
目前, Freewheel 核心任务系统采用微服务架构,在降低服务间耦合的同时,也对每个服务的鲁棒性提出了更高的要求。每个模块作为独立服务部署,都可能面临诸如性能瓶颈、内存泄露、Goroutine 泄漏等问题。在微服务化的环境中,快速准确定位具体服务的性能等问题是我们急需解决的痛点,Profiling 往往是解决这类问题的利器。本文主要介绍 Freewheel 的 Profiling 实践,供读者参考。
Golang pprof 解析
在软件工程中,Profiling 是指在程序的执行过程中,收集能反映程序执行状态的数据,例如程序执行所占用内存、特定指令的使用情况或函数调用的频率和持续时间,等等。Profiling 最常见的应用就是帮助应用程序定位和优化性能问题。
pprof 是 Golang 内置的 Profiling 工具,它主要支持以下几个维度的 Profiling:
cpu:CPU 分析,按照一定的频率采集所监听的应用程序的 CPU 使用情况。
heap:内存分析,记录内存分配情况。用于监控当前和历史内存使用情况,辅助检查内存泄漏。
threadcreate:反映系统线程的创建情况。
goroutine:当前所有 goroutine 的堆栈跟踪。
block:阻塞分析,记录 goroutine 阻塞等待同步的位置,可以用来分析和查找死锁等性能瓶颈。
mutex:互斥锁分析,记录互斥锁的竞争情况。
pprof 启用方式
针对不同的服务类型和场景,pprof 有多种启用方式。
进程 Profiling
非常驻进程
可以通过如下方式引入 runtime/pprof 库,在进程退出后,就可以获得 Profiling 数据:
import "runtime/pprof"func main() { f, err := os.Create("path/to/cpu.out") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() ...常驻进程
可以引入 net/http/pprof 来通过特定的 http 接口获得 Profiling 数据,这个库会注册如下的路由:
http.HandleFunc("/debug/pprof/", Index)http.HandleFunc("/debug/pprof/cmdline", Cmdline)http.HandleFunc("/debug/pprof/profile", Profile)http.HandleFunc("/debug/pprof/symbol", Symbol)http.HandleFunc("/debug/pprof/trace", Trace)只需要在代码里启动一个 http server,就可以对外暴露出 pprof 信息,然后使用 go tool pprof 命令就可以通过这些路由获得数据:
go tool pprof http://localhost:6060/debug/pprof/profile # 30-second CPU profilego tool pprof http://localhost:6060/debug/pprof/heap # heap profilego tool pprof http://localhost:6060/debug/pprof/block # goroutine blocking profile函数 Profiling
Golang 的 go test -bench 命令已经集成了 pprof 功能,只要针对特定函数编写 Benchmark 测试函数:
// in source filefunc foo(){}// in test filefunc Benchmark_foo(b *testing.B) { for i := 0; i < b.N; i++ { foo() }}使用如下指令可以在不侵入原有代码的情况下获得 foo 函数 Profiling 数据:
go test -benchmem -cpuprofile=path/to/cpu.out -bench '^(Benchmark_foo)$' .可视化
有了 Profiling 数据,就可以借助各种工具进行分析了。Profiling 数据的可视化支持火焰图、函数调用图、使用 top N 打印出占用 CPU/ 内存最多的函数列表,等等。其中最直观的展示方式就是火焰图了。火焰图 (Flame Graph) 是性能优化大师 Bredan Gregg 创建的一种性能分析图标,因为它的样子近似火焰而得名。
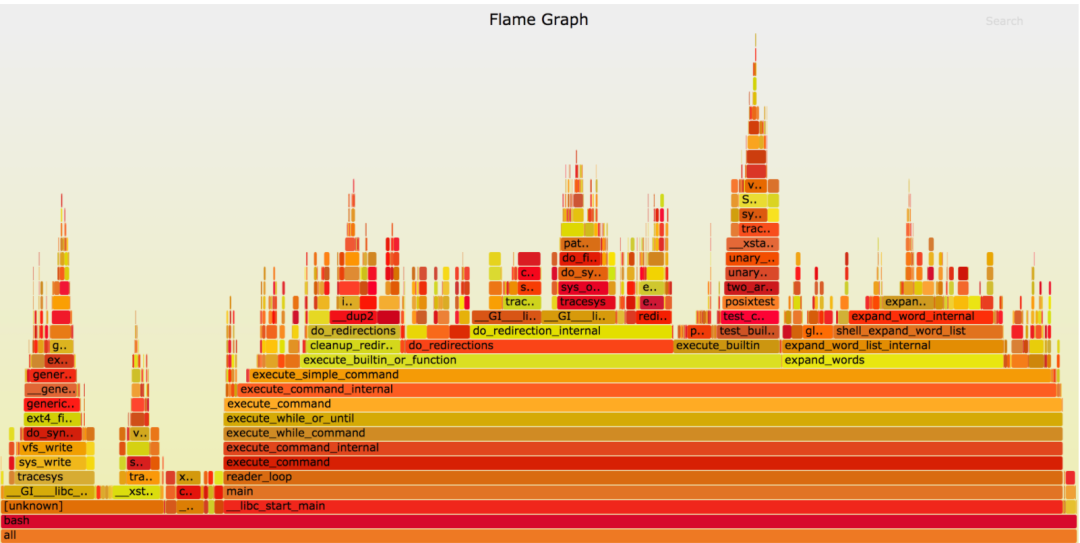
X 轴表示抽样数,如果一个函数在 X 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。
Y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
火焰图支持搜索,支持在每个函数上点击缩放,从而方便对 Profiling 结果进行精细分析。
Profiling 在微服务应用下的实践
Profiling 是大型应用程序无法避免的重要任务。Profiling 有助于我们理解 CPU 和内存密集型代码,帮助我们快速准确地定位性能 / 内存等问题,以便更好地优化代码。为此我们构建了完善的 Profiling 组件,并且集成到了现有的运维管理平台。
痛点分析
对线上服务做 Profiling 困难重重:由于安全需要,本地环境和线上服务之间会设置网络隔离,导致我们并不能在本地环境连通线上服务进行 Profiling,而直接在线上服务器做 Profiling 也比较困难,首先需要申请各种操作权限登录线上服务器,然后安装 pprof、graphviz 工具生成可视化的 Profiling Report,流程比较繁琐复杂。而线上环境由于采用 docker 部署,也无法直接使用浏览器查看可视化的 Profiling Report。
触发 Profiling 的方式单一:一般而言,我们是在性能测试时或者生产环境出现问题的当下,手动发送 Profiling 请求。但是这种方式并不能有效应对线上的突发状况,自动生成 Profiling Report。
不方便追踪和对比 Profiling 的结果:对于某个微服务而言,当我们检测到线上服务的性能下降时,会希望跟性能下降之前的 Profiling Report 做对比,以便快速定位性能下降的原因。现在为微服务生成的 Profiling Report 一般存储在开发人员本地环境,缺乏统一的管理,不方便日后追踪和对比。
架构设计
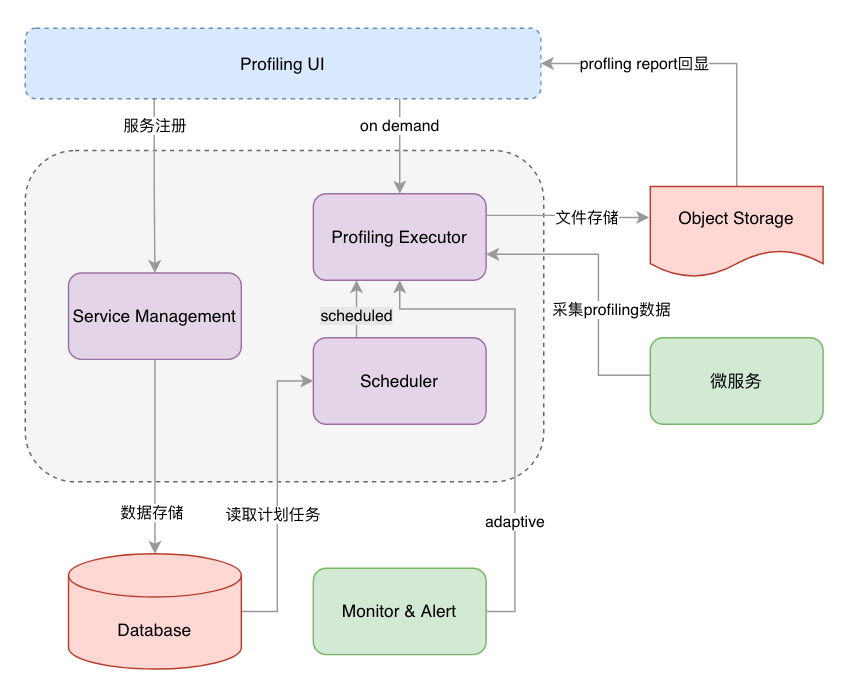
Profiling 组件由前后端两个部分构成。
前端:提供一个完善的 UI 用于微服务的注册、Profiling 任务的编排和触发,以及 Profiling Report 的展示;
后端:主要由三个组件构成:
a. Service Management 即服务管理,用于注册与管理微服务的基础信息 (地址,端口等);
b. Scheduler 即调度程序,通过定时器执行数据库里的计划任务;
c. Profiling Executor 即 Profiling 执行器,采集微服务的 Profiling 数据,并且生成 Profiling Report 并将文件进行归档存储。
具体的架构图如下所示:
功能设计
基于以上的痛点分析, Profling 组件设计了如下功能模块:
服务注册与管理
为微服务做 Profiling,首先我们需要知晓服务的地址,端口号和 Profiling 服务的端口号。Profiling 组件 Service Management 模块提供微服务信息的注册功能。
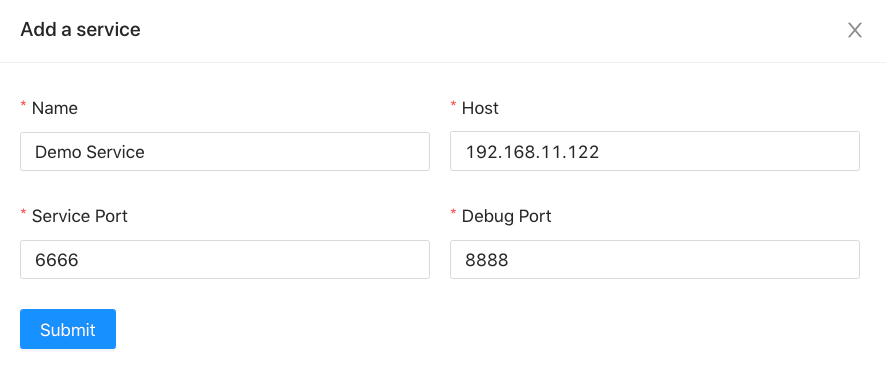
任务编排
在任务编排模块,用户可以从 Profiling 类型以及触发 Profiling 的方式两个维度来进行任务的设置与编排。目前系统提供的 Profiling 功能已经覆盖了关键的四项数据指标以及三种常用的触发机制。
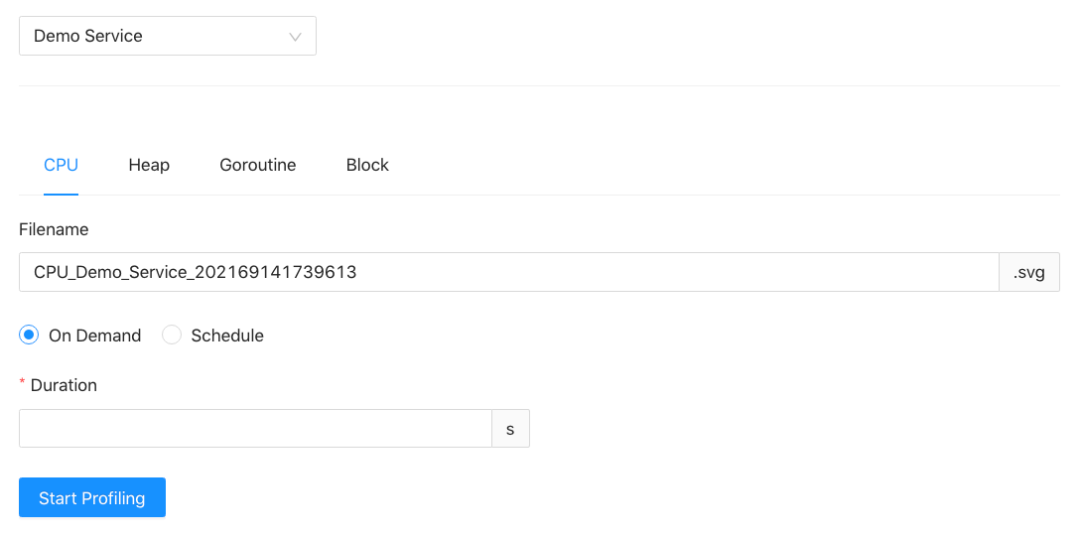
支持生成多个维度的 Profiling Report。Profiling 组件现在支持四种类型的 Profiling:CPU Profiling、Heap Profiling、Goroutine Profiling、Block Profiling,并且能够很容易地扩展支持其他类型的 Profiling。
支持多种方式触发 Profiling:即时开启、计划任务、自适应 Profiling
a. 即时开启 (On Demand Profiling)
这种情况适用于用户观测到了服务的异常情况或者正在进行性能测试,需要立即触发 Profiling,并且生成 Profiling Report 进行分析。
b. 计划任务 (Scheduled Profiling)
如果我们想对流量高峰时的服务性能进行分析,可以首先基于日志信息对历史流量情况进行分析,预测流量高峰出现的时间点,然后可以 schedule 到这个时间点自动触发 Profiling,生成 Profiling Report。
c. 自适应 Profiling (Adaptive Profiling)
我们知道,在线上环境开启某些类型的 Profiling 会对性能造成一些损失。所以, 我们一般只会在服务出现相应问题的时候才会触发 Profiling。当线上服务出现突发状况,譬如性能骤降、goroutine 或者内存暴涨时, 我们首先要做的就是快速修复,譬如服务重启、服务降级、回滚等,而不是保存现场,手动触发 Profiling,然后根据 Profiling Report 详细分析故障原因。上面介绍的两种 Profiling 方案并不能及时 catch 到线上的突发状况,自动触发 Profiling。所以,为了既减少性能损耗,避免不必要的 Profiling,同时又能捕捉到线上的突发状况,我们提出了一种基于监控的自适应的弹性 Profiling 方案。
这里所说的自适应性体现在两个方面,一方面是指当特定的监控指标出现异常时,自动触发 Profiling;另一方面是指,根据监控指标的不同,触发不同类型的 Profiling。例如,当监控系统监控到性能下降到特定阈值时,自动触发 CPU Profiling;当监控到内存涨到特定阈值时,自动触发 Heap Profiling;当监控到 Goroutines 数目涨到特定阈值时,自动触发 Goroutine Profiling 等。当然触发 Profiling 的条件可以自定义,也可以支持多种条件的组合。
具体如下图所示:
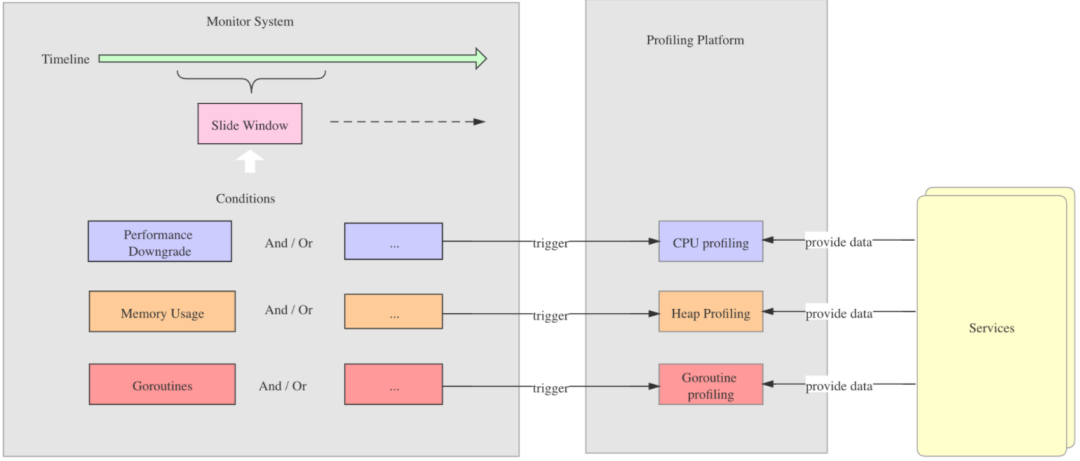
具体的实现方式是 Profiling 组件与监控系统集成,由 Profiling 组件提供一套能够触发 Profiling 的 API,在监控系统检测到具体指标异常时直接调用 API,触发 Profiling, 生成 Profiling Report。
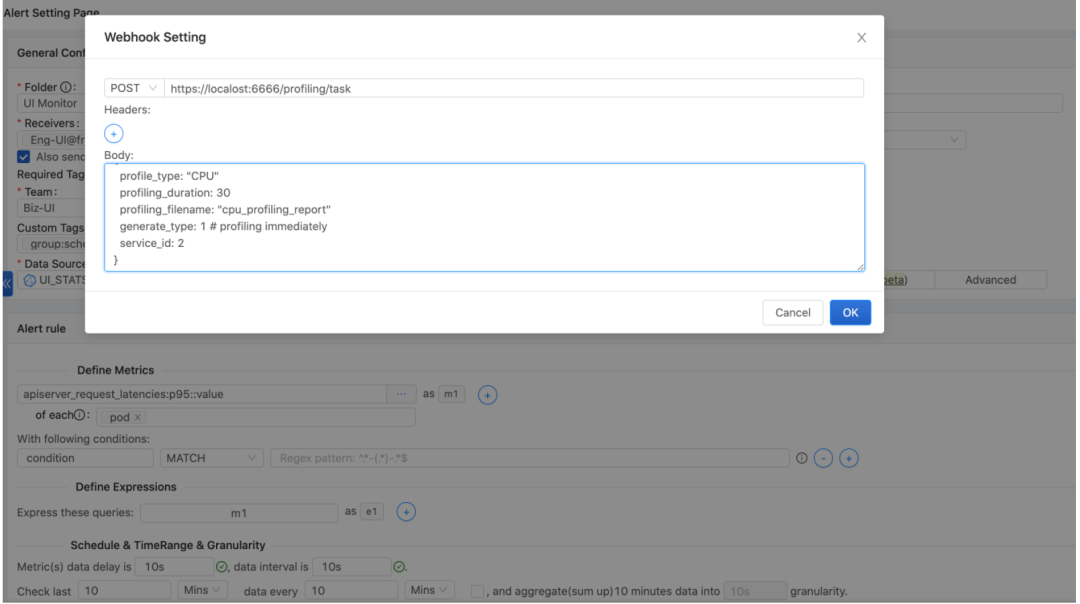
Freewheel 目前有两套主流监控系统。一套基于 ElastAlert,一套是自主开发的 pqm 监控组件。下面是与 ElastAlert 监控系统的集成。ElastAlert 支持在报警发生之后触发相关回调,使得我们能够借此能力通过 HTTP Post 接口调用 Profiling 组件 API 执行 Profiling 操作。
alert: posthttp_post_url: "http://localhost:6666/api/Profiling/task"http_post_payload: profile_type: "CPU" Profiling_duration: 30 Profiling_filename: "demo_service_cpu_flamegraph" generate_type: 1 # Profiling immediately service_id: 2与 Freewheel 自主研发的监控系统 pqm 集成也是采用类似的方式:
报表管理
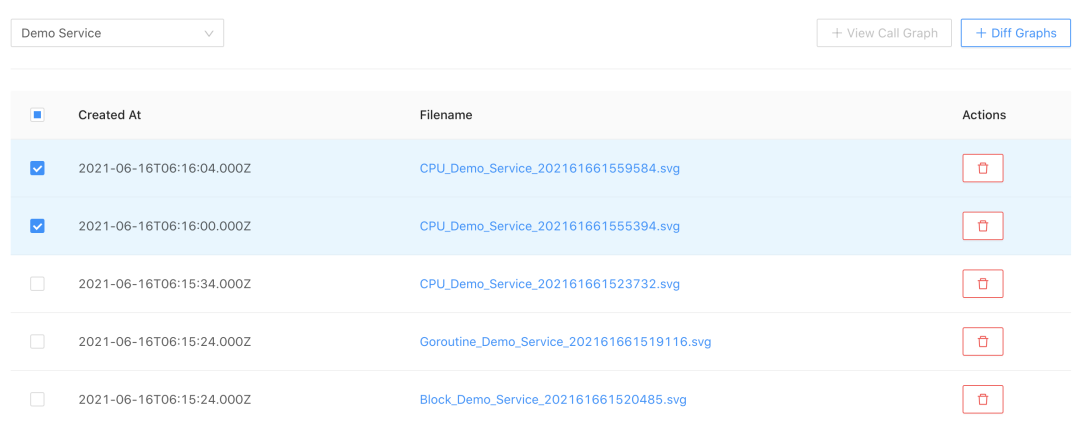
在报表管理模块,我们可以查看为某个微服务生成的所有 Profiling Report(目前支持火焰图和函数调用图)。但如果要处理某些问题,譬如性能回退,就要在代码修改前后或者不同时期不同场景下的火焰图之间,不断切换对比,定位问题所在。红蓝差分火焰图可以对比两张普通的火焰图,并对差异部分进行标色:红色表示上升,蓝色表示衰减,非常直观。鉴于此,我们同时提供了生成红蓝差分火焰图的功能。

任务管理
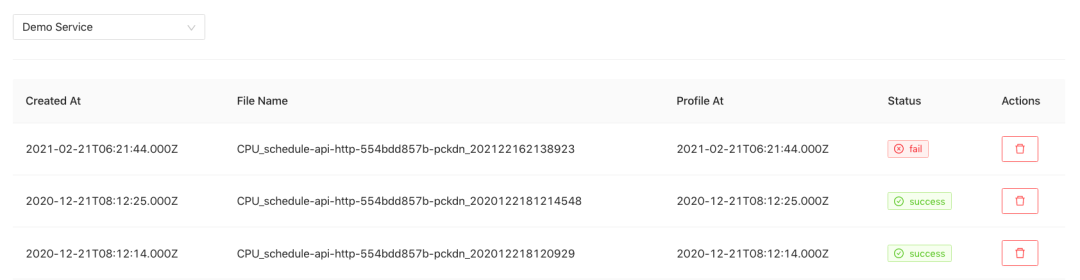
在任务管理模块, 可以查看某个微服务所有的 Profiling 任务及其状态,同时也支持 Profiling 任务的删除。
与微服务的集成
微服务使用 Profiling 组件功能的前提是启用 pprof ,支持 Profiling 数据的采集。Freewheel 的微服务属于上文提到的常驻进程型服务,与 pprof 集成的方式这里不再赘述。
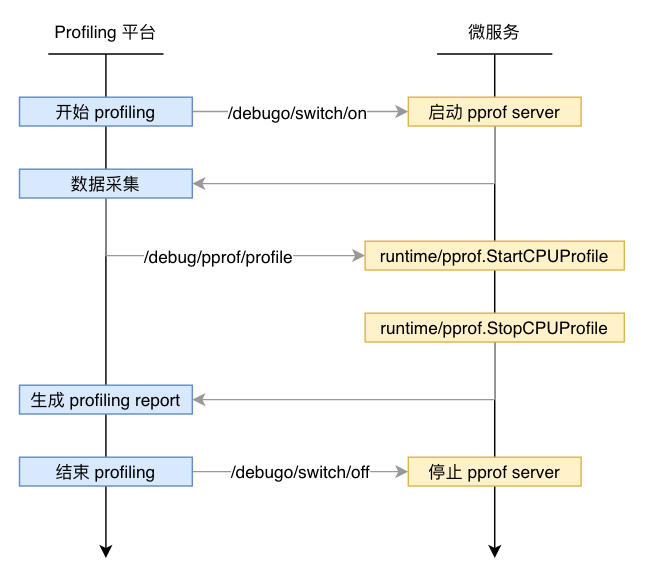
为了防止长期暴露 pprof 服务及端口,规避被攻击的风险,同时为了降低引入 pprof 对服务的性能影响,我们为微服务挂载了两个 API,以便动态启动和停止 pprof server。
/debugo/switch/on 启动 pprof server/debugo/swith/off 停止 pprof serverProfiling 组件在执行某个 Profiling 任务时,会先通过以上的接口启动 pprof server,然后通过调用 /debug/pprof/profile 等接口获得 runtime/pprof 库里相关函数采集的程序运行数据,在使用数据生成性能报告之后,再次调用接口停止 pprof server,具体的工作流程如下图所示:
落地效果
某一天,一个开发很久的新服务终于上线了。我们想了解在流量高峰阶段,服务的性能表现如何,于是根据历史日志预估了流量高峰到来的时间,并注册了一个此时间点执行的 Profiling 任务,生成的火焰图如下:
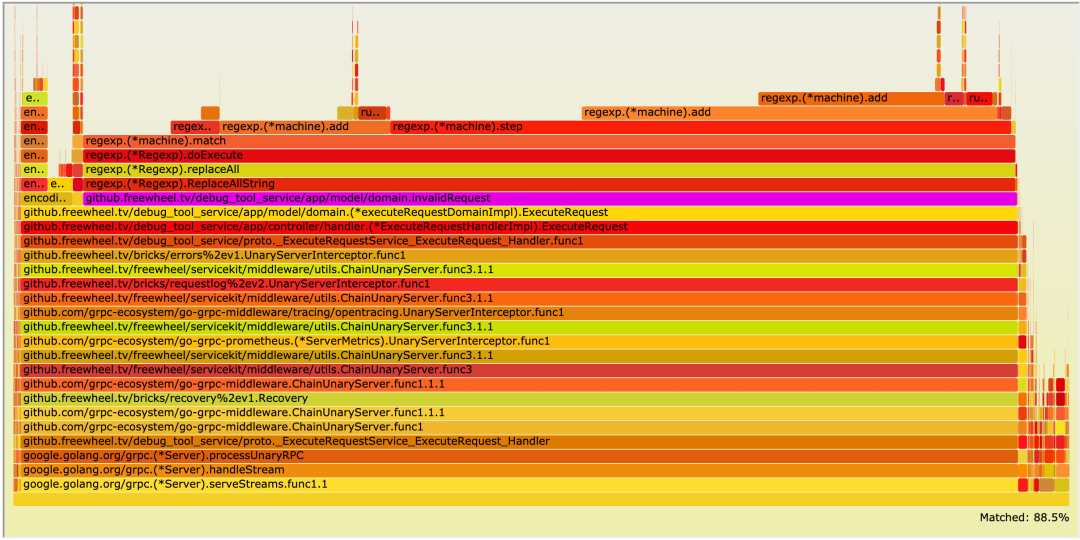
