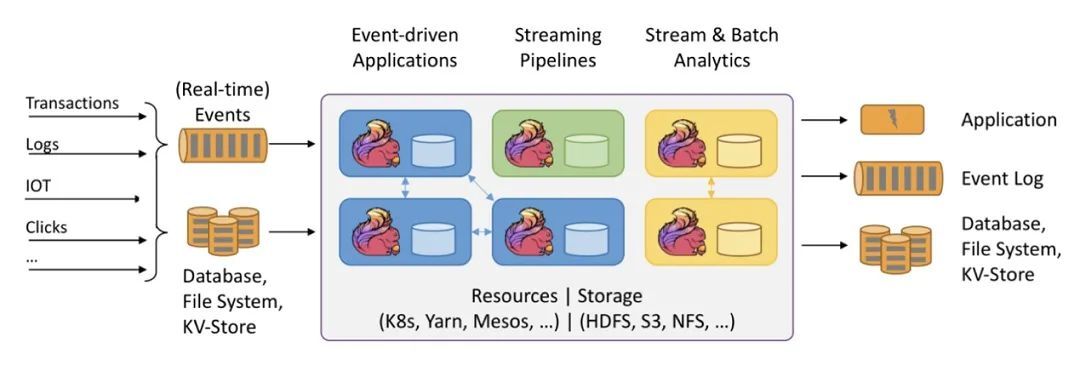
Flink 实现完善的流批一体架构也不是一蹴而就的,在早期的 Flink 版本中,Flink 的流和批无论在 API 还是在 Runtime 上都还没有达到彻底的统一。但从 1.9 版本开始,Flink 开始加速在流批一体上进行完善和升级,Flink SQL 作为用户使用的最主流 API,率先实现了流批一体语义,使得用户只需学习使用一套 SQL 就可以进行流批一体的开发,大幅节省开发成本。

但是 SQL 并不能解决用户的所有需求。一些定制化程度较高,比如需要精细化的操纵状态存储的作业还是需要继续使用 DataStream API。在常见的业务场景中,用户写了一份流计算作业后,一般还会再准备一个离线作业进行历史数据的批量回刷。但是 DataStream 虽然能很好的解决流计算场景的各种需求,但却缺乏对批处理的高效支持。
因此,Flink 社区在完成 SQL 流批一体升级之后,从 1.11 版本也开始投入大量精力对 DataStream 进行流批一体能力的完善,在 DataSteam API 上增加批处理的语义,同时结合流批一体 Connector 的设计,让 DataStream API 能够在流批融合场景下对接 Kafka 和 HDFS 等不同类型流批数据源。 接下来流批一体的迭代计算 API 也将被引入到 DataStream 中,进一步解锁一系列机器学习的场景。
在当前 Flink 主版本中,不管是 SQL 还是 DataStream API,在流批一体概念上都还是流计算和批计算功能的一个结合体。用户编写的代码,需要选择使用流的方式跑,还是批的方式跑。但有些业务场景已经提出更高的要求,即流批混合的需求,并且自动的在批和流之间自动切换,例如:数据集成以及数据入湖场景,用户的需求是先把数据库的全量数据同步到 HDFS 或者云存储上,然后再自动实时同步 DB 中的增量数据上去,并在同步过程中进行 流批混合的 ETL 数据处理,Flink 也将在后续继续支持更加智能的流批融合场景。
Flink “流批一体”技术在阿里巴巴的发展历程
阿里巴巴是国内最早选择 Flink 开源技术的公司,在 2015 年我所在的搜索推荐团队希望面向未来 5-10 年的发展,选择一款新的大数据计算引擎,用来处理搜索推荐后台海量商品和用户数据,由于电商行业对时效性具备非常高的诉求,因此我们希望新的计算引擎既有大规模批处理能力,也具备毫秒级实时处理能力,即一款流批统一的引擎,当时 Spark 的生态已经走向成熟,并且通过 Spark Streaming 提供了流批一体的计算能力,而 Flink 当时刚刚在前一年成为 Apache 顶级项目,还是一个冉冉升起的新星项目,当时团队内部针对 Spark 和 Flink 经过了一段时间的调研和讨论,一致认为虽然 Flink 当时生态并不成熟,但其基于流处理为核心的架构对于流批一体的支持更加合适,因此非常迅速的做出决定,在阿里内部基于开源 Flink 进行完善和优化,搭建搜索推荐的实时计算平台。
经过团队一年的努力,基于 Flink 的搜索推荐实时计算平台成功的支持了 2016 年的搜索双 11,保证了搜索推荐全链路实时化。通过在阿里最核心业务场景的落地证明,也让全集团都认识了 Flink 实时计算引擎,并决定将全集团实时数据业务都将迁移到 Flink 实时计算平台上。又经过一年的努力,Flink 在 2017 年双 11 不负众望,非常顺利的支持了全集团双 11 的实时数据业务,包括 GMV 大屏等最核心的数据业务场景。
2018 年 Flink 开始走向云端,阿里云上推出了基于 Flink 的实时计算产品,旨在为广大中小企业提供云计算服务。饮水思源,阿里巴巴不仅希望利用 Flink 技术解决自己业务的问题,同样也希望能够推动 Flink 开源社区更快的发展,为开源技术社区做出更多贡献,因此阿里巴巴在 2019 年初收购了 Flink 创始公司和团队 Ververica,开始投入更多资源在 Flink 生态和社区上。到了 2020 年,国内外主流科技公司几乎都已经选择了 Flink 作为其实时计算解决方案,我们看到 Flink 已经成为大数据业界实时计算的事实标准。
