
本文最初发表于 Medium 博客,经原作者 Anupam Chugh 授权,InfoQ 中文站翻译并分享。
2021 年才刚刚开始,在过去的一年中,机器学习领域中发生了很多事情。
本文介绍了最流行的开源研究项目、演示和原型。其范围从照片编辑到自然语言处理,再到使用“无代码”训练模型,我希望这些能够激发你去构建令人难以置信的人工智能产品。
1、Background Matting v2
https://github.com/PeterL1n/BackgroundMattingV2
Background Matting v2(背景抠图)从广受欢迎的 The World is Your Green Screen(世界是你的绿幕)开源项目中汲取灵感,展示了如何实时删除或更改背景。它提供了更好的性能(4K 时为 30fps,FHD 时为 60fps),并可与流行的视频会议应用 Zoom 一起使用。
该技术使用附加捕获的背景帧,并将其用于恢复 alpha 哑光和前景层。采用两个神经网络对高分辨率图像进行实时处理。
假如你想把某人从视频中移除,同时保留背景,这个项目绝对有用。

2、SkyAR
https://github.com/jiupinjia/SkyAR
这是一个神奇的项目,它能对视频中的天空进行替换和协调,并能在视频中自动生成具有逼真和戏剧性风格的天空背景,而且风格可控。
这个以 Pytorch 为基础的项目使用了 pytorch-CycleGAN-and-pix2pix 项目中的部分代码,使用了天空抠图,通过光流进行运动估计,以及图像混合,实时提供视频艺术背景。
上面提到的开源项目在电影和视频游戏中有惊人的潜力,比如增加雨天、晴天等等。

3、AnimeGAN v2
https://github.com/TachibanaYoshino/AnimeGANv2
将照片卡通化总是一个有趣的机器学习项目。不是吗?
这个项目 AnimeGAN v2 是 AnimeGAN 的改进版本。具体来说,它在保证防止高频伪影产生的同时,将神经风格转移与生成对抗网络(GAN)结合起来完成任务。

4、txtai
https://github.com/neuml/txtai
人工智能精准化的搜索引擎和问答聊天机器人永远是当前的需求。而这正是这个项目所要做的。
txtai 利用 sentence-transformers、transformers 和 faiss,为上下文搜索和提取式问题回答构建了一个人工智能引擎。
实际上, txtai 支持构建用于相似性搜索的文本索引,并基于抽取式创建问题回答系统。

5、Bringing-Old-Photos-Back-to-Life
https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life
接下来是微软最新的照片修复项目,可以自动修复受损照片。
具体来说,它通过在 PyTorch 中的深度学习实现,利用划痕检测、人脸增强等技术,修复遭受复杂退化的老照片。
根据他们的研究论文:“我们训练了两种变自编码器(variational autoencoders,VAEs),它们分别将旧照片和干净照片转换到两个潜在空间。而这两个潜在空间之间的转换是通过合成的配对数据来学习的。由于紧凑的潜在空间中的域隙是封闭的,所以这种转换能很好地泛化到真实照片中。此外,为了解决一张旧照片中的各种混杂退化问题,我们设计了一个全局分支和一个局部分支,该分支包括一个局部非局部分块,针对结构化缺陷,如划痕和尘点,以及一个局部分支,针对非结构化缺陷,如噪声和模糊。”
从下面的演示中可以看出,该模型的性能明显优于传统的技术方法。

6、Avatarify
https://github.com/alievk/avatarify
Deepfake 项目已经横扫机器学习和人工智能社区。这个项目展示了一个典型的示例,它允许你在实时视频会议应用中创建照片般逼真的头像。
主要是利用 First Order Model(一阶模型)来提取视频中的动作,然后利用光流把它们应用到目标的头像上。通过这种方式,你可以在虚拟的摄像机上生成虚拟的人物,甚至可以将经典画作做成动画。从伊隆·马斯克到蒙娜丽莎,你可以模仿任何人来玩耍!

7、Pulse
https://github.com/adamian98/pulse
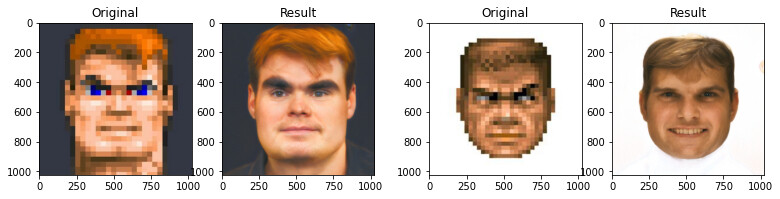
这是一个人工智能模型,它显示了如何从一个低分辨率的人脸图像中生成一个逼真的人脸图像。
PULSE,即 Self-Supervised Photo Speampling via Latent Space Exploration of Generative Models(通过生成模型的潜在空间探索进行的自监督照片上行采样)的缩写,它提供了一个超分辨率问题的替代公式,这个问题基于创建真实的超分辨率图像,同时也正确地缩小比例。
8、pixel2style2pixel
https://github.com/eladrich/pixel2style2pixel
基于研究论文《风格编码:用于图像到图像转换的 StyleGAN 编码器》(Encoding in Style: a StyleGAN Encoder for Imag-to-Image Translation),该项目使用 Pixel2Pixel 框架,其目的是使用相同的架构,以解决广泛的图像到图像转换任务,从而避免任何可能的局部性偏差。
在新一代编码网络的基础上,这个网络可以被训练成将人脸图像与正面姿势对齐,条件图像合成,并创建超分辨率图像。
从使用漫画家的作品生成近乎真实的人物,到将草图或人脸分割转换为照片般逼真的图像,你可以用它做的事情太多了。

9、igel
https://github.com/nidhaloff/igel
也许是因为预算问题或者缺乏清晰的愿景,但是对于创业公司来说,找到有机器学习经验的人总是一项挑战。更何况这方面的工作一直都在不断进步。
所以最近无代码机器学习平台大行其道,谷歌、苹果等公司也推出了自己的快速模型训练工具集。
这种有趣的开源机器学习项目可以让你不用编写代码就可以训练 / 拟合、测试和使用模型。尽管 GUI 拖放版本仍然处于开发阶段,但是通过该项目的命令行工具,你可以完成以下许多工作:
//train or fit a modeligel fit -dp 'path_to_your_csv_dataset.csv' -yml 'path_to_your_yaml_file.yaml'//evaluateigel evaluate -dp 'path_to_your_evaluation_dataset.csv'//predictigel predict -dp 'path_to_your_test_dataset.csv'此外,还可以使用单独的命令 igel experiment 将各个阶段结合起来:训练、评估和预测。更多细节,请参考这里的文档。
10、Pose Animator
https://github.com/yemount/pose-animator/
最后,我们有一个网络动画工具。基本上,这个项目利用 PoseNet 和 FaceMesh 里程碑式的成果,通过利用一些 TensorFlow.js 模型,让 SVG 矢量图像活起来。
你可以通过以下方式将自己的设计或骨架图像制作成动画。

作者介绍:
Anupam Chugh,Anupam Chugh,Android 和 iOS 开发者、拥有超过 200 万阅读量的作家。视技术和代码为毕生追求。
原文链接:




