什么是分布式事务
传统的基于数据库本地事务的解决方案只能保障单个服务的一次处理具备原子性、隔离性、一致性与持久性,但无法保障多个分布服务间处理的一致性。因此,我们必须建立一套分布式服务处理之间的协调机制,保障分布式服务处理的原子性、隔离性、一致性与持久性。
支付宝为什么需要分布式事务
基于 SOA 架构,整个支付宝系统会拆分成一系列独立开发、自包含、自主运行的业务服务,并将这些服务通过各种机制灵活地组装成最终用户所需要的产品与解决方案。
在多个服务协同完成一次业务时,由于业务约束(如红包不符合使用条件、账户余额不足等)、系统故障(如网络或系统超时或中断、数据库约束不满足等),都可能造成服务处理过程在任何一步无法继续,使数据处于不一致的状态,产生严重的业务后果,所以我们需要一个分布式事务的解决方案, 用来协调多个服务的业务一致性。
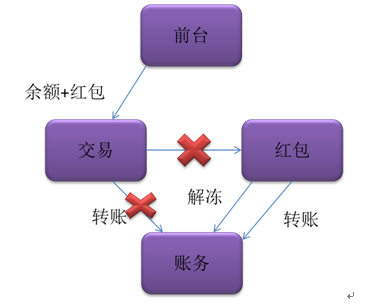
支付宝的分布式事务框架
支付宝开发的分布式事务是基于两阶段提交的理论 (Two Phase Commit),首先给出两阶段提交的逻辑图:
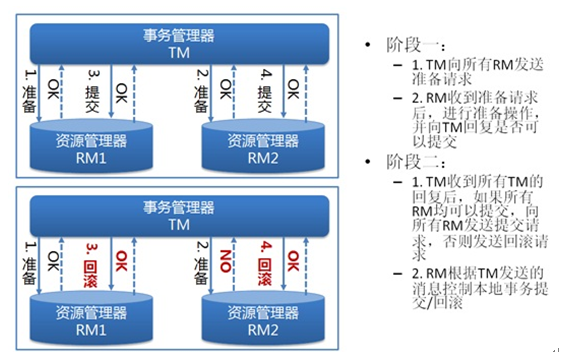
为了能够有效的让框架进行分布式事务的提交、回滚等动作,框架需要在整个两阶段执行过程中记录下足够的信息,设计了两张表来记录相关信息:
分布式业务控制活动主表:记录了全局事务的活动状态;
原子业务活动表:记录了原子业务活动的状态;
我们用一个例子来说明:
看一个典型的分布式事务场景。
业务场景描述: 用户购买商品,使用支付宝余额支付;
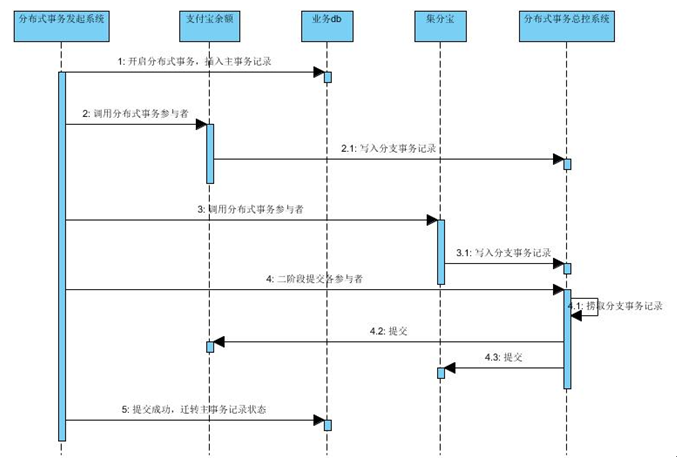
测试方案
分析步骤
- 角色定位
- 各分支的业务活动记录状态
- 梳理业务各个场景
- 验证梳理场景
- 恢复 & 回查机制
角色定位
首先测试人员需要分析所测试的系统处于分布式事务中的哪一个环节中, 是处于事务的发起者, 还是事务的参与者, 不同的角色的定位对于测试分析角度不同, 主要有以下的区别:
发起者:
分为同库 / 异库模式,主要区分是控制全局事务状态的主事务记录是否持久化在自己系统的 db 中;
参与者:
分为本地 / 远程模式,主要区分是是否可以创建嵌套的分布式事务;
各分支的业务活动记录状态
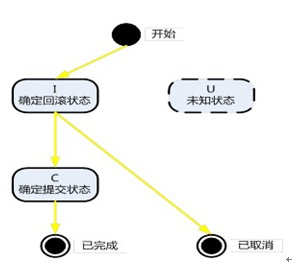
主事务记录:
根据业务场景的不同,主事务记录状态也会相应改变,主要的状态机变化如图所示,测试人员需要模拟业务场景来验证状态机的迁转是否正确;
同库:初始状态:I; 提交成功:C; 提交失败:I
异库:初始状态:U; 提交成功:U; 提交失败:U
梳理 & 验证业务场景
• 分析维度
- 一阶段:预处理:成功 / 失败;
- 二阶段:提交 / 回滚;
- 预期结果
- 各个状态场景
恢复 & 回查
- 恢复:应用使用分布式事务,出现处理失败的业务活动,为了确保产生的影响不破坏业务一致性,我们必须对这些记录进行恢复处理
- 回查:对于异库模式,事务状态为 U,若提交或回滚失败,分布式事务总控系统无法感知这笔分布式事务是否执行成功,需要业务系统提供相应的回查接口;
恢复及回查接口需要特别关注,对于分布式事务的正常二阶段提交或回滚,业务场景覆盖时多半都能 check 到,但是对于恢复及回查逻辑,很多时候都会遗漏,所以测试人员需要对这块特别做一个分析;
感谢侯伯薇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




