
人们常常认为软件研发度量为管理者提供了一把标尺,可以简单丈量出团队乃至个人的表现,但这个隐喻背后其实包含了对研发效能度量的一些误解。
度量分两种,一种是物理度量,一种是统计度量。
物理度量追求极致精确,测定目标物理量的接近绝对精确的数值。从秦始皇统一度量衡,到如今普遍使用的激光测距仪,物理学家已经将距离测定推进到了原子级,把质量测定推进到至少 10 的 27 次方分之一克。
而统计度量是通过观察样本,对目标统计量做出一种近似但科学的推断。比如,父母希望知道孩子的发育情况,那么可以参考国家儿童体格发育调查报告。其中的度量就是卫生部门对各个年龄和地区儿童的身高、体重进行大范围抽样,计算出他们的分布和均值等统计量。
大家经常引用彼得 · 德鲁克的名言,“you can't manage what you can't measure”(你如果无法度量就无法管理),但这里的度量到底是什么样的含义呢?鉴于物理课从初中开始就是主科,而统计学可能是大学里挂科最多的课程之一,大家对度量的朴素理解往往是偏向物理度量的。而当我们建立了上述两类区分,不难看出,管理学里讲的是统计度量——它对所谓“精确”的要求、对结果的解读都与物理度量有本质不同。
当我们谈论研发效能度量时,我们谈论的是统计度量——这是一个对正确理解和管理研发效能有很大影响但却常被忽视的基础性认知。管理学中的度量,包括研发效能度量,追求的不是绝对精确,不是在任何情况下没有反例,而是数据中反映出来的共性规律和潜在问题。对统计度量的使用,需要团队和管理者进行更多系统思考。物理度量简单直接,统计度量则需要辅以分析和调研。
从缺陷度量案例讲起
下面我们通过一个案例,具体理解研发效能度量的统计意义和系统思维。腾讯技术专家茹炳晟老师在文章《研发效能度量引发的血案》中举了一个用“千行代码缺陷率”度量代码质量的反例。

针对这个案例,我们想做以下几点补充:
首先,虽然代码行数和代码质量之间不存在因果性,但这并不会让“度量的大前提”失效,因为相关性足以支撑统计度量的现实意义:我们都希望软件缺陷少,因为缺陷很可能会影响用户使用,阻碍产品的价值实现,带来更多测试和开发成本;而缺陷数量和代码规模相关,所以要想获得对缺陷情况的全面认知,必然会综合考虑两者的关系,否则就会变成“多干多错、少干少错”。
其次,从千行代码缺陷率推导出“我们不相信你能够写出高质量的代码”、“我们不鼓励技术提升阶段的阵痛”和“我们欢迎那些平庸的程序员”这些错误价值观的根本原因,是没能理解统计度量固有的灰度。缺乏度量会使效能问题无法被发现,但度量时套用错误的“理工科思维”,试图依赖单一标尺得出精确结论,甚至是削足适履,可能更加危险。团队如果囿于这样的思维,那么换任何其他的度量指标都是枉然。下一节我们会展开阐述系统思维如何破解这里的问题。
最后,降低统计度量中的噪音,设计制衡机制,对度量指标的合理使用非常重要。茹老师提到深度代码分析指标“开发当量”,可通过计算抽象语法树(AST)的复杂度来估计工作量,消除源代码级别的噪音干扰(如换行、注释等)。如果没有类似制衡机制,有人就容易抵制不住走捷径的诱惑;反过来说,不能因为担心有人“在错误的地方花费更多时间和精力”而不做制衡,因噎废食。实际上,当与系统博弈的成本大于通过正确行为获益的成本,大家就会被引导到正确的行为上。
系统化破解“血案”
代码简洁、缺陷少、可维护性好的大牛被认为是测试不充分、工作不饱和,在技术提升阵痛期的工程师被批代码质量不高,平庸的工程师反而乐得逍遥——与其说这是指标的原罪,不如说是缺乏系统思维导致的恶果。我们经常担心某些度量指标的“负向牵引作用”,但“负向牵引”是如何产生的呢?
让我们用系统思维重新思考一下前面的案例:
平平无奇工程师 A 的千行代码缺陷率虽然落在安全范围,但每需求或每故事点代码行数/当量却异常偏高,说明代码规模有冗余;从缺陷停留时间看,一般需要很长时间才能定位并解决问题,维护成本确实偏高;进而从软件工程质量的角度看,A 的代码中可能有大量可复用逻辑没有被抽象,架构上也有优化的空间;从评审环节看,A 的代码要经过的平均评审轮次也可能偏高——综合起来,虽然工程师 A 不一定会被揪着修复缺陷,但可能需要在设计模式或架构设计方面补补课。
大牛工程师 B 的评价涉及对“缺陷”的多维度理解,如果同时参照后续测试中的故障和线上的事故,那么就能说明 B 的代码质量确实过硬,没有理由被责令加强自测;相反,如果缺少数据支撑,碰上不了解情况的领导反而会百口莫辩。
成长中的工程师 C,因为数据呈现出实际的不足,这本身有什么问题呢?团队如果有抵触“技术提升阶段的阵痛”的文化,只一味掩盖或隐藏“阵痛”,又如何能够改善呢?C 的技术追求需要团队的认可与支持,但在代码缺陷率方面的提升空间同样应该暴露出来。这不仅是对团队工作成果负责,也能为 C 的成长提供反馈和指引。
在复杂体系的度量中,任何单一指标被过度宽泛地解读、被过度简化地归因、被过度粗暴地使用,都是危险的。而控制这类风险,确保度量的牵引力不跑偏,需要通过系统化设计才能实现。数据扮演了驱动的角色,但需要组织动起来,这正是“数据驱动”软件工程的要义。
研发效能度量的系统方法
为了让软件效能度量在合适的土壤中生根发芽,我们建立了一套 MARI(measure-analyze-review-improve,即度量-分析-调研-改进,读作“码睿”)四步循环方法框架,帮助团队避坑。该方法的系统性不仅体现在多维指标共同构成度量体系,也体现在度量和后续实践的紧密结合。度量如果只止步于数字,就很难避免“为了度量而度量,为了提升而提升”的教条主义。
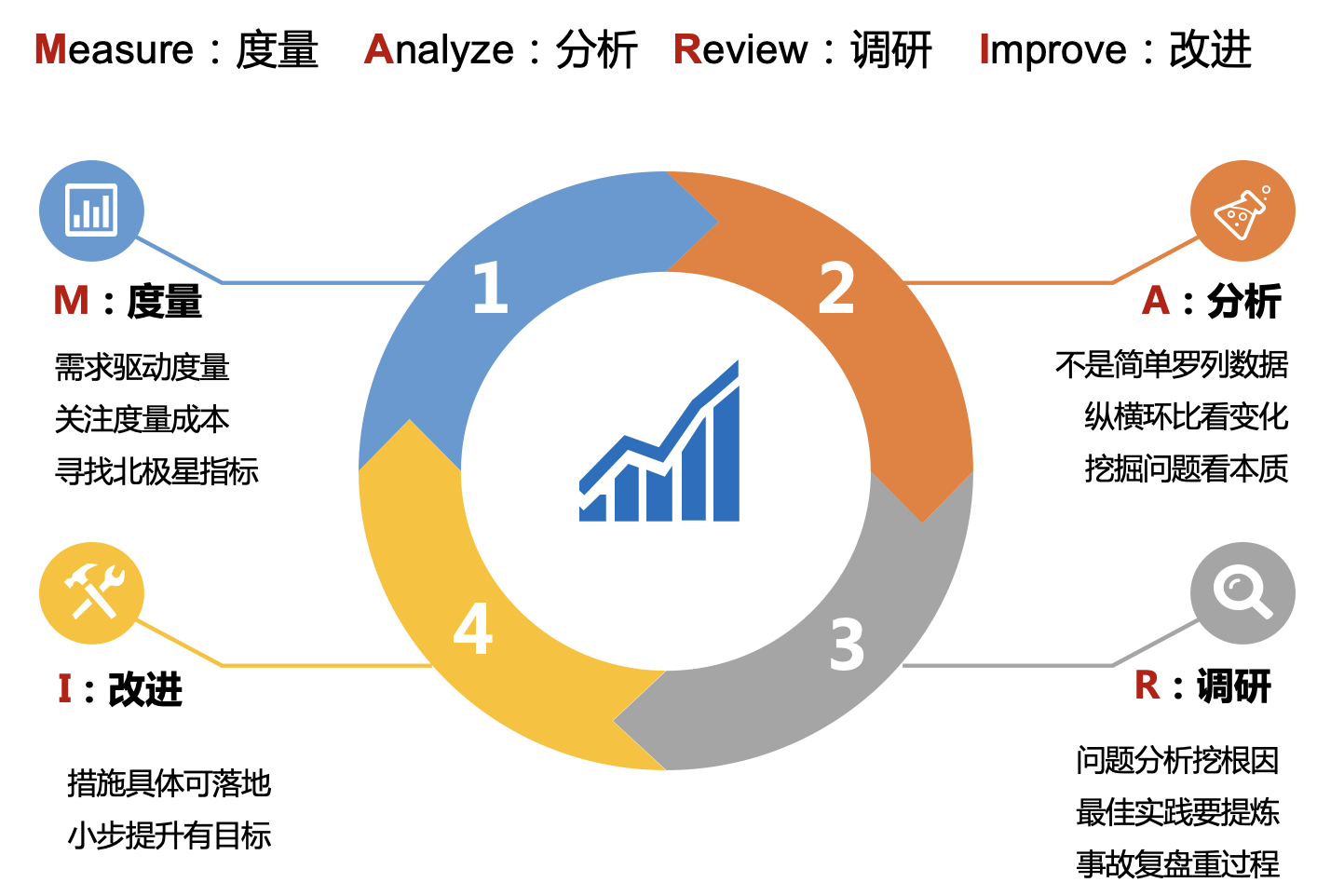
研发效能的度量和提升实践可以归纳为上图的闭环:从特定的认知需求出发,通过度量获得客观数据,通过分析定位潜在的问题,通过调研挖掘问题本质,通过改进解决问题。这样层层推进,持续循环,获取自反馈,才能让度量有响应、有落地。MARI 方法可以帮助团队体系化地认知研发效能度量,避免简单粗暴地误用。
本文阐述了研发效能度量的统计意义和系统思维,分享了我们对这些底层逻辑的理解,以及怎样在完整框架的支持下实现度量的价值落地。后续的几篇内容已经在筹备中,将详细展开具体的度量指标体系和 MARI 实践方法。非常期待与关心研发效能的朋友们多多交流、互相学习!
作者介绍:
任晶磊,清华大学计算机系博士,前微软亚洲研究院研究员,斯坦福大学、卡内基梅隆大学访问学者;现任思码逸 CEO,通过打造基于深度代码分析技术的研发大数据平台,以数据驱动软件工程,助力企业和开发团队提升研发效能。在程序分析、软件工程领域具备多年前沿研究经验,多篇论文发表在 FSE、OSDI 等顶级国际学术会议上,参与过微软下一代服务器架构的设计与实施,也是一位积极的开源贡献者。近期作为专家组成员参与《软件研发效能度量规范》标准编制。




