
服务必然会退化。这只是一个时间问题,而不是如果。当服务不可用、延迟增加或者成功率降低时,在具有许多相互依赖的微服务的分布式系统将越来越难以理解将会发生什么。企业只有在生产中出现问题,对客户造成影响时,才能发现问题的严重程度。这就是混沌工程(Chaos Engineering )能帮到我们的地方。
混沌工程是一门在系统上进行实验的学科,旨在建立人们对系统在生产环境中承受紊流状态的能力的信心。
对受控生产环境中的服务退化进行定期的测试,使我们能够预先验证系统的弹性并发现问题。在 Lyft 的发展过程中,我们迅速认识到混沌工程的重要性。因为 Lyft 服务之间的所有通信都是通过 Envoy Proxy 运行的,所以像故障注入这样的混沌实验利用它进行看起来是个不错的选择。
Lyft 几年前的情况
故障注入实验是在 Lyft 之前使用 Envoy 的运行时(磁盘层)进行的。工程师们执行一个 CLI 命令,在本地生成运行时文件。在将运行时文件提交到 GitHub 之后,通过将其写入主机集群的本地文件系统来部署它们。Envoy 将这些文件读取到内存中,然后向请求中注入故障。如果工程师想终止故障,他们必须重复相同的过程。在 Lyft 刚开始的时候,为了应对万圣节、新年前夜等节日的流量激增,他们进行了一次性实验,结果很好。但是,在大规模运行时,它也存在缺陷。
高接触
很多情况下,工程师需要在实验中执行多个步骤,比如为 1% 的请求注入故障,然后缓慢地增加以确保安全。向 GitHub 提交时需要提交很多次,过程很麻烦。
故障注入时间长
一旦运行时的变化被合并,运行时的部署需要几分钟的时间才能完成。如果实验导致了实际生产中的问题,而工程师想立即终止实验时,那就会有风险。
不能洞察全部活动故障
很难确定在一段时间内运行了多少次故障。这一信息对于从鸟瞰的角度观察所有的实验非常重要。
外部依赖关系:GitHub
这个过程依赖于 GitHub。当 GitHub 瘫痪时(这有可能发生,因为它毕竟是一项服务),活动故障将在系统中持续很长一段时间,并且无法界定。这个缺点太严重了,会危及我们的业务。
推出混沌实验框架
