
在 PyCon China 2022 大会上,龙蜥社区开发者严懿宸分享了主题为《Python 启动加速的探索与实践》的技术演讲。本次演讲,作者将从 CPython 社区相关工作、本方案的设计及实现,以及业务层面的集成等方面进行介绍。本文为本次演讲内容整理。
一、Python 启动速度简析
首先从一个 Python 3 中空解释器启动时间的好事分析开始。我们可以看到,主要的耗时都和 Python 包加载有关。

其中,CPU 时间中包加载占据了 30% 左右的时间;而 37% 的等待时间中,磁盘 IO 等花费的时间也和包加载有较大的关联。
熟悉 Python 机制的朋友大概知道,Python 中加载一个包首先会搜索对应的 pyc 文件,这是一种序列化的字节码格式。找到之后会对其进行反序列化,并执行其中的代码。如对应的 pyc 文件不存在,会重新编译 py 文件得到字节码,并序列化为 pyc 文件持久化保存。我们优化的主要目标主要集中在加载包这个过程,希望能够至少免去每次查找、读取、反序列化的开销。

以 Python3.10 为例,这里是使用 python 解释器启动一个空语句的所需时间,同时使用了 -Ximporttime 打印出过程中加载每一个包的耗时。可以粗略地看到,包加载时间大约占了总时间的 30% 左右。我们发现这种情况和 Java 虚拟机类似。在 Java 中,Java 会首先将 Java 源代码编译为 Java 字节码,随后由 Java 命令执行。
我们知道 Java 的优势并不包括启动速度,这种流程也是原因之一。那么 Java 如何部分解决这个问题呢?
二、PyCDS (代码对象共享)设计与实现
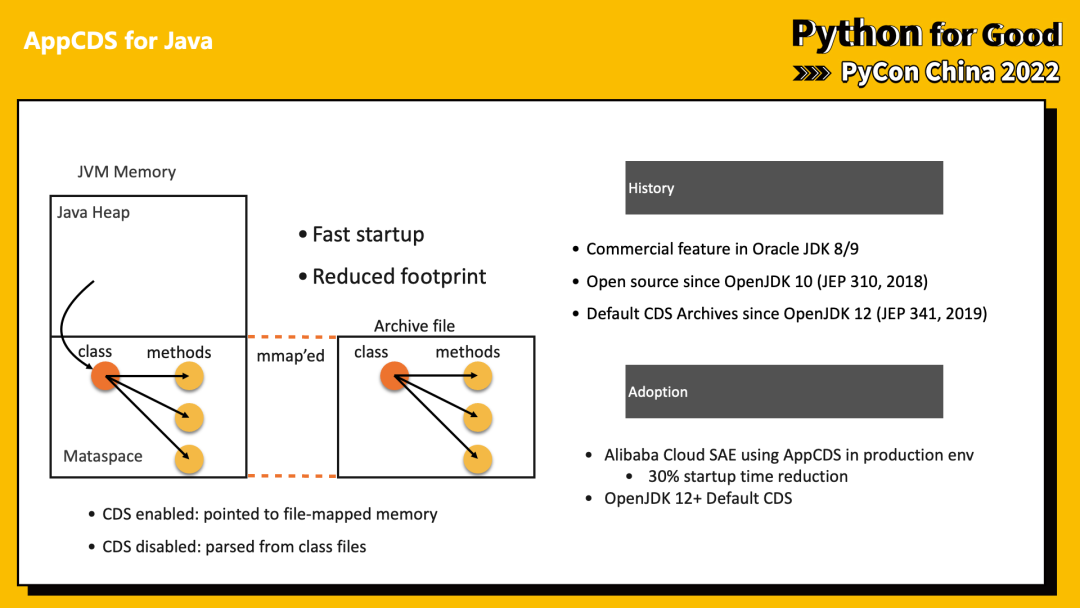
Java 中有一个叫做 CDS/AppCDS 的机制,通过将 Java 字节码和一些辅助数据持久化保存,在后续启动时使用 mmap 加载,节约了磁盘 IO 和解析验证 class 文件的开销。
很自然的想法是,如果我们希望在 Python 中使用类似的技术,目标应该是 Python 字节码。

Python 默认从 py 文件导入模块的逻辑如上图左边所示,首先根据制定的名字获取对应的规则,随后尝试寻找 pyc 文件或重新编译。最后,使用 exec 命令利用代码和一个空 dict 来创建模块,并加入 runtime。
我们做的事情可以简化为右侧逻辑。同样根据包名,尝试从 mmap 中加载。如果成功,那么同样的 codeobject 也可以用于初始化。
这样做有什么直接的障碍?
可以看到,Python 中代码对象的 C 数据结构大致如图,包括 consts、string、bytes 等 Python 数据类型。
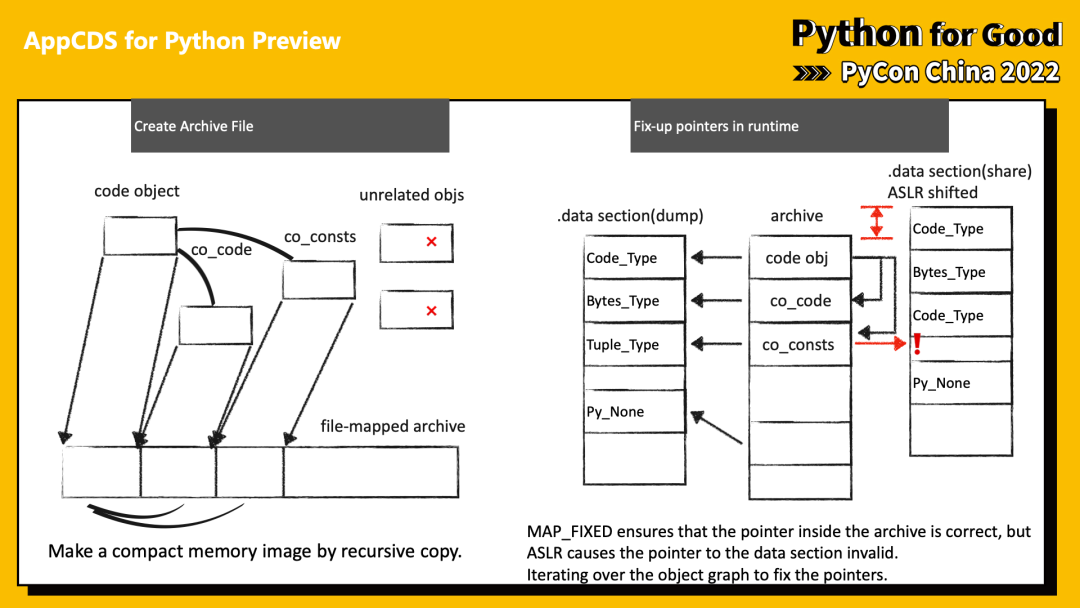
以使用到的 codeobject 作为 root,将涉及的数据序列化存储到内存映射中。
在这一步,最直接的问题是内存随机化机制。在处理 code object 中的 Python 对象时,每个 Python 对象头中都保存着指向当前进程中对应类型信息的指针。Runtime 通过这个指针判断该对象在 Python 中的类型。
以 PyCode_Type 为例,如果不做处理,这里会丢失类型信息(红色 offset)。
为了解决这个问题,在我们创建的镜像文件中会保存涉及的对象指针。在加载时动态 patch 相关的指针。
在整个过程中涉及的 Python 类型包括:
1. 常量(bool/None/ellipsis)
2. 字面量(float/complex)
3. 需要额外分配的变量(long/bytes/str)
4. container(tuple/frozenset)
对于常量和字面量,在内存映射中分配好空间后直接赋值即可保存;对于后两种,需要模拟 Python 中变量初始化的逻辑,创建合适的内存大小并写入对应位置。同时,对于非常量的类型,还需要对内存映射中的引用计数额外赋值,防止意外触发 Python 中的回收。
以上就是本项目的大致内容,另外关于项目的具体用法请前往 PyCDS 项目主页或我们在龙蜥实验室上的课程查看,链接见下:
龙蜥实验室课程:
https://lab.openanolis.cn/#/apply/chapters?courseId=117
PyCDS 主页:




