
作者:刘春雷,58 同城架构师
58 同城是中国互联网生活服务领域的领导者,是国内最大的一个生活服务类的平台,涵盖了丰富多样的业务场景,包括车、房产、招聘,本地服务、金融等众多业务。
因为业务种类繁多,我们发现很难找到一款数据库同时满足所有业务场景的要求。不同场景对数据库的要求各不相同,比如金融场景对数据的可靠性要求高,直播场景则对高并发有着极高的要求,数据分析场景更注重存储成本和 AP 性能。因此,我们充分调研了多种数据库,包括 OceanBase、TiDB、StarRocks 等,以支撑 58 同城复杂多样的业务场景。
引入 OceanBase 主要是为了满足 TP 业务的降本增效需求,以及解决核心业务分库分表的痛点。OceanBase 经历过大量金融核心场景的打磨,在核心业务场景选型中占据极大优势。
技术选型
在调研时,我们考察了 OceanBase 的一些特性,另我们最看重的特性包括多租户及资源隔离、高压缩率、优秀的查询性能。
(一)多租户
我们有很多业务需要部署大量的数据库实例,通常一个业务会占用一个数据库实例资源,保证业务之间互相不影响。这就可能造成严重的资源碎片化,在某个关键业务或关键客户需求激增时,难以灵活、弹性扩展,性能和可用性难以保证。比如核心业务大数据量级 58 同城仍然采用 MySQL 分库分表的架构,在业务洪流高峰时,没有很好的弹性扩展手段,只能从应用层去做流量保护来保证业务和数据库的稳定性。
由于数据库资源的碎片化部署,单个实例为了保证一定的性能弹性空间,往往会多划出一部分容量作为短时间内请求增长的预备资源。这种资源预留在整体业务视角来看实际上造成了巨大的资源浪费,大大抬高了 58 同城的资源成本。
而且大量的数据库实例同时带来的还有管理效率的降低, 数据库相关团队难以对成百甚至上千的实例进行精细化管理,出现故障、抖动等事件时恢复时效差,对整体资源水位的把控难以全局掌控,又抬高了 58 同城的管理成本。
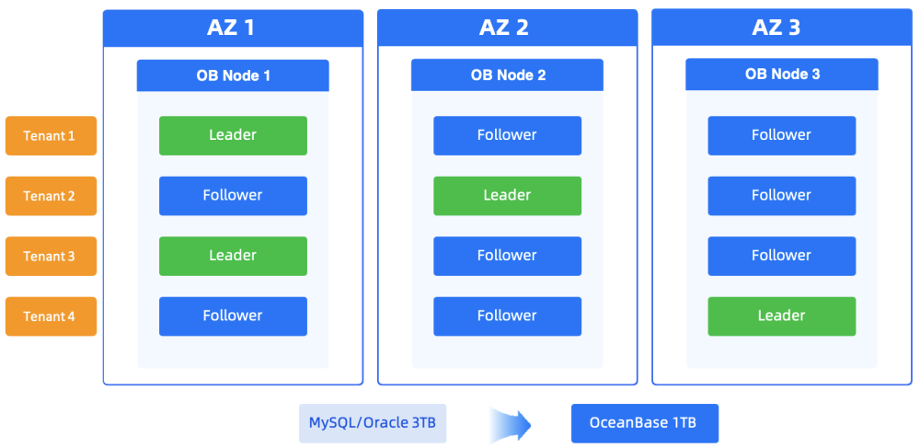
OceanBase 的优势在于,其多租户架构可以将多个不同业务的数据库实例集中整合,提升资源利用率,同时基于 Paxos 的多副本机制保证每个资源单元的高可用能力。这样就可以为不同业务提供不同规格的实例,保证资源隔离性的同时降低成本。
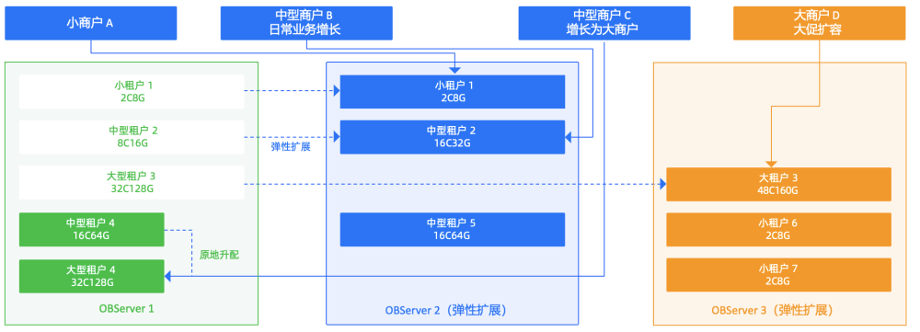
我们认为 OceanBase 多租户特性对 58 同城业务最大的帮助体现在以下三个方面。
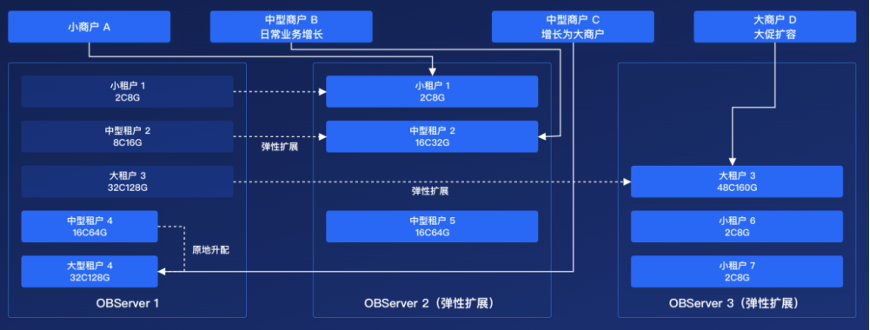
多租户池化:OceanBase 集群原生支持多租户下的资源隔离和虚拟化,一个集群中可以部署上百个数据库租户,租户间的数据和资源互相隔离,计算资源原地升级规格配置,秒级生效。
多维度弹性:基于 OceanBase 的单机分布式一体化式架构,可以实现单机原地升级配置、多机弹性扩展,多机流量均衡多个维度的扩容操作,并且扩容对上层应用透明。对于涉及数据迁移的扩展无需人工值守,可以自动完成迁移及多维度数据校验。
统一管理:把多个零散的实例统一部署在 OceanBase 后,运维管理的复杂度会大大降低,DBA 从之前管理数十个分散实例,到目前管理一个 OceanBase 集群,将负载、告警、调优全部统一至集群级别,常规故障能够自动恢复,大幅提升了业务支撑效率和应急响应能力。
(二)高压缩率
因为 OceanBase 的压缩率极高,所以我们也做了一个相对比较详细的调研。
OceanBase 支持不感知数据特征的通用压缩 ( compression ) 和感知数据特征并按列进行压缩的数据编码 ( encoding )。这两种压缩方式是正交的,也就是说,可以对一个数据块先进行编码,然后再进行通用压缩,来实现更高的压缩率。
通用压缩是在不感知微块内部数据格式的前提下,将整个微块通过通用压缩算法进行压缩,依赖通用压缩算法来检测并消除微块中的数据冗余。目前 OceanBase 支持选择 zlib、snappy、zstd、lz4 等算法进行通用压缩,可以根据表的应用场景,通过 DDL 对指定表的通用压缩算法进行配置和变更。
编码压缩的算法比较复杂,OceanBase 根据实际业务场景需求实现了单列数据的字典编码、 RLE 编码、常量编码、数值差值编码、定长字符串差值编码,同时还引入了列间等值编码和列间子串编码,能够分别对数据库中一列数据或几列数据间可能产生的不同类型数据冗余进行压缩。最后还可以再利用 bit-packing 编码、字符串 HEX 编码等,对已经编码过的数据再进行一层编码,进一步去除冗余的信息。
综上, OceanBase 相当于做了三层编码压缩:列内编码、列间编码,以及 bit-packing/hex 编码。
下面这两张图就分别是 bit-packing 编码和 hex 编码的示意图。
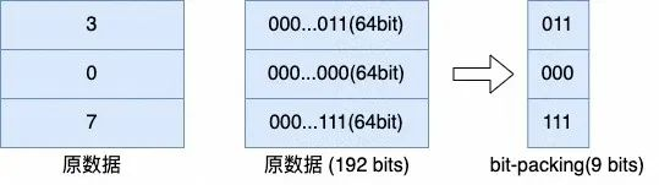
(bit-packing 编码)
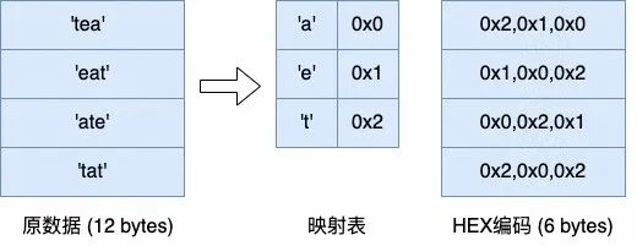
( HEX 编码)
此外,在编码压缩这一层还使用了自适应压缩技术,根据真实的数据特征自动选择最优的编码算法。因为数据编码的压缩效果不仅与表的 schema 相关,同时还与数据的分布,微块内数据值域等数据本身的特征相关,这也就意味着难以在用户设计表数据模型时指定列编码来实现最好的压缩效果。
为了减轻用户使用负担,也为了实现更好的压缩效果,OceanBase 支持在合并过程中分析数据类型、值域、NDV 等特征,结合合并任务中上一个微块对应列选择的编码算法和压缩率自适应地探测合适的编码,对同一列在不同数据块中支持使用不同的算法来进行编码。
(三)良好的查询性能
因为 OceanBase 有着极高的数据压缩率,所以我们特别关心 OceanBase 能否同时支持良好的查询性能。事实上, OceanBase 在设计数据编码格式时也考虑到了对查询性能带来的影响,我们了解到其中几种比较关键的提升查询性能的方法。
第一,行级粒度数据随机访问。通用压缩中如果要访问一个压缩块中的部分数据,通常需要将整个数据块解压后访问,某些分析型系统的数据编码大多面向扫描场景,而针对点查场景的数据编码较少。因此,OceanBase 采用了在访问某一行数据时需要对相邻数据行或数据块内读取行之前所有行进行解码计算的数据编码的格式(如 PFor 等差值编码)。
如果 OceanBase 需要更好地支持事务型负载,就意味着要支持相对更高效的点查,因此 OceanBase 在设计数据编码格式时保证了编码后的数据能够以行为粒度随机访问。也就是在对某一行点查时只需要对这一行相关的元数据进行访问并解码,减小了随机点查时的计算放大。同时,对于编码格式的微块,解码数据所需要的所有元数据都存储在微块内,让数据微块有自解释的能力,也在解码时提供了更好的内存局部性。
第二,计算下推。由于编码数据中会存储有序字典、 null bitmap 、常量等可以描述数据分布的元数据,在扫描数据时可以利用这些数据对于部分过滤,聚合算子的执行过程进行优化,实现在未解码的数据上直接进行计算。
OceanBase 对分析处理能力进行了大幅优化,一是将聚合与过滤计算下推到存储层执行(在后面落地实践的性能测试部分有提及),二是在向量化引擎中利用编码数据的列存特征进行向量化的批量解码等特性。在查询时充分利用了编码元数据和编码数据列存储的局部性,在编码数据上直接进行计算,大幅提高了下推算子的执行效率和向量化引擎中的数据解码效率。
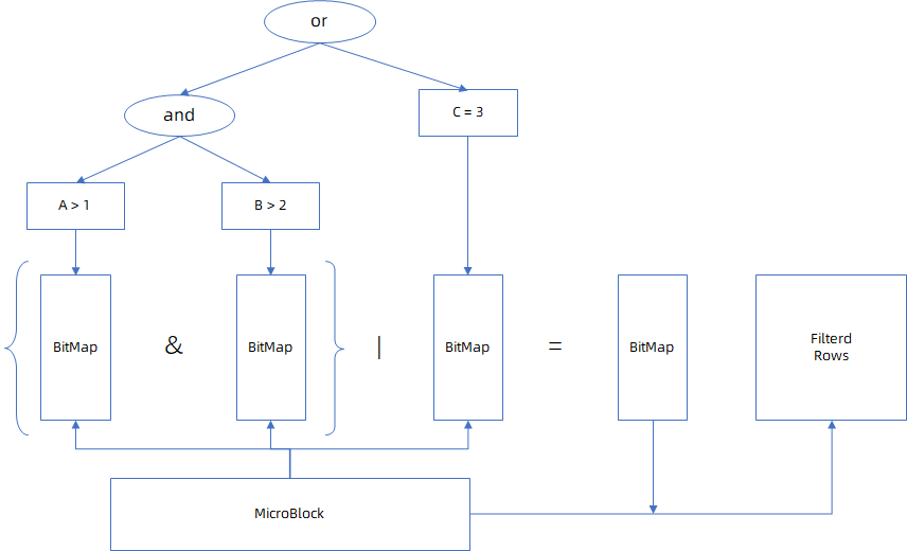
存储层的查询优化除了上面提到的行级数据随机访问和计算下推之外,还有 block cache、row cache、缓存解码器等手段。
当然,对于查询性能优化方面,起到更大作用的还是 SQL 层优化,而非存储层优化,不过我们暂时对 SQL 层的优化器和执行器还没有深入调研,这里就略去不提了。
而对于 OceanBase 的查询性能,我们进行了测试。例如最基础的 count 聚合测试,通常 DBA 习惯通过 count 看这张表有多少数据,相同的一张表,在 MySQL 里算 count 聚合要执行 1000 多秒,在 OceanBase 中只需要 0.03 秒。这是因为 OceanBase 的 scalar group by 会下压到存储层进行计算,可以直接利用存储层微块内部已经维护好的聚合信息让查询性能取得数量级的提升,对于我们最常用的聚合函数 count/min/max/sum 都是支持的。
比如在下面这个执行计划中,可以看到,1 号算子存储层 table scan 吐行的时候吐出来的数据就已经是 T_FUN_COUNT(t1.c1) 了,上层的 0 号算子 group by 就只需要再对存储层吐上来的各个微块的 count 信息求一个 count 的 sum 就好了,可以在计划里看到它确实也是这样做的:T_FUN_COUNT_SUM(T_FUN_COUNT(t1.c1))。
explain select count(c1) from t1;| ========================================|ID|OPERATOR |NAME|EST. ROWS|COST|----------------------------------------|0 |SCALAR GROUP BY| |1 |2 ||1 | TABLE SCAN |t1 |1 |2 |========================================Outputs & filters:------------------------------------- 0 - output([T_FUN_COUNT_SUM(T_FUN_COUNT(t1.c1))]), filter(nil), rowset=256, group(nil), agg_func([T_FUN_COUNT_SUM(T_FUN_COUNT(t1.c1))]) 1 - output([T_FUN_COUNT(t1.c1)]), filter(nil), rowset=256, access([t1.c1]), partitions(p0)除此以外,我们还测试了一些常用查询,比如查指定日期、指定集群的表大小的 top 10,在 MySQL 里是 0.04 秒,在 OceanBase 是 0.01 秒;查指定日期的表大小的 top 10,MySQL 里是 108 秒,在 OceanBase 是 28 秒。各种 SQL 的查询效率都会显著提升,对于最常用的聚合更有数量级的性能提升。
落地实践
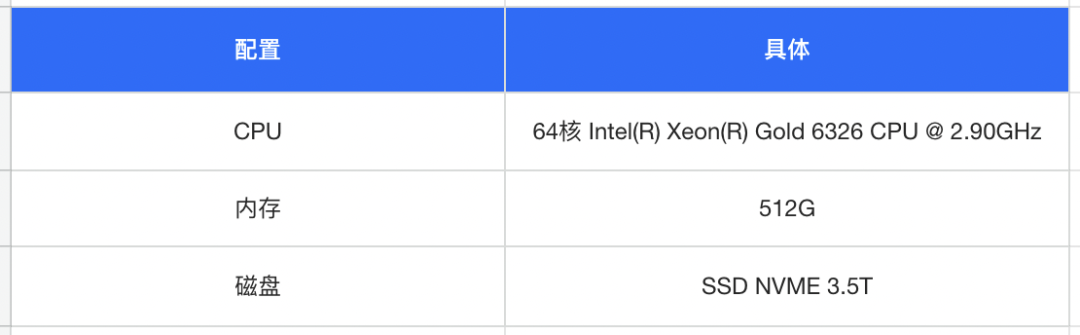
目前,58 同城优先将 DBA 使用的线上数据统计信息库迁移到了 OceanBase,进行运维和使用经验的积累,后续逐步将其他业务迁移到 OceanBase。我们使用 OceanBase 4.2.1 版本,搭建了一套 6 个节点的集群,机器配置如下表。
迁移到 OceanBase 的库存储了一些其他业务库的统计信息,比如存储 TiDB 业务库的实时慢 SQL、TiDB 业务库天级别慢 SQL、MySQL 业务库中表的基本信息和 SQL 的执行信息、Redis 业务库的链接信息等。
因为有些表的存储量很大,一张单表能达到 1.5TB,如果将大表放在 MySQL 中,查询分析时就会有明显的性能问题,所以我们之前大多数统计信息库都选择放在 TiDB 的不同集群中,比如线上所有 TiDB 集群的实时慢 SQL 放到一套 TiDB 集群里,TiDB 天级别的所有的慢 SQL 放到另一套 TiDB 集群里。
但是这些 TiDB 集群特别耗资源,原来每个业务的统计信息都对应一个 TiDB 集群,每个 TiDB 集群基本都需要 2 ~3 个 TiDB server,外加 3 个 PD,每台 server 都是 8 核 16G 虚拟机,每台 TiKV 是 40 核 256G 物理机。
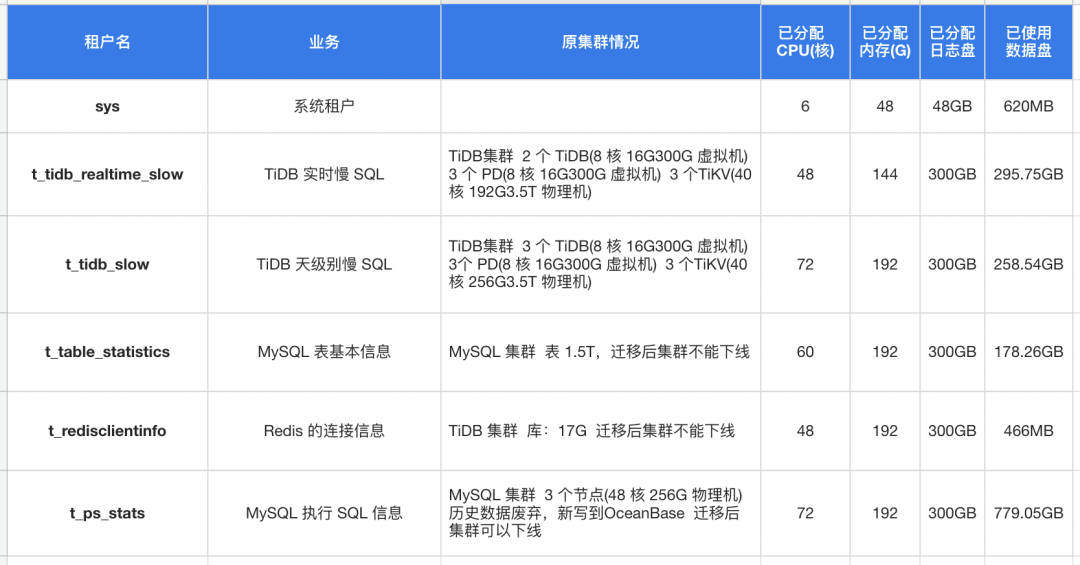
如今我们统一把上表的所有集群统一迁移到一套 OceanBase 集群上,不同业务的统计数据按照租户进行拆分。这样不仅利用 OceanBase 的高压缩比节省了存储空间(大约节省 50%),还能把节点数量也从 20+ 个缩减到 6 个,机器成本缩减了 5 倍。
此外,如果考虑到后续在 HTAP 场景中上线 OceanBase,替换现有的 TiKV 和 TiFlash 两套存储引擎,成本将节省更多。
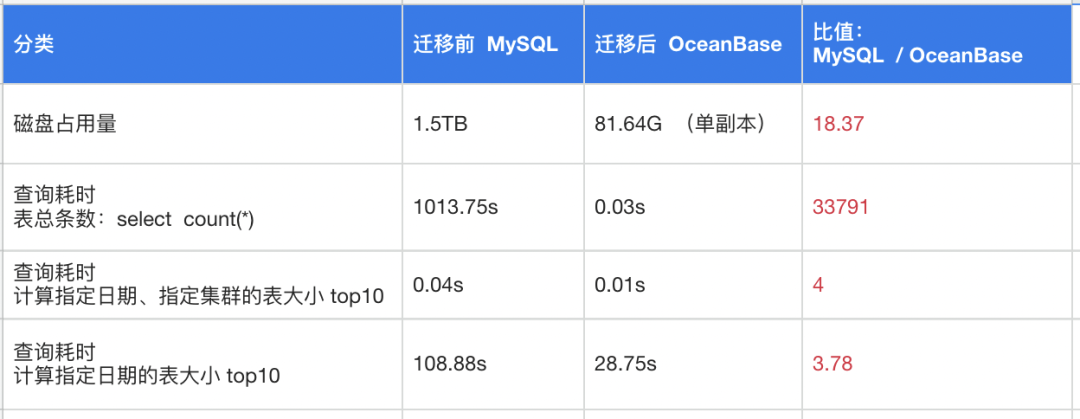
回到上线流程,我们使用 OMS 将一张 21 亿行的表从 MySQL 迁移到 OceanBase,迁移前的 MySQL 磁盘信息如下表。
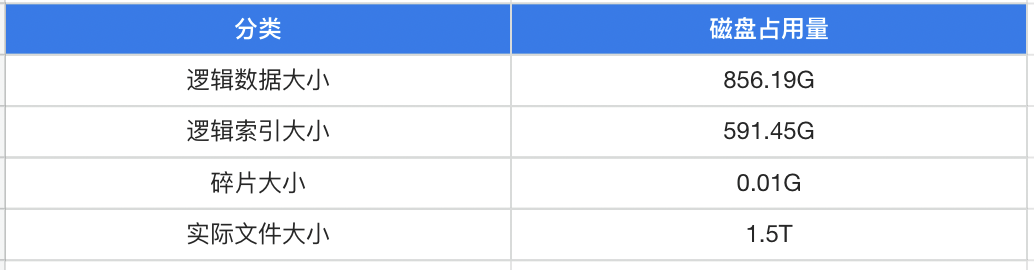
由于 OMS 可以选择迁移模式,我们没有选择高速迁移,而是选择平稳迁移模式耗费 11 小时完成迁移,大约每秒迁移五万多行数据。迁移后 OMS 会进行索引创建,我们选择单线程创建 4 个索引,耗费 7 个小时。官方建议选择多线程方式,可以更加快速地并行创建索引。
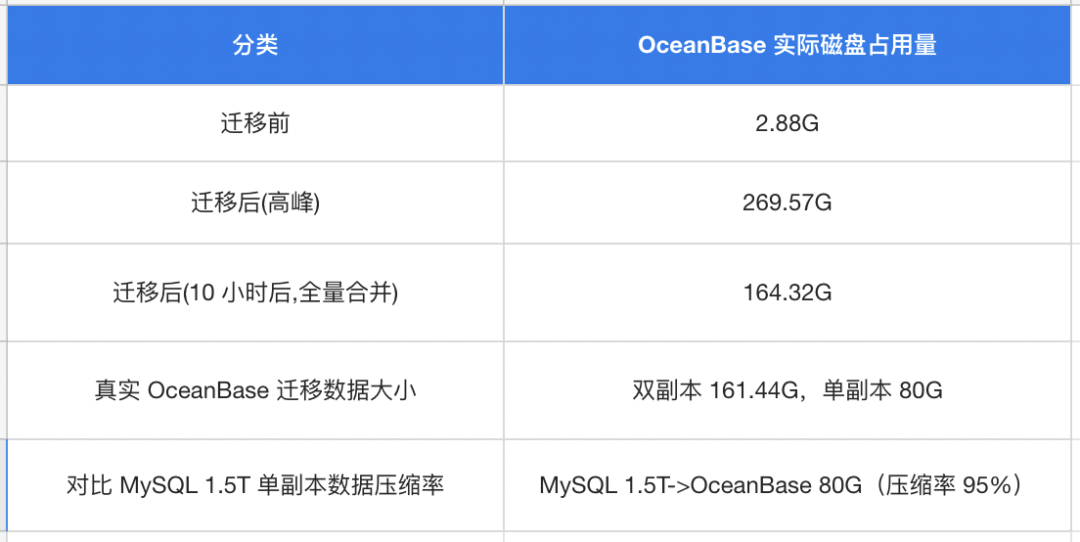
迁移完成后,会达到磁盘占用量的顶峰 259GB,全量合并后,数据约 157GB 。也就是说,MySQL 单副本 1.5TB 大表迁移到 OceanBase 后是双副本 155GB,从单副本来看的话,应该只有 80G 左右。整体的压缩率让我们很震惊,1.5T 变成 80G,压缩率达到 95%。
下图是迁移前后的存储成本和查询性能对比。
未来规划
从关注 OceanBase 到迁移上线,我们用了 6 个月时间,应用 OceanBase 后,最大的收获包括如下三方面。
首先,OceanBase 的多租户能力:支持我们把多个 MySQL 和 TiDB 的实例整合到一套 OceanBase 集群中,进行统一管理,租户间资源隔离,还可按需弹性扩展,在简化运维的同时有效提高资源利用率。
其次,基于 OceanBase 的高级压缩技术:在保证性能的同时,数据存储空间相比原先能够节省 3-5 倍左右,一些场景甚至可以节省将近 20 倍。同等硬件投入的前提下,可以让我们存储更多数据。
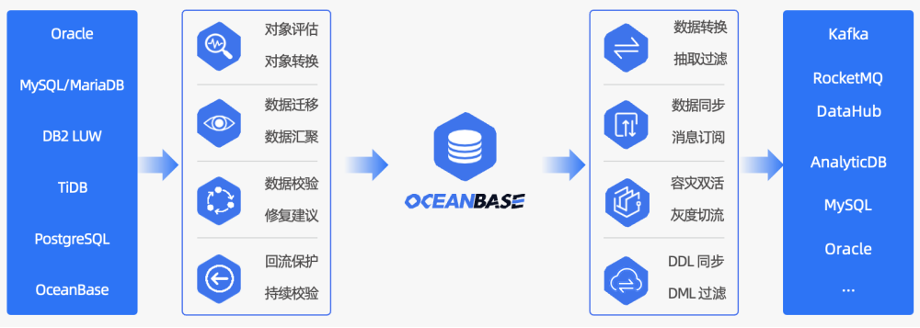
此外,数据迁移:因为 OceanBase 兼容 MySQL 协议与语法,所以我们可以利用 OMS 做到平滑迁移,大幅降低了业务迁移和改造成本。OMS 通过全量迁移、增量迁移、反向迁移,保障数据迁过程中的强一致,还提供了数据同步到 Kafka 等消息队列中的能力。
综合考虑 OceanBase 高压缩率带来的存储成本下降、各种内核实现优化带来的查询性能提升,以及超级好用的数据迁移工具 OMS,我们计划将后续大量 MySQL 的上百 GB 甚至上 T 级别的大表迁移至 OceanBase 。
除了 MySQL 场景以外,我们还尝试将资源占用极高的数据库也逐步替换成 OceanBase,以节省机器资源和存储资源。测试表明,OceanBase 查询性能也超越现有数据库 3~4 倍,完全满足我们的业务需求。
此外,我们将对 OceanBase 的 AP 能力进行深入调研和测试,使用 OceanBase 替换 升级,实现一套引擎同时处理 OLTP 业务和 OLAP 请求,降低运维复杂度和运维成本。




