
最近,谷歌宣布正式发布Hive-BigQuery Connector,简化 Apache Hive 和 Google BigQuery 之间的集成和迁移。这个开源连接器是一个 Hive 存储处理程序,它使 Hive 能够与 BigQuery 的存储层进行交互。
这个新增选项支持在 Hive 中使用类 SQI 查询语言HiveQL对 BigQuery 进行读写。这样,数据工程师就可以在不移动数据的情况下访问和查询 BigQuery 数据集,而 BigQuery 的用户则可以利用 Hive 的工具、库和框架进行数据处理和分析。谷歌云解决方案架构师Julien Phalip写道:
Hive-BigQuery 连接器实现了 Hive StorageHandler API,使 Hive 工作负载可以与 BigQuery 和 BigLake 表集成。所有的计算操作(如聚合和连接)仍然由 Hive 的执行引擎处理,连接器则管理所有与 BigQuery 数据层的交互,而不管底层数据是存储在 BigQuery 本地存储中,还是通过 BigLake 连接存储在云存储桶中。
Apache Hive是一个构建在 Hadoop 之上的流行的分布式数据仓库选项,它允许用户在大型数据集上执行查询。BigQuery是谷歌云提供的无服务器数据仓库,支持对海量数据集进行可扩展的查询。为了确保数据的一致性和可靠性,这次发布的开源连接器使用 Hive 的元数据来表示 BigQuery 中存储的表。
该连接器支持使用 MapReduce 和 Tez 执行引擎进行查询,在 Hive 中创建和删除 BigQuery 表,以及将 BigQuery 和 BigLake 表与 Hive 表进行连接。它还支持使用 Storage Read API 流和 Apache Arrow 格式从 BigQuery 表中快速读取数据。
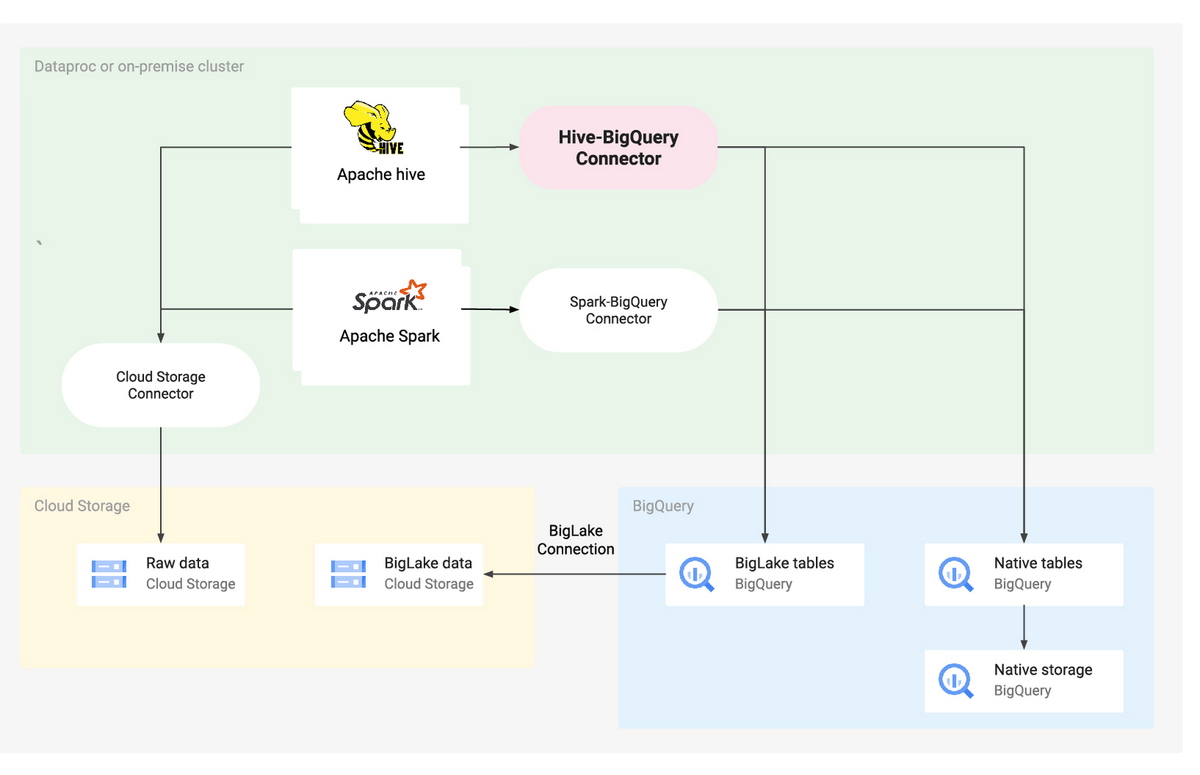
图片来源:谷歌数据分析博客
根据谷歌云的说法,Hive-BigQuery 连接器可以在以下场景中为企业提供帮助:确保迁移过程中操作的连续性,将 BigQuery 用于需要数据仓库子集的需求,或者保有一个完整的开源软件技术栈。
借助BigQuery Migration Service,谷歌提供了BigQuery批处理SQL转换器和交互式SQL转换器支持,可以将 Hive 查询转换为 BigQuery 特有的兼容 ANSI 的 SQL 语法。Phalip 解释说:
这个新的 Hive-BigQuery 连接器提供了一个额外的选项:你可以保留原来的 HiveQL 方言的查询,并继续在集群上使用 Hive 执行引擎运行这些查询,但让它们访问已迁移到 BigQuery 和 BigLake 表的数据。
这不是谷歌为分析不同的数据集并减少数据转换而发布的第一个开源连接器:Cloud Storage Connector实现了 Hadoop Compatible File System(HCFS) API,用于读写 Cloud Storage 中的数据文件,而Apache Spark SQL connector for BigQuery则实现了 Spark SQL Data Source API,将 BigQuery 表读取到 Spark 的数据帧中,并将数据帧写回 BigQuery。
Hive-BigQuery 连接器支持 Dataproc 2.0 和 2.1。谷歌还大概介绍了有关分区的一些限制。由于 Hive 和 BigQuery 的分区方式不同,所以该连接器不支持 Hive PARTITIONED BY 子句。但是,开发人员仍然可以使用 BigQuery 支持的时间单位列分区选项和摄入时间分区选项。
感兴趣的读者,可以从GitHub上获取该连接器。
原文链接:
https://www.infoq.com/news/2023/07/google-hive-bigquery-connector/




