
3 月 31 日,百度发布业界首个基于全新互相关注意力(Cross-Attention)的端到端语音语言大模型,实现超低时延与超低成本,在电话语音频道的语音问答场景中,调用成本较行业均值下降约 50%-90%。当日,文小言宣布品牌焕新,率先接入该模型,还带来多模型融合调度、图片问答等功能升级。
文小言最核心的三个场景依然是:搜、创、聊,支持这三个核心场景下有各种模型和技术。相比产品本身形象的升级,最重要的有两件事情:开放和应用,即能够兼容各种优秀先进模型、把各种先进模型能力用
文小言除了视觉变化,内核已经从单引擎大模型驱动,变成由多模型引擎驱动。更新后的文小言支持“多模型融合调度”,通过整合百度自研的文心 X1、文心 4.5 等顶尖模型,并接入 DeepSeek-R1 等第三方优质模型,实现了多模型间的智能协同。
百度自研大模型不但能“看”,更能“说”和“听”,背后就是其端到端语音大模型。新的端到端语音模型体验比原来会很大的提升,比如能够识别儿童的含糊发音,理解能力更符合儿童的习惯。
接入全新的端到端语音语言大模型后,文小言不仅能支持更拟真的语聊效果,而且支持重庆、广西、河南、广东、山东等特色方言。据介绍,语音大模型具备极低的训练和使用成本,极快的推理响应速度,语音交互时,可将用户等待时长从行业常见的 3-5 秒降低至 1 秒左右。
用户可以选择“自动模式”,一键调用最优模型组合,也可根据需求灵活选择单一模型完成特定任务,大幅提升响应速度与任务处理能力。
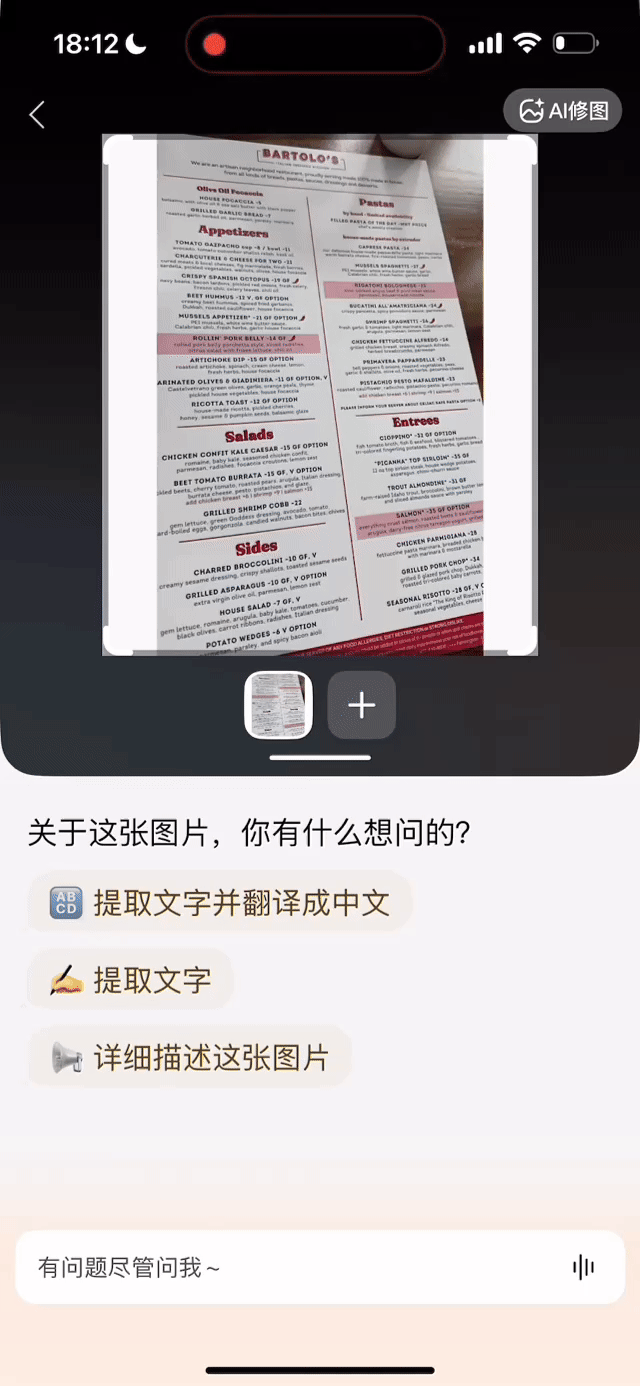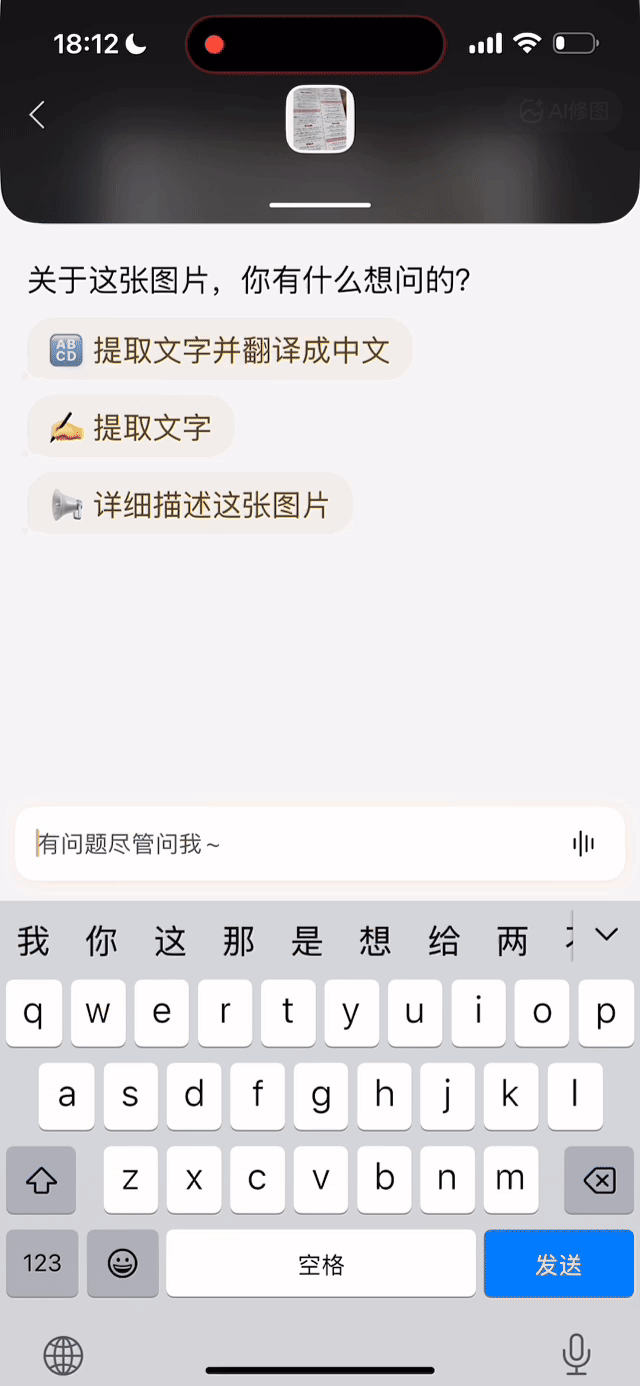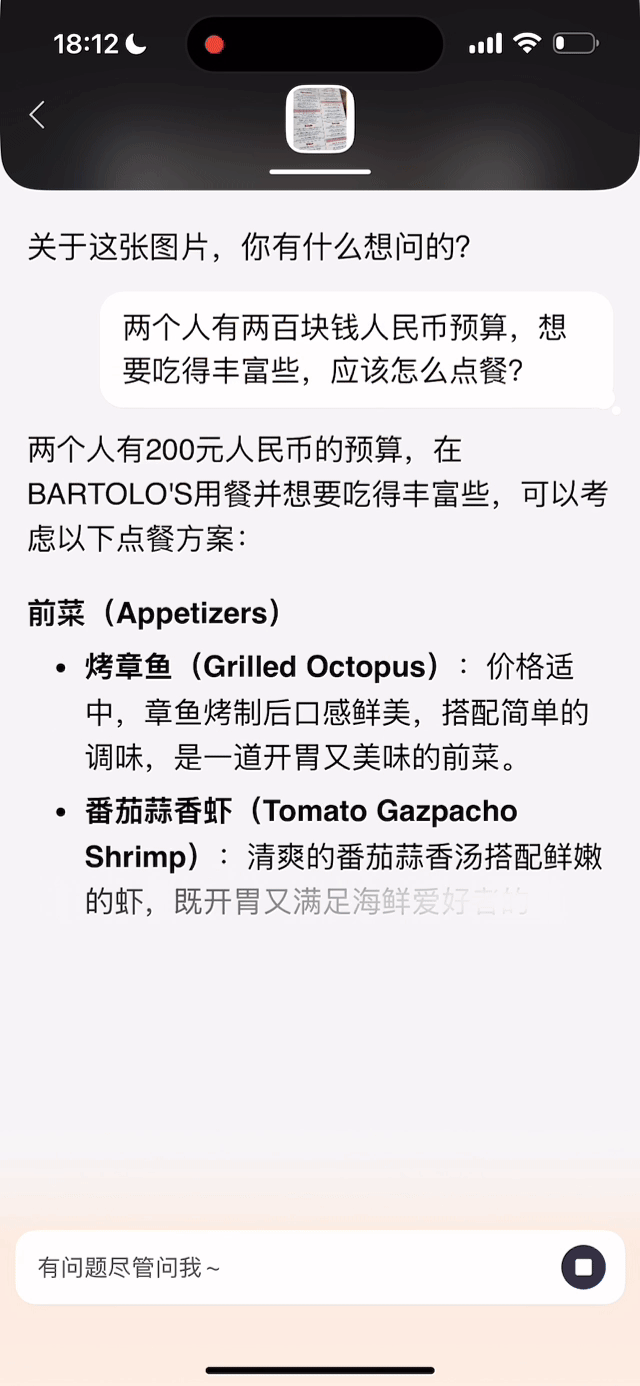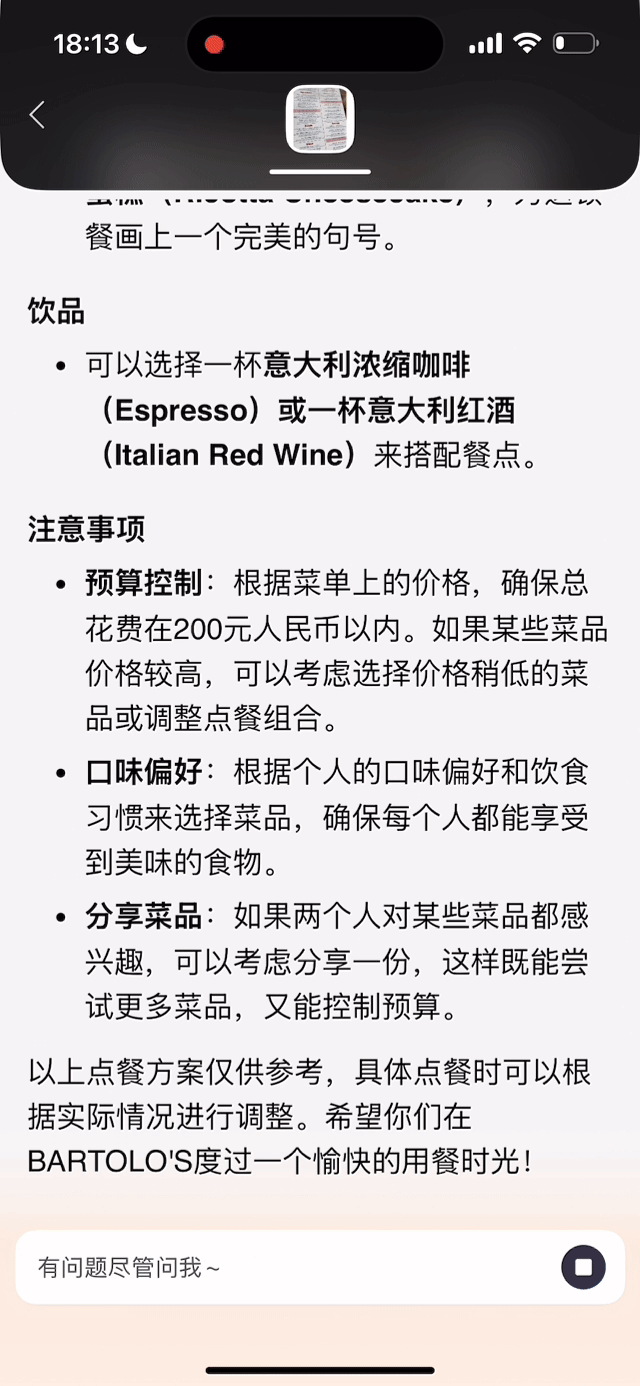
同时,文小言还加强了图片问答功能,用户拍摄或上传图片,以文字或语音提问即可直接获取深度解析。例如,拍摄一道数学题可实时生成解题思路与视频解析;上传多款商品图可对比参数、价格,辅助购物决策;拍摄杯子设计图后,AI 可自动解析风格并生成同款手机壳、支架等周边产品。





