 本文最初发表在 IEEE__ 软件 杂志上,由InfoQ 和 IEEE 计算机学会为你呈现。
本文最初发表在 IEEE__ 软件 杂志上,由InfoQ 和 IEEE 计算机学会为你呈现。
用于大数据的嵌入式分析和统计已经成为了业内一个重要的主题。随着数据量的不断增长,我们需要软件工程师对数据分析提供支持,并对数据进行一些统计计算。本文概要地介绍了嵌入式数据分析和统计的相关工具及类库,其中包括独立的软件包和带有统计能力的编程语言。我期待着收到本专栏读者和潜在的专栏作者的反馈,告诉我你们对这个专栏的想法,以及你们想要了解哪些相关技术。—Christof Ebert
不管在信息技术界还是嵌入式技术界,大数据都已经变成了非常关键的概念。1 这样的软件系统通常都有众多的异构连接,包括软件应用程序、中间件和传感器之类的组件。随着云设施的使用不断增长,可用的数据资源变得更加丰富了;智能电网、智能车辆技术、医药最近都出现了这种相互连接的数据源。我们每年生产的数据将近 1,200 艾字节,并且这一数字有增无减。2,3 这样海量的非结构化数据是业务和 IT 主管无法回避的巨大挑战。
大数据的定义由四个维度组成:数据量、数据源的复杂度、生产速度,以及潜在用户数。这些数据需要被组织起来,将无数的位和字节转换成可操作的信息—除非我们能提炼出其中的含义,否则数据再丰富都没用。在以前,程序员是写代码的,而统计学家是做统计的。程序员一般用通用的编程语言,而统计学家一般用专门的程序完成自己的日常工作,比如 IBM 的 SPSS (用于社会科学的统计软件包)。统计学家摆弄的国家统计数据或市场调研通常只有选定人群能用,而程序员处理的大量数据都是放在数据库或日志文件中的。从云到几乎所有人都可用的大数据改变了这一切。
(点击图片可以放大)

随着数据量和数据类型的不断增加,越来越需要软件工程师参与进来对它们做不同的统计分析。软件工程师积极地以前所未有的规模收集和分析数据,让它们变得有价值,拓展新的业务模型。1 比如说,考虑一下主动性维护。我们可以持续地对机器、网络进行监测,一旦发现违规和失效,则立即处理,从而让我们可以在破坏发生或系统瘫痪之前纠正它们。这可以从材料成本以及人工介入两方面降低维护成本。处理数据并找出其中的含义通常只是一个大项目中的一部分工作,或者只是嵌在某些软件中,配置中,或硬件优化问题中。幸运的是,大数据社区已经对这种需求作出了响应,他们创建了一系列的工具,可以将统计学家的一些魔力交给程序员—实际上,这些工具通常要比传统的统计工具更强大,因为它们能处理的数据量在规模上要比老的统计样本幅度更大。
用于嵌入式分析和统计的技术
可以执行统计分析的软件有很多;表一给出了一些最流行的软件。它们的区别在于用户对它们统计复杂度的要求,易用性,以及它们是独立的软件包,还是带有统计能力的编程语言。
表一中有三项很值得我们注意:R、Python、D3 (数据驱动文档 Data- Drives-Documents)。R 是一门面向统计的语言。Python 是一门通用的编程语言,并且已经证实在科学家和研究人员中间很流行,他们会用它作科学及统计计算。D3 是一个 JavaScript 库,用户可以用它创建可视化图形,并使用 Web 浏览器与之交互 (比如放大、缩小、收起和展开) 。R、Python 和 D3 都非常适用于嵌入式统计,有几个原因:
-
因为它们是独立的编程语言,可以轻松地通过标准语言机制跟其它系统交互,或者也可以通过导入及导出各种格式的数据。
-
Python 和 R 中的脚本可以直接嵌入到更大的分析工作流中。
-
Python 和 R 程序可以直接用来构建应用程序,这些应用程序可以从各种数据源读取数据,用户可以直接通过 Web 跟这些应用程序做数据分析及可视化的交互。
-
借助 D3,用户可以通过 Web 浏览器交互式地操作统计图形,将分析提升到更高水平。
-
它们比专业的统计包更靠近程序员的思维框架。
除了 D3,这个表中的所有东西都提供了进行高级统计(比如多元和时间序列分析)的设施,或者自身具备,或者通过类库实现。尽管其中的每一个都有侧重点,更适合解决特定的目标问题。比如 Python 的 Pandas 包,善于支持时间序列分析,因为它就是为了对财务数据做这样的分析而写的。
Python 的统计生态系统
现如今用来做统计的最流行的通用编程语言就是 Python。在科学计算方面它总是受到青睐,还有几个优秀的 Python 工具可以用来完成更复杂的统计任务。Python 中的基本科学库是 NumPy 。它对 Python 的主要贡献是一个同构的多维数组,可以用来放操作数据的方法。它可以集成 C/C++ 和 Fortran,还有几个函数可以用来执行高级的数学及统计计算。它内部主要用的是自己的数据结构,用本地代码实现,所以在 NumPy 中执行的矩阵计算比在 Python 中执行相同的计算快得多。构建在 NumPy 之上的 SciPy ,提供了一些高层的数学和统计函数。SciPy 再次处理了 NumPy 的数组;这些数组虽然很适合做数学计算,但处理可能会有缺失值的异构数据时有一点繁琐。为了解决这个问题, Pandas 提供了灵活的异构数据结构,很容易索引、切片,甚至合并和连接 (类似于 SQL 表之间的连接)。 引入 iPython 是个很吸引人的设置,它是一个交互式的 Python shell,有命令行补足、很好的历史记录,以及很多其它特性,在操作数据时特别有用。然后还可以用 Matplotlib 对结果可视化。

举例说明
世界银行是一个信息宝库,并且它的很多数据都可以通过Web 访问。对于更复杂的分析,公众可以从世界银行的数据目录下载数据,或通过API 访问它。最受欢迎的数据集是世界发展指标(WDI)。根据世界银行的说法,WDI 包含“最新、最准确的全球发展数据,包含国家、地球和全球的估算。” WDI 有两种可下载的格式:Microsoft Excel 和逗号分隔值(CSV) 文件。 (因为 Microsoft Excel 文件不适合编程分析,所以我们在这里处理的是CSV 文件。)

图 1.计算世界发展指标相关性的Python程序。这个程序采集了最前面30个测量最多的指标,计算斯皮尔曼相关系数,并用图形显示结果。
WDI CSV 包是一个 42.5M 的压缩文档。下载并解压后,你会见到主文件 WDI_Data.csv。获得该文件内容概览的好办法是交互地检查它。因为我们要用 Python,所以跟我们要用的那些工具交互的最好办法是发起一个 iPython 会话,然后加载数据:
In [1]: import pandas as pd
In [2]: data = pd.read_csv(“WDI_Data.csv”)
结果在 data 中,一个包含数据的 DataFrame。你可以把 DataFrame 看作一个二维数组,有一些易于操作的额外功能。在一个 DataFrame 中,数据被组织为几列和一个索引 (与行对应)。如果我们输入
In [3]: data.columns
我们会得到显示列名的输出:国家名、国家代码、指标名、指标代码。这些后面都跟着从 1960 到 2012 年每年的数据列。类似的,如果我们输入
In [4]: data.index
我们会看到数据有 317,094 行。每一行都对应一个国家一个特定指标从 1960 到 2012 年的值;一行中没有值的年份表明那一年在那个国家中没有测量这一指标。我们先看一下有多少指标
In [5]: len(data[‘Indicator Name’].unique())
Out[5]: 1289
然后看一下有多少国家
In [6]: len(data[‘Country Name’].unique())
Out[6]: 246
现在我们有一个要解决的问题:这些指标是彼此独立的,还是其中有些相互关联?
