
近年来,迁移学习、风格迁移、声码器、声学模型等方面的最新进展,为低资源语音克隆的提供了潜在的解决方案。爱奇艺联合西北工业大学音频语音与语言处理研究组、新加坡国立大学、清华大学深圳国际研究生院、起源智能、希尔贝壳在 ICASSP2021 举办了多说话人多风格音色克隆大赛——M2VoC。
M2VoC 挑战赛旨在提供一个通用的数据集以及一个公平的测试平台,对语音克隆任务进行研究。作为 2021 年声学、语音和信号处理国际会议(ICASSP2021)信号处理挑战旗舰任务之一,吸引了多支学术界和工业界的研究人员加入了挑战。
本周,在ICASSP2021峰会上,M2VoC 挑战赛顺利落幕,并公布了比赛成果。共 153 只队伍注册参赛了本次挑战赛,其中有多家学术机构和互联网公司共同参与其中,学术机构包括北京大学,清华大学,浙江大学,上海交通大学,国立台湾大学,哈工大,University of Crete,中科院自动化所,University of Tsukuba,Nagoya University,复旦大学,香港中文大学,中科院大学,电子科技大学等;参与互联网公司包括虎牙,微软,滴滴,腾讯,网易等。

爱奇艺多说话人多风格音色克隆大赛分为少样本赛道和极少样本赛道两大任务。在少样本赛道方面,主办方针对每个说话人提供 100 句不同说话风格的训练样本;在极少样本赛道方面,主办方针对每个说话人提供 5 句不同说话风格的训练样本;同时,主办方提供了两个基础库,分别包含 5000 句不同说话风格的训练样本,供参赛者训练基础模型。最终,主办方经过“说话人相似度、语音质量、风格/表现力、发音准确率”四大标准加权作为比赛评判标准。
针对提交成果,爱奇艺组委会进行了两轮主观评估:第一轮包括所有团队的提交,第二轮则对几个得分最高的团队进行了进一步评估。每个赛道的最终获胜者是根据两轮比赛的综合结果选出的。考虑到在短时间内对质量、风格和相似度进行主观评价的巨大成本,组委会采用了抽样评价方法。第一轮和第二轮主观听力测试分别有 66 名和 30 名专业听测人员参加。所有的听测人员都是以汉语为母语,由语言学专业的大学生和专业的语音注释员组成。
比赛汇集了业内顶尖团队,作为业内首个多说话人多风格音色克隆比赛,体现了当前业内和学界最高水平。本次挑战赛共收录 18 篇相关论文,其中,6 篇论文被 ICASSP2021 收录。

图:ICASSP 2021 本次挑战赛收录论文
参赛队伍在 Acoustic model、Speaker representation、Vocoder、Speaker adaptation strategy 等多个方面都提出了创新,并取得了很好的效果。相关成果应用于 APP 口播、UGC 配音、有声书、风格化语音合成等多个应用场景,能够满足不断变化的声音定制场景,特别是基于多风格低质量语料场景下的声音的定制。
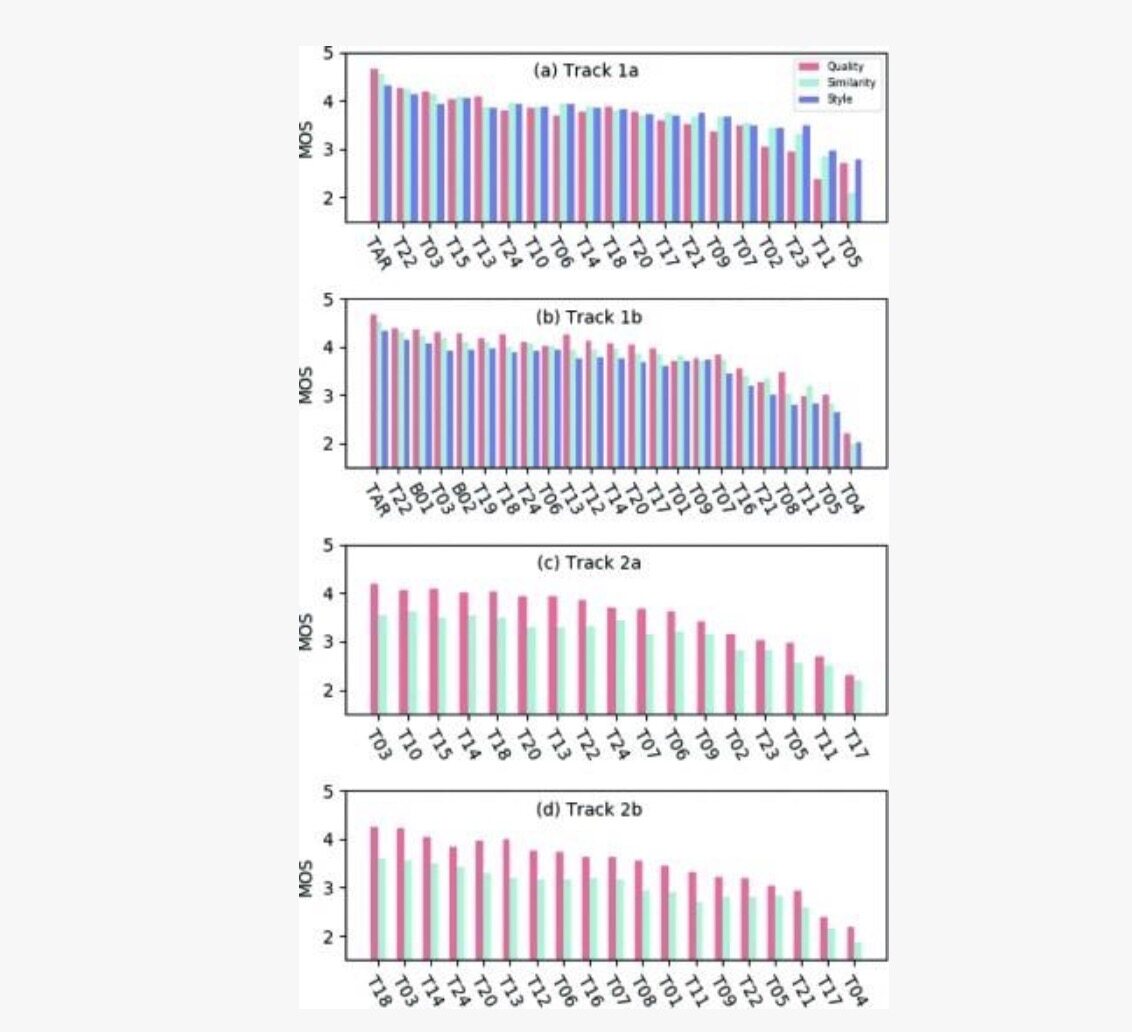
图:各赛道第一轮评估中所有提交的 MOS
本次爱奇艺多说话人多风格音色克隆大赛(M2VoC)是世界上第一个小资源音色克隆挑战赛,旨在为语音克隆任务的研究提供一个通用的数据集和一个公平的测试平台。挑战展示了当前语音克隆技术的性能:随着深度学习的进步,少样本语音克隆已经取得了相当好的性能,但单样本语音克隆仍然是一个未解决的问题。在现实世界的语音克隆应用中,低质量(嘈杂)音频和训练/适应/推理的时间/成本限制也是不可忽视的重要因素。
爱奇艺也在 ICASSP2021 发布了相关论文,总结本次大赛的情况。希望通过本次大赛的成果,为音色克隆、语音识别等前沿技术的创新探索提供更多机会,进一步拓宽人工智能技术的应用空间,为视听行业发展提供新的可能(在爱奇艺技术产品团队微信公众号,后台回复“papers”,获取 18 篇挑战赛论文合集)。




