
1、项目背景
去哪儿网作为全球领先的旅游搜索引擎,每天有成千上万的用户在这里买到了 低价的机票、酒店等产品,这其中有着庞大的客服团队在背后支持着售后服务工作,用户可以随时随地通过电话或者 chat 找到客服解决行中和行后的问题。随着人工智能在各个领域的应用,客服领域也有了很多落地场景,比如售后智能问答、智能 IVR、智能问题挖掘 、智能质检等,提高了客服的效率,节约了人力成本,提升了用户体验,本文主要介绍酒店售后智能问答的应用。
酒店售后场景中,这里指的都是 chat 渠道,我们将用户常问的问题整理成了标准问题 FAQ(Frequently Asked Questions)的 形式,总共五百多标准问题,这些问题会对应很多不同的问题分类。通过分析用户历史来看,大部分的用户问题都可以通过机器自助完成的,比如是否可以开发票、查看退款进度等问题,有一部分是需要客服通过和酒店沟通后才能解决,比如规则外退款、到酒店入住不了等问题。售后智能问答主要解决这些机器可以自助解决的问题,同时对不能自助解决的要能及时转到人工服务,避免给用户带来不好的体验,功能如图 1 所示。
下边简单介绍大概处理流程:
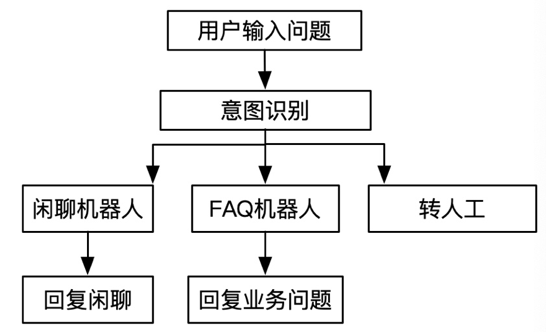
首先对用户输入问题进行意图识别,判断是否是闲聊还是问题咨询还是必须人工介入,然后转接到不同的模块处理,如图 2 所示。我们需要准确理解用户的问题,然后给出对应答案和操作,如果是复杂的问题或者用户对答案不满意可以唤起人工服务,目前平均对话 3.6 轮,24 小时自助率大概在 77%左右。
智能问答,涉及到自然语言理解、意图识别、QA 算法、多轮会话管理等任务。其中,QA(Question Answering)任务是比较基础和核心的模块,本文主要围绕 QA 算法,详细介绍基于 QA 我们在深度学习方法的一些尝试。
2、技术选型
我们先来回顾下 QA 任务的定义:给定一个用户问题 q,我们需要从知识库中查询出来 top k 个最相关的答案{a1,a2,…,ak},只要有一个回答 ak 在列表里,我们就说回答正确,否则回答错误。从这个定义来看,我们很容易想到的方法是基于分类和检索的方法。在本文中的知识库特指 FAQ,即通过运营整理出来的有限个标准问题,不是指问题对应的答案。因此,基于分类的方法,我们可以把每个 FAQ 当做一个分类,可以基于 SVM、FastText 等做多分类预测,标记样本时候,我们需要标记每个样本属于哪个分类。
但是,基于分类算法有很多弊端,首先由于 FAQ 问题很多,都当做小的类别的话,会有很多类样本分布很不均衡,很多类别学习不充分,平均准确率上不去。解决的办法也有很多,比如可以只挑选高频即样本多的类进行识别,当分类阈值很高时候才返回,其他识别不了的场景走检索的方式返回等。其次,分类问题的类别必须事先确定的,如果知识库的问题有增删改时候,就得重新训练,重新标记样本。如果知识库是通用型不怎么变还行,酒店业务复杂多变,产品和运营经常会对知识库进行增删改,因此,分类方法在酒店业务知识问题场景不太适用。所以,我们考虑采用基于检索的方式,比如基于 TF-IDF 或者 BM25 的文档相关性算法,或者基于其他深度学习的短文本匹配算法。由于深度学习的方法目前效果较好,我们在考虑选型时主要考虑了几种基于深度学习的文本匹配算法。
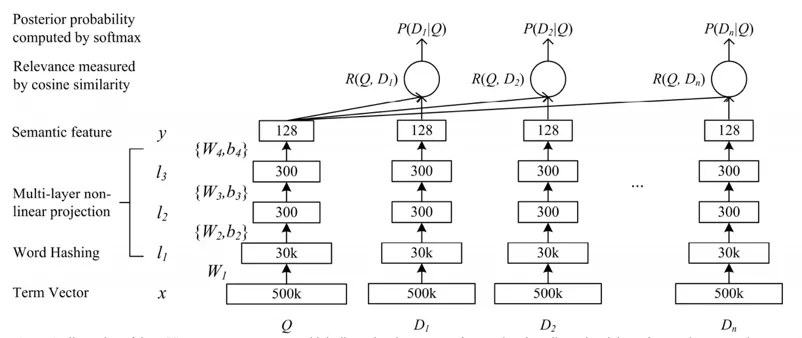
DSSM[1]可以说是深度学习在文本匹配的先驱了,网络结构如图 3 所示,最下边两层得到 embedding,接着过三层全连接层提取特征,接着计算查询 Q 和 D 的特征余弦相似度,计算 softmax 得到后验概率,损失是似然损失,最大化点击样本的概率。DSSM 还有很多变种,比如 CNN-DSSM[2]、LSTM-DSSM[3]、MV-DSSM[4]等。
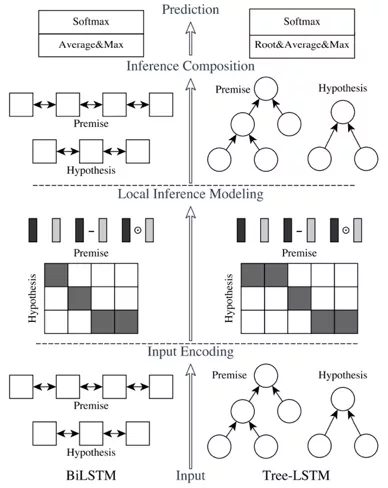
阿里的 ESIM[5],基于问题和答案动态编码,给定个前提 p 推导出假设 h,损失是判断 p 和 h 是否有关联。论文提出了两种结构,如图 4 所示,左边是 ESIM,右边是基于语法结构的 HIM。最底下的 Input Encoding 部分,将 p 和 h 进行 embedding 输入到双向 LSTM,得到 encoding,接着是核心的 Local Inference Modeling 部分,将上一步得到的特征基于 attention 机制计算出加权的 encoding,然后做一些对应位相减、相乘等操作,和原始特征拼到一起。最后是 Inference Composition 模块,把刚才的值再一次输入双向 LSTM,接着池化拼接、全连接,最后接 softmax 层。
