
本文最初发布于 hassenchaieb.com 网站,经原作者授权由 InfoQ 中文站翻译并分享。
如今,数据生态系统正在蓬勃发展,流行名词随处可见,每天都有新产品面世发布。身在其中的人们很难看清“庐山真面目”。
在这篇文章中,我会退后一步,试着解读当前生态系统的源头。为什么我们拥有如此众多的产品,它们在现代企业中又各自适合哪些位置?当然,我会做很多简化。实际上,每家公司都是独特的,有着自己独有的需求。
2000 年代初:互联网的崛起和数据量的增长
随着互联网的兴起,企业不得不处理越来越多的数据源。公司数据被存储在许多各自不同的关系数据库中。这让公司无法快速获得关于客户、销售等领域的数据分析结果和可行见解。
一种解决方案是数据仓库,它将所有彼此孤立的关系数据库整合到一个单一的事实来源中,用来提供客户数据的 360°全景视图。
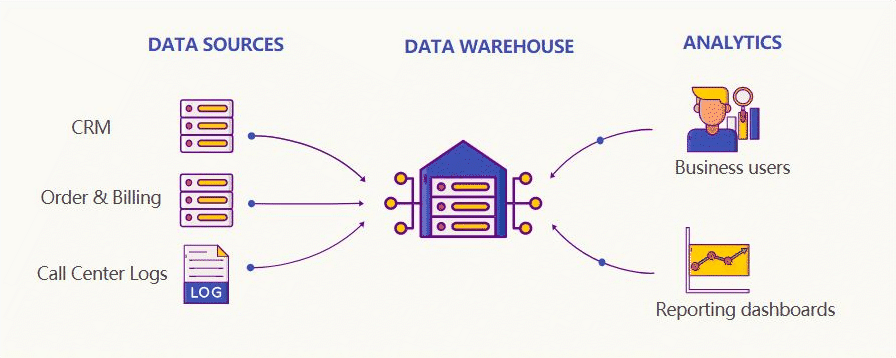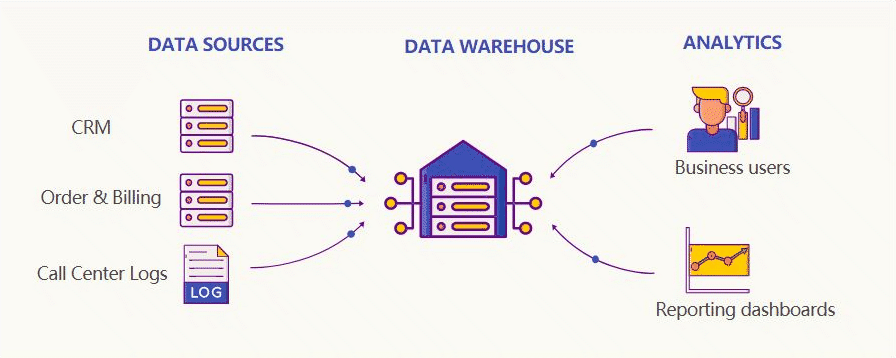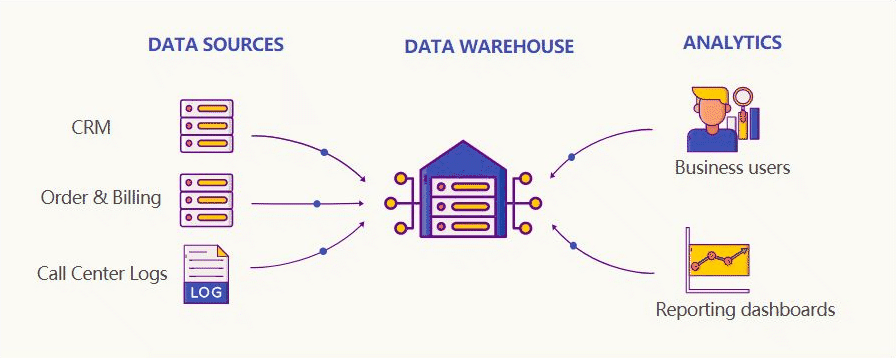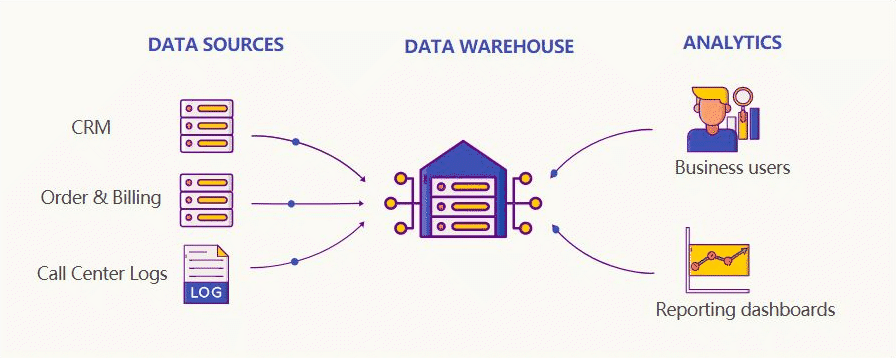
然后,许多大型科技公司开始收集海量数据,因此需要全新的数据存储和处理方式。这些工作再也不是单台计算机可以应付的了。2006 年,Hadoop 诞生。
Hadoop 是一组软件工具,可对庞大的数据集进行分布式处理(多台计算机)。
接下来,许多工程师离开了这些巨型公司,开始了自己的大数据创业,并获得了风险投资的资助。到 2010 年,大数据热潮来临。
2010 年,Gartner 将云计算列为第一大战略技术。云计算为大数据提供了必要的基础架构:足够的计算、存储和网络能力。
云提供商还为初创企业提供了一种轻松的方式来启动和扩展它们的业务(基础架构即服务),而无需企业管理自己的 IT 基础架构。
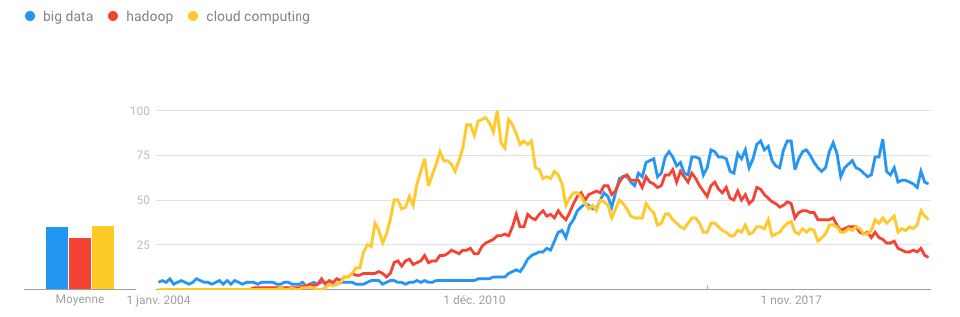
2010 年至 2015 年:云转型和现代数据仓库的成熟
不过,在 2010 年初,大多数大公司仍在犹豫不决,不知道是保留内部部署还是迁移到云端,并一直在等待市场上出现一家大型大数据服务提供商来简化云迁移工作。
只有那些在早期就采用云计算的大公司才开始投资大数据技术。事实证明,这并不是一次简单的技术迁移,而需要在全公司范围内推广数据驱动文化,增加很多新的岗位以及复杂的数据流程。
在那些年间,数据仓库迎来了模式变革。
由于数据量和数据类型的增加,以及对业务分析能力的期望升温,很多公司开始在数据仓库的 staging 层遇到瓶颈。用户通常需要数周或数月时间才能将一个新的数据源集成到“提取-转换-加载”模式中。
除了结构化的交易数据外,公司还开始使用快速变化的模式收集越来越多的行为数据。
最终,人们意识到存储成本已经比以前便宜多了,数据仓库的计算能力也有所提高。因此,在转换之前就将数据加载到仓库中是可行的办法。
行业开始发生三个转变:
从 ETL(提取-转换-加载)到 ELT(提取-加载-转换)
从本地部署到云:云服务提供商可以提供适合公司需求的简单而灵活的数据仓库。
从 Hadoop 到全新的数据湖:数据湖是中心化的原始数据 staging 区域,(它可以是一个简单的 Amazon S3 存储库或 Google Cloud Storage,也可以具有更多功能)
此外,可以处理大量数据的基础设施的普及为物联网和连接对象的崛起铺平了道路,这些产业取得很大成果。反过来,这增加了一些公司需要处理的数据量。
2015 年-2017 年:数据管道和 AI 风潮
对大多数公司而言,大数据基础设施的主要选项已经很清楚了,现在的核心挑战在于如何轻松、快速地提取数据,以及如何快速将其提供给分析师和业务用户。
公司开始聘请数据工程师来维护现代数据仓库周围的数据管道。我们看到 Apache Airflow 之类的数据流自动化工具的兴起。这些工具使公司能够自动化数据管道的提取和转换部分。
我们看到 NoSQL 风头不再,而 SQL 正式回归,身边是一些允许对非结构化和结构化数据仓库的数据发起 SQL 查询的工具(Snowflake、BigQuery)。
“大数据”风潮开始平息了,不是因为它被人遗忘,而是因为它已经成为现实。一个新的领域吸引大多数媒体的注意力。人工智能是新的金矿。随着深度学习的发展,机器学习获得巨大的关注度。
这一风潮让 AI 的实践落地开始普及,并催生了很多数据驱动的产品。(推荐系统、可预测的维护……)。结果,由于 ML 方法走向成熟,我们看到了 DataOps 协作平台的诞生,使公司能够轻松地对业务数据用 ML 模型来做试验。
对于大型组织的评论:如果现在你还没有主动构建大数据+AI 战略(无论是自行研发还是与供应商合作),你就是在让自己被时代淘汰。——MattTurk
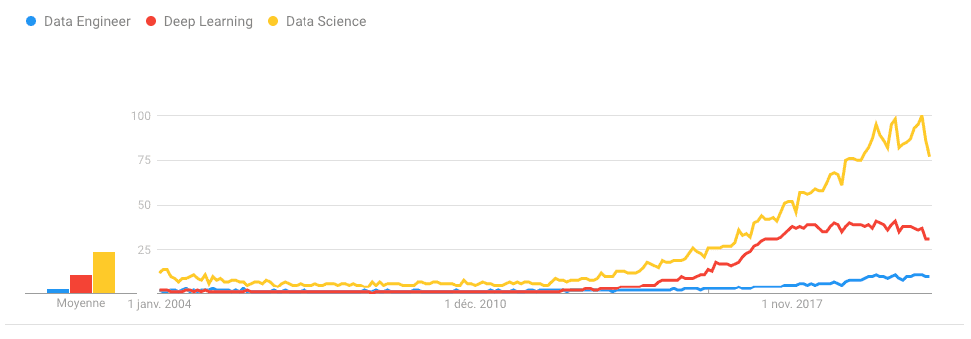
2018-2020:目前的挑战
从 2018 年到 2020 年:多数大型公司已开始或正在经历云端转型。
工程师一直在努力开发各种工具来更轻松、更快速地访问和处理原始数据。
诸如(dbt)之类的一些工具使用户可以将 SQL 作为转换层。
流处理方法越来越吸引人。
以下是今天的企业面临的一些挑战:
混合云:为避免供应商锁定并优化成本,许多公司都选择混合使用私有云、公共云和内部部署的方法。
数据分类和元数据管理:数据和数据源是整个系统的基础。需要对它们做适当的索引、扩充和引用,以便任何人都可以更轻松地找到它们,并知道如何使用它们。同样,我们看到机器学习管道中需要一种“功能目录”。
数据质量:数据质量意味着确保在数据管道每个阶段中数据的完整性、一致性、可用性和可使用性。
安全和隐私:在 Facebook 剑桥分析丑闻之后,公司和公众愈加重视隐私保护问题。GDPR(通用数据保护法规)和 CCPA(加利福尼亚消费者隐私法案)等新法规引入了新的数据跟踪和安全性约束。公司需要简单的解决方案来集中控制数据访问。企业必须跟踪和控制数据的用法。
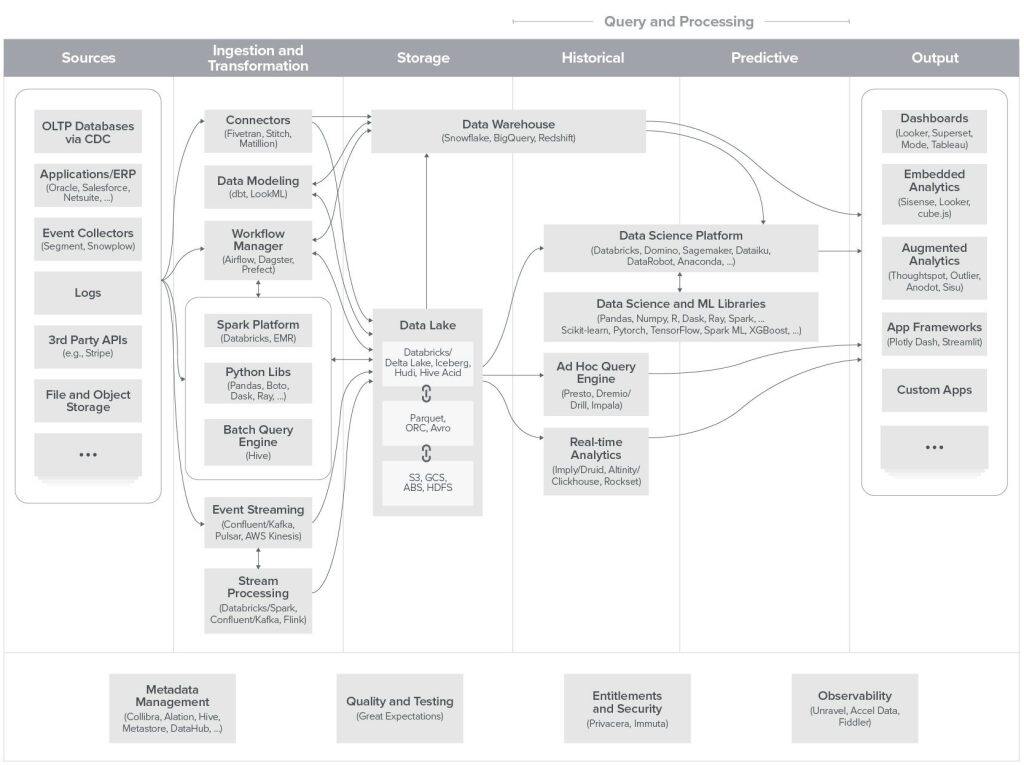
这有现代数据基础架构的一份相当完整的参考。它是由 Matt Bornstein、Martin Casado 和 Jennifer Li 在访谈 20 多位企业数据负责人和数据专家之后制作的。
原文链接:




