编者按:本文作者汪榕曾写过一篇文章:《以什么姿势进入数据挖掘会少走弯路》,是对想入行大数据的读者的肺腑之言,其中也表达了作者的一些想法,希望大家不要随便去上没有结合业务的收费培训班课程;而后,他有了结合他本人的工作经验,写一系列帮助大家进行实践学习课程文章的想法,InfoQ 也觉得这是件非常有意义的事情,特别是对于大数据行业 1-3 年工作经验的人士,或者是没有相关工作经验但是想入行大数据行业的人。课程的名称是“数据挖掘与数据产品的那些事”,目的是:1. 引导目标人群正确学习大数据挖掘与数据产品;2. 协助代码能力薄弱的学习者逐渐掌握大数据核心编码技巧;3. 帮助目标人群理解大数据挖掘生态圈的数据流程体系;4. 分享大数据领域实践数据产品与数据挖掘开发案例;5. 交流大数据挖掘从业者职业规划和发展方向。这系列文章会在 InfoQ 上形成一个专栏,本文是专栏的第一篇。
前言:工欲善其事,必先利其器。倘若不懂得构建一套大数据挖掘环境,何来谈 Data Mining!何来领悟“Data Mining Engineer”中的工程二字!也仅仅是在做数据分析相关的事罢了!此文来自于笔者在实践项目开发中的记录,真心希望日后成为所有进入大数据领域挖掘工程师们的良心参考资料。下面是它的一些说明:
- 它是部署在 Windows 环境,在项目的实践开发过程中,你将通过它去完成与集群的交互,测试和发布;
- 你可以部署成使用 MapReduce 框架,而本文主要优先采用 Spark 版本;
- 于你而言,它更多意义在于提高你在个人主机上进行业务场景建模的效率,方便你对算法模型进行测试和优化,以及打包、提交任务。
- 于我而言,网络上各种鱼龙混杂的资料,一方面是内容误导新人,更缺乏资源整合,一方面仅仅是搬运工,缺乏实践项目中的开发经验,有头无尾。这更是这篇文章的初衷。
铺垫:数据挖掘工程师是一个公司编制为数不多的岗位(你也许懂~)。对于新人,如果它是你的目标,你需要真正理解“挖掘”和“工程”的关联性和重要性,缺一不可;也希望你能区分它与分析师的差异性;更期待你能够知晓这个岗位在数据产品里的角色性,因为这些对于你如何去成为一位数据挖掘工程师来说,很重要!
说完上面这些杂七杂八的伏笔,下文我将深入仔细去引导你,如何去搭建属于自己 Spark 版本的 Data Mining 环境,以及某些环节在实践项目中开发的必要性。
第一步 : Java 安装和配置(1.7 或者 1.8)
- 理由:这是必须要去部署的环境,不解释。不过注意区分版本、以及个人主机是 32 位还是 64 位;
- 下载:本文提供 1.8 版本的下载 ,其中 32 位下载, 64 位下载;
- 安装配置:
-
1.【安装】:点击软件进行安装,按照引导步骤,并指定安装目录(个人喜爱),本文选择默认安装路径;
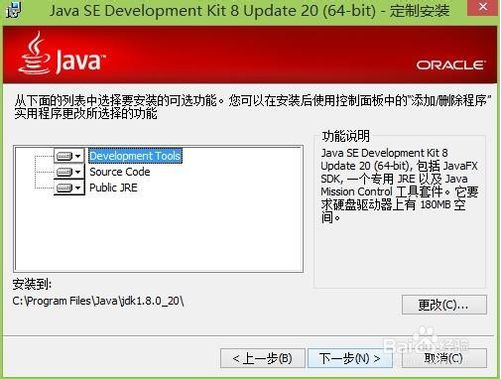
jdk 安装路径
-
2.【配置】:配置环境变量 JAVA_HOME 和路径 PATH,选择我的电脑 > 系统属性 > 高级系统设置 > 环境变量;
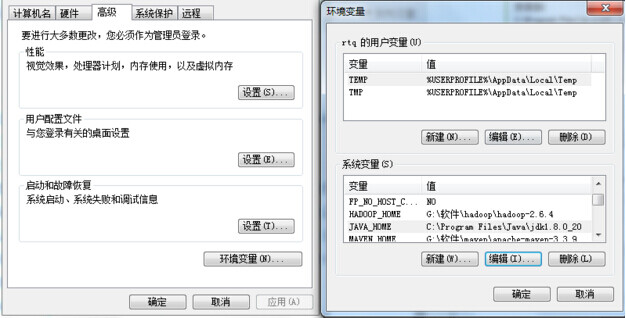
环境变量设置
a. 新建 JAVA_HOME,为 C:\Program Files\Java\jdk1.8.0_20。
b. 新建 CLASSPATH,为“.;%JAVA_HOME%/lib/dt.jar;%JAVA_HOME%/lib/tools.jar;”
c. 编辑 Path,添加“;%JAVA_HOME%/bin;%JAVA_HOME%/jre/bin”
-
考虑到有不少读者非软件专业,因此这里没有一笔带过基本的软件安装。最终安装成功的显示如下所示:

成功安装 java 的显示
第二步 : IDE 安装和配置(Eclipse 或者 Spring Tool Suite)
- 理由:编写工程代码的集成环境,也就是你写代码的地儿。注意 IDE 区分版本、以及个人主机是 32 位还是 64 位;
- 下载:本文提供最新 STS 版本的下载 ,其中 32 位下载, 64 位下载。也可以使用 Eclipse 或 SBT;
- 安装配置:
- 1. 将安装包下载放在选定目录,进行解压就可以了,并创建桌面快捷方式,方便以后使用;

STS 解压后应用程序
在后期使用 IDE 时,考虑到个人有代码洁癖,因此,我都推荐先设置好这几点:a.字体大小和类型,b.缩进方式,c.代码行数序号;
第三步 : IDE 插件的加载
- 理由:编写 MapReduce/Spark 工程需要的插件,注意区分 hadoop 版本。
- 下载:本文提供 hadoop2.6.0 版本的插件 ,其中下载地址
- 安装配置:
- 1. 将 Jar 包放在 STS 目录,位置于\sts-bundle\sts-3.8.1.RELEASE\dropins 下;
第四步 : Maven 的安装配置
- 理由:开发实践数据挖掘项目,更多采用 Maven 进行项目管理。
- 下载:本文提供两个版本的下载 ,其中 3.3.3 下载, 3.3.9 下载
- 安装配置:
- 1. 将安装包解压放在指定目录,设置全局变量 M2_HOME 和添加路径 PATH;

MAVEN 的全局变量和路径设置

Maven 安装成功的显示
第五步 : hadoop 包的下载配置
- 理由:代码执行过程中依赖 hadoop 的环境,需要单独配置 hadoop 的执行路径。
- 下载:本文提供 2.6.0 版本的下载 ,其中下载地址
- 安装配置:
- 1. 将安装包解压放在指定目录,设置全局变量 HADOOP_HOME 和添加路径 PATH;

配置 hadoop 的全局变量和路径
第六步 : hadoop 插件的加载配置
- 理由:代码执行过程中依赖 hadoop 的 JAR 插件,需要单独编译或者下载,放置在上述 hadoop 解压包的 bin 目录下。
- 下载:本文提供 2.6.0 版本的插件下载 ,其中 32 位, 64 位
- 安装配置:
- 1. 将安装包解压放在指定目录,将 hadoop.dll 和 winutils.exe 放在 hadoop 的 bin 目录下就可以了;

将 hadoop 插件放置于 bin 目录下
第七步 : spark 包的下载配置
- 理由:代码执行过程中依赖 spark 的配置环境,需要下载包放置在指定目录,并设置全局变量和路径。
- 下载:本文提供 spark-1.6.2-bin-hadoop2.6 版本的插件下载 ,其中下载地址
- 安装配置:
- 1. 将安装包解压放在指定目录,设置全局变量 SPARK_HOME 和添加路径 PATH;

配置 Spark 的全局变量和路径
通过上述的安装,可以通过下面的显示来验证是否成功

Spark 配置成功的显示
第八步 : scala 环境的安装配置
- 理由:代码执行过程中依赖 scala 的配置环境,需要安装 scala 环境,并设置全局变量和路径。
- 下载:本文提供三个版本的安装包下载 ,其中 2.10.1 , 2.10.4 , 2.11.0
- 安装配置:
- 1. 将安装包安装在指定目录,设置全局变量 SCALA_HOME 和添加路径 PATH,最终安装成功显示如下;

scala 成功安装的显示图
第九步 : scala ide 集成插件的加载配置
- 理由:IDE 集成环境执行过程中依赖 scala 插件的相关 JAR 包,需要单独下载相应版本的 scala ide,并将 features 和 plugins 目录下的文件都复制到上述 STS 集成环境下。
- 下载:本文提供两个版本的包下载 ,其中 32 位, 64 位。
- 安装配置:
- 1. 将下载包解压,复制 features 和 plugins 目录下的文件到\sts-bundle\sts-3.8.1.RELEASE\ 下的同命名文件目录中去;

scala ide 集成插件复制到 sts 指定目录
至此,通过以上 9 个步骤的下载、安装和配置,一个基于 Windows 的标配大数据挖掘环境就已经搭建好了。上面这些版本和链接都会在以后日子进行更新迭代,有部署过程中遇到问题的小伙伴,也可以积极将问题和截图发到评论里,一起进行解决。
- 下面的内容,本文就利用上述所有步骤部署的大数据挖掘环境做一个实践项目开发的流程,后期文章中会更深入引导数据产品中的数据挖掘工程开发。让真正想踏入大数据圈子做数据挖掘的小伙伴们,能够清楚自己目前应该做的事,以及公司级别实践应用的场景。不脱节、不迷茫、不盲目!
Step1:创建 MAVEN 工程

创建 Maven 工程中的步骤一

创建 Maven 工程中的步骤二
Step2:创建工程中的对象

创建 Maven 工程中的对象

创建成功显示图
Step3:配置好 pom.xml 文件,下载相关 Spark 依赖包

修改 pom.xml 文件,添加工程依赖包坐标
Step4:写一个朴素贝叶斯模型里涉及先验概率计算的逻辑,后期深入的开发等着以后的文章吧!
(点击放大图像)

代码逻辑,让大家看看模样
总结:工欲善其事,必先利其器!这句话里面有两层的逻辑,一方面,你在要踏入大数据挖掘领域的同时,应该要学会部署一套上述这样的环境,因为它对于你的模型工程开发、集群任务提交、数据产品项目开发、甚至是以后的模型优化重构,都是至关重要!一方面,我希望真正想学习大数据挖掘的小伙伴们,要走一个正确的方向,真正理解大数据生态圈的特点,要致力于为数据产品提供源源不断的大数据挖掘体系而奋斗,因为这事,不仅仅是玩玩而已!(上述下载的版本和链接都会在以后的时间进行更新维护)。
作者介绍:汪榕,3 年场景建模经验,曾累计获得 8 次数学建模一等奖,包括全国大学生国家一等奖,在国内期刊发表过相关学术研究。两年电商数据挖掘实践,负责开发精准营销产品中的用户标签体系。发表过数据挖掘相关的多篇文章。目前在互联网金融行业从事数据挖掘工作,参与开发反欺诈实时监控系统。




