
微服务是⼀种分布式架构,系统内各部分(服务)被部署为单独的应用程序,并通过某种远程访问协议进⾏通讯。分布式应⽤的挑战之⼀就是如何管理远程服务的可用性和它们的响应。本⽂主要探讨服务的响应时间对系统的影响和应对。
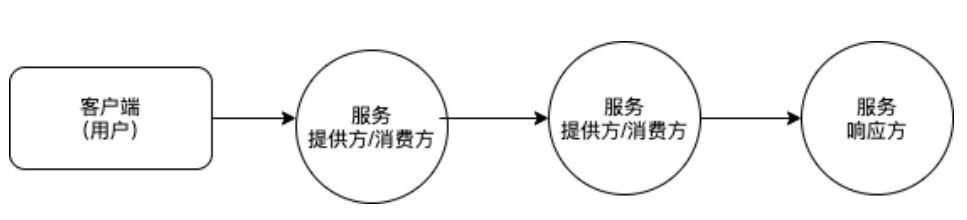
上图是简化的微服务调用链路过程,为清晰阐述三个相关方,图中的客户端被限定为用户端(如移动端应用、浏览器页面等),服务端被区分为服务消费方(网络调用中客户端)和服务提供方(网络调用中服务端)。⼤部分服务既为服务消费方,⼜为服务提供方,如处于调⽤链路中间的业务服务,大概率需要去整合数据,所以通常会同时作为服务消费方和服务提供方,两种资源消耗并存。小部分服务是纯粹的服务提供方,如数据库、缓存、ZooKeeper 等。下⽂先来分析服务响应时间过⻓对资源消耗问题。
资源消耗分析
静态分析
微服务都有⾃身的硬件资源上限,直观来看,响应时间会对资源消耗产⽣直接影响。
服务消费方
协议消耗,每次发起 TCP 连接请求时,通常会让系统选取⼀个空闲的本地端⼝(local port),该端⼝是独占的,不能和其他 TCP 连接共享。TCP 端⼝的数据类型是 unsigned short,因此可⽤端⼝最多只有 65535,所以在全部作为 client 端的情况下,最⼤TCP 连接数 65535。
除端⼝消耗外,发起调⽤的业务进程、线程、协程等待过程中,⽆法释放其所消耗的内存、CPU 等,是服务消费⽅发起调⽤的主要消耗。
服务提供方
协议消耗,主要是建⽴连接的消耗,每接收每⼀个 tcp 连接都要占⼀个⽂件描述符,理论上是 server 端单机最⼤tcp 连接数约为 2 的 48 次方。
业务逻辑消耗。在复杂的业务逻辑、机器资源和⽹络带宽条件下,最⼤并发 tcp 连接数远不能达到理论上限,有时候会发现,单机 1w 并发往往也是⽐较困难。因此,服务提供⽅主要是业务逻辑的⼤量资源消耗,如 CPU、⽹络带宽、磁盘 IO 等。
动态分析
在调⽤持续发⽣且服务提供⽅不及时返回的情况下,未触发性能拐点前,可以简化认为资源的消耗是线性增⻓。微服务发起⼀个请求,会占⽤⼀个空闲的本地端⼝,当然,每个连接所对应的业务处理过程,也会对应消耗内存、IO、CPU 消耗等资源,
简化为如下公式:
RR = RT - QPS * RCPR * Duration- Release * Tinny_T
其中,资源容量(rt, Resource Total )受单机性能影响,可以简化为固定值;单请求消耗资源数(rcpr , ResourceCostPerRequest)受业务影响,也可以简化为固定值。
那么,资源剩余数(RR, Resource Remaining),将受这三个变量影响:每秒请求数(QPS)、请求持续时间 (Duration )和资源释放的速度( Release *Tinny_T)。
在连接不释放的情境下,Release 简化为 0,则上⾯公式简化为:
RR = RT - QPS * RCPR * Duration
可以看到,系统所剩余资源,随 Duration 线性减少,最终被耗尽。
这⾥额外讨论下池化技术,池化技术是⼀个⾮常重要的技术,如连接池可以避免 重新创建连接,在提⾼效率的同时也限制资源不受控的消耗。Redis、数据库 (Mysql、Mongo)等中间件连接驱动⼤都采⽤连接池。如 Golang Mysql 连接池设置 如下:
db.SetConnMaxLifetime(time.Minute * 3)db.SetMaxOpenConns(10)db.SetMaxIdleConns(10)虽然有池化技术,但是如果连接未得到及时释放,且连接池未设置最⼤连接数的情况 下,⽤户不断的请求仍会导致不断创建新连接,急剧消耗资源。限定最⼤连接数最⼤连接数的情况下,造成连接池拒绝连接,或进⾏排队等待,虽然会避免系统宕机风险,但也造成业务⽆法使⽤。对于对外提供实时服务的系统来讲,池化的队列上限, 也可以看作是资源对外提供服务的上限。
设置超时
在设定超时时间后。由于资源释放速度较快,可以假设为⼀旦主动关闭连接,资源⽴即释放。那么,系统内所保留的资源可以简化为设置超时时间(TV,Timeout Value)时间段内连接所保持的资源:
RR = RT - QPS * RCPR * TV
对参数进⾏归⼀简化:
rr = 1 - k * qps * tv
示意图如下:
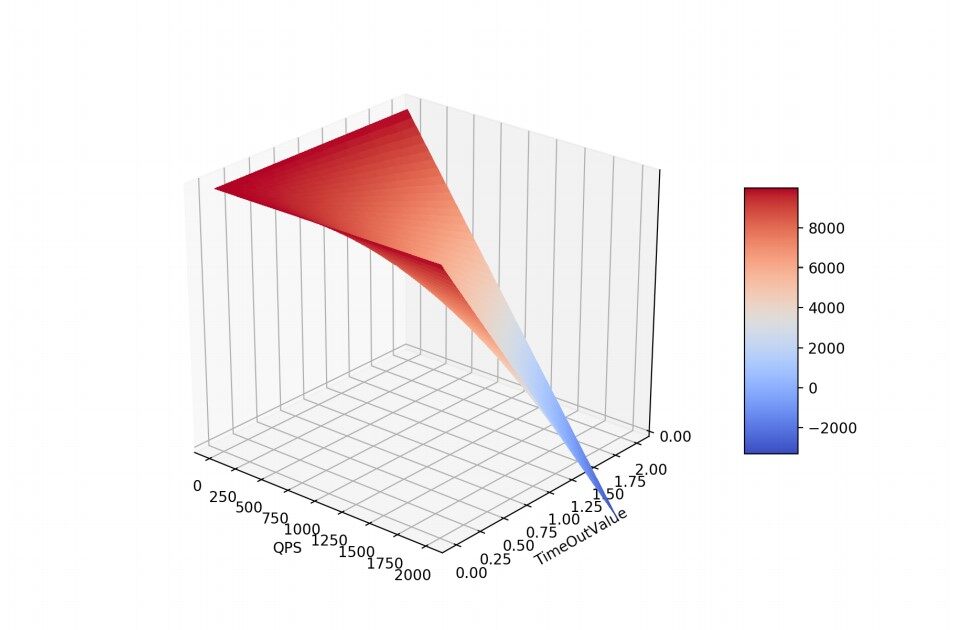
从图中可以看到,在资源总量、QPS 固定、且发⽣超时的情况下,超时时间和资源消耗的速度和成近似线性正⽐。所以从尽快释放消耗资源的⻆度来看,超时时间的设置 应当和 QPS 成反⽐,QPS 越⾼,超时时间应当越短。
超时时间设置治理
从资源静态和动态分析看,我们应当规范设置调⽤超时时间。设置超时时间的意义, 是在极端情况下,采⽤主动的快速失败策略,使得资源消耗与释放资源之间达到平衡,避免调⽤双⽅因资源耗尽⽽宕机。超时时间设置不当引发,容易引发⽣产故障, 线上已经有诸多血的教训。
设置过长
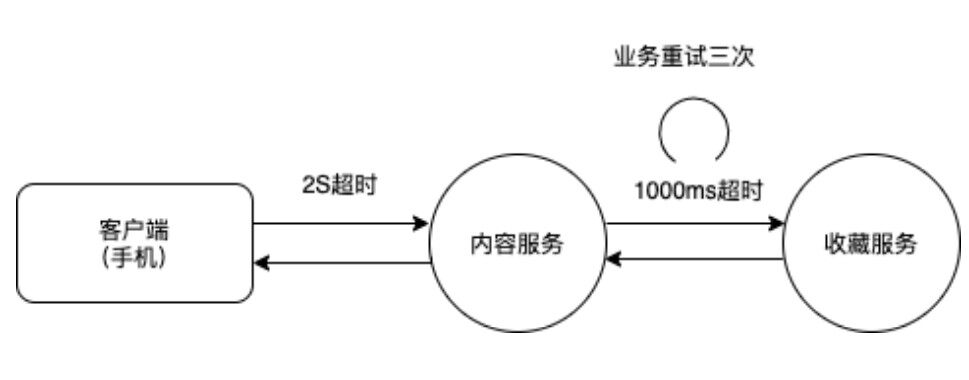
超时时间过⻓容易引起降级失效、系统崩溃、连接池爆满等问题。如下图,内容服务是⾯向⽤户直接提供知识内容的核⼼服务。收藏服务返回⽤户对内容的是否收藏,属于低优先级服务。如果内容服务请求收藏服务设置超时时间过⻓,如图中,虽然设置 1S 超时,但是重试累计 3S,则⼀旦收藏服务发⽣宕机(通常是由于上游 QPS 异常导致),则内容服务会失效,⽆法返回给⽤户数据,甚⾄发⽣串联雪崩。
设置过短
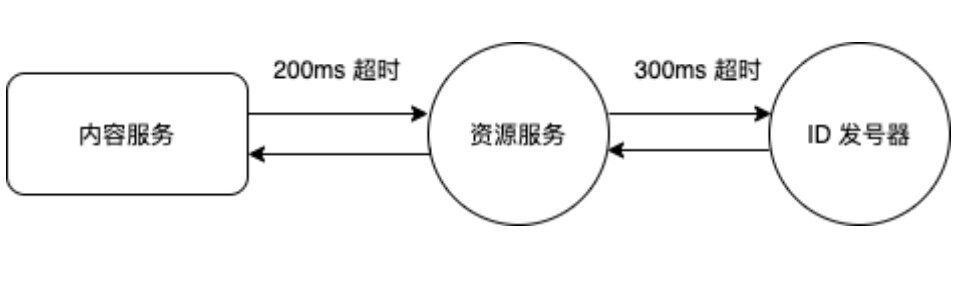
超时时间设置过短,实际⽣产中容易因⽹络抖动⽽告警频繁,造成服务不稳定等⽤户体验问题。如内容服务调⽤资源服务超时时间设置 200ms,资源服务调⽤ID 发号器服务超时时间设置为 300ms,⼀旦⽹络抖动后,资源服务 200ms 即超时返回,资源服务对下游的调⽤ 300ms 超时也⽆实际意义。
合理设定
合理设置超时时间,对系统的稳定来⾔,非常重要,我们可以从以下⻆度来考虑设置值:
⽤户⻆度。微服务最终为服务对象是⽤户,从⽤户交互数据来讲,服务响应时间在 300ms 内最佳, 2000ms 内仍可接受。通常情况下,建议超时的上限值为 2000ms,超过 2000ms 的非重要请求,则有必要被降级处理。
技术⻆度。同时考虑到 TCP 算法中 Delayed ACK + Nagle 算法开启的场景,最小 delay 值 40 ms,建议下限值设定为 50ms; 在 RTT 较⼩的正常网络环境中,TCP 数据包丢包,超时重传的最⼩值,200 ms,因此我们建议 300ms 可以视为超时设置的最佳选择,为重传保留⼀定的余量。
资源消耗⻆度。依据资源消耗的分析,超时时间⻓短应当和 QPS 成反⽐例。我们设定基础值超时设定为 300ms、100QPS,并根据实际 QPS 做调整。
