
我们正一步步迈向 2023 年的终点,也许是时候对这一年来 AI 研究、行业动态以及开源领域发生的主要变化做一番简要回顾了。当然,这篇文章不可能面面俱到。我们只挑干货,一同审视这风云变幻的一年中都有哪些大事值得回味。
2022 年的趋势进一步扩展
这一年中,AI 产品并没有表现出任何根本性的发展或者方法创新。相反,2023 年的重点就是对过去一年已经生效的趋势做进一步扩展:
ChatGPT 依托的 GPT 3.5 升级到了 GPT 4。
DALL-E 2 升级到了 DALL-E 3。
Stable Diffusion 2.0 升级到了 Stable Diffusion XL。
还有更多...
有个有趣的传言说,GPT-4 是由 16 个子模块组成的混合专家模型(MoE)。据传这 16 个子模块各自拥有 1110 亿个参数(作为参考,GPT-3 总共也只有 1750 亿个参数)。

2023 年 AI 现状报告中的 GPT-3/GPT-4 示意图。
GPT-4 属于混合专家模型的情况可能是真的,但我们还无法确定。从趋势上看,行业研究人员在论文中分享的信息要比以往更少。例如,虽然 GPT-1、GPT-2、GPT-3 乃至 InstructGPT 论文都公开了架构和训练细节,但 GPT-4 的架构却一直是个谜。再举另外一个例子:虽然 Meta AI 的第一篇 Llama 论文详细介绍了用于模型训练的数据集,但从 Llama 2 模型开始也不再公布这方面信息。关于这个问题,斯坦福大学上周公布了基础模型透明度指数。根据该指数,Llama 2 以 54%领先,而 GPT-4 则以 48%排名第三。
当然,要求这些企业发布自己的商业秘密也不太合理。总之,逐渐封闭本身是个有趣的趋势,而且就目前来看我们可能会在 2024 年继续沿着这个路子走下去。
关于规模扩展,今年的另一大趋势在于输入上下文的长度不断增长。例如,GPT-4 竞争对手 Claude 2 的主要卖点之一,就是其支持最多 100k 的输入 token(GPT-4 目前仅支持 32k token),也就是说其在为长文档生成摘要方面具备鲜明的优势。另外,Claude 2 还支持 PDF 输入,因此在实践应用中更加灵活实用。
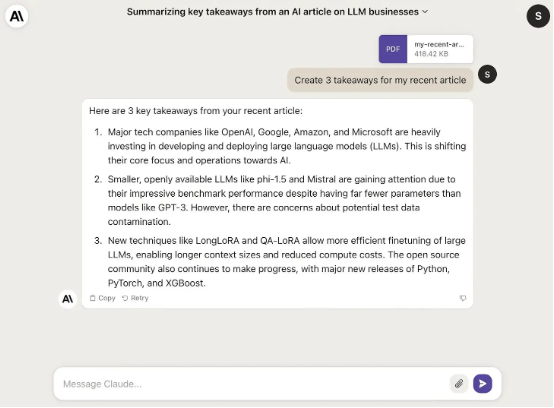
使用 Claude 2 为 PDF 文档生成摘要。
开源与研究趋势
我还记得,去年开源社区的主要关注对象还是潜在扩散模型(最典型的代表就是 Stable Diffusion)等计算机视觉模型。扩散模型与计算机视觉与一直高度相关、牢牢绑定。但短短一年过去,如今的开源与研究社区新贵已然变成了大语言模型。
开源(更确切地讲,是公开可用)大语言模型的爆发式增长,一定程度上要归功于 Meta 发布的首个预训练 Llama 模型。尽管其仍有许可限制,但已经启发了 Alpaca、Vicuna、Llama-Adapter、Lit-Llama 等衍生成果和众多研究人员/从业者的关注。
几个月后,Llama 2 模型正式亮相,在基本取代 Llama 1 的基础之上表现出更为强大的功能,甚至还提供了微调版本。
然而,目前的大多数开源大语言模型仍然是纯文本模型。好在 Llama-Adapter v1 和 Llama-Adapter v2 微调版本有望将现有大模型转化为多模态模型。
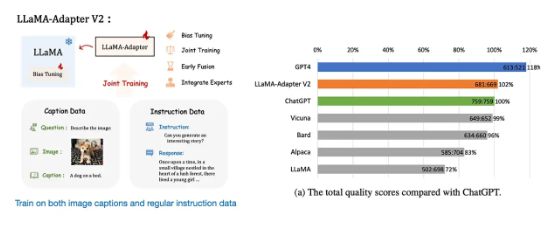
Llama-Adapter V2 示意图,https://arxiv.org/abs/2304.15010
Fuyu-8B 是个值得关注的例外模型,此模型刚刚在 10 月 17 日正式发布。
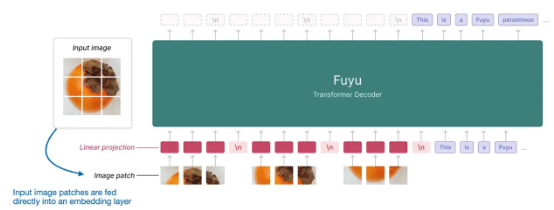
Fuyu 示意图及注释 https://www.adept.ai/blog/fuyu-8b
值得注意的是,Fuyu 能够将输入补丁直接传递至线性投影(或者叫嵌入层)处以学习其自身图像补丁嵌入,而不会像其他模型/方法那样依靠额外的预训练图像编码器(例如 LLaVA 和 MiniGPT-V),这就极大简化了架构和训练设置。
除了前面提到的少数多模态尝试之外,目前最大的研究重点仍然是如何将 GPT-4 文本性能迁移至参数范围<100 B 的小模型当中。目前的主要技术难点则包括硬件资源成本与限制、可访问数据量不足,以及开发时间太短(受到发布计划的影响,大多数研究人员不可能投入数年时间来训练单一模型)。
然而,开源大语言模型的未来突破并不一定来自将模型扩展至更大规模。在新的一年中,我们将继续关注混合专家模型能否将开源模型提升到新的高度。
另一个有趣的现象,就是我们在研究前沿还看到了一些针对基于 Trasnformer 大语言模型的替代方案,包括循环 RWKV 大模型和卷积 Hyena 大模型,希望能够提供运行效率。但必须承认,基于 Transformer 的大语言模型仍然是当前最先进的技术方案。
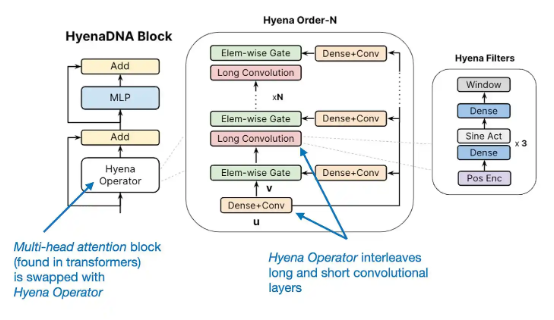
带注释的 Hyena 大模型架构示意图: https://hazyresearch.stanford.edu/blog/2023-06-29-hyena-dna
总的来讲,2023 年是开源活动高度活跃的一年,也带来了不少突破和进步,并切实证明了技术研究工作有着一加一大于二的协同效应。但令人遗憾的是,仍有声音在积极反对和打击开源 AI 技术。希望我们能够继续保持住这股积极的势头,建立起更高效的解决方案和替代方案,而不仅仅是继续依赖科技巨头们发布的类 ChatGPT 产品。
在本小节的最后,我们要感谢开源和研究社区的付出。你们的努力让可以运行在单个 GPU 上的小型高效模型成为现实,包括 1.3B 参数的 phi 1.5、7B 参数的 Mistral 和 7B Zephyr,这些都拥有接近大型专有模型的性能表现。这样的趋势令人兴奋,期待相关工作能在 2024 年带来更多进展。
关于生产力的承诺