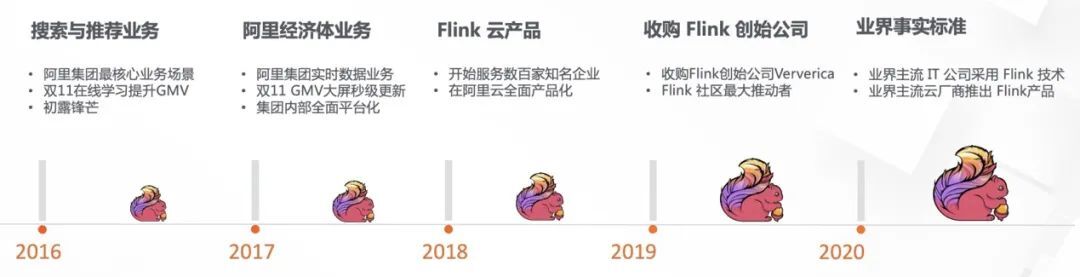
接下来,Flink 社区不会停止技术创新,在阿里巴巴业务场景中流批一体技术已经从理论走向落地。2020 年的双 11,Flink 流批一体技术在天猫营销决策核心系统中给出了精彩的表现,加上之前已经在搜索推荐中成功运行的流批一体索引构建以及机器学习流程,充分验证了 5 年前我们大胆选择 Flink 技术体系的正确性,相信未来我们将会在更多公司看到 Flink 流批一体技术的落地。
“流批一体”技术创新,推动 Flink 开源社区蓬勃发展
Flink 坚持流批一体技术创新之路,也自然推动 Flink 开源社区的高速发展和生态的加速繁荣。我们欣喜的看到,随着 Flink 在国内更多公司的加速落地,来自中文社区力量日益庞大,已经开始逐渐超越国外成为主流。
首先最明显的是用户数量的增多,从今年 6 月份起,Flink 中文邮件列表的活跃度开始超越英文邮件列表。随着大量的用户涌入 Flink 社区,也带来了更多的优秀代码贡献者,有效的促进了 Flink 引擎的开发迭代。
自 1.8.0 版本以来,Flink 每个版本的 Contributor 数量都在提升,其中大多数都是来自国内的各大企业。毫无疑问,来自国内的开发者和用户群体,已经逐渐成为推动 Flink 向前发展的中坚力量。
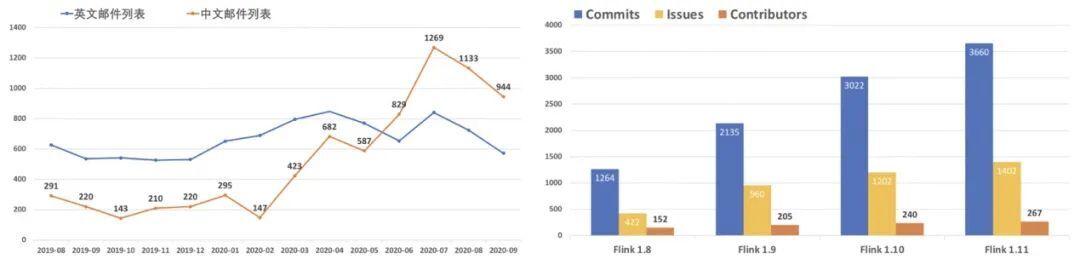
中文社区的不断壮大,使得 Flink 整体的活跃度和 2019 年相比有增无减。在 Apache 软件基金会 2020 财年的报告中,Flink 蝉联了年度最活跃项目(通过 user+dev 邮件列表活跃度)。与此同时,在代码 Commit 次数和 Github 主页流量这两项指标上,Flink 均排名第二。能在 Apache 软件基金会接近 350 个 顶级项目中取得如此成绩,着实不易。
Flink Forward Asia 2020,“流批一体”技术揭秘
Flink Forward 是由 Apache 官方授权的 Flink 技术大会, 今年 Flink Forward Asia (简称:FFA) 大会全程采用在线直播的方式,免费为广大开发者提供一场开源大数据技术盛宴,足不出户可以在线观看来自 阿里巴巴、蚂蚁科技、腾讯、字节跳动、美团、小米、快手、B 站、网易、微博、Intel、DellEMC、Linkedin 等国内外一线互联网公司针对 Flink 的技术实践分享和技术创新。
流批一体也将是本届 FFA 大会的热门话题,来自天猫数据技术负责人将会给大家分享 Flink 流批一体技术在阿里的实践和落地,让大家看到流批一体技术是如何在双 11 最核心的场景中发挥业务价值;来自阿里巴巴、字节跳动的 Flink PMC 和 Committer 技术专家将围绕 Flink 流批一体 SQL 和 Runtime 进行深度技术解读,为大家带来 Flink 社区的最新技术进展;来自腾讯的游戏技术专家将为大家带来 Flink 在国民游戏王者荣耀中的应用实践;来自美团的实时大数据负责人将为大家介绍 Flink 如何助力生活服务场景实时化;来自快手大数据负责人将为大家带来 Flink 在快手的前世今生发展历程;来自微博的机器学习技术专家将为大家带来如何利用 Flink 进行信息推荐。此外,Flink 相关的议题还涵盖了金融、银行、物流、汽车制造、出行等各行各业,呈现出百花齐放的繁荣生态景象。欢迎对开源大数据技术有热情的开发者能参加本届 Flink Forward Asia 技术大会,了解更多 Flink 社区最新技术发展和创新。
戳这里,去 Flink Forward Asia 2020。