基于上述的语义匹配模型,正常使用方式是来一个查询请求,要去和库里所有知识库问题匹配计算一遍,计算开销太大了,满足不了线上需求。对于 DSSM,我们可以提前把知识库标准问题过一遍网络 inference,抽取最后一层输出作为句子特征存储起来,线上只要用同样方式把用户问题变成特征向量,和库里的向量计算一遍余弦相似度就能快速找到 top k 个最相似问题;对于 ESIM,由于需要基于查询问题和库里问题组合动态编码,不能进行提前编码。可以先训练个简单的比如 Siamese 网络先提取 top n 个候选问题,比如 50 个,再从这些候选问题基于 ESIM 选出 top k 个最终结果。
因此,我们希望有一种端到端的学习模型,不用做各种传统 NLP 的处理工作,能提前计算好知识库问题的特征,线上只用计算输入问题的特征,并且对于知识库新增或者修改,模型有比较好的鲁棒性,不用重新训练也能准确表征新问题的句子特征。
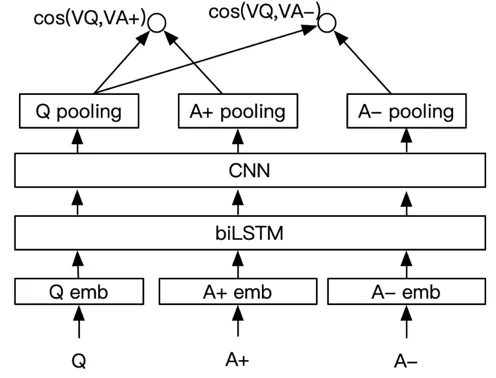
我们参考了 Minwei Feng [6]的方法,在 CNN 前接入了一层双向 LSTM,可以获取句子前后的信息,此模型作为我们的 baseline 方法。用户输入 Q,A+是知识库标记为正确的样本,A-是知识库其他随机取的一个样本,先计算得到 embedding,然后输入到双向 LSTM,得到句子进一步表示,接着输入到 CNN 网络,再过一层 pooling 层,得到向量表示,分别计算出 Q 和正负样本的余弦相似度,计算损失 L= max{0,m-cos(VQ, VA+) + cos(VQ, VA-)},更新网络参数。
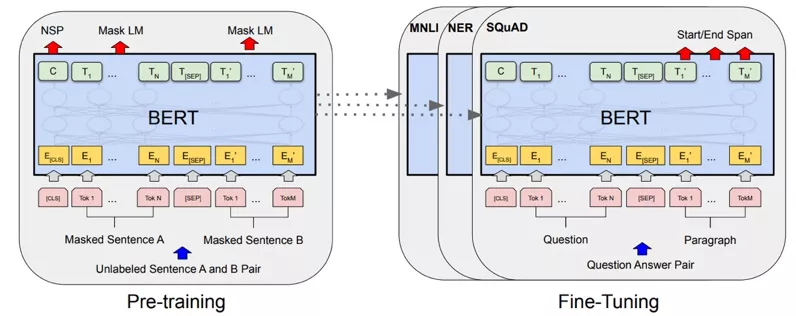
近几年,预训练(Pre-training)模型在自然语言处理领域得到了广泛应用,其中,最重要的就是 Google 的 BERT[7]预训练模型,基于 Transformer 网络结构再大规模无监督语料进行预训练,在下游的不同 NLP 任务进行微调(Fine-tuning),在 11 项自然语言处理任务中得到了不错的结果。预训练和微调除了输出层,其他网络结构都一样,微调就是基于预训练的网络参数进行初始化,如图 6 所示。
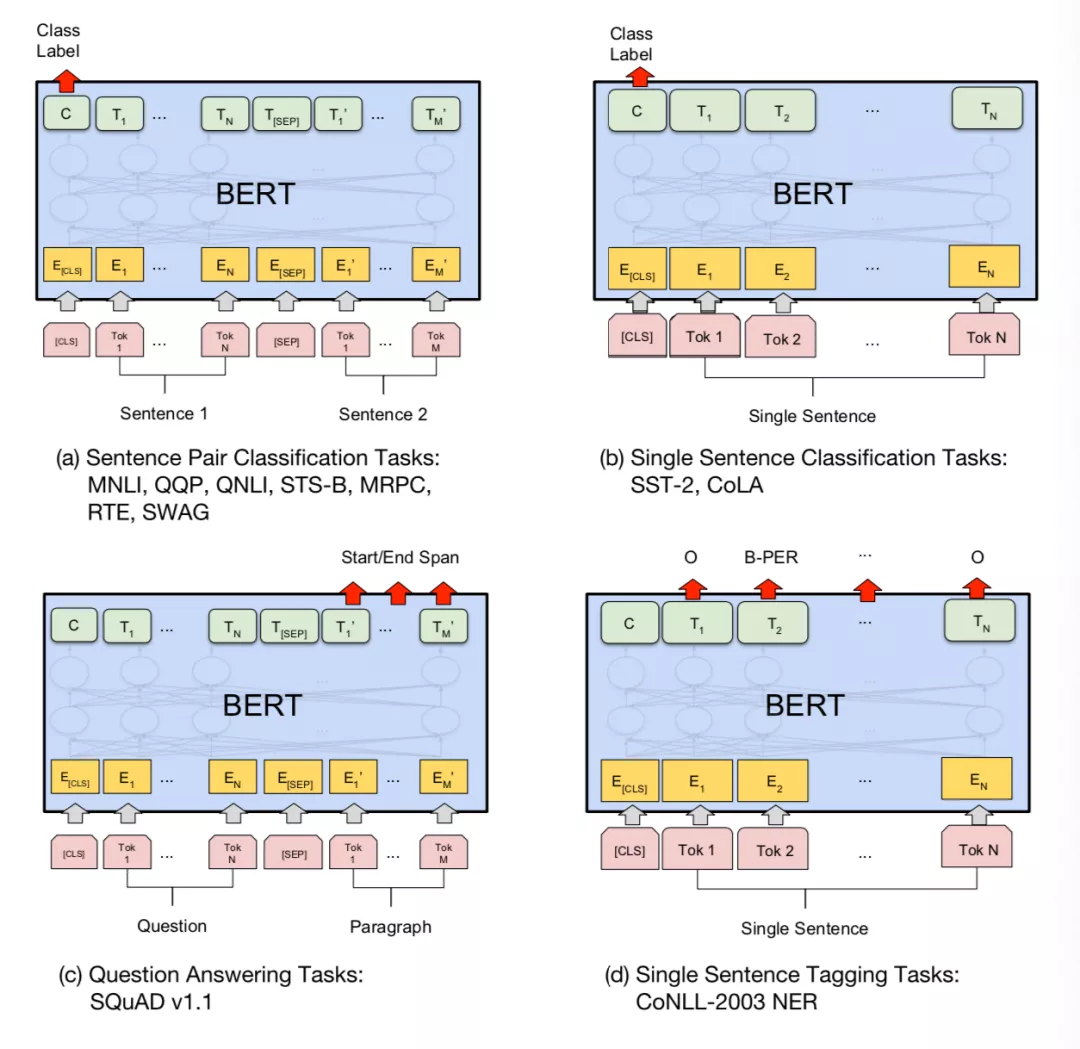
BERT 的 fine-tune 主要支持以下四种任务:
(1)基于句子对的分类
(2)基于单个句子的分类任务
(3)问答任务,类似于阅读理解,是从 paragraph 里面选择一个最可能的回答
(4)命名实体识别
前文已经讨论过,我们 QA 任务的场景,FAQ 的类型多,变动大,不适合当做固定类别的分类任务来做,所以倾向于去对句子对做分类。下面我们评测了下 fine-tune 后 BERT 的效果。
3、评测效果
为了比较上述模型在酒店业务场景的效果,我们基于同一份标准语料按照一定比例划分了训练集、验证集和测试集,训练集对样本较少的类别进行了上采样处理,验证集和测试集的类别分布相对均匀,消除因为某些类别占比太多导致平均准确率太高或者太低的影响。返回结果分别评估了 top1、top3、top5 的准确率,比如 P@3 表示返回的 top3 个问题的准确率,top 里只要有一个正确,这次结果就算对的。比较结果如表 1 所示,base 指上文介绍的 baseline 模型,base+BERT 表示基于 base 选出来 top10 粗排,再用 BERT 精排,这里 BERT 两次微调,第一次是和其他模型一样训练集上基于公开中文 base 模型上微调,第二次是在验证集上先用 base 跑出来 top10,把分错样本收集起来,进一步微调。ESIM 不知道是实现方式有点问题,还是负样本得特殊构建,因为基于 pair 动态编码,库里其他好多问题没有变成负样本训练过,基于概率值倒排结果和预想中不一致。对于新出现类别的鲁棒性测试,我们新增了三百个知识库 FAQ,人工标记了一些样本,不重新训练模型,top3 准确率 baseline 和 BERT 差不多,84%左右,DSSM 低了 4 个百分点,这些模型对新问题都有比较好的鲁棒性。
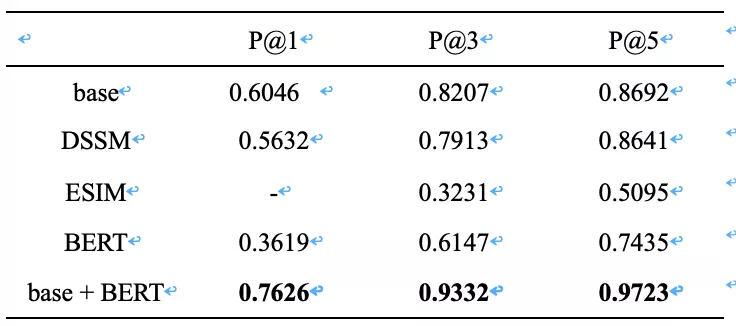
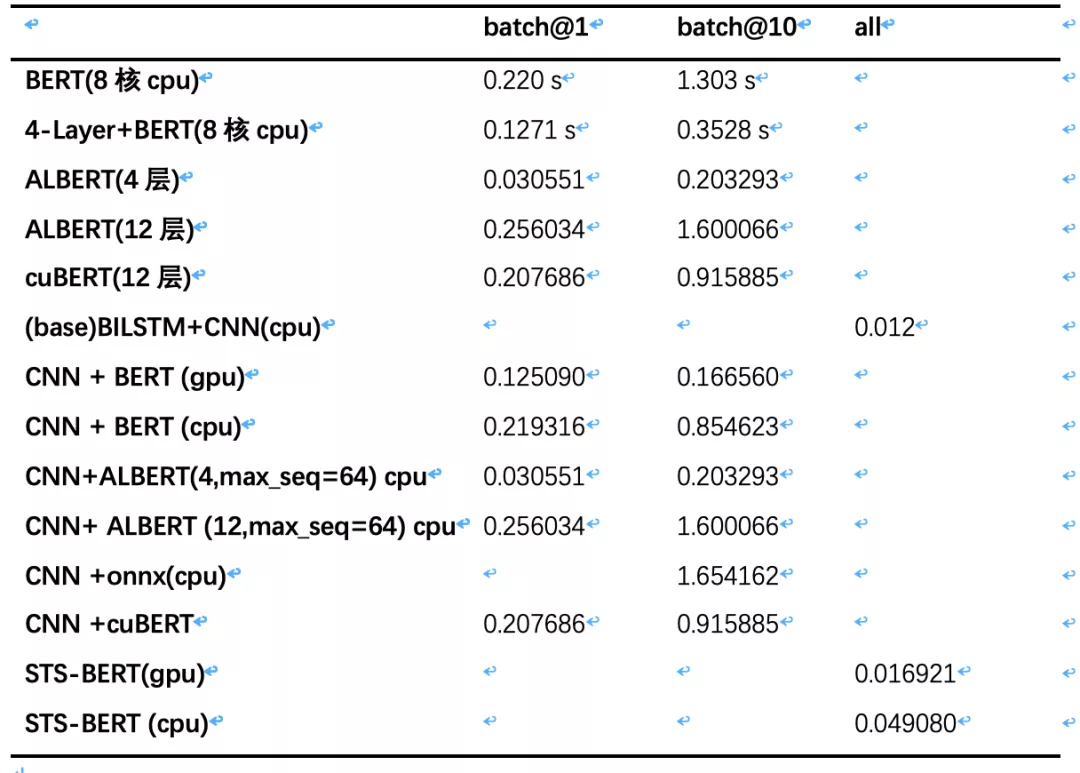
表 1 的准确率实验数据可以看出,baseline + BERT 效果相对是最好的,比 baseline 高出 10 个百分点,top1 召回提升 26%,top5 召回提升 11%,缺点是预测速度过慢,ALBERT 理论上应该速度更快效果更好,还需要调优。DSSM 效果整体和 baseline 差不多,基于 DSSM 粗排+BERT/ALBERT 精排效果待优化。考虑目前的业务场景,需要在 baseline 粗排得到 top10 之后进行精排,挨个通过 BERT 网络计算 query 和候选集对。从表 2 的速度对比可以看到,inference 时间在 batch size=10 时候,CPU 上 base 20 ms 左右,BERT 需要 800 多 ms,GPU 需要 160 多 ms,响应时间过长线上没法直接使用,我们需要进一步优化。比如并行计算 batch size=1 的预测,CPU 平台也需要 200ms 以上,而业务最多能忍受的时间在 100ms 之内。
4、工程优化
对于 GPU,可以选择 TensorRT 或者 Faster Transformer 等办法,但是由于我们资源比较少,还是希望在 CPU 上优化。这个方向也已经有很多研究了,比如知乎的 cuBERT[8],微软[9]的基于 oonx 运行时能提升 17 倍,但是我们尝试后,好像没有达到预想中的提升。找 cuBERT 作者咨询后尝试了他们重写 cuda 接口的效果,比原生系统下降了 100ms,但是对于我们大 batch size 的使用方式还是不够快。我们也尝试过打算简化网络模型牺牲点精度,比如减少 BERT 层数、重写 tf 的预测逻辑、蒸馏出一个小的 student 模型等方法[10],以及瘦身版的 albert-tiny[11],损失的精度没有预期那么好。业界还有很多优化方法,比如 facebook 的模型参数压缩 Quant-Noise[12]方法,RoBERTa 模型从 480M 压缩到了 14M,精度没怎么降。详细数据在表 2 中可以看到,最后这些方法均没有采用。
由于 BERT 没有直接提供句子编码的方式,如果直接提取 BERT 的输出层取平均或者 CLS token 作为句子的 fixed embedding 作为特征,然后计算句子相似度效果很差,论文[13]中也提到了这个问题,因为优化的目标不一样。基于 baseline 思路,我们准备在 BERT 后接一层损失变换一下来更新 BERT 参数,刚好 sentence-bert[13]实现了这个思想。
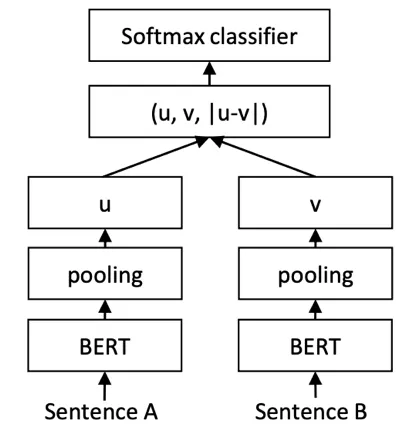
STS-BERT 网络结构很简单,如图 8 所示,BERT 后接了 pooling 层提取句子特征,基于 siamese 网络供共享 BERT 参数,最后根据业务可以接入分类或者回归目标函数,反传更新参数,这样特征层提取出来就有意义,可以用来结算余弦相似度,标准 FAQ 可以预计算提取特征,线上只用 batch size=1 计算 query 的特征,然后和 FAQ 的用简单的方法比较相似度。
我们基于 Triplet 损失,embedding 取了 768 维,在同样的训练集上训练,top 的准确率都分别比 base 提升了 5 个百分点,平均时间也只需要 49ms 左右,但是比最好的 base+bert 还差好几个点,未来还需要进一步优化。同时,我们也和论文一样尝试过直接使用 bert embedding 的方式做比较,相同场景下用 bert embedding+svm 平均准确率只有 77%,下降了十几个点。
5、总结
对于非常大体量的互联网公司来说,加机器和加人可能是一个万能药,但是对于大多数其他公司来说,在生产上直接应用目前越来越深的模型需要付出巨大的资源消耗和优化的研发成本。所以咱们这些公司做深度学习的落地应用,感觉回到了在 SOC 上开发软件的时代,带着锁链跳舞,凡事需要权衡实现方案和代价的 tradeoff,对于现在习惯于动辄横向扩展加机器的技术人员来说也是一种有趣的复古考验。本文没有特别深入的技术改造和算法优化,只是在实际工作中的一些体验和经验,希望能给大家带来一点收获。
[1] Po-Sen Huang, Xiaodong He, Jianfeng Gao, et al. Learning deep structured semantic models for web search using clickthrough data. CIKM. 2013.