综合⽽⾔,我们简单的给出以下参考值,也可以根据自己的情况设定基准值后进⾏调整:
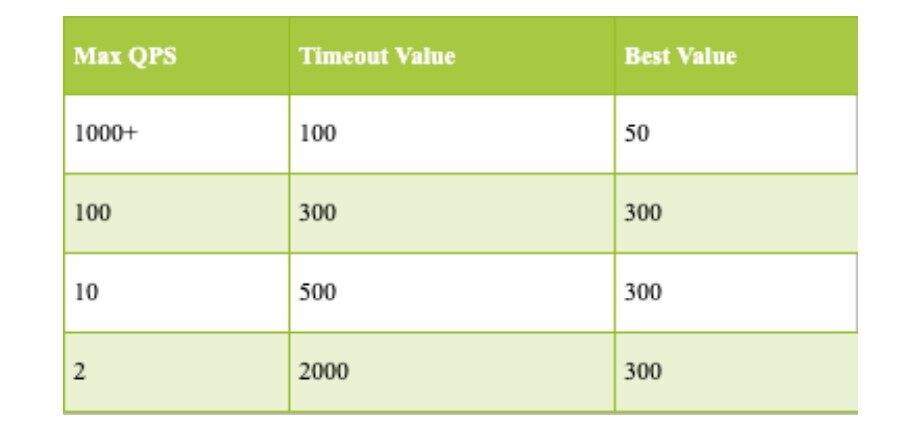
⾃动化设置
前⽂给出了合理设置超时时间的参考值,接下来,我们要考虑如何将超时时间的设置与业务解耦。超时时间的设置,和熔断、限流⼀样,是异常状况下系统的⼀种⾃我保护机制,熔断、限流都已经从业务解耦⾄框架层,如利⽤API ⽹关可以统⼀处理微服务之间调⽤的熔断、限流。超时时间的设置,也可以借助运维体系内其他框架,实现解耦并⾃动设定,如下图。
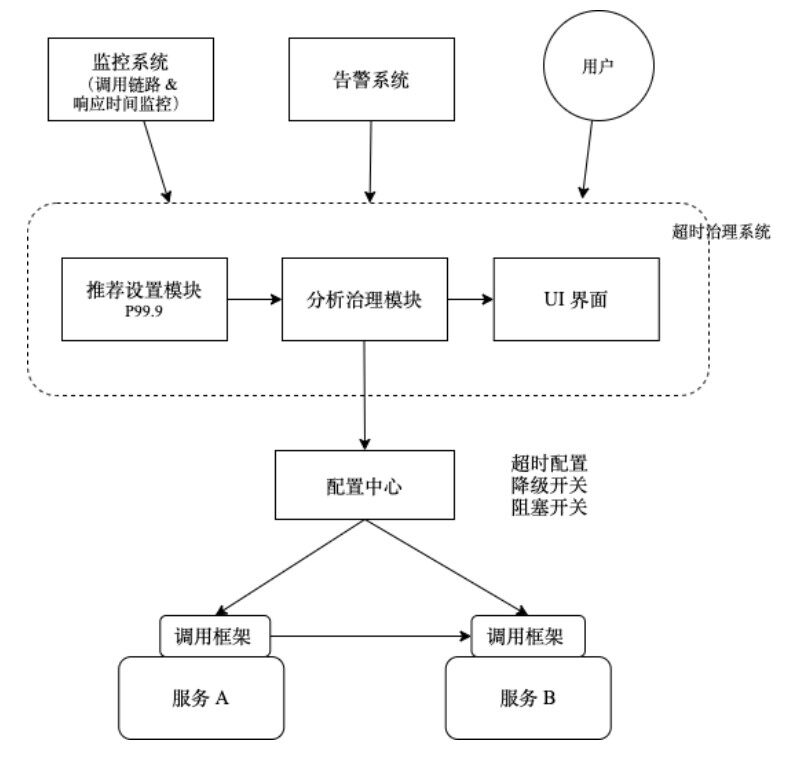
这⾥我们构建了超时治理系统,它⾃身包含三个模块:推荐设置模块,分析治理模块、UI 界⾯。并对外部依赖监控系统(Prometheus 等)、告警系统、配置中⼼(Consul、etcd)、及统⼀的⽹络调⽤框架(Http)。该系统还可以嵌⼊监控系统内 作为其内部功能来实现,或在响应时间监控的基础性进⾏改造。
下⽂对每个模块及依赖进⾏简述:
推荐设置模块
该模块,以响应监控系统的数据为输⼊,产出每⽇/周等固定周期内 P99.9(根据实际 情况来要求)的响应时间,除去异常偏离点,并添加⼀定的 Buffer,⾃动产出 API 调⽤超时时间的设置参考值。
⽇常中,线上正常的响应时间 P99.9 代表该系统稳定状态下的值,超出该值意味着系统出现异常。但必须明确指出,该推荐值可能并⾮理想状态下的超时设置值。
分析治理模块
由于服务响应时间可以粗略认为是对资源的消耗量成正⽐,分析治理模块依赖监控系 统产出的服务响应时间、流量峰值、以及对应的系统资源⽔位,对响应时间及超时时 间设置进⾏分析,输出最终的设置值后,通过配置中⼼下发⾄调⽤框架。
从简处理的话,可以基于上⽂推荐的 QPS 和 超时时间设定值,来进⾏预警提示偏离点。
更加精细化的处理,可以按接⼝的响应时间 * QPS 来均摊服务资源,对于明显超出均摊值的点,进⾏异常提示。
反馈上下游调⽤链路中,下游超时时间设置⾼于上游超时时间的异常点。
收集线上真实告警数据,并依据策略对持续发⽣的超时问题进⾏汇总反 馈。如产⽣超时异常周报等。
UI 界面
