瞬息万变的世界:敏捷 & DevOps
由于业务需求是变更最主要的驱动者,少做一些,但做得更好,交付更快,这是领先的企业和成功的企业与其他企业的不同之处。
当竞争对手交付了相关功能,速度比你快,质量比你好,那么你最终会丧失市场份额。用投资于销售和市场营销活动的方式弥补产品的不足,其代价会很高,而且可能不可靠,而且你可能会发现,客户转向了质量卓越的产品。
这正是“敏捷开发”产生的原因:需要更快地采取行动,应对不断变化的需求(因为我们的目标市场和竞争对手永远不会静止不动),可信赖的最佳品质,经常资源不足。敏捷就是源于科技公司和 IT 部门的期望。
自然地,下一步是找到一个将敏捷应用于生产的方法:连接开发和运维。这就产生了“DevOps”。
运维的主要目标是保证应用程序的稳定和健康,而开发的主要目标是不断地创新,并提供满足业务和客户需求的应用程序。理解这两点是 DevOps 发展的关键。既然变更是稳定最大的敌人这点没有疑问,那么理解和调和这种冲突应该是 DevOps 的主要目标。
为了有效地掌握敏捷冲刺部署以及实施 DevOps,人们需要能够实现部署自动化。否则,部署和发布就需要手动操作步骤和过程,而这些操作并不总是能够准确地重复,容易出现人为错误,并且无法进行高频率地处理。
处理数据库部署并不简单;不像其它软件组件和代码或者已编译的代码,数据库不是一个文件集合。那不是可以从开发环境复制到测试环境然后复制到生产环境的东西,因为数据库是个容器,里面装了我们最有价值且必须保存的资产——业务数据。它保存了所有应有程序内容、客户事务处理等。为了促成数据库变更,需要开发迁移代码——用于处理数据库模式结构(表结构)的脚本、数据库代码(过程、函数等)和应用程序使用的内容(元数据表、查找内容表或者参数表)。
数据库变更部署流程的挑战
应对数据库挑战的一个方法是,迫使数据库变更遵循一般过程:创建数据库对象的脚本,然后存储在传统的版本控制系统中。
那造成了其它的挑战,包括:
- 由于是两个单独的系统,版本控制系统中的脚本与它们所代表的数据库对象之间没有关联。数据库代码的编写和测试都是在数据库端完成,脱离了任何最佳编码实践(检入、检出、标记等),容易出现“旧时代”的所有问题,比如:
- 代码覆盖在数据库中很常见,因为没有什么能够防止它发生。
- 在数据库上运行代码之前,要先从版本控制系统中取得脚本,还要防止工作在错误的版本上;但是没有强制措施可以保证这一点。
- 脚本在版本控制系统中的路径可能会出错,因为开发人员靠记忆做这件事。
- 流程之外的更新会被忽视等等。
- 脚本是手动编写的,容易出现认为错误、语法错误等等。
- 为了拥有以后可能需要的一切,开发人员竟然不得不为每个对象保存两到三个脚本:对象的实际代码、升级脚本和回滚脚本。
- 脚本很难进行整体测试。一个人单独更新了一个对象,而另一个人单独更新了另一个对象,如果脚本需要以特定的顺序运行,那么以任意顺序运行通常就会由于错误的依赖关系而产生错误。
- 如果一个脚本被开发成代表整个更新而不是单个变更的单独脚本,那么它可以处理依赖关系,但处理项目范围的变更就要困难得多了。那是一个很长的命令列表。
- 除非非常有经验,否则这些脚本中会缺少从编写到运行这段时间内发生在目标环境里的变更;可能会覆盖生产环境中的热补丁,或者与另一个团队并行操作。
- 内容变更管理非常困难。实际上,版本控制系统不适合元数据或者查找内容。在大部分情况下,根本就没有对它们进行管理。

