
本文要介绍的是 2011 年 NSDI 期刊中的论文 —— Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center1,该论文实现的 Mesos 能够在集群中管理不同的计算框架,例如 Hadoop 和 MPI 等。虽然 Mesos 集群管理系统是 10 多年前发布的技术,今天已经逐渐被更主流、更通用的容器编排系统 Kubernetes 取代,但是它确实可以解决集群管理上的部分问题。
Apache Mesos 和 Kubernetes 都是优秀的开源框架,也都支持大规模的集群管理,但是它们两个管理的集群规模仍然差一个数量级,单个 Mesos 集群可以管理 50,000 节点,而 Kubernetes 集群却只能管理 5,000 节点,需要做很多优化和限制,才能达到相同的数量级。
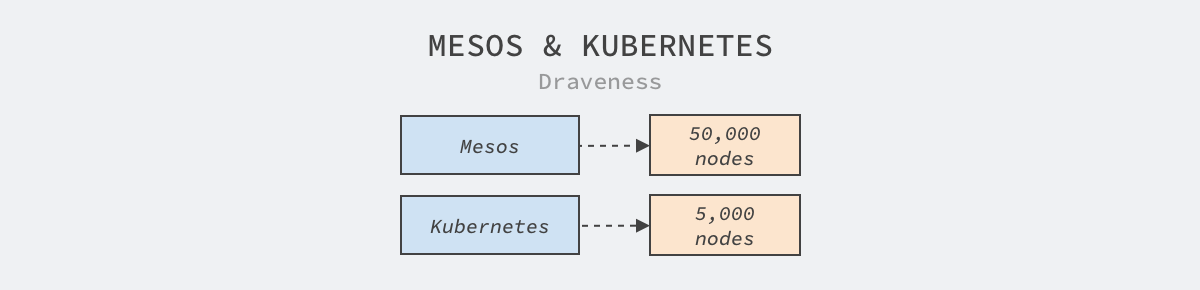
图 1 - Kubernetes 和 Mesos 集群
虽然 Kubernetes 是今天集群管理的主流技术,但是 Mesos 在刚刚出现时也是很先进的集群管理系统,它想要取代的是当时更为常见的静态分片集群。静态分片集群虽然可以同时运行属于不同框架的工作负载(例如:Hadoop、MPI),但是因为框架的异构性,使用静态分片技术会将集群中的机器预先分配给不同的框架,再由这些框架分配和管理资源。
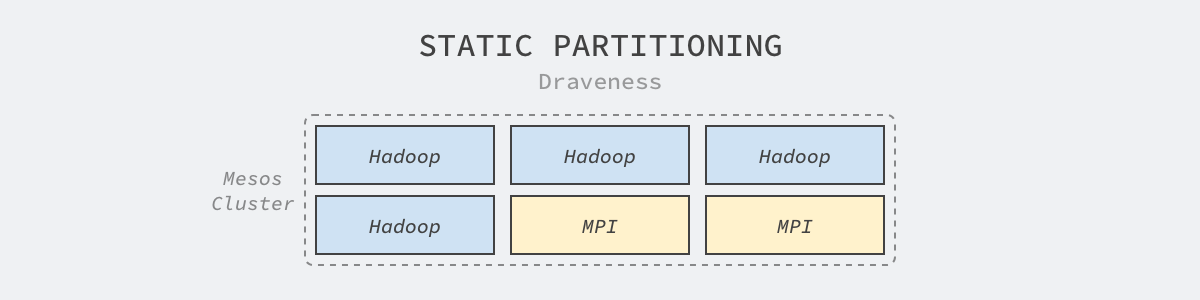
图 2 - 静态分片
Mesos 在最初设计时并不会直接管理和调度开发者提交的工作负载,而是提供一组接口暴露集群的资源,并通过这组轻量级的接口同时对接 Hadoop、MPI 等框架。
架构
如下图所示的 Mesos 集群同时运行了 Hadoop 和 Mesos 两个框架,如果忽略图中与 Hadoop、MPI 框架的相关模块,我们会发现架构会变得非常简单,它仅由 Zookeeper 集群、Mesos 主节点和工作节点组成。
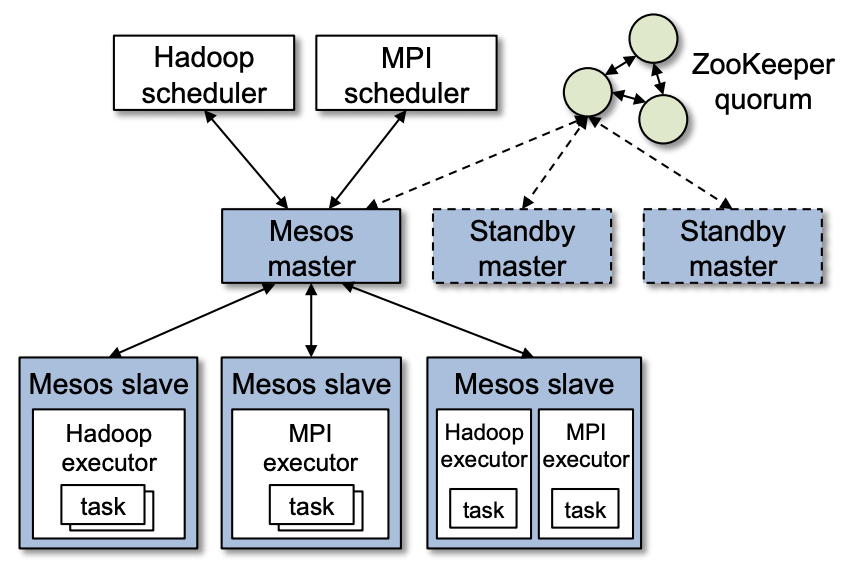
图 3 - Mesos 架构图
Zookeeper 集群提供了高可用的数据存储和选举等功能;
Mesos 主节点收集工作节点上报的数据并向框架的调度器提供资源;
Mesos 工作节点上报数据并通过框架的执行者在本地启动任务;
每个 Mesos 集群中运行的框架都由调度器和执行者两部分组成,调度器会处理主节点提供的资源,与 Kubernetes 的调度器有着相同的作用,当调度器接受主节点提供的资源后,它会返回待运行任务的相关信息;而执行者会在工作节点上运行框架创建的任务。
Mesos 为了保证更好的可扩展性,它定义了一套能够满足资源共享的最小接口,将任务调度和执行的控制权都通过如下所示的接口交给框架,其本身仅保留较粗粒度的调度和资源管理功能。
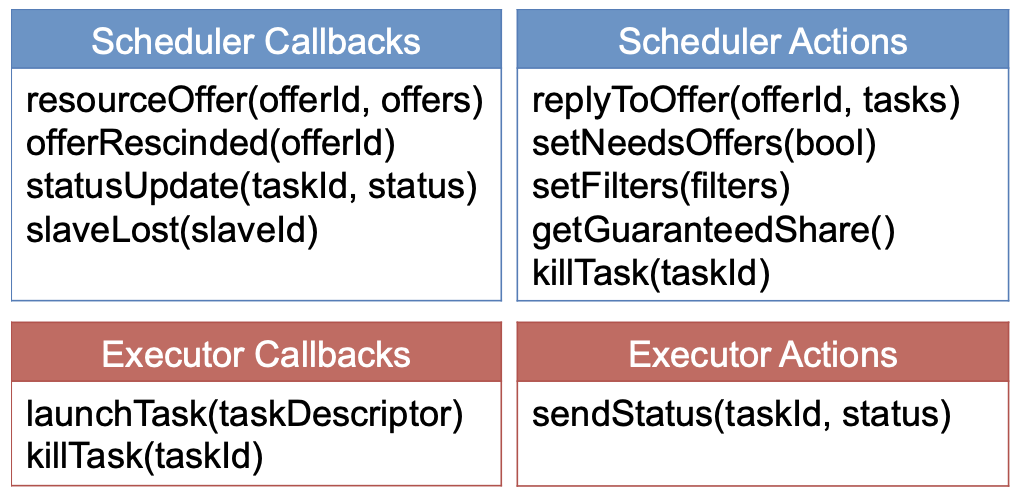
图 4 - Mesos 接口
因为 Mesos 中的任务调度是分布式的过程,所以为了保证该过程的效率和可靠性,它引入了下面的这三种机制:
节点过滤器:框架使用过滤器剔除集群中不满足自身调度条件的节点;
资源主动分配:为了提高框架的调度速度,会将预先提供给框架的资源计入框架的总分配资源,直到框架完成调度,这能激励框架实现更快的调度器;
资源撤回:如果框架在一段时间内没有处理主节点提供的资源,Mesos 会撤回资源并提供给其他框架;
除了提供良好的扩展性和性能之外,作为集群调度管理系统,Mesos 也面临着隔离不同任务资源的问题。在 Mesos 刚刚发布时,容器技术还没有像今天这么普及,但是它也利用操作系统的容器隔离不同工作负载的影响2,并利用可插拔式的隔离模块支持多种隔离机制。
调度模型
我们在文章开篇就已经介绍过 Mesos 和 Kubernetes 能够管理的集群规模有数量级的差距,这里简单对比分析下两者在调度器上的差异,这能帮助我们理解 Kubernetes 调度器在设计时做出的决策,以及这些决策是如何影响它的可扩展性。
需要注意的是,提升系统可扩展性往往都是复杂的问题,而在 Kubernetes 这样庞大的系统中会显得更加复杂,Kubernetes 的调度器不是影响其可扩展性的唯一因素,想要提升单个集群的规模要从多个方面入手。
Mesos 的调度器选择了两层的调度设计,其中顶层调度器仅会根据底层框架调度器的需求粗粒度地过滤集群中的节点,而框架调度器会执行真正的任务调度,将任务绑定到相应的节点上。
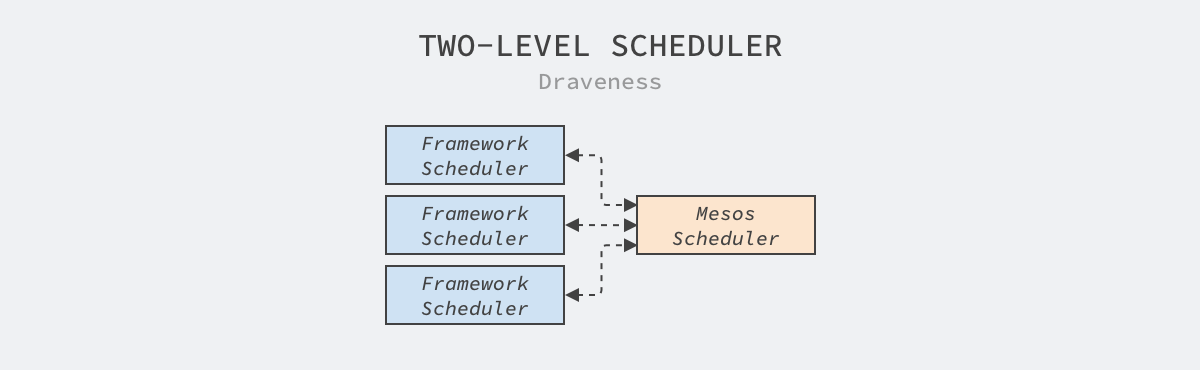
图 5 - 两层调度器
这种两层的调度器设计看起来虽然很复杂,但是实际上它能够降低 Mesos 调度器的复杂度并提高了它的可扩展性:
降低复杂度:顶层调度器不需要处理真正的调度过程,它仅通过资源提供(Resource Offer)机制将一组节点交给底层调度器控制;
提高可扩展性:两层调度器设计可以更方便地接入新的框架调度器,兼容不同复杂的调度策略,不同框架调度器内部可以串行为任务选择节点,提高整体调度的吞吐量;
虽然 Mesos 通过两层调度器设计提供了很强的扩展性,但是它却不能为调度决策提供全局最优解。这是因为所有的调度决策都是在整个集群中的一部分节点中做出的,所有的调度决策都只是局部最优的,而这也是多调度器中的常见问题3。
在调度系统中,想要实现更好的扩展性就一定面临着分片,分片必然导致调度器无法提供全局最优解并且显著地增加系统的复杂性。我们从 Linux、Go 语言等 CPU 调度器的演进可以观察到这点,最初的调度器大多数都是单线程的,为了提高调度器的性能,会使用多调度器并引入工作窃取机制处理多调度器中待调度任务队列的不平衡。
Kubernetes v1.21 版本的内置调度器仍然是单线程的,它为了在全局 5,000 个节点中做出最优的调度决策,需要使用不同的插件遍历这 5,000 个节点并排序,而这也是影响其扩展性的重要原因之一。全局最优解听起来是非常美好的设计,但是在调度这种比较复杂的场景中,局部最优解往往也都可以满足需求,在业务上不需要保证该约束时,就可以通过多调度器来提升性能了。
总结
当对比 Mesos 和静态分片集群的资源利用率时,我们会发现 Mesos 在 CPU 和内存的集群资源利用率上都明显高于使用静态分片的集群,而这个结果也不会造成太多的意外,因为动态的资源分配策略一般都能够提高集群的资源利用率。
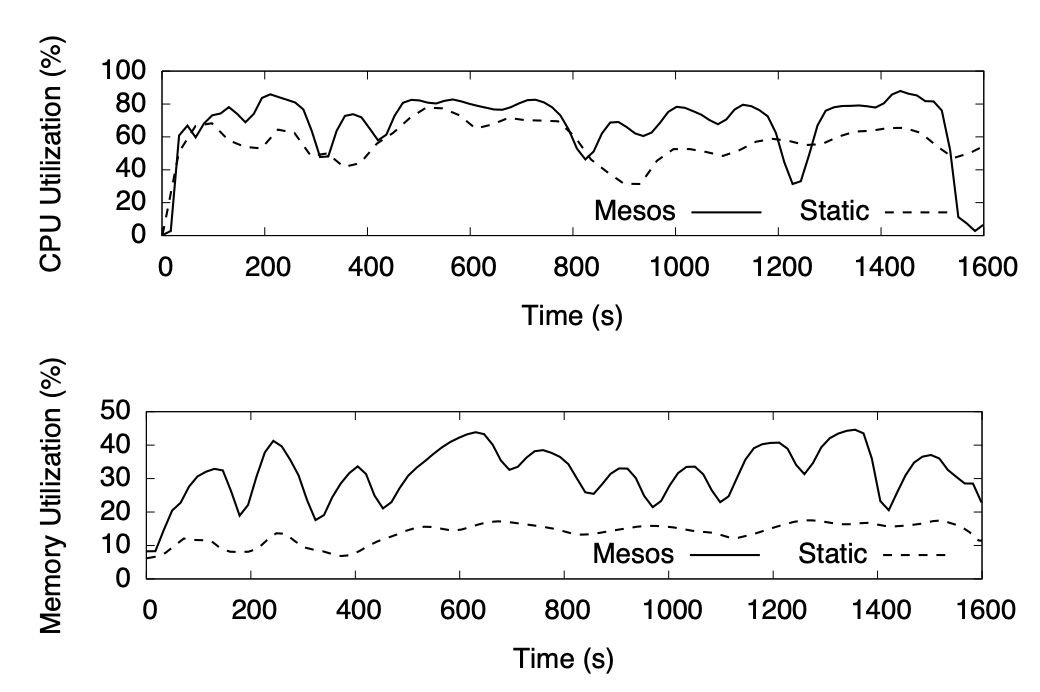
图 6 - Mesos 和静态集群的资源利用率对比
了解 Mesos 出现时解决的问题以及它的设计可以让我们更好地理解今天面临的挑战,Mesos 在刚刚出现时是非常新颖的技术,与同期的其他产品来讲确实提供了很强的灵活性,但是随着 Yarn、Kubernetes 等技术的出现,它的很多场景也都被新技术取代,而这也是技术发展的必然趋势。
推荐阅读
Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, and Ion Stoica. 2011. Mesos: a platform for fine-grained resource sharing in the data center. In Proceedings of the 8th USENIX conference on Networked systems design and implementation (NSDI'11). USENIX Association, USA, 295–308. ↩︎
What’s LXC? https://linuxcontainers.org/lxc/introduction/ ↩︎
本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。
文章图片
你可以在 技术文章配图指南 中找到画图的方法和素材。
本文转载自:面向信仰编程