混沌实验框架(Chaos Experimentation Framework,CEF)是一个建立在 Clutch 的 Envoy Proxy 基础上的开源框架。对于整合 CEF,Clutch 是非常有意义的,因为我们可以利用内置特性,比如丰富的响应式用户界面、基于角色的访问控制、审计日志、数据库层、统计数据接收器等。
CEF 提供了一个强大的后端和用户友好的用户界面,这让工程师们对他们的实验充满信心。在从用户界面开始试验之后的几毫秒内,后端就会注入故障。这种方式通过使用 Envoy Proxy 的 xDS APIs 来传输失败配置,而不依赖于将配置部署到每台机器。其设计用于快速注入故障,无任何依赖关系。
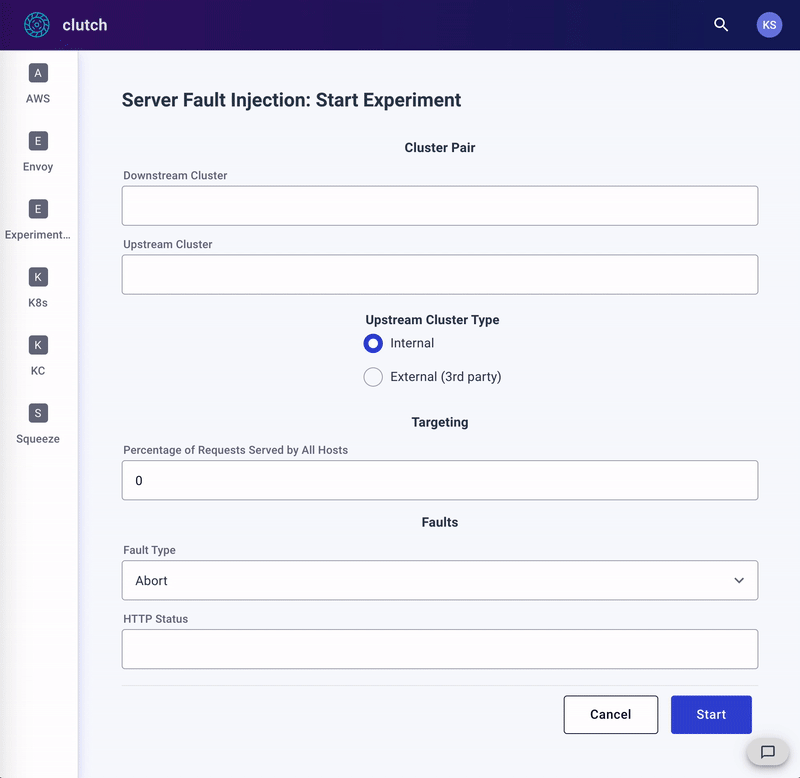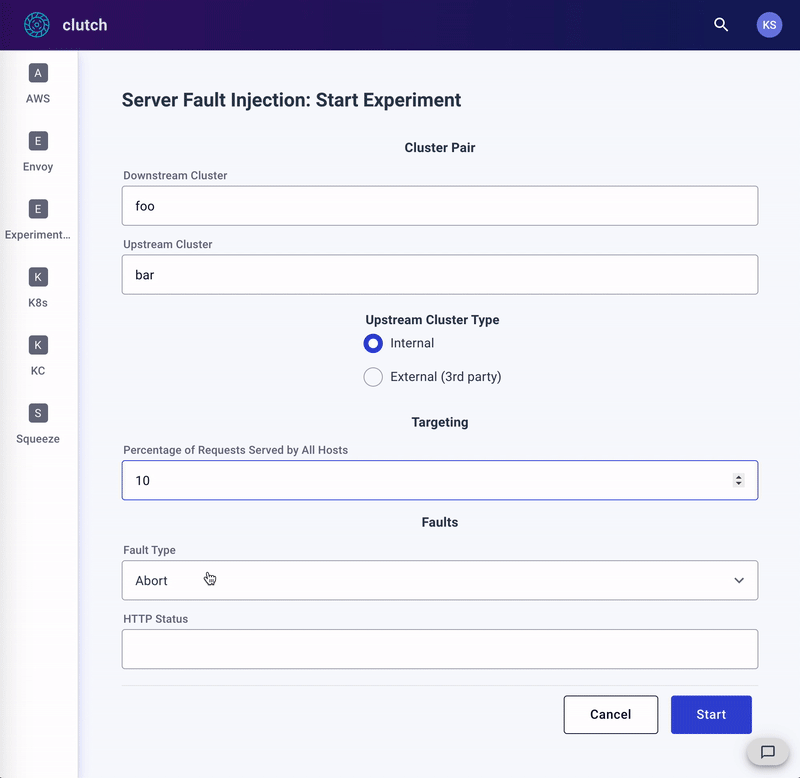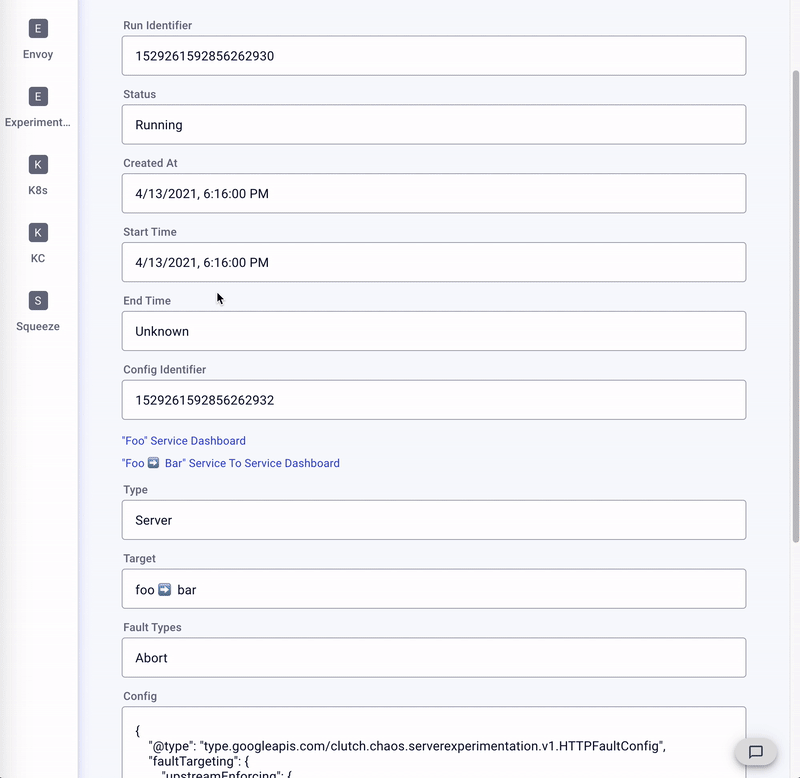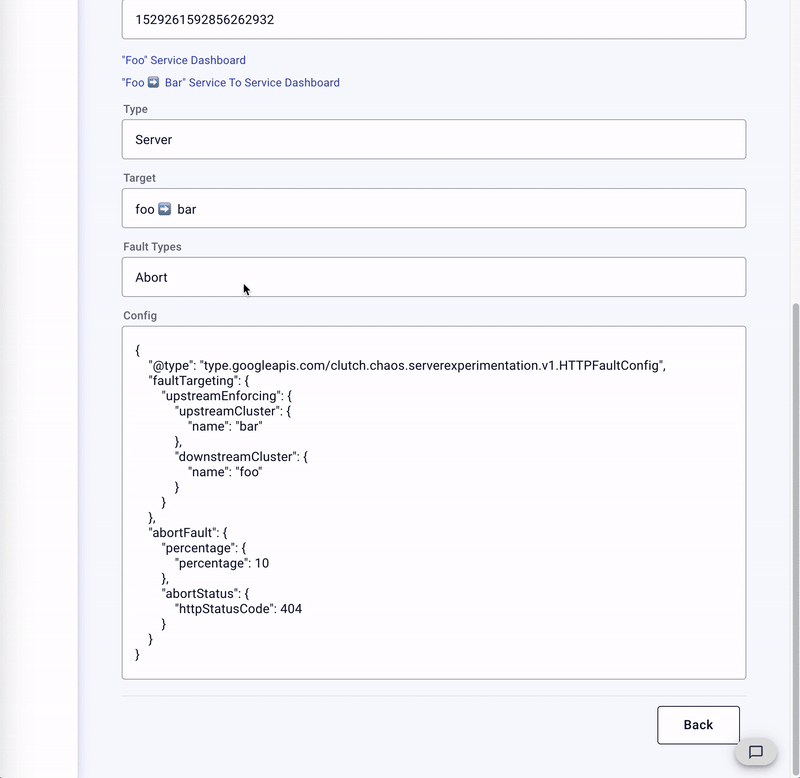
服务器混沌实验流程
好处
我们在 Lyft 看到了 CEF 带来的一些好处。
自助式服务
这一框架是完全自助式的,Lyft 的工程师只需点击一个按钮就能在他们的服务中快速进行故障注入实验。
与 CI/CD 管道集成
我们对所有的部署进行实验,以确保新代码的部署不会影响服务对故障的恢复能力。这样就保证了系统的单行定期得到检验。
保证客户的弹性
在 Lyft 努力保证服务网络具有弹性的同时,保证移动客户端拥有一个后备计划也同样重要,因为它并没有达到预期的效果。一般来说,移动客户端上的产品流都是在理想状态下进行测试的,也就是“快乐路径”。但是,在 QA 环境中,测试非理想路径下的流是困难的。如果能够在移动客户端端点定期运行故障注入实验,我们就能够最大限度地降低后端服务退化对客户的影响。
更快的服务层审计
根据每项服务的业务关键程度,Lyft 服务分为不同的层次(0 层 ~ 3 层)。第 0 层是最重要的,我们将故障注入到第 1 层服务中,该服务具有第 0 层的下游依赖关系。使用这种方法,我们模拟了某一特定第 1 层服务经历退化的情形,并观察这种退化如何影响第 0 层下游依赖。理想情况下,第 1 层服务不应该硬依赖于第 0 层服务。但是,我们发现有些情况并非如此。通过 CEF,这样的层级审计速度更快。
验证对第三方外部服务的回退
通常情况下,在外部服务(如 Mapbox、谷歌地图、DynamoDB、Redis 等)发生故障之前,很难对其进行测试。有了 CEF,Lyft 的工程师们一直在主动验证回退逻辑,以防止外部服务出现退化。
使可观察性和配置保持最新
通过定期进行故障注入测试,工程师们预先调整了服务报警、超时和重试策略。除了这些调整之外,他们还确保在出现问题时,服务的统计数据和日志记录能够提供明确的根源指示。
“混沌实验框架非常简单,而且使用起来也非常直截了当。这使得服务所有者可以确定微服务的弹性。”
—— 一位 Lyft 工程师的评价
架构
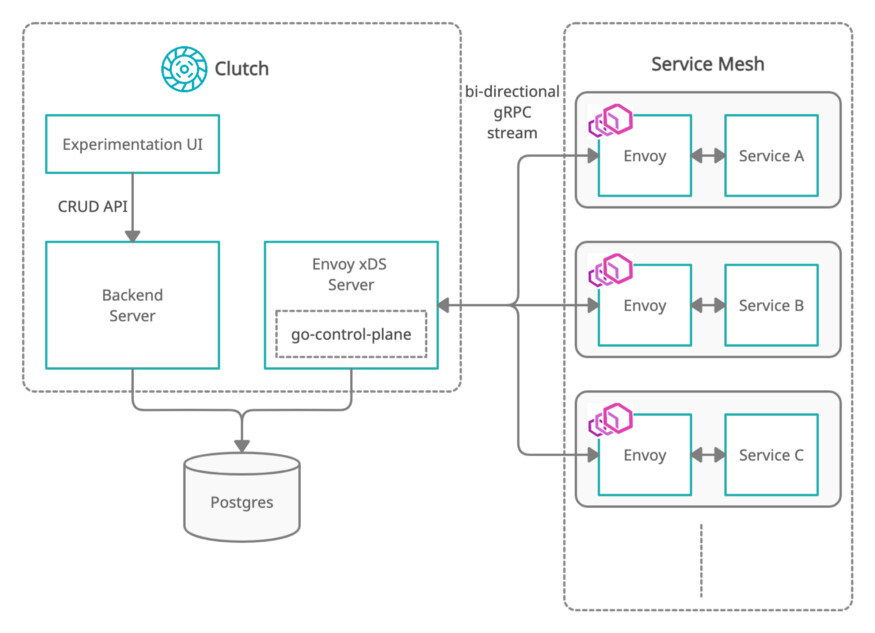
混沌实验框架的架构及其与 Envoy 服务网格的交互
该框架中有两个主要组件:后端服务器和 Envoy xDS 管理服务器。
后端服务器负责实验的所有 CRUD 操作。它将实验存储在其 Postgres 数据库的表中。
该框架的另一个组件是 xDS 管理服务器。该管理服务器由 Envoy Proxy 的扩展配置发现服务(Extension Configuration Discovery Service,ECDS)和运行时发现服务(Runtime Discovery Service,RTDS)API 组成。所有的 xDS API 都可以用来进行故障注入实验。通过 RTDS,可以对特定运行时故障进行修正。ECDS 允许对整个故障过滤器进行修改,以便执行任何自定义实验。在网状结构中启动 Envoy 后,它与管理服务器创建一个双向 gRPC 流。以下是 Envoy 中的 RTDS 配置代码片段:
layered_runtime: layers: - name : rtds rtds_layer: name: rtds rtds_config: resource_api_version: v3 api_config_source: api_type: GRPC transport_api_version: v3 grpc_services: envoy_grpc: {cluster_name: clutchxds} ...http_filters:- name: envoy.fault typed_config: "@type": "type.googleapis.com/envoy.extensions.filters.http.fault.v3.HTTPFault" abort: percentage: numerator: 0 denominator: HUNDRED http_status: 503 delay: percentage: numerator: 0 denominator: HUNDRED fixed_delay: 0.001s...
管理服务器定期轮询 Postgres,以获取所有活动实验。随后形成一个具有 TTL 的运行时资源,并将其发送到各自的集群中。因此,故障的传播只需要几毫秒。
该框架本身具有很大弹性。如果服务的成功率下降到超过了配置的阈值,那么实验将自动终止。此外,当管理服务器本身出现退化时,所有的实验都会自动禁用,而无需工程师的介入。
与 Clutch 和 Envoy Proxy 一样,整个框架都是通过配置驱动的。用户可以选择 ECDS 或 RTDS,调整 Postgres 的轮询时间,提供运行时前缀,调整资源 TTL 时间,等等。
未来之路
在这一领域还有很多工作要做,以防止系统的退化影响客户。以下是我们提出的一些未来改进的想法:
调度将使我们能够全天候运行实验,并为系统的最新性和弹性提供更多的信心。
利用 Envoy 的负载报告服务 API 进行实时统计(每秒钟)
要进行更积极的实验,就需要有一个严格的指标驱动的反馈系统,以确保我们能够在实验影响到用户之前迅速终止实验。
挤压测试使我们可以把额外的流量路由到特定服务的特定主机,并帮助确定该主机在集群中可以提供的最大并行请求数。基于挤压测试,工程师可以设定服务的扩展阈值和其断路阈值。
该框架已经提供了对注入 Redis 故障的基本支持。然而,更高级的特性将允许根据一组 Redis 命令注入故障,并进行延迟注入或连接失败实验。
作者介绍:
Kathan Shah,Lyft 软件工程师。
原文链接:




