
近期,Apache 软件基金会宣布归档了 13 个与大数据相关的项目,其中 10 个是属于 Hadoop 生态的项目,例如 Eagle、Sentry、Tajo 等。
Apache Hadoop 作为一个完整的开源大数据套件,在过去的十多年里深刻影响了整个计算机界。但随着各类新兴技术的发展, Hadoop 生态圈已经发生了巨大的变化。Hadoop 已死吗?如果是真的话,那么谁会取代?大数据分析的未来又将走向何处?
本文整理自 Kyligence 首席架构师、Apache Kylin PMC Chair 史少锋在由七牛云主办的 2021 ECUG Con 上的主题演讲《大数据分析如何迎接后 Hadoop 时代》。
Hadoop 为大数据而生
过去二十年里,人类一直处在一个数据爆炸的时代。企业的传统业务数据如订单、仓储的增量相对平缓,在整体数据量中的占比逐渐减少;取而代之的是人类数据(例如社交媒体、照片、行为画像等数据)和机器数据(日志、IoT 设备等产生的数据)大量被采集和保存,它们的量级远远超过传统业务数据。在海量数据和人类既有能力之间,一直存在着巨大的技术缺口,这个缺口催生了各类大数据技术,从而诞生了我们所说的大数据时代。
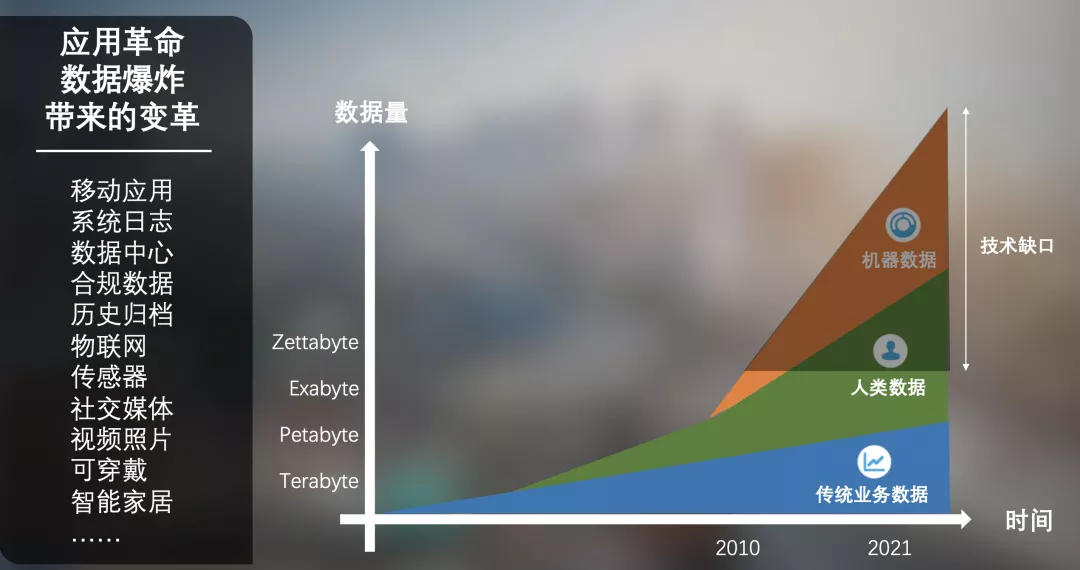
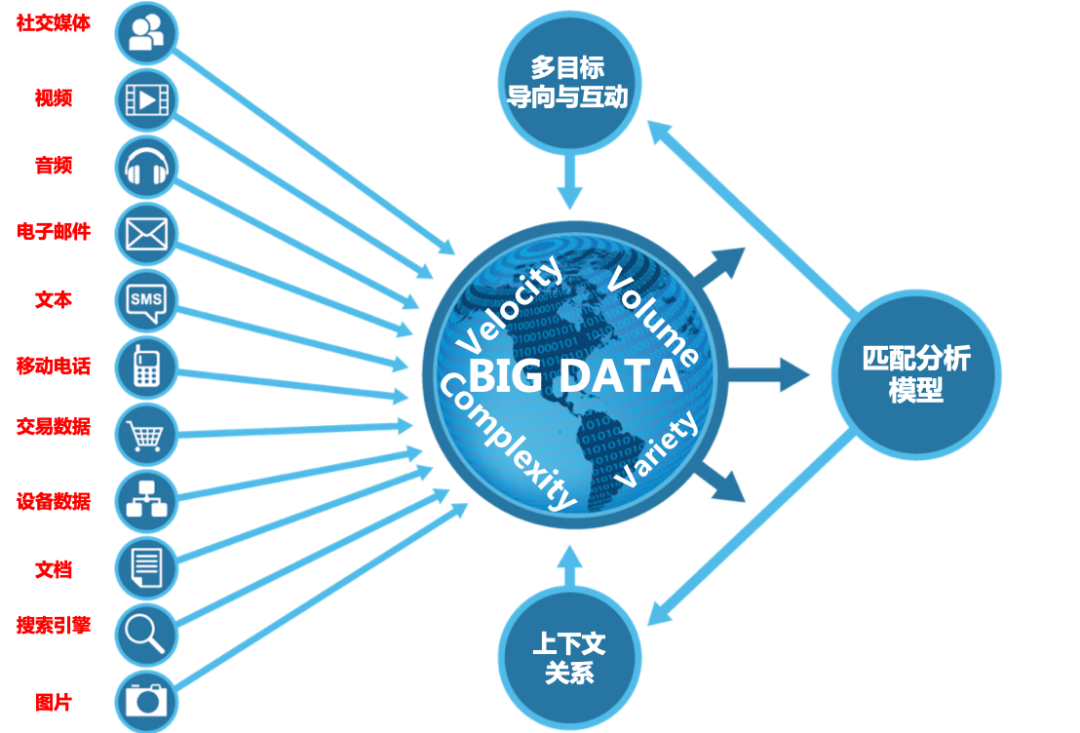
根据业界普遍达成的共识,一个大数据系统需要满足 3 个方面的需求:
1) Volume:数据容量要大,这是大数据系统的首要特性。
2) Velocity:数据处理速度要快。
3) Variety:要能够处理多样的数据类型,包括结构化、半结构化、非结构化,甚至图片视频等等。
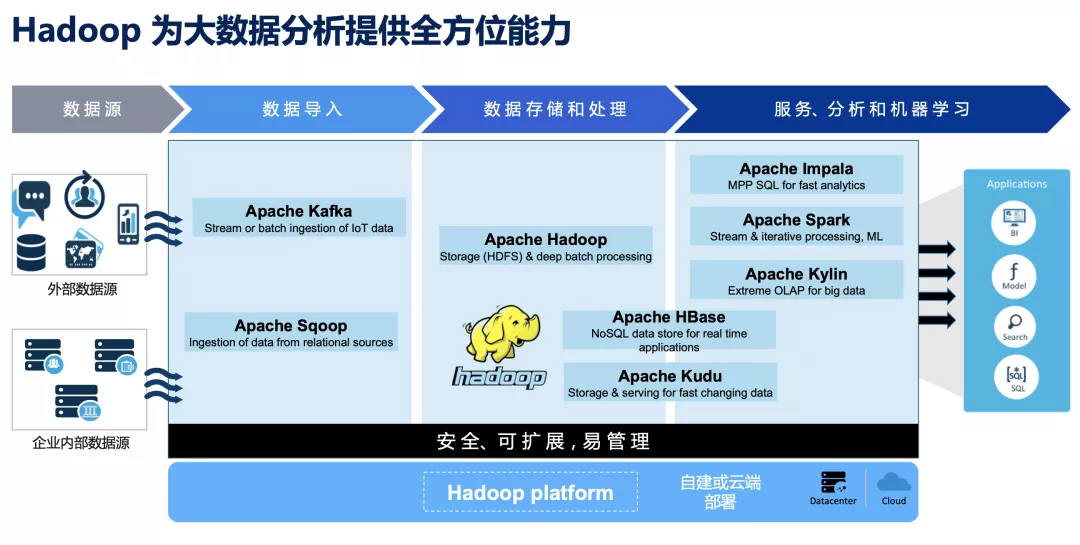
Hadoop 就是这样一个全功能的大数据处理平台,它包含了多种组件以满足不同的功能,例如 HDFS 做数据存储,Yarn 做资源管理,MapReduce 和 Spark 做数据计算和处理,Sqoop 做关系数据采集,Kafka 做实时数据管道,HBase 做在线数据存储和访问,Impala 做在线 Ad-hoc 查询等。Apache Kylin 也是 Hadoop 生态组件中的一员,借助于其它组件来完成计算和存储,自身专注于高性能 OLAP 分析,从而对 Hadoop 生态能力形成补充。Hadoop 诞生后很快就利用集群并行计算,打破了由超级计算机保持的排序记录,证明了自己的实力,进而逐渐被企业和各种组织广泛采纳。
Hadoop 这十年
借助「大数据」的东风以及 Apache 开源社区的影响力,Hadoop 快速普及,随之而来的是一票商业化公司涌现。此外,公有云厂商也在云上提供了托管的 Hadoop 服务。
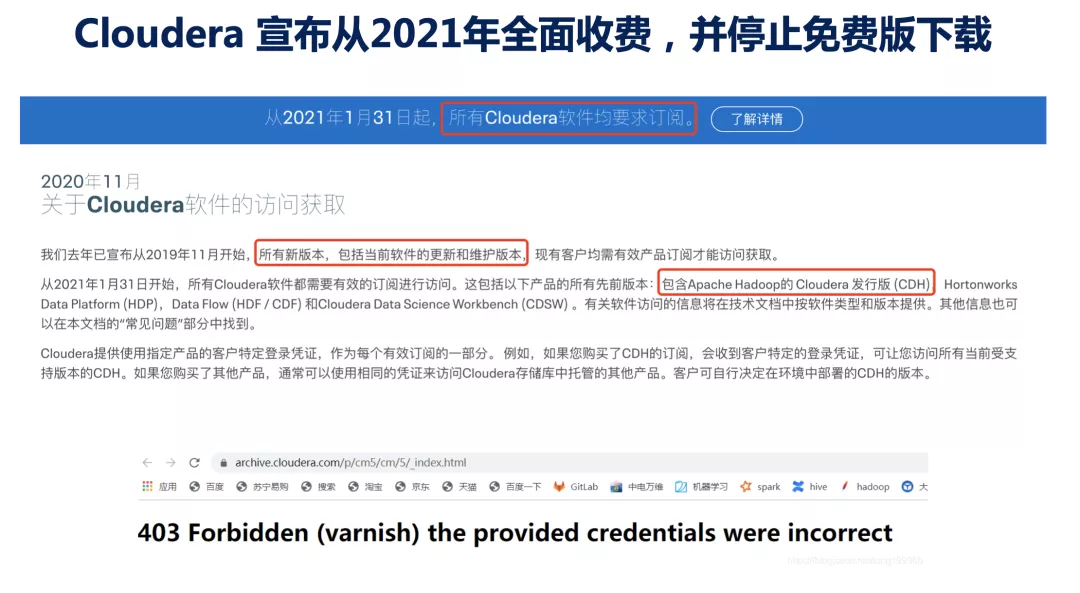
但到 2018 年,整个市场风云突变,一则重磅新闻让整个 Hadoop 生态圈炸锅了:Cloudera 和 Hortonworks 合并了,也就是说这个市场上的第一名和第二名抱团了;紧接着 HPE 宣布收购 MapR,这些迹象说明, 在 Hadoop 风光的表象之下,是企业经营困难,钱难赚了。

