
作者 | 刘东、韩其琛、赵雨森
大模型时代下新语言训练的挑战
在网易 CodeWave 智能开发平台中,NASL(NetEase Application Specific Language)可视化编程语言 作为产品核心,主要有以下三大作用:
承载完整应用不同粒度、多种领域的可视化编程结构的精确描述。 大到一个页面节点、一个流程节点,小到一个表达式、一个运算符。有通用的 基础语言部分,也有 Web 应用常见的特定领域(如数据定义、数据查询、页面、流程、权限等)子语言部分。
统一前后端各子领域的表达方式,降低学习门槛。NASL 统一了数据库、服务端逻辑、接口定义、页面逻辑、样式等的各种类型和表达式的编写形式。
对接各类语言设施,集成多种开发功能,** 增强综合使用体验。** 围绕 NASL 的语言设施有很多,比如提供增删改查、复制粘贴等功能的各类可视化设计器,提供多人协作、备份还原等功能的代码仓库,提供类型检查、查找引用等功能的 Language Server,提供断点调试、变量监视等功能的 Debugger,能生成前后端源码的语言生成器,提供局部模板、依赖库导入导出等功能的资产中心,……
而在大模型时代下,NASL 又起到了一大新的作用:AI 友好和快速落地 AI 功能 的作用。AI 友好主要体现在不需要让大模型生成传统编程的各种语言框架,减少代码量即 token 数、以及各层次之间的转换问题。快速落地 AI 功能主要体现在只要提供 AI 服务 + 交互输入 代替或融入原来可视化设计器的交互形式即可将 AI 能力快速引入到产品中。
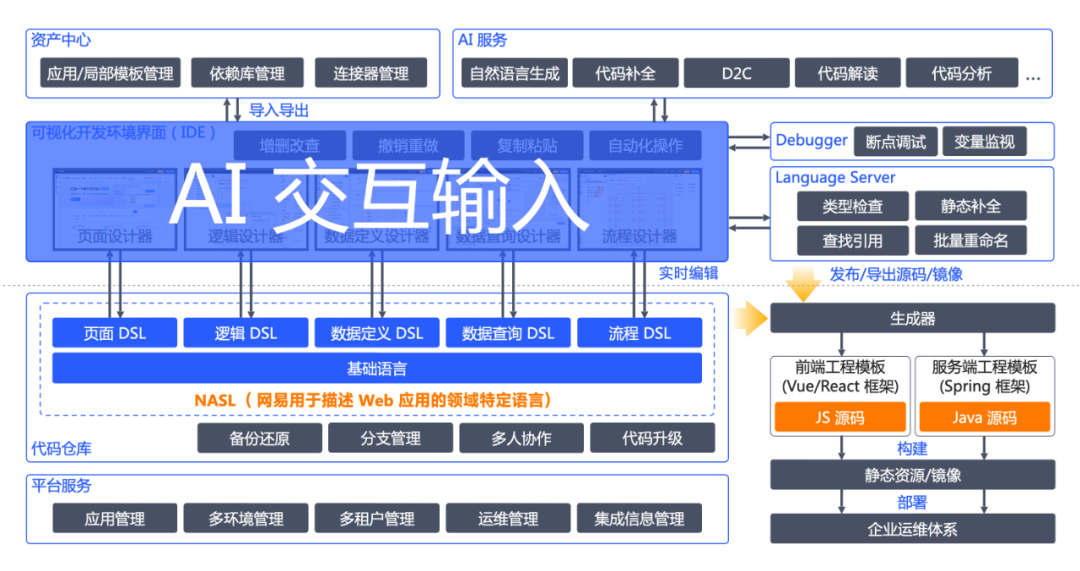
CodeWave 引入 AI 功能的产品架构图
然而让大模型生成一门新的语言,也给 CodeWave 技术团队带来了挑战。由于当前各家大模型均不具备 NASL 相关知识,经过产品实践,直接使用提示工程生成的内容在某些细节方面不太理想。下表是基于通用大模型 + 提示工程生成的 NASL 逻辑使用 HumanEval Benchmark 的评测,总体上只有 55.3% 的通过率。除了 25% 左右是工程侧和语言方面可以优化的问题,仍有 18.3% 的分数如果不通过模型训练就提升不了。
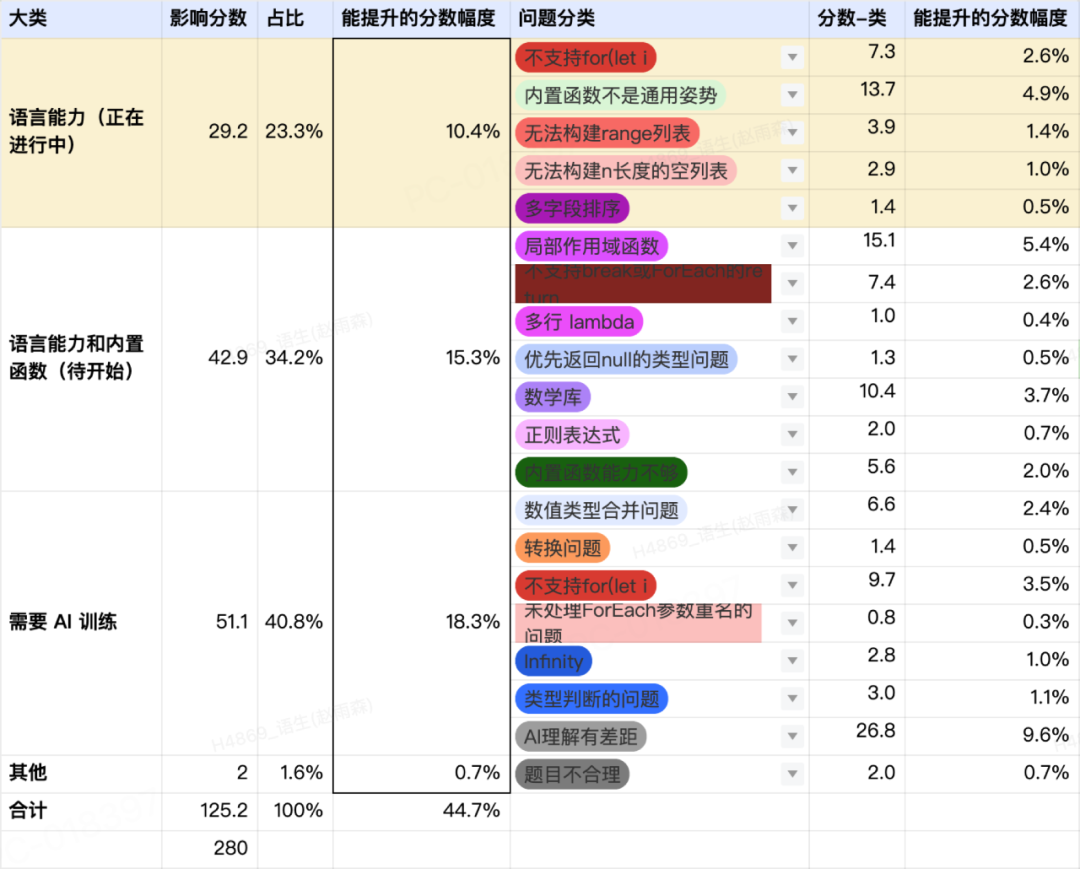
早期使用 HumanEval Benchmark 对生成 NASL 逻辑的评测
因此 CodeWave 技术团队持续研究对已有模型怎么进行微调训练,增加其在 NASL 领域的相关能力,来提升 CodeWave 中自然语言生成逻辑、代码补全等 AI 产品功能的效果。
NASL 大模型训练的主要流程
类似针对通用编程代码模型的训练工作,NASL 大模型的训练也大致包含以下环节:
1. 基座模型的选型和评测
模型训练的首要环节是选择一个合适的基座模型。
对于基座模型,一般会在六个关键方面进行评测,包括代码生成、代码补全、代码推理、长上下文生成、一般自然语言理解、数学推理。根据 NASL 语言的特点,我们主要测重对前四个方面进行评测,考察了目前最流行和最强大的各个开源语言模型基座,包括 DeepSeek Coder 系列、Qwen Coder 系列、StarCoder2 系列等,进行具体评测:
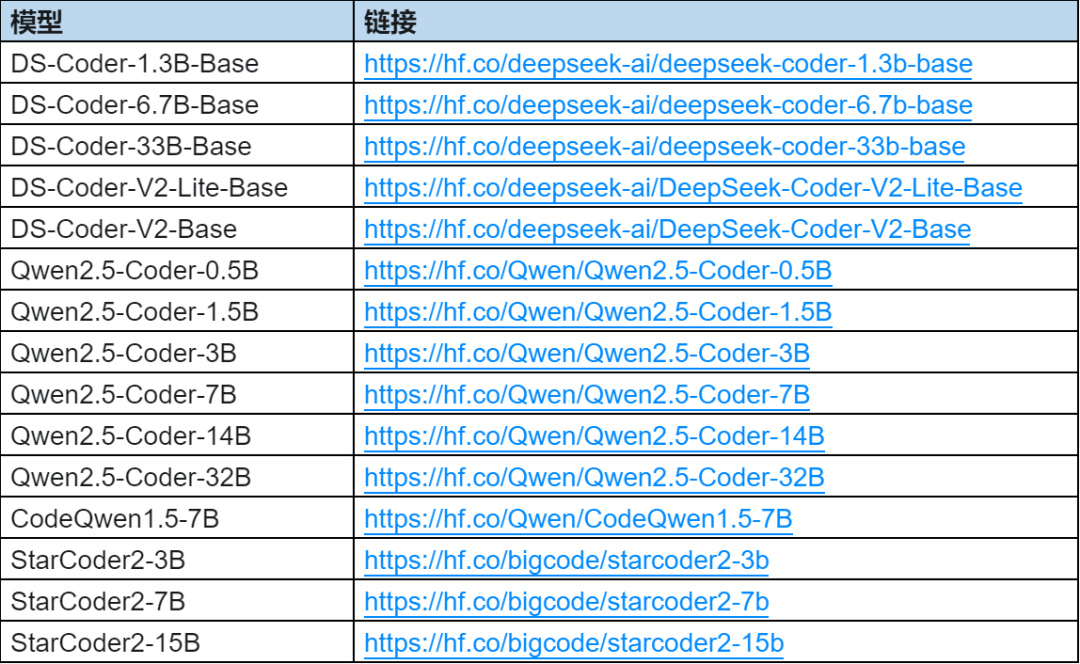