因为我们是按年份和国家测量的指标,所以我们必须确定让哪个参数保持恒定,从而更精确地定义这个问题。一般而言,当样本增加时,我们会得到更好的统计结果。然后重新表述这个问题就变得有意义了:哪一年的测量结果最多,测量最多的指标是独立的,还是其中一些彼此相关?所谓“测量最多的指标”,是指那些在更多国家中测量的指标。事实证明,我们可以在大约 50 个 LOC 中找到问题的答案。图一中是完整的程序。
代码 1–10 行导入了我们将要用到的库。第 11 行读取数据。在第 13 行中,我们给出了一个数值,这是我们要检查的测量最多的指标的个数。在第 15 行,我们找到了从 0 开始的带有年度测量值的第一列。在那之后,我们可以在第 17 行找到有最多测量值的那一列(2005 年)。然后我们去掉了没有那些测量结果的所有数据。在第 20 到 26 行,我们获取了测量最多的指标。
真正的统计计算从第 28 行开始,我们准备了一个表,用来存放每对指标相关性的结果值。在接下来的循环中,我们计算每对指标的相关性,并把它放在之前准备好的表中。最后,在第 41 到 52 行,我们把这些结果显示在屏幕上,并保存为一个 PDF 文件(见图二)。我们还把相关矩阵的垂直顺序做了反向处理,以便让最重要的指标出现在矩阵的顶部(代码 41 和 49 行)。
对角线上有完美的相关性—理应如此,因为那里检查的是相同的指标。除此之外,我们的确看到了有些指标之间有相关性—有些是正相关的,甚至很强,也有些是负相关或者非常的负相关。
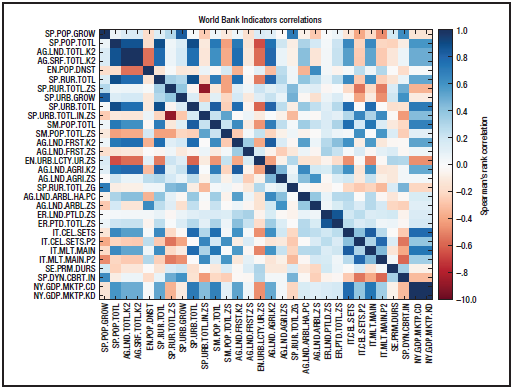
图 ****2. 图一中的Python程序创建出来的世界发展指标相关矩阵。
Python 生态系统中更高级的组件
因为 Python 受到了科研界的青睐,一些专业化的工具也随之出现。其中有构建在 NumPy、SciPy 和 matplotlib 之上的 Scikit-learn ,它提供了完备的机器学习工具包。对于符合层级结构的超大型数据集,Python 提供了 PyTables ,它以 HDF5 库为基础。这是一个行业热点, DARPA 在 2013 年从 XDATA 项目基金中拿出 300 万美元给 Continuum Analytics 作为奖励,让它进一步推进 Python 数据分析工具的开发。可以预料到的是接下来的几年这个生态系统仍将稳步发展。
用于统计计算的 R 项目
R 是做统计的语言。可以这么说,Python 让做统计变成了程序员的活,而 R 让写程序变成了统计人员的任务。这门语言的中心是有效操作表示统计数据集的对象。这些对象通常是向量、列表,和表示按行和列组织的数据集的数据帧。R 有常用的流程控制结构,甚至用到了面向对象编程的思想(尽管它的面向对象实现跟我们在更传统的面向对象语言中的概念有很大差别)。R 的卓越之处在于它所提供的各种统计类库。R 的类库中几乎实现了所有的统计测试或方法(然而在 Python 中,有时你可能会发现你必须推出自己的实现)。为了让你明白它看起来是什么样的,图三给出了一个跟图一一样的程序,相同的逻辑,但实现用的是 R 而不是 Python。图四是结果。

图 ****3. 用R实现图一中那个计算世界发展指标相关性的程序。
组合、联合、整合嵌入式分析技术
我们在本文中给出的例子是不同应用程序合并到一起处理大数据的典型办法。数据从源头(以某种原始格式)流向我们的统计包可接受的格式。统计包必须有一些能够操作和查询数据的办法,以便我们能取得想要检查的数据子集。这些都是统计分析必须有的。统计分析的结果可以用文本格式或图形渲染出来。我们可以在本地计算机上执行这一处理,也可以通过 Web 完成(此时数据的运算和处理是由服务器执行的,参数、结果和图形要通过 Web 浏览器)。这是一个很强大的概念,因为许多不同的设定,从 ERP 框架到汽车诊断软件,都可以将数据导出为 CSV 这样简单的格式—实际上,当我们遇到一个不允许导出任何东西,封闭并且有专有数据格式的软件时,应该视作是一种警告。
要想按你想要的方式分析数据,你必须首先能够访问到它。所以你应该通过各种手段选择那些可以促进数据交换的技术,或者通过简单的导出机制,或者通过适当的调用,比如通过一个 REST(表述性状态转移)API。
数据一直在变大,所以你必须进行调研,看你正在考虑的工具能否胜任你的数据处理工作。你没必要在主存中处理所有数据。比如说,R 有一个 大内存 库,让我们用共享内存和内存映射文件处理超大数据集。还有,要确保软件包不仅能处理大量输入,还要能处理大型数据结构:比如说,如果表的大小被限定在32 位整型之内,你就不能处理有5 百万条记录的表。
在上面的例子中,警觉的读者可能已经注意到了,我们将数据变成适于统计分析的格式所用的代码,要比统计分析本身的代码还多,不管怎么说,那是由已经写好的函数做的。我们的例子有点儿小,所以预处理和真正的处理两者的比例可能尤其显得头重脚轻,但这个例子也表明了这一事实,即数据操作通常和数据分析同样重要(和苛刻)。实际上,R 和NumPy/SciPy 真正的实力并不在于它们掌握了统计算法,而是在于它们知道如何有效地处理它们提供的数据结构。并且这基本上是程序员的工作,不是统计学家的。别处还有更深入的资源可供阅读。4-7
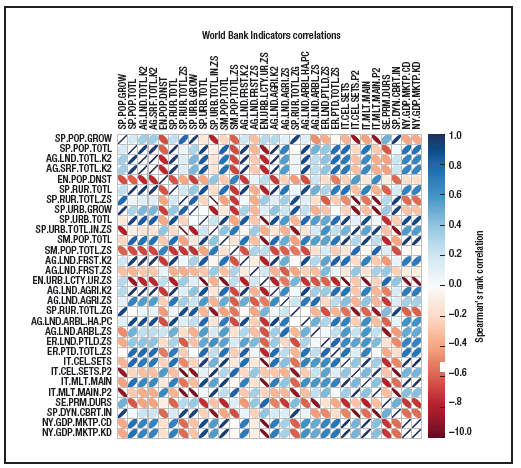
图 4. 用R做出来的世界发展指标相关矩阵
参考资料
- C. Ebert and R. Dumke, Software Measurement, Springer, 2007.
- K. Michael and K.W. Miller, eds., Computer, vol. 46, no. 6, 2013.
- T. Menzies and T. Zimmermann, eds., IEEE Software, vol. 30, no. 4, 2013.
关于作者
 Panos Louridas 是希腊研究和技术网的顾问,同时也是雅典经济与商业大学的研究员。可以通过 louridas@grnet.gr 或 louridas@aueb.gr 联系到他。
Panos Louridas 是希腊研究和技术网的顾问,同时也是雅典经济与商业大学的研究员。可以通过 louridas@grnet.gr 或 louridas@aueb.gr 联系到他。
 Christof Ebert 是矢量咨询服务的总经理。他是 IEEE 高级会员,IEEE 软件的软件技术部的编辑。可以通过 christof. ebert@vector.com 联系他。
Christof Ebert 是矢量咨询服务的总经理。他是 IEEE 高级会员,IEEE 软件的软件技术部的编辑。可以通过 christof. ebert@vector.com 联系他。
本文最初发表在 IEEE 软件 杂志上。 IEEE 软件的使命是构建领先的和面向未来的软件从业人员社区。这份杂志致力于提供可靠、使用、前沿的软件开发信息,让工程师和管理人员能够紧跟快速变化的技术。