合并 Hortonworks 之后,Cloudera 又宣布,所有产品线全面收费,包括历史的开源版本也要付费后才能获取,开源的产品不再面向全部用户,而是仅仅针对付费用户。过去一直被大家免费使用的 HDP 发行版,也不再维护和提供下载了,未来都合并到统一的 CDP 平台了。
回看 Hadoop 的发展历史,它能兴起是因为用户对于大数据处理的旺盛需求。但在今天,用户对数据管理和分析有了新的需求,例如在线快速分析、存算分离或者 AI/ML 等面向人工智能与机器学习方面,Hadoop 的支持比较有限,无法和一些新兴的技术相比较,例如这几年很火的 Redis、Elastisearch、Clickhouse 等都可以做大数据分析。对于客户而言,如果用单一技术就能满足需求,那么就大可不必去部署复杂的 Hadoop 平台了。

从另一个角度来看,云计算在过去十多年快速发展壮大,不光干翻了传统企业软件厂商如 IBM、HP 等,也一定程度上蚕食了 Hadoop 所处的大数据处理和分析市场。早期,云厂商还只是在 IaaS 层提供了 Hadoop 的部署,例如 AWS EMR (它号称是全世界部署最多的 Hadoop 集群)。对于用户来说,云上托管的 Hadoop 服务可以随开随停,数据也可以放心地备份在云厂商的数据服务上,使用简单的同时也会节约资源和成本。此后,云厂商打造了更多面向特定场景的大数据服务,从而形成了一个完整的生态。例如 AWS 的 S3 实现数据的高持久低成本存储,Amazon DynamoDB 实现低延迟的 KV 数据存储和访问,以及无服务器的大数据查询服务 Athena 等。
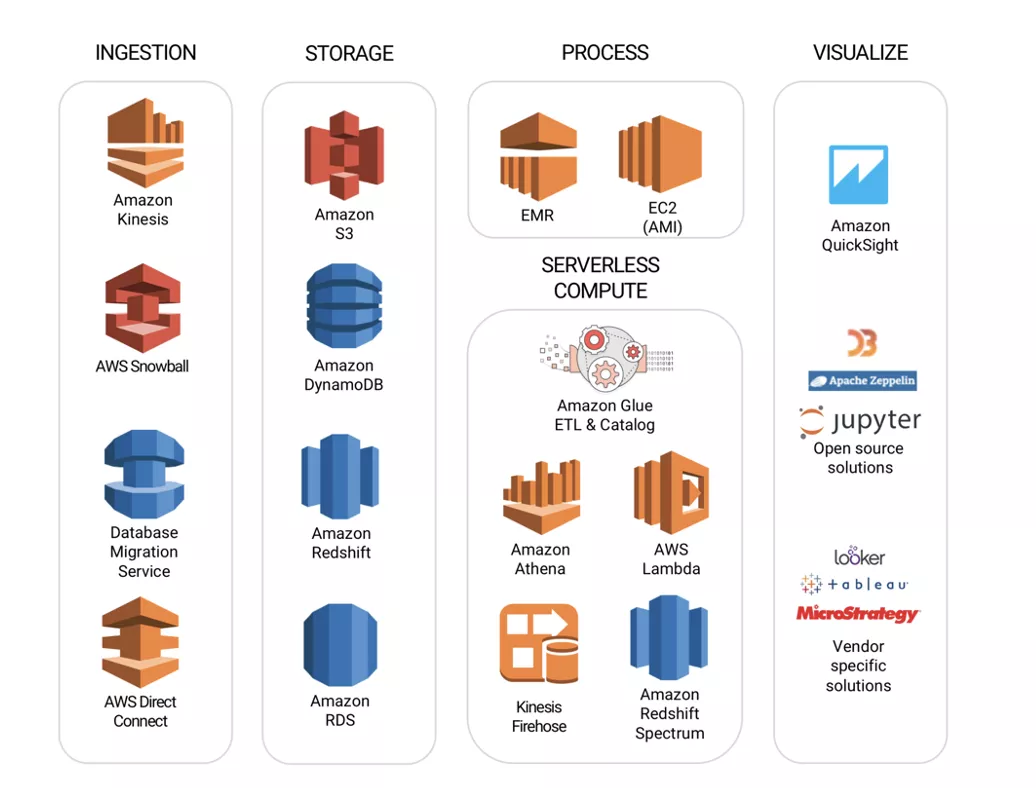
除了新兴技术和云厂商的持续发力,Hadoop 本身的发展也逐渐显露「疲态」,堆积木的方式固然不错,但无形中也加大了用户的使用难度。从下图可以看到在 2016 年,Hadoop 上已经有超过 20 个常用组件,对于 Hadoop 用户来说,学习和运维都是一个巨大的挑战。

综合以上因素来看,Hadoop 逐渐失去光环是必然的事情,并不是很意外。话说回来,任何一个技术都有其发展、成熟到衰落的一个过程,这是客观规律,没有任何技术可以逃脱。
那么 Hadoop 会退出历史舞台吗?我们相信这个事情不会很快发生,毕竟 Hadoop 的用户体量非常大,平台和应用的迁移成本非常高昂,所以今天的用户还会继续使用它,只是新的用户会逐渐减少。这个过程我们称它为「后 Hadoop 时代」。
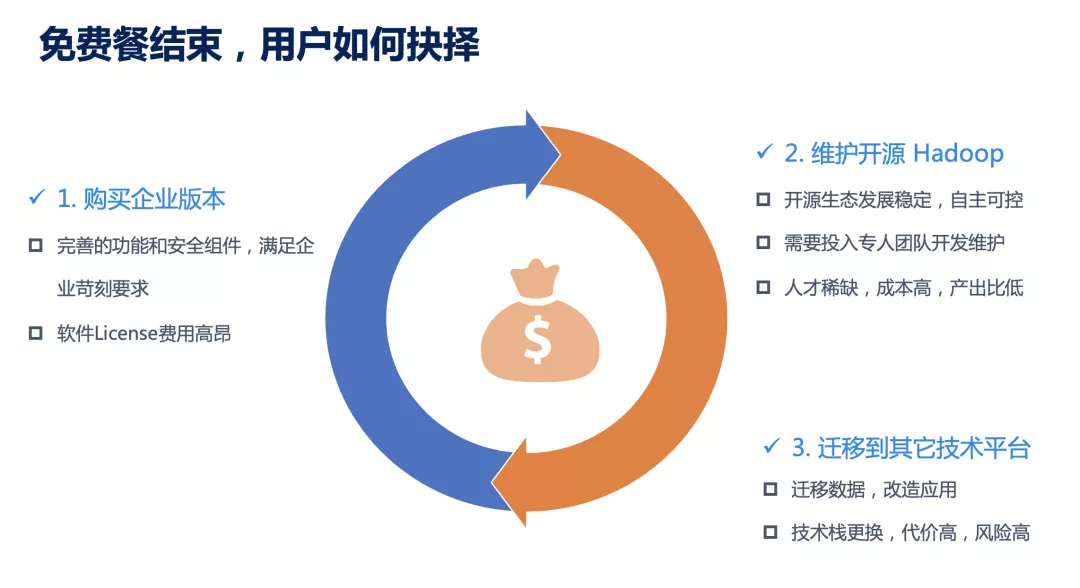
既然进入了后 Hadoop 时代,作为 Hadoop 用户,如何面对这个转变过程呢,有哪些选项可以选择呢?选择是有的,就看你的荷包和技术能力了。
首先,指望像 Cloudera/Hortonworks 这样的技术厂商,再发布一个面向大众的高质量免费产品,基本上不可能了。事实证明他们早前的免费版+收费版双线走的路是不通的,所以日后 Cloudera 只会提供收费版本 CDP,免费午餐结束。至于是否有其它厂商愿意挺身而出再扛起免费大旗,这个就不得而知了;而且就算有这样的厂商,它的产品稳定性和先进性还不得而知,毕竟 Hadoop 的核心开发者可大都是在 Cloudera 和 Hortonworks 的。