可以看到 domain.inValidRequest 执行时间竟然占到了总执行时间的 80% 以上,并且性能瓶颈主要在 regexp.(*machine).match。我们分析了要匹配的正则表达式,最后采用 strings.Index 和 strings.Replace 来实现同样的效果。优化之后的 domain.inValidRequest 仅占总执行时长的 2.2%,性能简直实现了质的飞越。
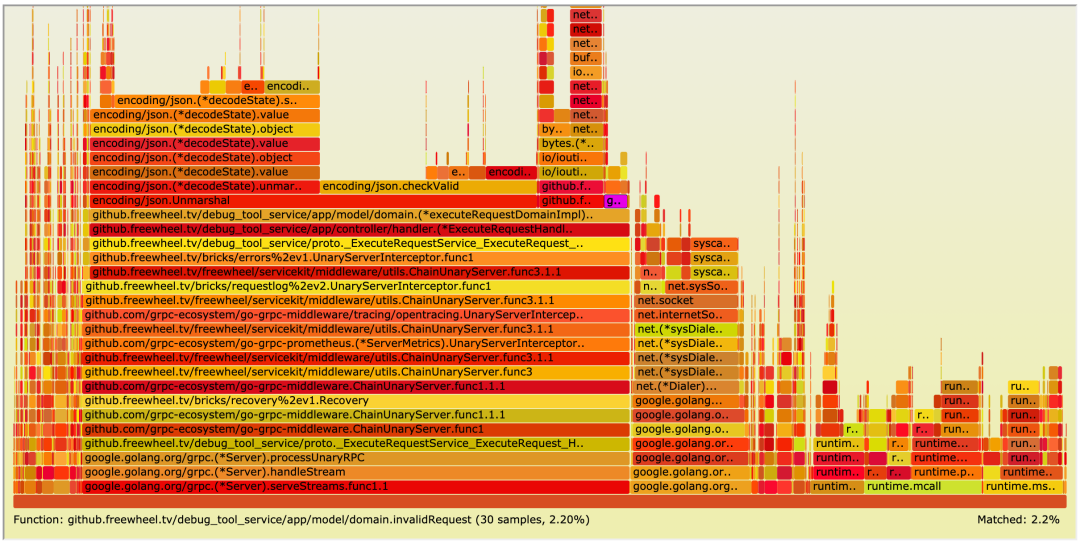
但我们仍然从上面的火焰图看到 json.Unmarshal 占到了总执行时长的 22% 左右。通过一番调研,我们引入了 github.com/json-iterator/go 库来替代 golang 原生的 encoing/json 库来执行 Unmarshal 操作,通过下面的火焰图可以看到 Unmarshal 的耗时降到了 14.2%。
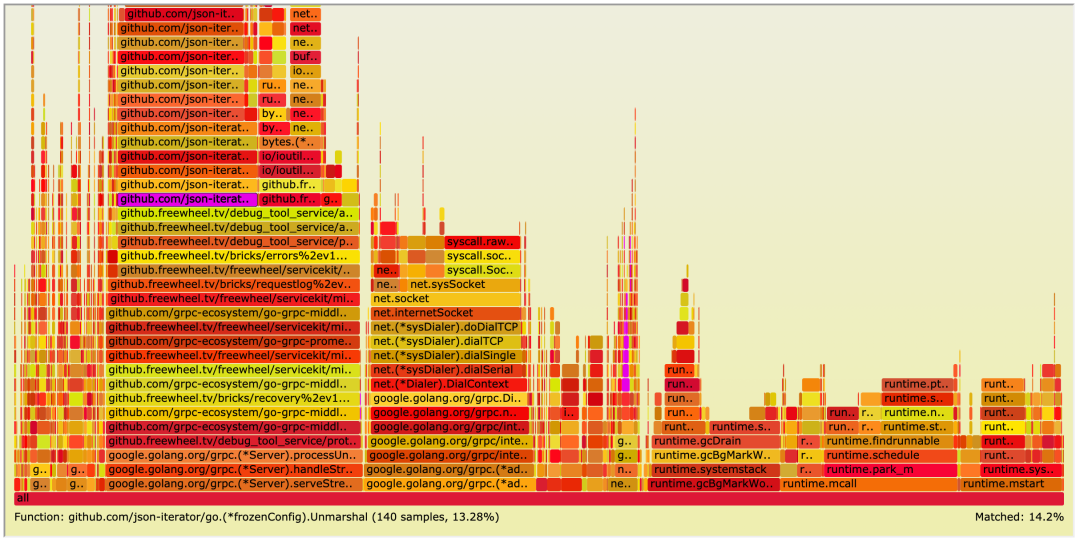
对此我们其实也有一些思考,我们在本地做了压测,性能达到了预期,通过火焰图也没有看到明显的性能瓶颈,那为什么问题到了线上就体现出来了呢?
后来我们定位到了原因,是因为线上需要解析的字符串竟然能达到几兆,这也是本地测试没有考虑到的情况。所以,即使我们认为在本地已经进行了充分测试, 但是百密也可能会有一疏,在真实的生产环境,在流量高峰期收集一段时间的 Profiling 数据并进行分析和优化,不失为一个好的习惯。
结语
本文介绍了如何基于 Golang pprof 构建完善的 Profiling 组件,提供多种触发 Profiling 的方式,并为微服务提供自动生成的、可追踪的 Profiling Report,希望能为微服务的稳定性保驾护航。
作者介绍:
韩钦亭, Freewheel 高级研发工程师,任职于 Freewheel 核心业务开发团队,致力于 Golang 微服务开发和系统重构相关工作。
系列文章推荐: 云原生环境下的微服务实践全解