通过管理 UI 界⾯,以微服务为单位,对其调⽤情况,展示分析治理模块异常点,以及告警问题汇总。赋予使⽤者进⾏⼈⼯调整超时时间⼊⼝,并以⼈⼯设置为⾼优先级。
配置中心
超时时间设置的下发通常有配置中⼼来实现,配置中⼼有⾃身的⾼可⽤和⼀致性保障,同时有 Watch 机制来确保及时下发配置⾄调⽤框架使⽤。
调用框架
⽹络调⽤框架,接受从配置中⼼下发的配置并实现指定的⾏为,与超时设置⾏为相关的配置有三类,降级、阻塞、设置超时时间。
降级,即降级开关,开关下发后,对依赖服务直接进⾏降级,不再进⾏调⽤,该状态在紧急状态或重⼤活动时候使⽤。
阻塞开关,服务调⽤内部框架会按照设定超时时间进⾏阻塞,该能⼒⽤于寻找在当前超时时间设置下,系统性能瓶颈。通过压测,为重要服务线上超时时间设置提供最真实的数据。
超时配置,由超时治理系统所最终输出的超时配置,会由配置中⼼⾃动下发⾄各个服务,并在调⽤过程中使⽤。
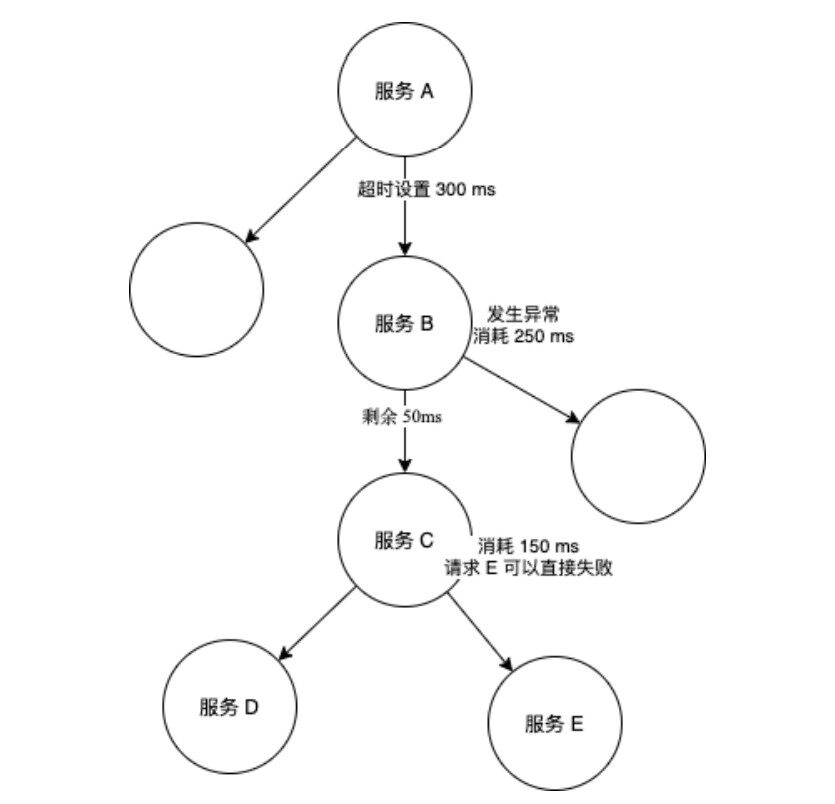
另外,调⽤框架还应当实现,超时时间⾃动递减机制,如上游每次发起请求,到下游开始发起请求前,如果剩余可⽤时间已经为 0 ,则应当主动失败,参考下图。
告警和优化
超时时间设置是系统的第⼀重保护,超时时间设置后,需要配合超时告警和响应时间优化,才能形成构成的完整的系统⾃我修复的闭环。
告警
超时告警,会直接反馈超时设置的效果,⽽且也是⻓耗时请求被超时设置拦截后,系 统⾃我保护的下⼀个重要环节。系统调⽤发⽣超时告警,可以通过运维体系监控告警 让⼈⼒及时介⼊排查问题,以避免更⼤损失。
超时告警通常只是告警监控系统⾥⼀个⼦监控项,从实际⽣产中来看,超时告警 往往也是最频繁发⽣的告警,超时告警如何在保障灵敏度的同时,避免过渡告警,需 要专⻔考虑。对此,我们建议从范围和时间两个维度来区分超时告警:
从范围来看,可以将局部性超时和⼤⾯积超时告警区分对待:
大面积告警,紧急⼈⼒介⼊,通常是运维⽹络故障等原因,可以结合⽹络 监控来具体定位。
局部小范围告警,作为⾮紧急重要事情处理。
从时间来看,将波动性和持续性超时告警区分对待:
持续性问题,⼤概率是业务问题,紧急人力介入从而避免业务发⽣重⼤损失。
波动性问题,根据出现频率,排查隐藏线上问题并解决,作为⾮紧急重要事情处理。
对于如何定义短暂性的波动,可以由运维评估出⽇常⽹络抖动平均抖动时⻓ ,超过⽹ 络波动的时⻓⼀定阈值后,则触发紧急告警。如果运维体系资源充⾜,建议将超时告 警波动性监控细化到具体接⼝。
优化
响应时间优化是超时治理的治本措施。理想情况下,服务的响应时间当然是越快越 好,但也要和当前业务发展相匹配,要保障系统稳定,也要避免为优化响应时间耗费过多成本。
原则上,应当依据超时设置时间来优化响应时间,⽽⾮以响应时间来决定超时时 间。服务超时,可能是应⽤层代码错误、⽹络丢包,服务器⾃身硬件异常、或⼤量数 据库操作慢查询等问题导致。可以采⽤的措施有:
排查异常问题,如排查业务超时重试次数、排查错误⽇志、排查库表操作是否有慢查询等。
调整软件设计架构,提⾼业务响应速度,如使⽤缓存、拆分调整架构减少调⽤层级等。
调整运维⽅式,如发版引发的告警,则可以从调⽤框架的重试中进⾏解决,也可以依赖滚动发布进⾏解决。
纵向或横向扩充资源,提⾼单机性能,如 CPU、内存,以期望在性能拐点达到前获得消耗与释放平衡。横向在降低单机 QPS 的同时,适当增加超时时间。
总结
单体服务内部只有对库、Redis 等⽹络调⽤,相⽐之下,微服务系统内部发⽣的⽹络调 ⽤频度呈⼏何倍数增加。所以⽹络超时参数的设置治理,在微服务体系治理体系内也 ⾮常重要。
本⽂从动态和静态资源⻆度分析了超时设置对系统的影响,让我们从原理的⻆度 看到超时合理设置的必要性,它是避免系统在极端情况下发⽣串联性雪崩的有效措 施。在以往开发过程中,对于这⼀重要的参数,通常是由各位开发⼈员凭⾃身经验来 设置,由于开发者⽔平经验参差不⻬,设置的超时时间也不⼀定合理。这会导致在系 统在异常情况下容易处于串联雪崩的危险境地(如⼤型活动⾼流量⾼并发,个别⾮核 ⼼服务宕机,导致整个活动失败)。⽽通过⾃动化设置,将超时的设置解耦到框架层 来解决,可以由开发经验差异导致的不合理设置,还可以实现⼀些特殊功能,如探究 服务在超时状态下极限性能。
超时时间设置完成后,超时的治理,核⼼还在于对系统或者架构的优化。我们再 次阐述下设置超时的原则,应当优化服务响应时间,来满⾜合理的超时设置时间,⽽ ⾮以响应时间来决定超时时间。
关于作者:
奇正,曾在奥多比 、百度任高级工程师,现任某互联网公司后端负责人,先后从事过 C++、Android、Golang 的开发工作。




