
10 月 27 日,智谱 AI 在 2023 中国计算机大会(CNCC)上发布了自研第三代对话大模型 ChatGLM3,这是智谱 AI 在今年内第三次对 ChatGLM 基座模型进行了深度优化。ChatGLM 是由清华大学创新领军工程博士张鹏带领下的团队开发的一个开源且支持中英双语的类 ChatGPT 大语言模型,一经推出就迅速受到大家的关注。
此次 ChatGLM3 发布后,几个小时的时间就覆盖了大模型圈内人的朋友圈,所以 ChatGLM3 本次到底升级了什么?对大模型的发展又产生了哪些影响?
一、更强大、更高效、更长,都是 ChatGLM3 的形容词
随着人工智能技术的快速发展,自然语言处理领域已经成为最具挑战性和最活跃的研究方向之一。在这个领域中,大型预训练模型被证明是实现卓越性能的关键。
从性能方面,推理速度和成本一直是衡量模型性能的重要指标之一,在众多预训练模型中,ChatGLM 系列模型也一直因其优秀的性能和创新能力而备受关注。而此次智谱 AI 发布的 ChatGLM3 的推理框架是基于最新的高效动态推理和显存优化技术构建的,在相同硬件、模型条件下,相较于目前最佳的开源实现,对比伯克利大学推出的 vLLM 以及 Hugging Face TGI 的最新版本,推理速度提升了 2-3 倍,推理成本降低一倍,每千 tokens 仅 0.5 分,成本相对最低。这些数据足以表明,ChatGLM 系列模型在推理速度和成本方面已具有显著优势。
与 ChatGLM 二代模型相比,ChatGLM3 在 44 个中英文公开数据集测试中表现优异,在国内同尺寸模型中排名首位。评测结果显示,ChatGLM3 在 MMLU、CEval、GSM8K 和 BBH 等基准测试中均取得了显著的性能提升,分别提升了 36%、33%、179%和 126%。这主要得益于其独创的多阶段增强预训练方法,以及更丰富的训练数据以及更优的训练方案。多阶段增强预训练方法在语言模型训练中展现出显著的优势,其根据不同的任务和数据分布来优化模型性能,从而在各种不同的语言任务中取得更好的表现。通过多个预训练阶段的反复迭代和优化,模型得以深入学习语言知识和规律,进而提升对语言的理解能力,这种方法有助于强化模型的泛化能力,使其能够更好地适应各种不同的语言环境。此外,在面对复杂的语言现象时,该方法使模型还能够更加鲁棒地处理各种情况,减少出现偏见或误解的可能性。
除了在基准测试中表现出色,ChatGLM3 还瞄准了 GPT-4V 的技术升级,要知道,GPT-4V 具有每种模态(文本和视觉)的限制和能力,同时呈现出来自所述模态交叉和大规模模型提供的智能和推理的新颖能力。所以本次发布的 ChatGLM3 实现的若干全新功能的迭代升级中,最引人注目的就是多模态理解能力的 CogVLM-看图识语义功能,该功能在 10 余个国际标准图文评测数据集上取得 SOTA。此外,与 GPT-4V 相比,ChatGLM3 的语义能力和逻辑能力都得到了大大增强:
代码增强模块 Code Interpreter 根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务;
网络搜索增强 WebGLM-接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。
此外,ChatGLM3 目前已经具有了全新的 Agent 智能体能力,其集成了自研的 AgentTuning 技术,激活了模型智能代理能力。在智能规划和执行方面,ChatGLM3 相比 ChatGLM 二代提升了 1000%,这一技术开启了一种全新的模型智能体能力,使 ChatGLM3 能够在更多复杂场景中发挥出色表现。例如,ChatGLM3 能够原生支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理以及操作系统等复杂场景。
非常值得一提的是,为了更好地适应边缘计算的需求,ChatGLM3 还推出了可手机部署的端侧模型 ChatGLM3-1.5B 和 3B。这些模型支持包括 vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上 CPU 芯片的推理,速度可达 20tokens/s。在精度方面,1.5B 和 3B 模型在公开 benchmark 上与 ChatGLM2-6B 模型性能接近。这一创新为自然语言处理应用在移动设备上的部署提供了便捷的方式,进一步拓展了自然语言处理技术的应用范围。
而正是在全新升级的 ChatGLM3 赋能下,生成式 AI 助手智谱清言目前已成为国内首个具备 Advanced Data Analysis(原 Code Interpreter)能力的大模型产品,可支持图像处理、数学计算、数据分析等使用场景。CogVLM 模型则提高了智谱清言的中文图文理解能力,取得了接近 GPT-4V 的图片理解能力。它可以回答各种类型的视觉问题,并且可以完成复杂的目标检测,并打上标签,完成自动数据标注。

据悉,目前智谱清言已具有搜索增强能力,它可以帮助用户整理出相关问题的网上文献或文章链接,并整理出答案,这意味着智谱清言将为用户提供更好的自然语言处理服务。
二、ChatGLM3 继续开源,“搞好开源”是智谱 AI 的初心
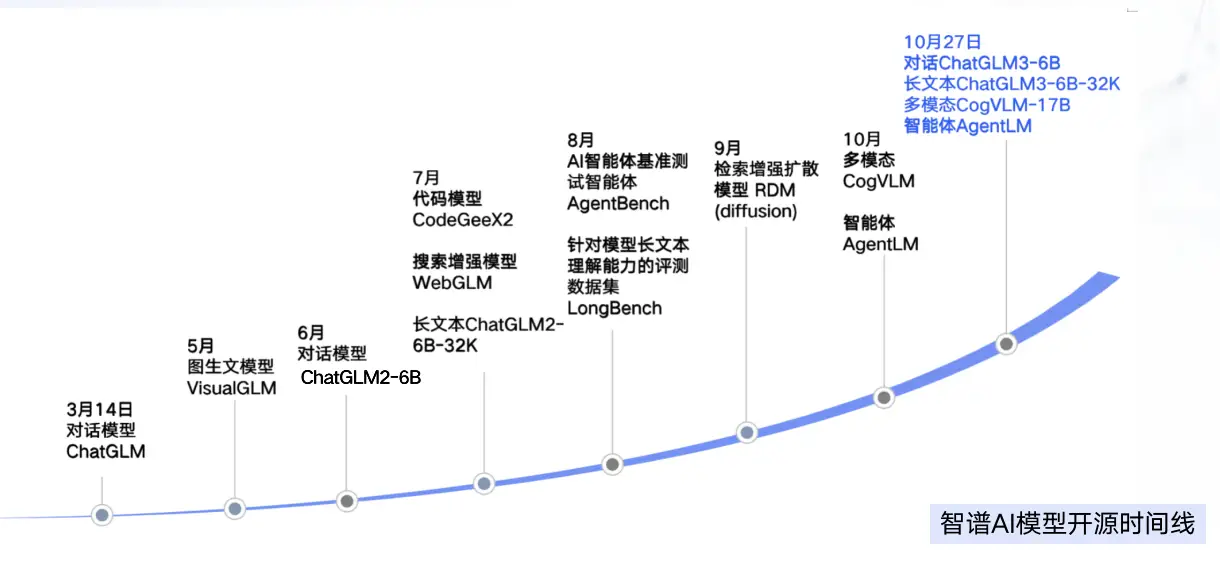
在此次 ChatGLM3 大模型的发布现场,智谱 AI 宣布为了进一步推动开源生态,将对包括 ChatGLM3-6B、ChatGLM3-6B-32K 以及 CogVLM-17B 和 AgentLM 在内的多个模型进行开源。
目前,ChatGLM3-6B 模型的开源成绩已经比较可观,它在 44 多个对话模型数据集上的 9 个榜单中排名第一,其开源的 32k 版本 ChatGLM3-6B-32K 在 LongBench 中表现最佳。
伴随着 ChatGLM3 的开源,模型的工作原理和团队技术研发的决策过程可以被更多人了解,模型的透明度和可解释性将更有助于从业者理解模型,增强对模型的信任和使用体验,学术界和产业界的大模型开发者们都可以获取到模型的源代码和参数,基于现有模型参数和算法进行更深入的研究和创新,模型的性能也将有望在短时间内再次完成快速迭代,自然语言处理领域将得到进一步的发展。同时,开放的生态系统和社区也将推动 ChatGLM3 在实际场景中的应用和优化,相关产业将获得基于 ChatGLM3 更智能、更高效的服务和解决方案以完成数字化转型。
其实,ChatGLM3 并不是智谱 AI 的第一次开源,早在今年三月,智谱 AI 就已经陆续宣布大模型产品开源,而且成绩持续斐然,推动大模型行业发展是他们的初心也是一直在做的事情。比如多模态 CogVLM-17B 在开源后,在 10 个多模态榜单中排名第一;再如智能体 AgentLM,其让开源模型达到甚至超过闭源模型的 Agent 能力。
智谱 AI 从 B 端企业服务方面有深厚的基础,他们将自己的大模型进行开源,其实可以更好地让大家从场景落地方面实现大模型技术的创新,这是很多尚未商业化的大模型无法比拟的优势。
当然了,目前有越来越多的公司和研究机构开始将他们的大模型开源,国内比较知名的就有阿里巴巴的通义大模型系列、华为的盘古大模型系列、腾讯的混元大模型系列等多家。但当我们复盘包括智谱 AI 开源在内的这些大模型,我们会发现,它们不仅在中文领域表现出色,也在英文等其他语言领域有着广泛的应用,但由于这些开源的大模型具有极高的参数量和计算量,需要大量的数据和算力支持,所以只有少数的大型科技公司和研究机构能够开发和维护这些大模型。但也正因为这些挑战存在,大模型开源就变得更为重要,只有越来越多的人开始应用开源模型,难题才会有可能解决掉。
三、ChatGLM 系列大模型有“势必做好国产化”的决心
ChatGLM 3 的发布让智谱 AI 已构建起的全模型产品线更加强大。智谱 AI CEO 张鹏表示:“自 2020 年起,智谱 AI 便专注大模型的自研创新。从早期开始的 GLM 预训练架构的研发,到今天 ChatGLM3 的推出,我们在技术研发、国产适配、开源生态、商业交付等各方面都有了一定进展。我们希望基于当前完整的自研产品线,包括对话、多模态、代码、搜索增强等模型,以及全流程的技术支持,可以更好地支撑行业生态,与合作伙伴一同高速发展。”
自 2022 年初,ChatGLM 系列模型已支持在昇腾、神威超算、海光 DCU 架构上进行大规模预训练和推理,截至目前已支持 10 余种国产硬件生态,包括昇腾、神威超算、海光 DCU、海飞科、沐曦曦云、算能科技、天数智芯、寒武纪、摩尔线程、百度昆仑芯、灵汐科技、长城超云等。通过与国产芯片企业的联合创新,ChatGLM 系列模型性能不断优化,国产硬件生态也得到了大模型国产化的闭环。
ChatGLM 针对国产芯片的场景创新和技术支撑,其实也是我完成高新技术国产化升级的过程,这可以促进更多的研究者、开发者以及企业参与到自然语言处理技术的研究和开发中来,共同推动国内自然语言处理技术的发展。当 ChatGLM 在与国产芯片彼此成就的过程中,这将陆续帮助国产芯片摆脱对国外模型的依赖,增强国内模型的自主可控性,做出更适合中国市场需求的芯片的同时,这对于国家信息安全、产业发展等方面都具有重要的意义,直接增强了国家的科技实力,为国家的科技发展和国际竞争力提升具有重要价值。
四、写在最后
在 ChatGLM 3 系列模型发布后,智谱 AI 成为了目前国内唯一一个有对标 Open AI 全模型产品线的公司,(以下对比左侧产品为 OpenAI,右侧产品为智谱 AI):
对话方面:ChatGPT——ChatGLM(对话)
文生图方面:DALL.E——CogView(文生图)
代码方面:Codex——CodeGeeX (代码)
搜索增强方面:WebGPT——WebGLM (搜索增强)
图文理解方面:GPT-4V——ChatGLM 3 (CogVLM,AgentTuning…)
一名微软的算法工程师说,“在硅谷,智谱 AI 的 GLM 应该是最被头部科技企业承认的中国大语言模型。”可见 ChatGLM 是智谱 AI,也是国内大模型厂商追逐 OpenAI 的最大底气。最新一代大模型 ChatGLM3 的开源,在助于推动自然语言处理领域的发展、加速 AI 应用的开发过程、提高模型的可信度和透明度、促进社区合作和创新等方面具有重要的价值。但是否能够完全超越 OpenAI,还要看走出实验室后,ChatGLM3 在具体场景下的应用和性能表现。
但不管怎么说,一直将“持续搞好开源、做好国产化”作为基本功的 ChatGLM,通过不断开放和共享其技术和模型,已经大力促进了全球范围内的技术创新和产业发展,为中国大模型的产业升级和技术创新做出了较为突出的贡献。
事实上,在目前这个阶段,大模型厂商都应该做好以上两项基本功。只有通过稳扎稳打,不断推动大模型技术的发展和应用,才能让“中国大模型”在全球市场中展现出更多的价值。中国的厂商应该积极响应这一号召,加大投入,加强研发,不断提升自身的大模型技术和应用能力,抱团取暖,为中国的人工智能产业做出更大的贡献。