(点击上图可以查看大图)
最近十年,出现了另一种理念,就是使用工具处理环境间迁移代码的生成。这种操作方式被贴上了“比较 & 同步”的标签,是说用一种机械的比较方法检查源环境中的数据库对象,并将它与目标环境进行比较,如果发现差异,就会自动生成一个仿照源对象更改目标对象的脚本。在一段时间内,这似乎是个好方法,直到其缺陷变得越来越明显。
数据库的比较常常是在选定的检查点上执行的,通常是在开发周期结束之后,部署之前:
- 比较工具并不清楚发生在它运行之前的变更,或者任何发生在目标环境中的变更。没有版本控制,我们就没有变更信息,只知道特定时间点的差异。
- 对象脚本保存在传统的版本控制解决方案中,而部署使用的是比较 & 同步工具,你可以放开了想象,这两者之间是如何的无法协同。一个系统对另一个系统一无所知。
- 手动检查和关于每个变更的详细知识必须是部署流程的一部分。否则,下面这样的不幸就会发生,用过时的代码或者来自完全从事另外一项工作的团队的结构覆盖了生产环境中恰当的、最新的更新(比如由一个开发团队提供的热补丁)。
- 团队之间的代码合并完全无法实现。如果需要合并,就需要手动编写代码。
手动流程使用“比较 & 同步”工具还是可以的,但需要熟练和耐心。对数据库而言,试图基于这些工具自动化部署流程包含了相当大的风险。
DBA 深知数据库部署的陷阱,同时作为最不合时宜的故障的受害人,往往回避基于上述流程的自动化,因为他们对自动脚本生成器的准确性没有信心,或者对保证预先准备好的、手动生成的脚本在开发完成后任何时候都依然正确的能力没有信心。为了避免冲突,他们常常把事情掌握在自己手中。小心翼翼地检查变更,手动创建尽可能贴合部署活动的变更脚本,相比之下,这种做法似乎不那么令人沮丧。
安全的数据库部署自动化
通过将数据库对象变更脚本写进传统的版本控制系统中实现自动化的做法有局限性、不灵活、与数据库本身脱节,而且可能不合标准,并容易因为脚本冲突丢失目标环境的更新。使用“比较 & 同步”工具实现自动化则是一件有风险的事。这两种理念没有结合在一起,一个不知道另一个,必须找出一种更好的解决方案。
为了将数据库恰当地自动化,必须考虑下列因素:
- 在执行一个工作流程时,有恰当的数据库版本控制系统,应对数据库独有的挑战。这可以防止任何流程外的变更、代码覆盖、或者不完整的更新。
- 利用已经证明了的版本控制最佳实践,获得关于谁在什么时间因为什么做了什么的完整信息。确保变更的完美记录是以后部署的基础。
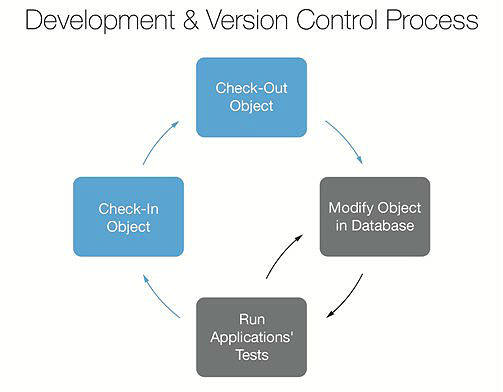
- 与基于任务的开发相协调,使每个版本控制下的变更与一个变更请求或者一个问题单相关联。这使得基于任务的部署、部分部署和最后时刻的范围变更可以在代码和数据库之间协调。
- 确保配置管理 & 一致性,这样,每个开发环境、分支、主干、沙箱以及测试或生产环境都遵循相同的结构、一致的状态;或者对任何偏差和差异做详细说明。
- 处理部署流程自动化的脚本化接口能够在每次执行时提供可重复的结果。如果不得不使用用户界面一次又一次地做同样的工作,那么即使是最先进的解决方案也会变得繁琐。
- 提供可靠的部署脚本,能够解决冲突、合并代码、以及与其他团队交叉更新;同时还能忽略错误的代码覆盖,以及完全集成到版本控制库。
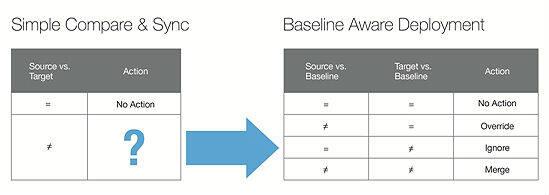

(点击上图可以查看大图)
7. 动态提供自动生成的开发脚本,处理部署项目范围内的任意组合,从多模式的大型更新,到基于单任务的变更及其所依赖的对象。
8. 在变更部署前后,利用“标签”(标记数据库结构快照和相关内容)作为安全网,这样,随时都可以简单快速地回滚。
9. 可以完全集成到其它系统(ALM、变更管理 / 问题单、构建服务器以及发布管理器)。
实现一种能够应对这些挑战的解决方案,将使企业能够实行恰当的数据库自动化。数据库自动化很容易与变更和发布流程的其余部分集成,进而实现完整的端到端的自动化。

(点击上图可以查看大图)
总结
数据库对自动化提出了一个真正的挑战。将数据库对象变更脚本写进传统的版本控制系统或者使用“比较& 同步”工具,对于自动化而言,这两种理念要么效率不高,要么是件纯冒险的事,因为它们彼此之间互不知晓。要以数据库DevOps 的形式实现一种更好的解决方案。
数据库DevOps 应该遵循已经证明了的变更管理最佳实践,在数据库上强制实行单一的变更流程,能够解决部署冲突,降低代码覆盖、交叉更新和代码合并的风险,同时能够插入到发布流程的其余部分。
关于作者
 Yaniv Yehuda是 DBmaestro 的联合创始人和 CTO,这是一家专注于数据库开发和部署技术的企业级软件开发公司。Yaniv 还是 Extreme Technology 的联合创始人和开发主管,这是一家面向以色列市场的 IT 服务提供商。Yaniv 曾经是以色列国防军计算机中心 Mamram 的一名上尉,他在那里担任软件工程经理。
Yaniv Yehuda是 DBmaestro 的联合创始人和 CTO,这是一家专注于数据库开发和部署技术的企业级软件开发公司。Yaniv 还是 Extreme Technology 的联合创始人和开发主管,这是一家面向以色列市场的 IT 服务提供商。Yaniv 曾经是以色列国防军计算机中心 Mamram 的一名上尉,他在那里担任软件工程经理。
查看英文原文:**** The Secrets of Database Change Deployment Automation