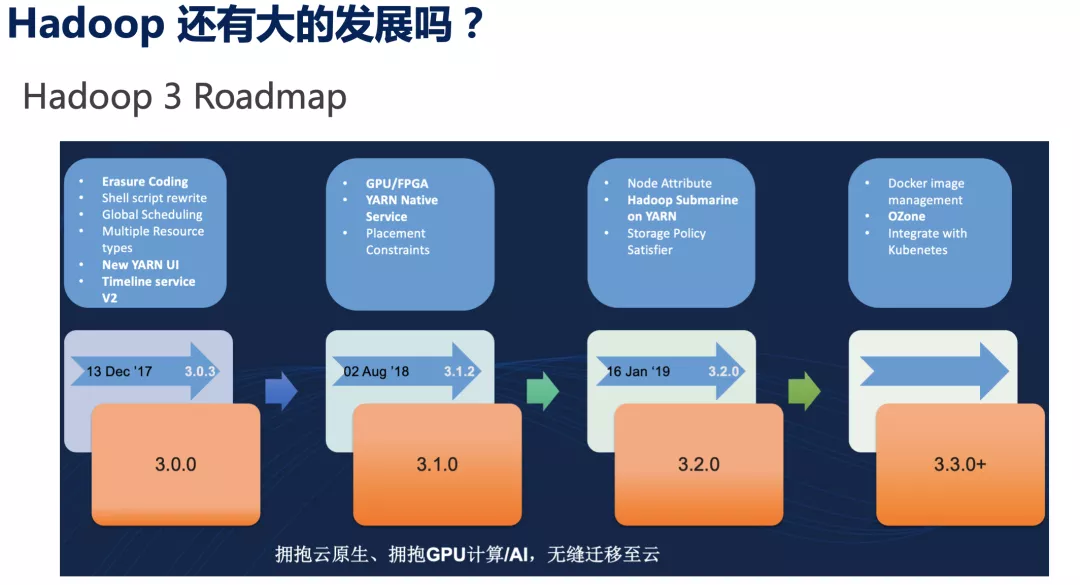
但是这里大家别忘了,Hadoop 是托管在 Apache 基金会的开源项目,Apache 的目的是为 public good,大众可以免费获取、使用和分发的。所以如果不想付费购买的话,那还有 Apache Hadoop 这个选项可以免费使用,毕竟一众互联网公司,都还用的是 Apache Hadoop(以它们的规模,只能用开源版),它们可以,为什么我不可以呢?话虽这么说,但是开源软件质量一般,没有服务,也没有 SLA 保证,出了问题只能自己去研究和解决,有问题发到社区,然后慢慢等结果吧,这个如果你能接受,那么可以雇几个工程师尝试一下。同时提醒你,市场上的 Hadoop 开发或运维工程师价格也是不菲的。如果你还在意 Apache Hadoop 未来的技术方向和潜力,不妨研究一下它的 roadmap;下面是摘自某次 Hadoop 社区的 meetup,上面可以看到 3.0 之后,Hadoop 的新功能就乏善可陈了,主要是一些跟 K8s、Docker 的整合了,这些对于大数据来说吸引力不足。
如果上面两个选择都不合你的胃口,那可能就剩最后一条路了:去 Hadoop,迁移到其它技术平台。
后 Hadoop 时代的大数据分析
前面分析了用户该如何面对后 Hadoop 时代,那么 Hadoop 生态的厂商,该如何应对呢?这里我以 Kylin 和 Kyligence 为例做一些经验分享。