[2] Yelong Shen, Xiaodong He, Jianfeng Gao, et al. A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. CIKM. 2014.
[3] H. Palangi, L. Deng, Y. Shen, et al. Semantic Modelling with Long-Short-Term Memory for Information Retrieval. arXiv preprint arXiv:1412.6629, 2014.
[4] A. M. Elkahky, Y. Song, and X. He. A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems. www. 2015.
[5] Qian Chen, Xiao-Dan Zhu, Zhen-Hua Ling, et al. Enhanced lstm for natural language inference. ACL. 2017.
[6] Minwei Feng, Bing Xiang, Michael R. Glass, et al. Applying Deep Learning to Answer Selection: A Study and An Open Task. ASRU. 2015.
[7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805, 2018.
[8] Fast implementation of BERT inference directly on NVIDIA (CUDA, CUBLAS) and Intel MKL. https://github.com/zhihu/cuBERT.
[9] Microsoft open sources breakthrough optimizations for transformer inference on GPU and CPU. https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu.
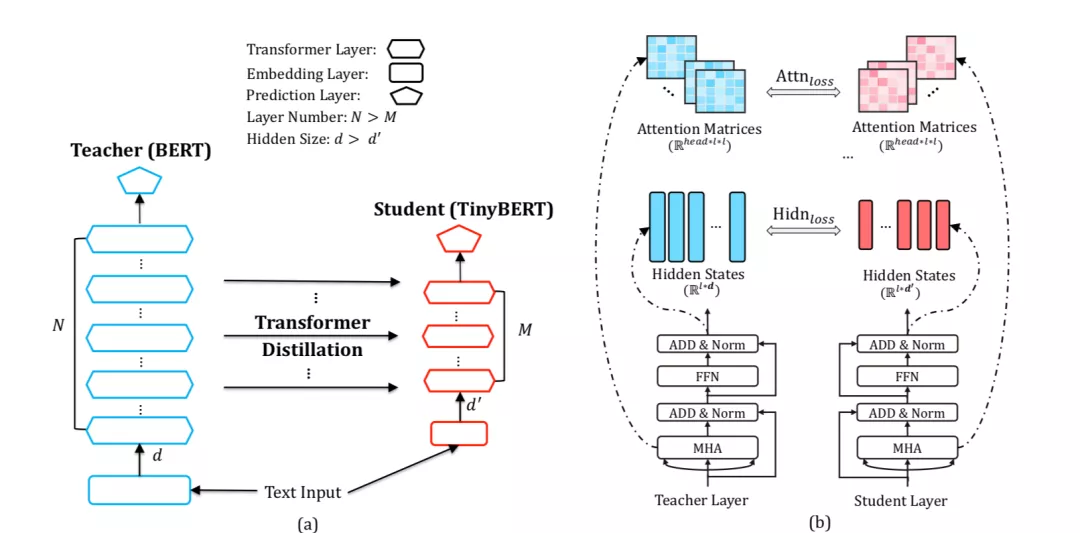
[10] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for natural language understanding. arXiv preprint arXiv:1909.10351, 2019. 34
[11] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942, 2019.
[12] Angela Fan, Pierre Stock, Benjamin Graham, et al. Training with Quantization Noise for Extreme Model Compression. arXiv preprint arXiv:2004.07320, 2020.
[13] Nils Reimers, Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP. 2019.
头图:Unsplash
作者:李兆海 胡智
原文:https://mp.weixin.qq.com/s/PPUh13SVvk3R0Tn0DgxWlQ
原文:深度学习在酒店售后智能问答场景实践
来源:Qunar 技术沙龙 - 微信公众号 [ID:QunarTL]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




