
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2020 年 OSDI 期刊中的论文 —— Thunderbolt: Throughput-Optimized, Quality-of-Service-Aware Power Capping at Scale1,该论文实现的 Thunderbolt 可以在数据中心实现电力资源的超售,电子资源的超售可以使同一个数据中心运行更多的服务器,从而提高数据中心的整体性能并减少日常的维护开销、降低成本。
超售系统的目的都是降低成本并提高利用率,但是也都面临着资源过度使用的潜在可能,这也就需要引入限制和保护系统在影响系统之前或者之时及时止损,正如航空公司会超售机票一样,一旦超售的航班全满,就会采用升舱、换飞机或者赔偿等方式解决问题,避免事态的进一步恶化。
图 1 - 资源超售
现代的计算集群都会同时运行延时敏感型的在线服务和面向吞吐量的批处理工作负载,在运行期间一旦发生突发事件,我们会通过 Linux 内核的 CPU 限制等机制优先保证前者的延时,并在没有突发情况的机器上使用后者提高集群的资源利用率。
延迟敏感型的在线服务往往可以容忍宕机,但是它们需要保证程序执行期间有稳定的性能和资源,这些服务在遇到性能问题时更倾向于调度到其他资源充足的机器上;而面向吞吐量的批处理任务其实可以容忍资源的不稳定,但是一旦调度到其他机器上,可能需要重新计算,这就浪费了大量的计算和网络资源。
图 2 - 电力超售和混合部署
从调度的角度上来看,论文中 Thunderbolt 要解决的问题和混合部署、计算资源超售的场景非常相似,它们两者都希望保证集群中的两种类型服务的延迟和吞吐量,只是 Thunderbolt 会将电力资源作为约束条件,而后者的目的是更高的资源利用率,这也是作者对这篇论文感兴趣的原因。
Thunderbolt 使用如下所示的架构设计,图中的四个蓝色方块就是该系统的几个核心组件,我们能从图中清晰地看到该系统的数据流向:
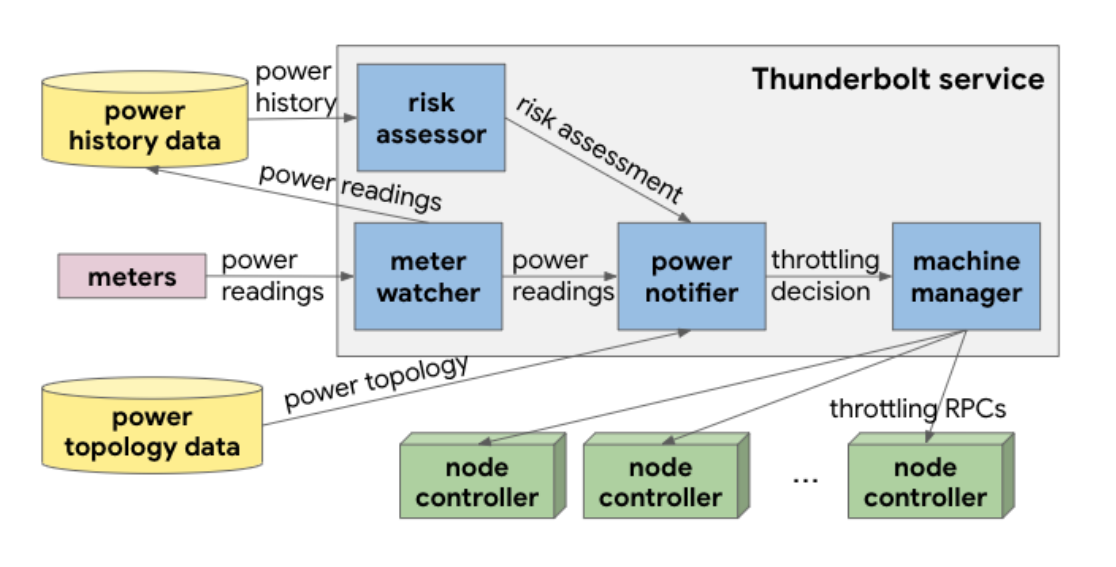
图 3 - Thunderbolt 架构
上述架构中包含两个不同的电力限制路径,分别是根据实时数据决策的反应式限制(Reactive Capping)和被称为故障转移机制的主动式限制(Proactive Capping),这两种限制策略会在不同情况下触发。
反应式限制:会监控电表发出的实时电力信号,当集群占用的电力功率高于特定数值时就会限制 CPU 的使用;
主动式限制:当电力信号变得不可用时,主动式限制会接管整个系统,根据历史的数据评估机房断路器切断电源的风险,如果评估的风险过高,也会限制集群的 CPU 使用;
反应式限制
因为 CPU 的利用率能够很好地指示当前任务使用的 CPU 功率,所以我们可以通过限制 CPU 来降低整个集群中服务器消耗的电力。Thunderbolt 使用 Linux 内核的完全公平调度器(Completely Fair Scheduler)精确的控制节点中进程的 CPU 占用,以此来控制节点占用的资源:
独立的任务会运行在它们自己的 Linux 控制组(Cgroups)中,调度器提供了两个用于控制 CPU 使用量的参数,即 quota 和 period,其中 quota 是当前工作负载在每个 period 能够得到的执行时间,它们的单位都是微秒。如上图所示,当 quota 为 20,000、period 为 100,000 时,当前控制组中的任务在每 100ms 的时间周期中都会获得 20ms 的执行时间。
同一个节点上的不同任务会分别属于不同的控制组,我们可以通过调节它们的参数为不同的任务设置不同的服务质量。而 Thunderbolt 会利用上面这点将延迟敏感型的任务设置成高优先级,将面向吞吐量的的任务设置成低优先级,在电力资源不足时限制后者的 CPU 使用。
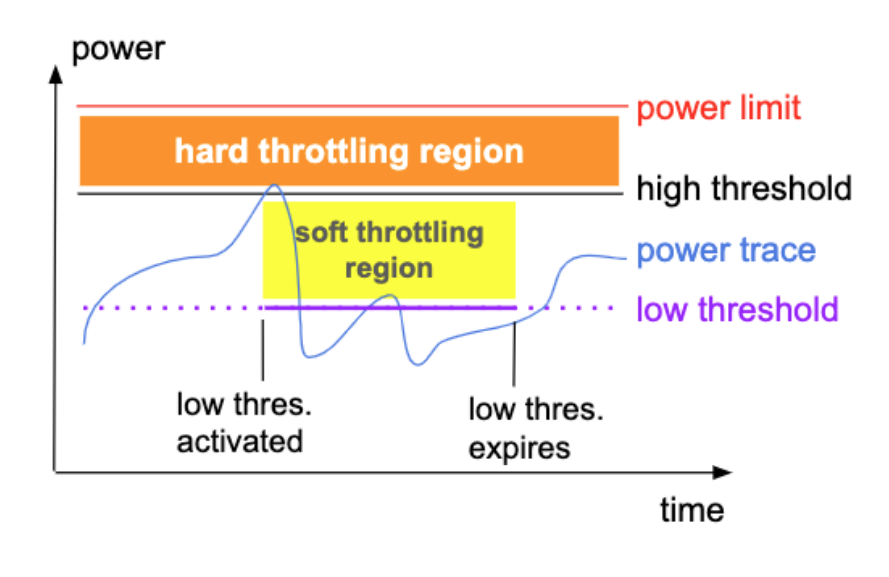
图 4 - 流量塑形
虽然我们会使用 CFS 限制工作负载的 CPU 使用,但是仍然需要上面的流量塑形控制策略决定应该何时限制以及如何限制 CPU 的使用量来控制集群的电力用量。在上述折线图中,包含两个不同的限制区域:
硬限制区域:当节点的电力用量进入硬限制区域时,会将 CPU 的使用量减少 99% 防止过度使用资源,同时会立刻创建一段软限制区域;
软限制区域:当节点的电力用量进入软限制区域时,会将 CPU 的使用量在一定时间内减少 25%,随后电力使用会在软限制区域区域下来回震荡,直到走出软限制区域;
软限制区域仅会在机器的能源使用进入硬限制区域时才会触发,同时会在一段时间后消失,减少对当前节点的电力资源的使用限制。
主动式限制
主动式的限制策略更像是一种故障转移的保护策略,当集群中的电表变得无法工作时,我们仍然需要保证集群的稳定。但是因为实时电力资源的缺失,我们没有办法使用上面的反应式策略,系统需要根据历史数据和服务质量决定每个任务分配的 CPU 资源。在这种策略下,使用 Linux 的 CFS 为工作负载动态分配资源是很难的,我们会直接将逻辑 CPU 从任务的 CPU 亲和(Affinity)中移除以减少资源的消耗。
与反应式策略仅会限制面向吞吐量的工作负载不同,当电表不能提供实时可用的数据时,CPU 的禁用会应用到集群中的全部的负载上,在这时我们只能牺牲在线服务的性能保证整个集群的电力安全,避免断电带来的大型事故。
总结
作为普通的软件工程师,在看这篇论文之前从来没有考虑过电力供应对数据中心带来的影响,也没有想过可以通过超售电力资源降低数据中心的成本。但是虽然我们没有遇到过这个问题,但是我们也可以从类似的问题中寻找答案,例如:集群中的计算资源超售和混合部署与论文中的场景有相似的解决方案。
这篇论文其实从不一样的角度开阔了我们的视野,让我们能从集群之外的物理世界考虑如何降低成本并提高能效,试想除了电力资源、计算资源的超售,我们还可以超售哪些资源呢,相信从这个角度出发,可以套用相似的逻辑解决不同的问题。
推荐阅读
Li S, Wang X, Zhang X, et al. Thunderbolt: Throughput-Optimized, Quality-of-Service-Aware Power Capping at Scale[C]//14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020: 1241-1255. ↩︎
本文转载自:Draveness