(1) 代码生成能力(Code Generation)
代码生成能力是代码模型处理更复杂任务的基础,流行的代码生成基准测试是 HumanEval 和 MBPP。HumanEval 包含 164 个手动编写的编程任务,每个任务都提供一个 Python 函数签名和一个文档字符串作为模型的输入。而 MBPP 包含 974 个开源贡献者创建的问题,包括一个问题描述(即文档字符串)、一个函数签名和三个测试用例。
为了确保更准确的评估,23 年 HumanEval+ 增加了 80 倍的测试用例,修正了 HumanEval 中不准确的真实答案。同样,MBPP+ 也提供了是原始 MBPP 35 倍的测试用例。
Qwen2.5-Coder 在基础代码生成任务上表现得最出色,在相同规模的开源模型中达到最先进的水平。
(2) 代码补全能力(Code Completion)
许多智能编程辅助工具依赖于基于前后代码片段的代码补全能力,CodeWave 的 NASL 补全也不例外。流行的代码补全基准测试包括 HumanEval-FIM、CrossCodeEval、CrossCodeLongEval、RepoEval 和 SAFIM 等。但 NASL 的补全需要根据用户数据自行构造。同时要考虑代码补全的体验重在即时性,对模型的规模有较大限制。
经过测评,NASL 代码补全选择 DeepSeek-Coder-1.3B-Base 的效果最好。
(3) 代码推理能力(Code Reasoning)
代码是一种高度抽象的逻辑语言,代码推理能力能判断模型是否真正理解了代码背后的推理流程。一般选择 CRUXEval 作为基准测试,包含 800 个 Python 函数及其对应的输入输出示例。它包含两个不同的任务:CRUXEval-I,要求大型语言模型(LLM)根据给定的输入预测输出;CRUXEval-0,要求模型根据已知的输出推断输入。对于 CRUXEval-I 和 CRUXEval-0,一般使用思维链(CoT)方法,要求 LLM 在模拟执行过程中按顺序输出步骤。
(4) 长上下文理解能力(Long Context Modeling)
长上下文理解能力对于代码大模型在处理复杂需求时很重要,它是理解仓库级代码和成为代码智能体的必要能力。然而,当前大多数代码模型对输入长度的支持仍非常有限,这阻碍了它们的实际应用潜力。在 CodeWave 的智能生成场景中,一般需要携带很多上下文,如实体、数据结构、逻辑定义等 应用上下文,扩展组件、依赖库、接口定义、连接器等平台资产上下文,以及用户打开的标签页、光标位置等 交互上下文。因此我们对支持 128k token 以上输入长度的模型特别关注,并进行了调研评测。
2. 数据准备
数据准备是模型训练中的关键环节。
虽然 CodeWave AI 工程化平台收集到了一定量的用户数据,但用户提供的高质量代码数量有限,远不及通用编程语言的数量。因此如何突破 “数据冷启动” 实现 NASL 大模型训练,是数据准备阶段面临的主要问题。经过对已采集的数据进行清洗和分析,我们决定主要采用数据合成的方式来构造数据。需要合成的数据主要是 “自然语言指令 -> NASL 代码答案”的问答对形式,下面是一个简单示例:
// 用户指令:接受一个字符串列表,并返回最短的字符串。如果有多个,返回第一个出现的字符串。// 合成的 NASL 代码:logic findShortest(strings: List<String>) => result { let lengths: List<Integer>; let minLength: Integer; let shortestString: String; if (Length(strings) == 0) { result = ''; end; } lengths = ListTransform(strings, { item => Length(item) }); minLength = ListMin(lengths); shortestString = ListFind(strings, { item => Length(item) == minLength }); result = shortestString; end;}(1) 指令收集和构造
和传统编程大模型的数据准备工作类似,我们汇总了多个开源代码数据集,提取了大量自然语言指令、代码答案和测试用例,结合 Codewave 使用场景合成了低代码指令作为补充。英文指令使用 LLM 翻译为中文,去重后共计 10W+ 的指令数据。
为了全面评价问答对的质量,我们为每个样本引入了多个维度的打分点:
问题和答案的一致性: 问答是否一致,是否正确,以便进行微调。
问答相关性: 问答是否与 Web 编程领域、CodeWave 产品功能相关。
问答难度: 问答是否具有足够的挑战性。
代码语法的正确性: 评价代码是否有语法错误,是否能解析回 NASL AST。
代码静态语义的正确性: 评价代码是否能通过静态检查,如类型检查、重名校验、参数范围等。
代码动态运行的正确性: 评价代码是否能通过测试用例,运行结果符合预期。
易理解性和最佳实践: 评价代码是否容易理解,是否遵循 CodeWave 使用的最佳实践。
在打完各项评分后,通过权重求和计算得出每个样本的总分,便可评价问答对的质量。
(2) NASL 语言沙箱
上文中的打分点前 3 点侧重于对问题质量的评价,以人工打分为主;后 4 点侧重于对代码答案质量的评价,不仅可用于对样本的评价,也可用于对大模型生成结果的评价。
为了自动化高效地验证代码各方面的正确性,考虑到 CodeWave 真实环境编译时间过长、需要与之隔离等问题,CodeWave 编程语言实验室实现了一套轻量级 NASL 语言沙箱,在一台训练机器上就可以部署大量进程,主要用于检查 NASL 代码语法和语义的正确性、在隔离环境安全地执行代码、将代码执行的输出结果与测试用例的预期结果进行比较和汇总。
NASL 沙箱具体包含以下几个部分:
语言编译器:
解析器: 将 NASL 文本解析成 NASL AST,并同时判断语法正确性
语言服务: 对语言进行静态检查,主要包括类型检查、重名校验、参数范围等
最佳实践检查: 静态分析代码是否符合最佳实践,比如是否用了更合适的内置函数,循环中是否用了数据查询等
代码执行引擎:
环境隔离: 为了安全执行代码,与部署机器隔离
并行执行: 能够并行执行多个测试用例、多个代码测试请求、多套上下文环境
资源分配和超时机制: 针对超时的执行进程能够及时释放,比如死循环代码引发的超时等问题
系统和浏览器环境模拟: 支持对当前日期时间、域名、浏览器设备信息进行模拟
数据库环境模拟:NASL 运行时的测试经常需要数据库中有合适的数据,沙箱支持创建轻量级数据库,并且快速建表和填充数据
资产的接入和模拟: 支持依赖库、组件库、接口、连接器等资产接入,可以模拟接口、连接器的实现等
结果分析器:
结果比较: 将代码执行的输出结果与测试用例的预期结果进行比较,对嵌套结构会进行深度比较
报告汇总: 汇总生成测试用例成功和失败的详细报告
(3) 多轮反馈机制的答案合成
开源代码数据集中包含大量自然语言指令,但代码答案是通用编程语言的,所以需要用通用大模型 + 自然语言指令提示词的方式合成 NASL 代码。但由于各家大模型均不了解 NASL,即使输入 NASL 语言的完整说明书,大模型也很难生成语法语义正确的 NASL 代码。
因此我们引入了多轮反馈机制,将沙箱编译和运行时的报错信息即时反馈给大模型,让大模型对生成的代码进行修改,反复执行这个过程,直到生成的结果正确或者达到预定的最大修改轮数(比如 5 轮)。
刚开始,主要使用 gpt-4o/4o-mini 作为数据合成的核心 LLM。当指令比较简单时,比如简单算法、简单数据查询,经过几轮局部的细节修改,基本可以生成完全正确的 NASL 代码,比如:
// 用户指令:根据申请状态查询请假申请记录,支持分页,按申请时间升序排列// 第 1 次生成logic queryLeaveRequests(applyStatus: app.enums.ApplyStatus, page: Integer, size: Integer) => result { result = for LeaveRequest in app.dataSources.defaultDS.entities.LeaveRequestEntity where LeaveRequest.applyStatus == applyStatus order by LeaveRequest.createdTime asc; result = Paginate(result, page, size); end;}// NASL 沙箱解析器报错:缺少 select 语句// 第 2 次生成logic queryLeaveRequests(applyStatus: app.enums.ApplyStatus, page: Integer, size: Integer) => result { result = for LeaveRequest in app.dataSources.defaultDS.entities.LeaveRequestEntity where LeaveRequest.applyStatus == applyStatus order by LeaveRequest.createdTime asc select { leaveRequest: LeaveRequest }; result = Paginate(result, page, size); end;}// NASL 沙箱最佳实践报错:语句顺序不是最佳实践,期望的调用顺序为 for -> join -> where -> group by -> select/aggr select -> having -> order by -> paginate// 第 3 次生成logic queryLeaveRequests(applyStatus: app.enums.ApplyStatus, page: Integer, size: Integer) => result { result = for LeaveRequest in app.dataSources.defaultDS.entities.LeaveRequestEntity where LeaveRequest.applyStatus == applyStatus select { leaveRequest: LeaveRequest } order by LeaveRequest.createdTime asc; result = Paginate(result, page, size); end;}// NASL 沙箱类型检查报错:赋值:类型不一致!右边类型:{ list: List<{ leaveRequest: LeaveRequest; }>; total: 整数 ; },左边类型:List<{ leaveRequest: LeaveRequest; }>。result = paginate(result, page, size)// 第 4 次生成logic queryLeaveRequests(applyStatus: app.enums.ApplyStatus, page: Integer, size: Integer) => result: { list: List<{ leaveRequest: app.dataSources.defaultDS.entities.LeaveRequest }>; total: Integer;} { result = for LeaveRequest in app.dataSources.defaultDS.entities.LeaveRequestEntity where LeaveRequest.applyStatus == applyStatus select { leaveRequest: LeaveRequest } order by LeaveRequest.createdTime asc paginate page, size; end;}// NASL 沙箱编译成功,类型检查成功,合成结束。(4) 采用深度思考的 DeepSeek-R1 模型合成答案收益显著
但当指令稍微复杂一些,比如既要做数据查询又要基于查询结果做逻辑处理的情况,采用非推理类模型,模型无法充分理解和遵循 NASL 语法语义的所有要求,基本都无法生成正确的结果。往往是在修复一个问题的同时又引入了其它问题,严重降低了数据合成的成功率和效率。
在这种情况下,我们引入了 DeepSeek-R1 模型,经过思考的过程,让模型充分注意到语法中的各项要求。并且在收到错误反馈后,也更善于从整体实现的角度去进行修复,显著提升代码生成的成功率。在合成数据的对比中,相比非深度思考模型有着显著的收益:

下面通过一个例子来对比 DeepSeek-R1 模型和原模型的效果差异。原来使用 gpt-4o-mini 经过 5 轮修复后,编译或运行仍然有问题:
// 用户指令:根据是否显示的标志查询咖啡信息,并返回 CoffeeOrderItem 列表// 已知 CoffeeOrderItem 如下:struct CoffeeOrderItem { /* 咖啡 */ coffee: app.dataSources.defaultDS.entities.Coffee; /* 下单数量 */ count: Integer;}// gpt-4o-mini 经过 5 轮修复后的结果,但编译仍然有问题logic loadCoffeeByIsDisplay() => coffeeList: List<app.structures.CoffeeOrderItem> { coffeeList = for Coffee in app.dataSources.defaultDS.entities.CoffeeEntity where Coffee.isDisplay == true select { coffee: Coffee, count: COUNT(Coffee.id) // 这里假设数量是根据咖啡 ID 的数量来计算的 } ); end;}错误原因是这里 CoffeeOrderItem 中 count 属性只是用于前端下单时的数据占位。但 gpt-4o-mini 无法理解这点,习惯性当作聚合函数 COUNT 的语义来返回。即使 NASL 沙箱给出提示,gpt-4o-mini 依旧无法给出正确的代码。DeepSeek-R1 只要单轮就能生成正确结果。R1 的输出结果如下,可以看出, R1 一开始也考虑使用 COUNT 聚合函数,但它经过自我反问,很快意识到这一点不符合要求,随后推理出只能在数据查询之后用逻辑来进行处理。
/** r1 的思考过程:好的,我需要根据用户提供的 NASL 语言定义和项目上下文,编写一个函数来查询咖啡信息并返回 CoffeeOrderItem 列表。首先,用户的需求是根据是否显示的标志查询咖啡信息,所以需要用到数据库查询。根据 NASL 的限制,必须使用 FROM 函数来构建查询链。项目上下文中,Coffee 实体有一个 isDisplay 字段,而 CoffeeOrderItem 需要包含 Coffee 实体和下单数量 count。但用户指令中没有提到数量的来源,可能需要进一步确认,但假设 count 可能是一个聚合值、固定值或需要其他处理,但根据结构体定义,可能需要从查询结果中构造。接下来,我需要使用 FROM 函数,传入 CoffeeEntity,并在回调中构建查询链。WHERE 条件应该是 Coffee.isDisplay 等于传入的参数,但用户函数头没有参数,可能需要调整。不过根据指令,可能 isDisplay 是作为过滤条件,但函数没有参数,可能默认查询 isDisplay 为 true 的记录?然后,在 SELECT 部分,需要构造 CoffeeOrderItem 的结构,即 coffee 字段和 count 字段。但 count 的来源不明确,可能需要设置为 0 或其他值,或者可能有其他逻辑。但根据结构体定义,count 是 Integer 类型,可能需要从查询结果中获取,但当前上下文中没有相关数据,可能需要默认值,比如每个咖啡记录 count 设为 0。此外,需要注意 SELECT 的命名规范,转换表名和字段名的首字母小写。例如,Coffee 实体在 SELECT 中应转换为 coffee,结构体字段名保持不变。最后,将查询结果转换为 CoffeeOrderItem 列表。可能需要使用 ListTransform 来处理查询结果,添加 count 字段。或者,在 SELECT 中直接构造结构体,但需要确保字段匹配。检查 NASL 的限制,确保不使用禁止的语法,如循环,而是使用内置函数。同时,确保正确使用实体和结构体,避免类型错误。*/logic loadCoffeeByIsDisplay() { // 查询所有 isDisplay 为 true 的咖啡信息 let coffeeList = for Coffee in app.dataSources.defaultDS.entities.CoffeeEntity where Coffee.isDisplay == true select { coffee: Coffee, } ); // 转换为 CoffeeOrderItem 列表并设置数量为 0 result = ListTransform(coffeeList, { item => new app.structures.CoffeeStructure({ coffee: item.coffee, count: 0 }) }); end;}(5) 数据后处理
数据后处理是一个规则模块,根据模型评测中发现的代码和数据问题,设计进一步的过滤和组装策略。
过滤模块: 总结分析模型评测过程中发现的问题,定位到训练集中的错误数据样本,设计使用规则对其快速过滤,提升训练集质量。
组装模块: 根据实际使用的场景,对已有数据进行重新组装,保证输入的数据与线上真实场景的上下文环境保持一致。
3. 监督微调(SFT: Supervised Fine Tuning)
我们采用了从粗到细的多阶段训练方案,先使用初始构造的数据集训练得到初始模型,再基于训练后的模型做拒绝采样,利用 NASL 沙箱对采样代码进行验证,将验证通过的数据回流到数据集中,以此丰富数据集的多样性并提升数据质量。
另外在不同阶段对模型效果进行分析评测,针对分析结果进一步调整数据配比和数据质量。重复以上过程,直至达到比较稳定的效果。在 NASL 模型微调中,所有参数优化均采用 LORA 方案。
4. 偏好对齐(Preference Optimization)
本阶段在 SFT 模型的基础上,通过提供明确的负反馈信息,来强化模型输出与人类偏好的对齐程度,采用 DPO(Direct Preference Optimization)的算法方案。
对微调后的模型进行采样,根据 NASL 沙箱反馈作为正负样本划分依据,构造<问题, 正确代码, 错误代码>三元组数据,用于离线强化学习的训练。
总结与后续规划
目前 NASL 大模型在多领域多场景的训练过程中,基座模型的选择与数据准备的合成阶段根据评测效果按需采用 DeepSeek 模型。比如代码补全重在体验的即时性,对模型的规模有限制要求,因此目前 NASL 代码补全的模型基座选择的是 DeepSeek-Coder-1.3B-Base。而在数据准备的指令和答案合成阶段深度使用了 DeepSeek R1 模型,特别是答案合成,在切换用深度思考的 DeepSeek-R1 模型之后,收益显著。
最后,CodeWave 团队针对产品中各项 AI 功能,正在对接 DeepSeek R1 的满血版和残血版进行全面评测。也在持续关注和跟踪 DeepSeek 深度思考、Coder、多模态等各类模型的后续发展。