在我看来,开源 AI 就是开发高效、定制大语言模型的主要途径,其中包括根据各种个人/特定领域数据、针对不同场景进行微调的大模型。我自己经常在社交媒体上讨论 Lit-GPT,这是我正在积极贡献的一个开源大语言模型。而且我觉得开源并不代表粗糙,我也希望能在保持开源的同时、让成果拥有出色的设计水平。
自从 ChatGPT 发布以来,我们看到大语言模型几乎被应用在各个领域。屏幕前的读者可能已经体验过 ChatGPT,所以这里就不具体解释大模型在不同场景下的实际效果了。
关键在于,我们得把生成式 AI 之力用在“正确”的地方。比如说,ChatGPT 肯定不擅长回答我们常去的杂货店晚上几点关门。我个人最喜欢的用法之一,就是让它帮我修改文章中的语法、或者是集思广益,包括给句子和段落做做润色等。从更宏观的角度看,大语言模型做出了关于生产力的承诺,可能很多朋友都体验过它带来的效率提升。
除了常规文本大模型之外,微软和 GitHub 的 Copilot 编码助手也在日趋成熟,并受到越来越多程序员们的喜爱。今年早些时候,Ark-Invest 发布的报告估计,代码助手有望将编码任务的完成时间缩短约 55%。
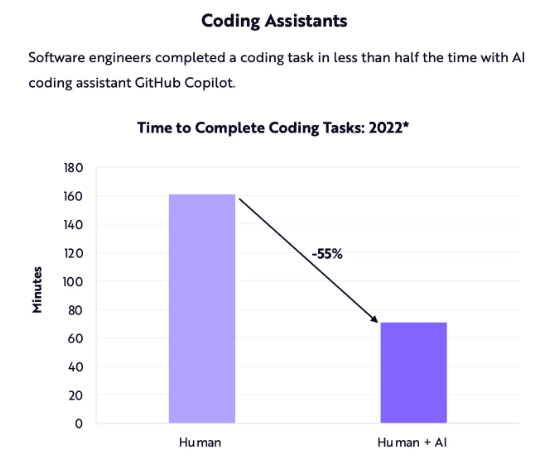
编码助手示意图 https://ark-invest.com/home-thank-you-big-ideas-2023/
实际效果究竟有没有 55%尚有争议,但如果大家已经体验过编码助手,就会发现它们确实很有帮助,能够将繁琐的编码相关任务变得更加轻松。
而且有一点是肯定的:编码助手将长期存在,并随着时间推移变得越来越强大。它们最终会取代人类程序员吗?我希望不会,但它们无疑会让现有程序员变得更具生产力。
那这对于 Stack Overflow 又意味着什么?《AI 技术现状》报告中包含一份图表,展示了 Stack Overflow 与 GitHub 网站之间的流量对比,后者的逐渐胜出可能就跟 Copilot 的采用率提升有关。但我个人认为形成这种趋势的应该不只是 Copilot,ChatGPT/GPT-4 在编码任务方面的表现也相当出色,所以我怀疑 Stack Overflow 下滑是整个生成式 AI 阵营发展壮大的共同结果。
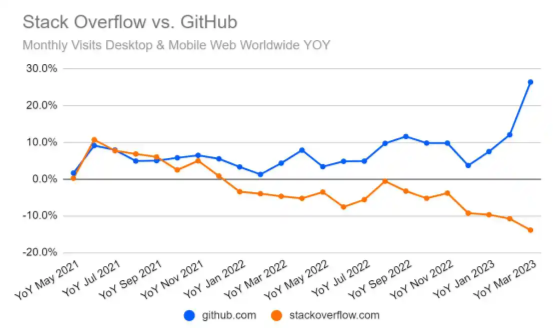
《2023 年 AI 现状报告》(http://stateof.ai/)中的图表
AI 仍不完善
幻觉问题
2022 年困扰大语言模型的问题在今年仍未得到解决:它们会生成负面内容,而且经常产生幻觉。这一年中倒确实出现了有望解决问题的几种方法,包括利用人类反馈的强化学习(RLHF)以及英伟达的 NeMO Guardrails 等。然而,这些方法要么过于严格、要么只能算是松散的补丁。到目前为止,还没有任何方法(甚至没有可靠的思路)能够在不削弱大模型能力的同时,100%解决掉幻觉问题。在我看来,这一切都取决于我们如何使用大语言模型:别指望在所有场景下都使用大模型——数学计算还是交给计算器比较好;尽量用大模型处理它最擅长的文本创作等工作,并保证认真检查它的输出内容。
此外,对于特定的业务类应用,探索检索增强(RAG)也是一种值得考虑的折衷方案。在 RAG 中,我们需要从语料库中检索相关文档段落,再根据检索到的内容微调大模型所生成的文本。这种方式让模型能够从数据库和文档中提取外部信息,而不必记住所有知识。
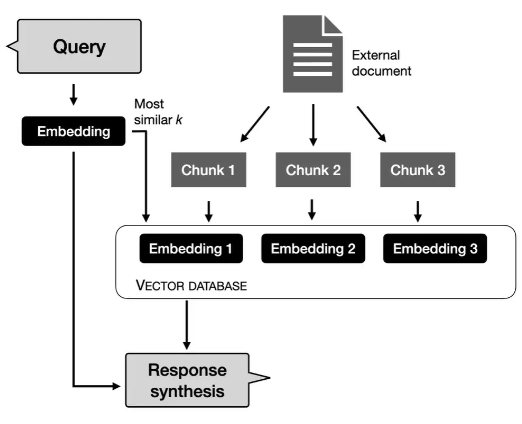
我自己的新书《Machine Learning Q and AI》(https://leanpub.com/machine-learning-q-and-ai/)中的 RAG 示例。
版权问题
另一个更紧迫的问题,则是围绕 AI 出现的版权争论。根据维基百科的解释,“对于受版权保护的素材训练而成的大语言模型,模型自身的版权应如何对待仍悬而未决。”总的来说,相关规则似乎仍在起草和修改当中。我希望无论最终规则如何,其内容都应尽可能明确,以便 AI 研究人员和从业者能够做出相应的调整和行动。
评估问题
长久以来,困扰学术研究的一大难题在于,目前流行的基准测试和排行榜所采取的评估方法早就半公开了,其测试集甚至已经被某些大模型用作训练数据。phi 1.5 和 Mistral 就都存在这样的问题。
也有人在用其他大模型自动做评估,但这种方式不擅长处理那些跟偏好相关的问题。总之,不少论文已经在依赖 GPT-4 作为辅助性质的模型评估方案。

LIMA 论文中的人类与 GPT_4 偏好评估示例。
收入问题
生成式 AI 目前仍处于探索阶段,不过文本和图像生成器已经能够在特定场景下带来不错的表现。然而,由于高昂的托管和运行时间成本,这些工具能够为企业产生正向现金流仍是个备受争议的问题。例如,有报道称 OpenAI 过去一年亏损了 5.4 亿美元。另一方面,最近的报道指出 OpenAI 目前的单月收入为 8000 美元,已经足以抵偿或超过其运营成本。
伪造图像
由生成式 AI 引发的另一个大问题,就是伪造图像和视频。这类隐患在当前的社交媒体平台上已经相当明显。伪造图像和视频一直是个大麻烦,而且凭借远低于 Photoshop 等内容编辑软件的准入门槛,AI 技术已经将严重性提升到了新的水平。
目前有一部分 AI 系统在尝试检测由 AI 生成的内容,但这些系统在文本、图像和视频检测中的表现都不够可靠。某种程度上,遏制并解决这些问题的唯一方法仍然要依靠人类专家。就如同我们不能轻易相信网上某个论坛或者网站中的医疗或者法律建议一样,我们也绝不能在未经认真核实的情况下,就盲目相信网络上散播的图像和视频。
数据集瓶颈
跟之前提到的版权争议相关,不少企业(包括 Twitter/X 和 Reddit)都关闭了免费 API 以增强经营收入,同时也防止爬取者收集其平台数据用于 AI 训练。
我见过不少由数据集专职收集厂商打出的宣传广告。从这个角度来看,尽管 AI 确实会用自动化取代一部分工作岗位,但似乎同时也创造出了新的职务类型。
目前来看,为开源大模型做贡献的最佳方式之一,就是建立一个众包性质的数据集平台,在这里搜集、整理并发布明确允许大语言训练使用的数据资源。
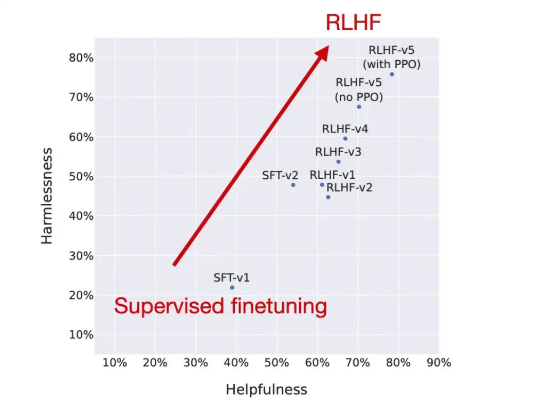
RLHF 会是破解难题的正确答案吗?
在 Llama 2 模型套件发布时,我很高兴看到其中包含了可通过聊天进行微调的模型。Meta AI 也使用人类反馈强化学习(RLHF)提高了模型的实用性和无害性。
Llama 2 论文中的注释图:开放基础与微调聊天模型, https://arxiv.org/abs/2307.09288
我一直觉得 RHLF 是种非常有趣、而且极具前景的方法。但除了 InstructGPT、ChatGPT 和 Llama 2 之外,大多数模型并没有广泛采用。可在无意之中,我还是找到了下面这份 RLHF 流行度统计图表。
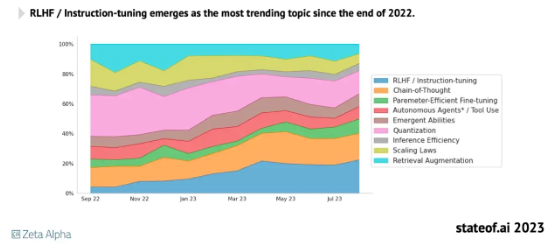
《2023 年 AI 现状报告》中的 RLHF 流行度图表。
由于 RLHF 的实施难度比较大,所以大部分开源项目仍然采取指令微调的有监督微调方式。
RLHF 的最新替代方案是直接偏好优化(DPO)。在相关论文中,研究人员表示 RLHF 中拟合奖励模型的交叉熵损失可以直接用于大模型的微调。根据他们的基准测试,DPO 的效率更高,而且在对质量的响应方面一般也优于 RLHF/PPO。
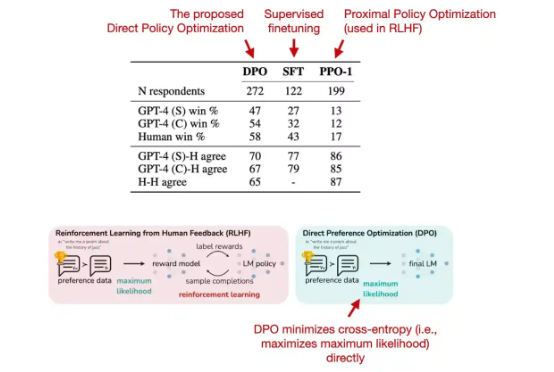
DPO 论文(https://arxiv.org/abs/2305.18290)中的注释图。
但 DPO 似乎还未得到广泛使用。而令我兴奋的是,两周之前 Lewis Tunstall 及其同事通过 DPO 训练了首个公开可用的大语言模型,该模型的性能似乎优于由 RLHF 训练而成的大型 Llama-2 70b 聊天模型:
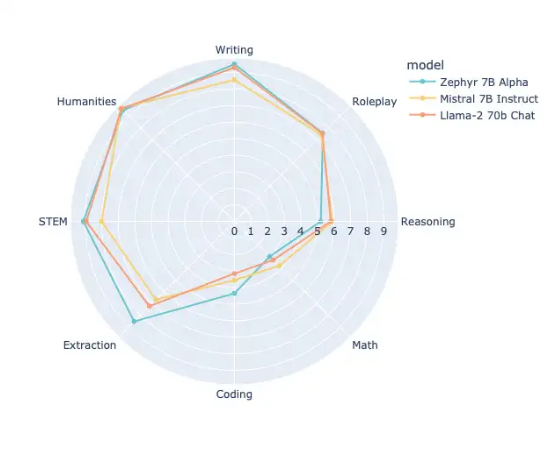
Zephyr 7B 模型公告截图。
而且值得注意的是,RLHF 并非专门用于优化基准性能;目前这种方法的主要用途仍是由人类用户评估模型的“实用性”和“无害性”。
分类专用模型
我上周刚刚在 Packt 生成式 AI 大会上做了演讲,特别强调目前文本模型最典型的用例之一就是内容分类。比如说垃圾邮件分类、文档分类、客户评论分类以及对社交媒体上的有毒言论做标记等等。
根据个人经验,使用“小型”大模型(例如 DistilBERT)完全可以在单个 GPU 上实现非常好的分类性能。
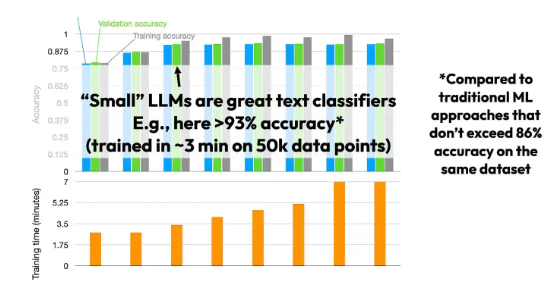
大家可以通过微调,将“小型”大模型用作文本分类器。
我曾经尝试使用“小型”大模型进行过文本分类演练,其中的 Sylvain Payot 源自对现成 Roberta 模型的微调,并成功在 IMDB 电影评论数据集上实现了高于 96%的预测准确率。(作为对比,我在该数据集上训练过的最佳机器学习词袋模型,其准确率也仅有 89%。)
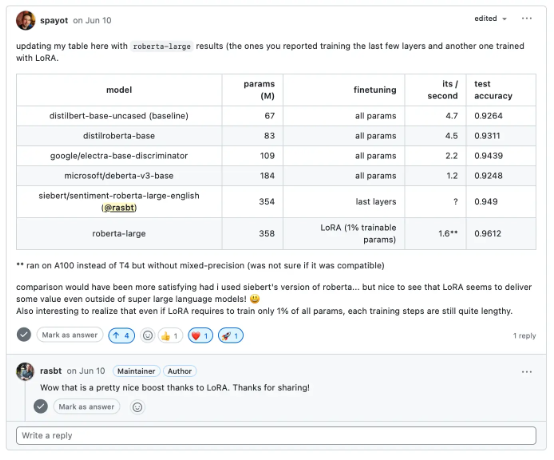
我在深度学习基础课上讨论最佳分类模型。
话虽如此,但目前我还没看到任何将大语言纳入分类场景的尝试或者趋势。大多数从业者在这类场景中仍然使用基于 BERT 的编码器模型或编码器-解码器模型,例如 2022 年推出的 FLAN-T5。这可能是因为此类架构的效果已经足够令人满意。
表格数据集现状
2022 年,我写过一篇《表格数据的深度学习简史》(A Short Chronology Of Deep Learning For Tabular Data),其中涵盖了很多关于深度学习的有趣表格数据方法。而且跟前面提到的分类大模型类似,表格数据集在这一年中同样没有多少进展……也可能是因为我太忙了,没有注意到。
表格数据集示例。
2022 年,Grinsztajn 等人发表了名为《为什么树状模型在表格数据上仍然优于深度学习?》(Why do tree-based models still outperform deep learning on tabular data?)的文章。我相信对于中小型数据集(10k 训练样本)上的表格数据,树状模型(随机森林和 XGBoost)优于深度学习方法这个主要结论仍然正确。
以该结论为基础,XGBoost 在诞生近十年之后发布了 2.0 版本大更新。新版本拥有更高的内存效率、支持不适合内存存储的大型数据集以及多目标树等。
2023 年计算机视觉现状
虽然今年的重头戏都在大语言模型这边,但计算机视觉领域也取得了不少进展。考虑到本文的篇幅已经很长了,这里就不赘述计算机视觉的最新研究成果。具体可以看我在今年 CVPR 2023 大会上发表的这篇文章(https://magazine.sebastianraschka.com/p/ahead-of-ai-10-state-of-computer)。
除了研究之外,与计算机视觉相关的 AI 技术还激发出更多新产品和新体验,而且这一切都在 2023 年内逐步发展成熟。
例如,当我今年参加奥斯汀召开的夏季 SciPy 大会时,就看到一辆真正无人驾驶的 Waymo 汽车在街道上驶过。
而在观看电影时,我也看到 AI 在电影行业中得到愈发普遍的应用。比如《夺宝奇兵 5》中哈里森·福特的去衰老特效,就是由制作团队利用演员旧素材训练出的 AI 模型完成的。
此外,生成式 AI 功能现已广泛纳入知名软件产品当中,比如说 Adobe 公司的 Firefly 2。
2024 年展望
终于来到最后的预测环节,这也是最具挑战的部分。去年,我预计大语言模型有望在文本和代码以外的其他领域迎来更多应用。这个结论基本得到证实,比如说 DNA 大模型 HyenaDNA;另外还有 Geneformer,这是一个由 3000 万单细胞转录组预训练而成的 transformer 模型,用于促进网络生物学的研究。
到 2024 年,相信大语言模型将在计算机科学之外给 STEM 研究带来更加广泛的影响。
另一个新兴趋势,则是随着 GPU 供应不足加之需求旺盛,将有更多企业开发自己的定制化 AI 芯片。谷歌将加大力度开发 TPU 硬件,亚马逊推出了 Trainium 芯片,而 AMD 可能会逐渐缩小与英伟达之间的差距。现如今,就连微软和 OpenAI 也在开发自己的定制化 AI 芯片,唯一的挑战就是各主要深度学习框架能不能为这些新硬件提供全面且有力的支持。
至于开源大模型,其整体水平仍然落后于最先进的闭源模型。目前,最大的开放模型是 Falcon 180B。但这应该不是太大的问题,因为多数人根本承受不了如此巨大模型所占用的海量硬件资源。正如前文所提到,我更希望看到由多个小型子模块组成的开源混合专家模型(MoE)。
我对众包数据集问题也抱持乐观态度,并相信 DPO 的崛起将给先进开源模型带来新的监督微调选项。
原文链接:
https://magazine.sebastianraschka.com/p/ai-and-open-source-in-2023