Apache Kylin 项目和 Kyligence 公司都诞生于 Hadoop 时代,在最初的时候,我们的产品都是构建在 Hadoop 之上的。

在大概三年前,我们就已经敏锐地预判到,客户的需求逐渐在往云原生的、存储计算分离的方向上发展。在这样的行业趋势下,我们也对原有平台体系做了一些新的设计。
2019 年,Kyligence Cloud 宣布完全脱离 Hadoop 平台,底层使用云原生架构,存储使用云厂商的对象存储,例如 AWS S3、Azure blob storage、ADLS 等,计算使用 Spark+容器化,资源可以直接对接云平台的 IaaS 服务和 ECS。未来我们也希望能更进一步基于 Kubernetes 打造资源调度,可以让资源请求延迟更低、利用率更高。
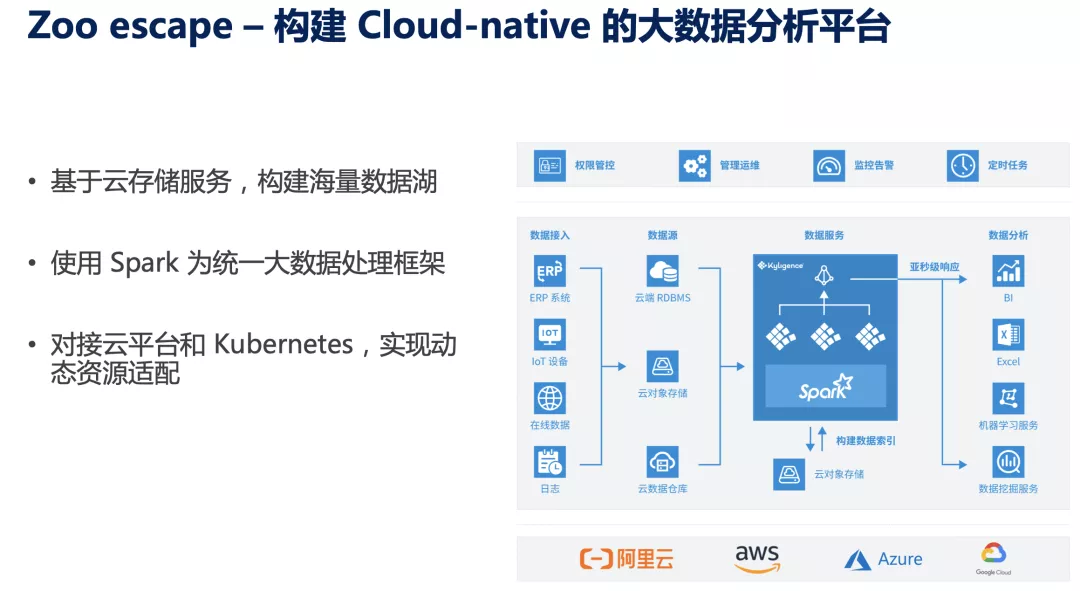
如今我们已经真切感受到这套体系架构带来的灵活性、可运维性以及低 TCO,在多个(特别是中小规模)客户得到非常积极的反馈;目前正在细致优化和打磨,同时向多个云做拓展。
未来,大数据热点在哪里
展望一下未来大数据分析的热点在哪里;这里我们不妨拿最近市场上炙手可热的 Snowflake 和 Databricks 来聊一聊。
Snowflake 上市的时候股价曾一度飙涨到每股 400 多美金,易用性是让 Snowflake 身价暴涨的一个重要原因。Snowflake 是一个把数据仓库做成 SaaS 服务的软件供应商,这种完全托管的服务对于用户使用变得非常简单,不再需要学习很多的数仓知识,也不需要学习如何优化模型、如何性能调优等,所有的资源申请、查询优化、出错重试等等都通过自动化解决了。目前 Snowflake 有超过 2000 家企业客户,市值达到千亿美金,已经超越了百年老店 IBM。
再来看看 Databricks,这是一个在云上面向数据分析师和科学家的一站式大数据分析平台,上层提供了一个功能丰富又简单的交互式 Notebook,用户可以直接手写 Python、Scala 或 SQL 进行数据分析和挖掘,底层计算使用 Apache Spark,存储使用 Delta 对接云存储服务,实现一致性和事务性。这两年 Databricks 在市场持续发力,目的就是希望能让分析师可以非常方便地使用他们的产品来做数据挖掘和预测。最近一轮 10 亿美金融资已经让 Databricks 的估值飙升至 280 亿美金。

为什么是他们受到了资本界的欢迎?可以看到无论是 Snowflake 或是 Databricks 都是基于公有云平台的,具有使用简单、弹性伸缩、按量计费、灵活取用等特点。Kyligence 所做的就是努力让产品更贴合时代的发展和用户的需求,Kyligence Cloud 为企业客户提供一站式大数据管理和分析服务,凭借经济高效的解决方案来支持企业日益增长的云上分析业务,简化大数据分析的流程,帮助企业进一步降低用户数据上云的整体拥有成本。
在国内,我们看到公有云的发展进程不及北美,这是不同国情及市场需求产生的结果。美国在云原生道路上的科技成果已经逐步显现成果,中国也在迎头赶超,我相信现在是一个非常好的时间点去投入研发力量、资源储备来打磨下一代大数据分析产品。
原文链接:




