
作者 | 易点天下数据平台团队
近年来数字化搞得如火如荼,越来越多的人意识到数据的重要性。面对爆发式增长的数据,如何让数据有序的存储,快速的查询产生价值是数据仓库考虑的问题,也是 OLAP 引擎主要解决的问题。因此也产生了一批优秀的开源 OLAP 引擎,例如 Kylin、Druid、ClickHouse、StarRocks 等。
易点天下作为一家技术驱动发展的企业国际化智能营销服务公司,公司积极采用大数据和人工智能技术来落地和推动业务的发展。随着公司业务的扩展,数据处理需求日益增多,业务快速迭代和发展的情况下,不仅缺少数据仓库的标准化规范设计,而且缺少一款集实时离线为一体的数仓统一解决方案,鉴于此情况,我们对数仓进行了统一规划和建设。
数仓建设规范
数据分层
数据引入层 ODS (Operational Data Store) :存放未经处理的原始数据,包括埋点上报日志数据,数据库抽取的结构化数据。明细数据层 DWD (Data Warehouse Detail):主要要完成对 ODS 层的数据清洗,脱敏,维度退化,压缩格式转化。汇总数据层 DWS (Data Warehouse Summary) :DWS 层就是关于各个主题的加工和使用,是宽表聚合值。数据应用层 ADS (Application Data Service) :ADS 层是面向业务定制的应用数据层。维度层 DIM (Dimension) : 基于维度建模理念,建立整个企业的一致性维度。低基数维度数据一般是配置表,比如枚举值对应的中文含义,或者日期维表,国家地域维表;高基数一般是用户信息表、产品信息表类似的资料表。
业务类和数据域定义
此定义主要规范数据仓库处理数据的范围,以及处理数据的业务类型,此模块需要结合业务具体分析,例如:
业务类:广告投放类,创新类,推广类,电商类
数据域:收入 revenue,花费 cost,投放 dsp,渠道 channel
数据指标
原子指标
原子指标是指用户行为直接产生的那些数据,比如说展示(Impression)、点击(Click)、访问(Visits)、购买(Purchase)、消费的金额(Sale),这些数据是实实在在的,不可分的。有一个可以直接区别原子指标的方法,那就是它们都可以直接求和。原子指标有着默认的维度——时间。
复合指标
是指那些通过原子指标计算而得到的指标,复合指标不可以直接求和。复合指标包含了各种转化率(Conversion Rate)和各种平均指标。
像点击率(CTR)、跳出率(Bounce Rate)、投资回报率(ROI) 这样的复合指标是转化率类型的复合指标。
像平均点击价格(CPC)、每千次展示成本(eCPM)、平均单次访问页面数(Pageview per Session)这样的复合指标是平均值类型的复合指标。
派生指标
基于原子指标进行维度、统计周期的派生,派生指标 = 统计周期 + 派生维度 + 过滤条件 + 原子指标,如近 7 天账户消费金额,去年账户余额总和、昨天产品销售金额等。
数据模型规范
良好的数据模型规范有助于开发和数据分析师对数据的管理和探索,保障了数据的一致性,准确性和易用性。我们从下面三个方面来规范数据模型。
命名规范
数据分层 _ 业务分类 _ [数据域] _ 自定义 _ [过程] _ [存储方式]
ods_innovate_cost_channel_test_kf
dws_innovate_cost_channel_mv
业务分类:game,adv,innovate …
过程表示:测试表加 _test 后缀,开发表加 _dev,归档备份表加 _arch,kf 表示 kafka 外表,s3 表示基于 s3 的外表, oss、obs、mv 表示视图表。正常线上的内表在自定义后就结束了。
存储规范
ODS 日志两种存储方式:1. 必须要分区字段 2. 离线日志以 gz 压缩 3. 实时数据 Kafka 接入
DWD/DWS 层存储格式:1. 必须有分区字段 2. ORC 格式存储
ADS 层存储要求: 1. 数据可以 delete 2. TP99 达到 5s 以内
数据规范
从埋点收集 ODS 到 DWS 数据,再到 ADS 数据,有统一的数据处理规范才能有效避免不必要的数据质量问题。
例如针对数据规范我们一般从下面两个方向处理:
分区规范
日期 day,格式 YYYYMMDD
小时 hour,格式 HH(24 小时格式)
数据格式规范
大小写统一的规范。例如 ID 统一大写;app、make、os 统一小写
时区统一的规范。比如说国内业务用北京时区,海外业务用 UTC 时区
模型衡量指标
命名规范性和数据完整性
命名规范数据完整的模型可以快速提高开发维护效率。
中间层表的增长比例
增长过快说明模型设计的稳定性不够,复用性不高。
应用层 ADS 跨层访问(穿透)
说明 DWS 中间层设计不足。
较多的 ADS 表共性逻辑未下沉数量
模型复用性不高。
应用层跨集市依赖
耦合度过高会给数据的运维、治理带来很多影响,在数据下线、变更、治理过程中不得不考虑到依赖。
技术选型
通过数仓建设,我们需要解决以下问题:
数据存储的规范性
数据模型的复用性
数据模型的耦合性
数据的完整性
数据查询效率
数据成本可控
在标准测试数据集上,我们选取了一些常见的低基数聚合场景。ClickHouse 的整体查询时间是 StarRocks 的 2.26 倍。在 SSB 单表和用户经常碰到的低基数聚合场景下对比了 StarRocks 和 ClickHouse 的性能指标。采用一组 16core 64GB 内存的云主机,在 6 亿行的数据规模进行测试,下面测试为各种引擎在不同 SQL 下花费的时间。
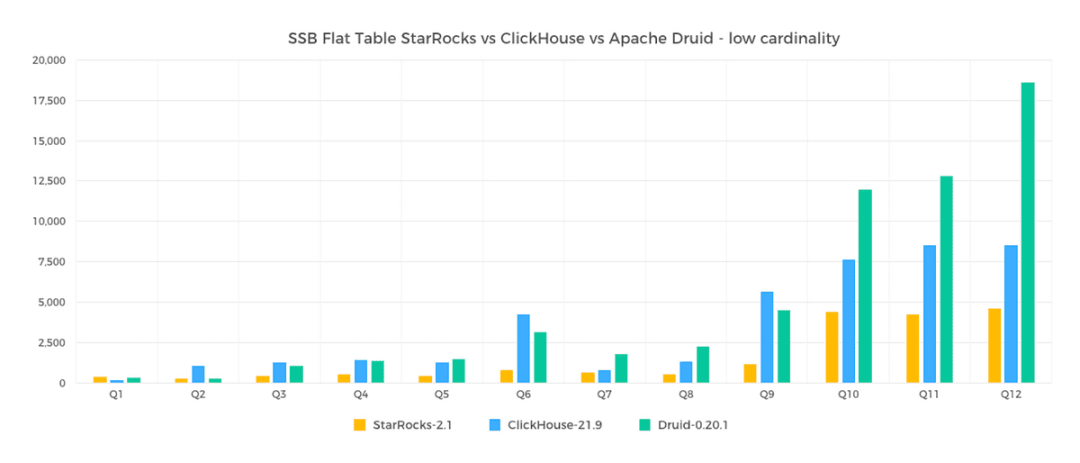
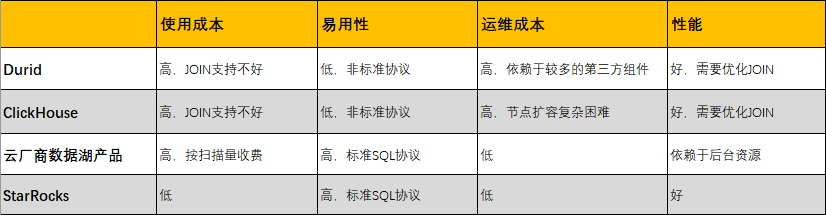
参考 StarRocks Summit 2022 对常见 OLAP 数据库进行了使用成本的对比,最终我们计划将基于 ClickHouse 等其他数据库产品的查询迁移到基于 StarRocks 来构建数据仓库。
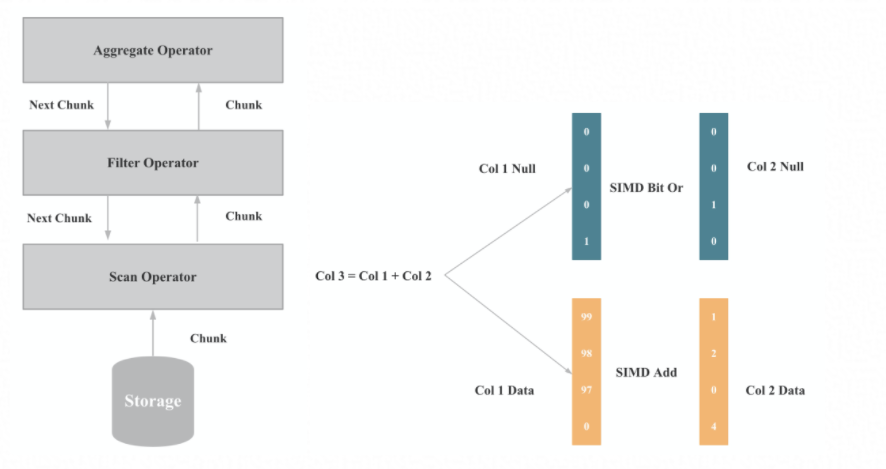
向量化的执行引擎也是我们选择 StarRocks 的原因之一,StarRocks 通过实现全面向量化引擎,充分发挥了 CPU 的处理能力。全面向量化引擎按照列式的方式组织和处理数据。StarRocks 的数据存储、内存中数据的组织方式,以及 SQL 算子的计算方式,都是列式实现的。按列的数据组织也会更加充分的利用 CPU 的 Cache,按列计算会有更少的虚函数调用以及更少的分支判断从而获得更加充分的 CPU 指令流水。
技术架构
数据平台目前处理的数据涉及公司多个产品,每日处理全球增量数据几十 T,近千亿条记录,跨云跨地域的数据也给数据处理带来不少挑战。目前我们已经针对 BI 系统开展了 StarRocks 的数据仓库的建设,随着经验的积累,后期会推广到数据平台所有项目的数据场景中。
目前数据平台以实时流和离线处理两条方式同时向 StarRocks 数据仓库中进行数据 load。如下架构中我们自研了数据治理平台(DataPlus)用于数据监控提高数据质量, 维护元数据血缘等数据的拓扑结构,自动化建模。另外我们还自研了分布式的跨云调度系统(EasyJob), 用来系统便捷的处理多云环境下的数据依赖和调度。下面是目前数据平台在数据分析中的主要流程架构。
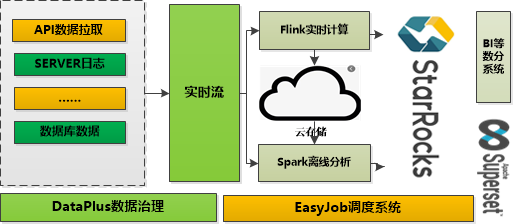
离线数据导入通过 EasyJob 定时调用 Broker Load 的方式导入 StarRocks。
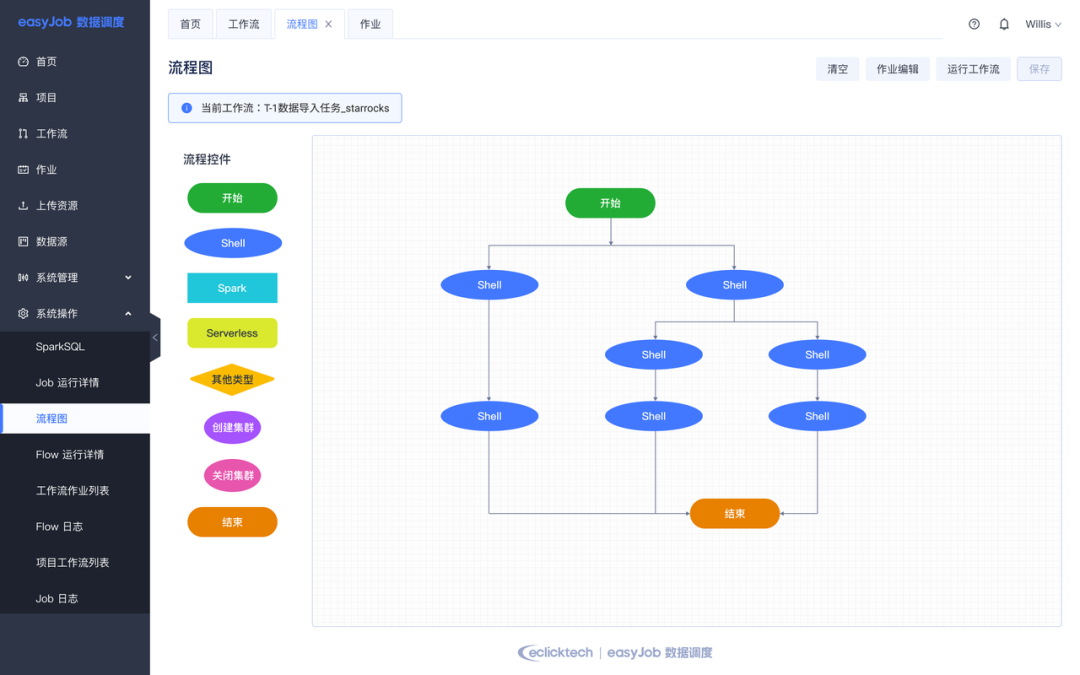
通过 DataPlus 系统我们对 StarRocks 中的数据和云存储数据进行了定时的一致性校验,保证数据的一致性。
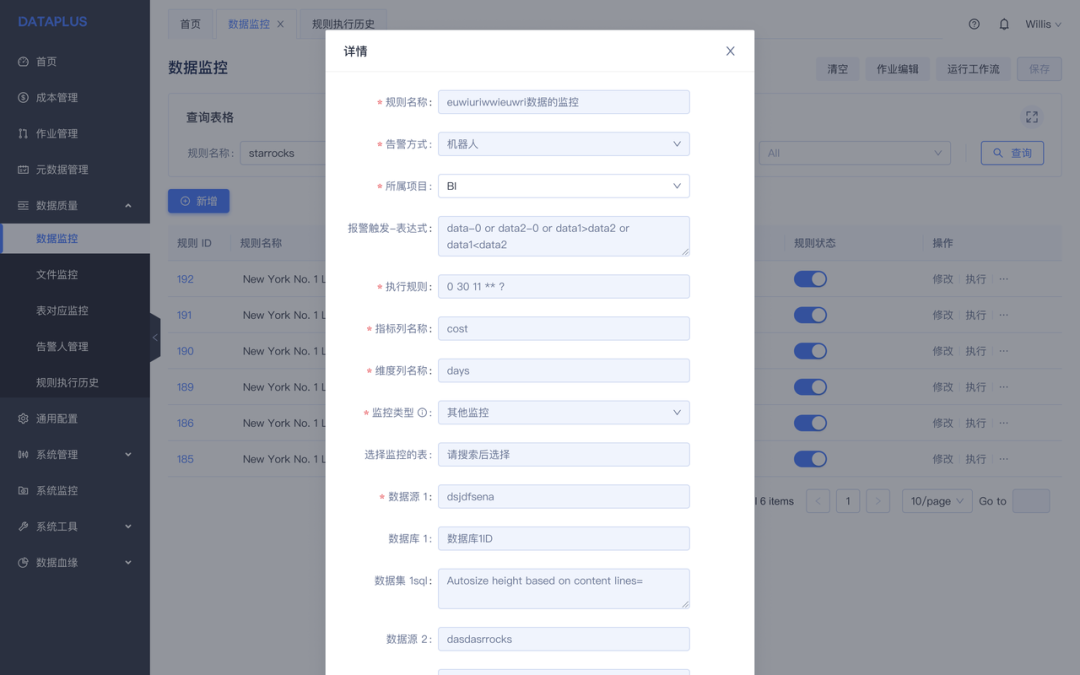
我们一直寻找一种实时和离线一体的数据处理解决方案,实时离线数据处理完后都会进入 StarRocks 进行全流程建模,在数据湖中我们进行了数据分层,最底层的 ODS 基本上通过外部数据源建立,数据存储在外部云存储上,例如 oss,s3,obs 等,然后通过调度系统定时触发上层表得生成,再往上层 DWS 和 ADS 我们部分表采用物化视图的方式图提高查询性能。
整体数据流动架构如下:
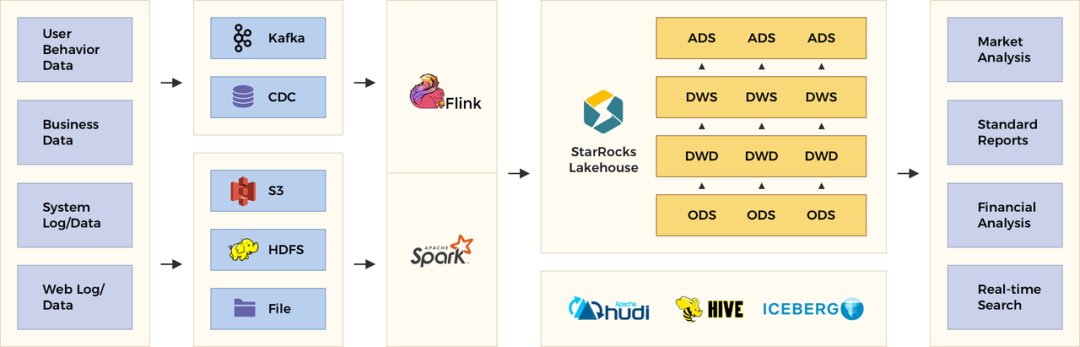
StarRocks 能够支持秒级的导入延迟,提供准实时的服务能力。StarRocks 的存储引擎在数据导入时能够保证每一次操作的 ACID。一个批次的导入数据生效是原子性的,要么全部导入成功,要么全部失败。并发进行的各个事务相互之间互不影响,对外提供 Snapshot Isolation 的事务隔离级别。
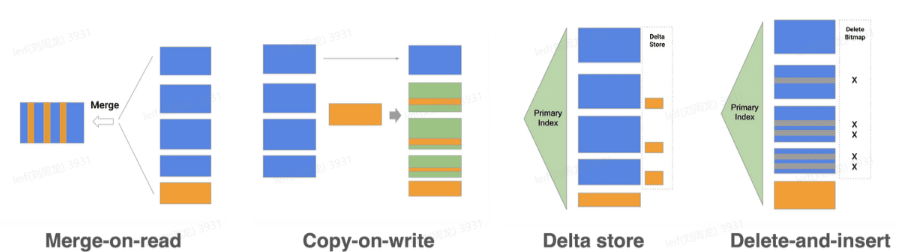
StarRocks 存储引擎不仅能够提供高效的 Append 操作,也能高效的处理 Upsert 类操作。使用 Delete-and-insert (Merge_on_write) 的实现方式,通过主键索引快速过滤,消除了读取时 Sort merge 操作,同时还可以充分利用其他二级索引。在大量更新的场景下,仍然可以保证查询的极速性能。
智能数据建模
通过元数据,数据血缘体系建立,未来我们可以通过让建模规范,建模质量等规则自动化,形成线上系统的自动化建模功能,自动化建模生成标准 SQL,最终在数仓(StarRocks)中定时执行生效。下面图是建模过程和 DataPlus 中功能的映射。建模自动化的好处就是可以限制人为建模的不规范操作,最大程度的优化模型和成本。
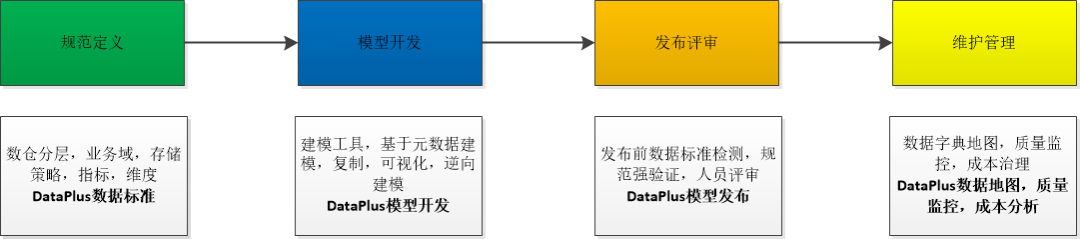
模型定义后,对模型生成效率的优化至关重要,不一样的解决方式,会影响模型的查询生成效率,模型的复用度,影响用户使用体验,我们建模中针对下面三个模型经行了重点构造,基于 StarRocks 的模型构造,大大提高了查询效率。
物化视图
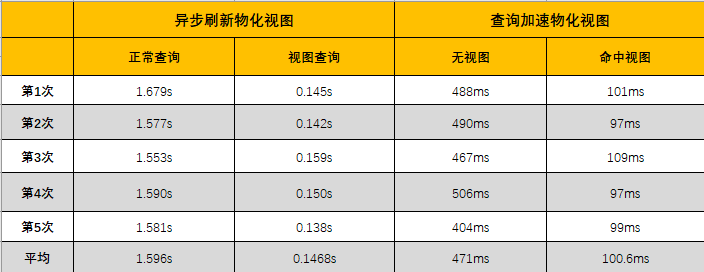
在数仓建模中我们大量采用了物化视图来加速和生成 DWS 以上数据层。创建两种物化视图的方式:

对比测试了两种物化视图的性能提升:
分析模型
统一的模型 SQL 设计,可以大幅提高查询性能,例如我们主要针对下面三种常见分析模型设计了标准建模 SQL。
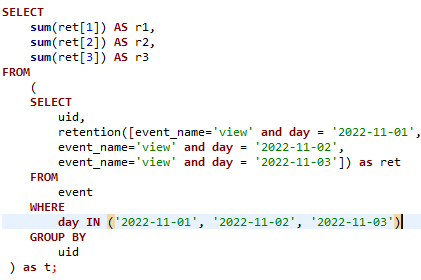
行为分析的应用 – 用户留存分析
对于用户留存的分析,我们采用 retention 函数来分析。
行为分析的应用 – 漏斗分析
我们采用 StarRocks 中的 window_funnel 函数实现高效的漏斗分析,例如下面是统计达到各种级别的用户数。

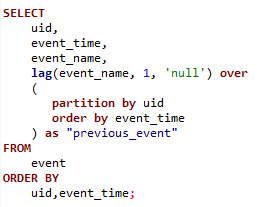
行为分析的应用 – 路径分析
对于路径分析,我们一般采用了 StarRocks 支持的窗口函数 ROW_NUMBER(),LEAD(),LAG() 等窗口函数来分析,例如获取用户访问的前一个事件记录。
建设成果
公司数仓建设过程分为四个阶段:
是数据仓库规范建立和技术调研选型。
是性能压测,经过测试和之前我们应用的 ClickHouse 有 2.2 倍以上的提升,Join 查询更是有数倍的提升,小时数据 load 在 1 分钟可以完成,保证离线查询效率。
试点运行,经过迁移部分业务使用效率得到大幅提升,以往比较头大的复杂自主 SQL 查询,TP95 查询都可以在 5s 返回。支持交互式 SQL 自主分析。
是全面部署和公司其他数据类产品应用,并完善监控等集群的自动化运维。
在 BI 系统中经过一段时间的使用,StarRocks 已经应用已经进入第四阶段,未来公司会将更多的业务切入到 StarRocks,并结合 DataPlus 的智能建模,表热度分析等数据治理,相信性能和成本会达到更理想的状态。同样我们也期待 StarRocks 在新版本中实时物化视图更强悍的能力。
今日好文推荐
OpenAI回应ChatGPT不向所有中国用户开放;字节改节奏,双月OKR改季度;马斯克称今年底卸任推特CEO|Q资讯
背负着整个现代网络,却因“缺钱”放弃开源,core-js 负责人痛诉:“免费开源软件的根基已经崩塌了”




