
本文最初发布于 rubikscode.com 网站,经原作者授权由 InfoQ 中文站翻译并分享。
围绕模型优化这一主题发展出来的许多子分支之间的差异之大往往令人难以置信。其中的一个子分支叫做超参数优化,或超参数调优。
在本文中你会学到:
机器学习中的超参数
前置条件和数据
网格搜索超参数调优
随机搜索超参数调优
贝叶斯超参数优化
减半网格搜索和减半随机搜索
替代选项
机器学习中的超参数
超参数是所有机器学习和深度学习算法都包含的一部分。与由算法本身学习的标准机器学习参数(如线性回归中的 w 和 b,或神经网络中的连接权重)不同,超参数由工程师在训练流程之前设置。
它们是完全由工程师定义的一项外部因素,用来控制学习算法的行为。想看些例子?学习率是最著名的超参数之一,SVM 中的 C 也是超参数,决策树的最大深度同样是一个超参数,等等。这些超参数都可以由工程师手动设置。
但是,如果我们想运行多个测试,超参数用起来可能会很麻烦。于是我们就需要对超参数做优化了。这些技术的主要目标是找到给定机器学习算法的最佳超参数,以在验证集上获得最佳评估性能。在本教程中,我们探索了几种可以为你提供最佳超参数的技术。
前置条件和数据
前置条件和库
请安装以下 Python 库,为本文接下来的内容做准备:
NumPy——如果你需要安装帮助,请参考这份指南。
SciKit Learn——如果你需要安装帮助,请参考这份指南。
SciPy——如果你需要安装帮助,请参考这份指南。
Sci-Kit Optimization——如果你需要安装帮助,请参考这份指南。
安装完成后,请确保你已导入本教程中使用的所有必要模块。
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import f1_scorefrom sklearn.model_selection import GridSearchCV, RandomizedSearchCVfrom sklearn.experimental import enable_halving_search_cvfrom sklearn.model_selection import HalvingGridSearchCV, HalvingRandomSearchCVfrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestRegressorfrom scipy import statsfrom skopt import BayesSearchCVfrom skopt.space import Real, Categorical除此之外,你最好起码熟悉一下线性代数、微积分和概率论的基础知识。
准备数据
我们在本文中使用的数据来自 PalmerPenguins 数据集。该数据集是最近发布的,旨在作为著名的 Iris 数据集的替代品。它由 Kristen Gorman 博士和南极洲 LTER 的帕尔默科考站共同创建。你可以在此处或通过 Kaggle 获取此数据集。
该数据集本质上是由两个数据集组成的,每个数据集包含 344 只企鹅的数据。就像 Iris 一样,这个数据集也有来自帕尔默群岛 3 个岛屿的 3 个种类的企鹅。此外,这些数据集包含每个物种的 culmen 维度。culmen 是鸟喙的上脊。在简化的企鹅数据中,culmen 长度和深度被重命名为变量 culmen_length_mm 和 culmen_depth_mm。
由于这个数据集已经标记过了,我们应该能验证我们的实验结果。但实际情况往往没这么简单,聚类算法结果的验证通常是一个艰难而复杂的过程。
我们先来加载并准备 PalmerPenguins 数据集。首先,我们加载数据集,删除本文中不会用到的特征:
data = pd.read_csv('./data/penguins_size.csv')data = data.dropna()data = data.drop(['sex', 'island', 'flipper_length_mm', 'body_mass_g'], axis=1)然后我们分离输入数据并对其进行缩放:
X = data.drop(['species'], axis=1)ss = StandardScaler()X = ss.fit_transform(X) y = data['species']spicies = {'Adelie': 0, 'Chinstrap': 1, 'Gentoo': 2}y = [spicies[item] for item in y]y = np.array(y) 最后,我们将数据拆分为训练和测试数据集:
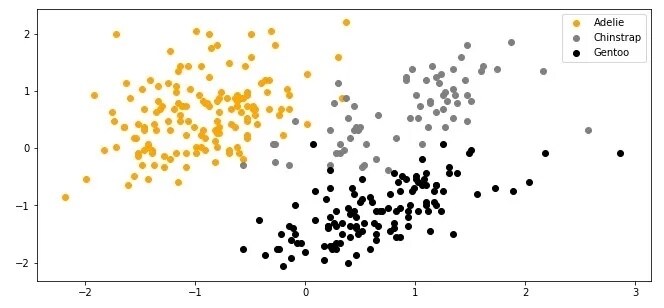
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=33)当我们绘制这里的数据时,图像是下面这个样子:
网格搜索超参数调优
超参数调优的工作手动做起来又慢又烦人。所以我们开始探索第一个,也是最简单的超参数优化技术——网格搜索。这种技术可以加快调优工作,是最常用的超参数优化技术之一。从本质上讲,它会自动化试错流程。对于这种技术,我们提供了一个包含所有超参数值的列表,然后该算法为每个可能的组合构建模型,对其进行评估,并选择提供最佳结果的值。它是一种通用技术,可以应用于任何模型。
在我们的示例中,我们使用 SVM 算法进行分类。我们考虑了三个超参数——C、gamma 和 kernel。想要更详细地了解它们的话请查看这篇文章。对于 C,我们要检查以下值:0.1、1、100、1000;对于 gamma,我们使用值:0.0001、0.001、0.005、0.1、1、3、5,对于 kernel,我们使用值:“linear”和“rbf”。
网格搜索实现
下面是代码中的样子:
hyperparameters = { 'C': [0.1, 1, 100, 1000], 'gamma': [0.0001, 0.001, 0.005, 0.1, 1, 3, 5], 'kernel': ('linear', 'rbf')}我们这里利用了 Sci-Kit Learn 库及其 SVC 类,其中包含 SVM 分类实现。除此之外,我们还使用了 GridSearchCV 类,用于网格搜索优化。结合起来是这个样子:
grid = GridSearchCV( estimator=SVC(), param_grid=hyperparameters, cv=5, scoring='f1_micro', n_jobs=-1)这个类通过构造器接收几个参数:
estimator——实例机器学习算法本身。我们在那里传递 SVC 类的新实例。
param_grid——包含超参数字典。
cv——确定交叉验证拆分策略。
scoring——用于评估预测的验证指标。我们使用 F1 分数。
n_jobs——表示要并行运行的作业数。值-1 表示正在使用所有处理器。
剩下要做的就是使用 fit 方法运行训练过程:
grid.fit(X_train, y_train)训练完成后,我们可以查看最佳超参数和这些参数的得分:
print(f'Best parameters: {grid.best_params_}')print(f'Best score: {grid.best_score_}')
Best parameters: {'C': 1000, 'gamma': 0.1, 'kernel': 'rbf'}Best score: 0.9626834381551361 此外,我们可以打印出所有结果:
print(f'All results: {grid.cv_results_}')
Allresults: {'mean_fit_time': array([0.00780015, 0.00280147, 0.00120015, 0.00219998, 0.0240006 , 0.00739942, 0.00059962, 0.00600033, 0.0009994 , 0.00279789, 0.00099969, 0.00340114, 0.00059986, 0.00299864, 0.000597 , 0.00340023, 0.00119658, 0.00280094, 0.00060058, 0.00179944, 0.00099964, 0.00079966, 0.00099916, 0.00100031, 0.00079999, 0.002 , 0.00080023, 0.00220037, 0.00119958, 0.00160012, 0.02939963, 0.00099955, 0.00119963, 0.00139995, 0.00100069, 0.00100017, 0.00140052, 0.00119977, 0.00099974, 0.00180006, 0.00100312, 0.00199976, 0.00220003, 0.00320096, 0.00240035, 0.001999 , 0.00319982, 0.00199995, 0.00299931, 0.00199928, ...好的,现在我们构建这个模型并检查它在测试数据集上的表现:
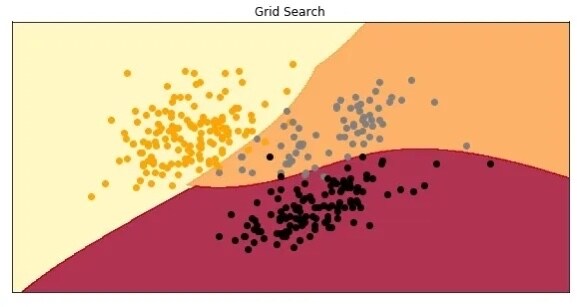
model = SVC(C=500, gamma = 0.1, kernel = 'rbf')model.fit(X_train, y_train)preditions = model.predict(X_test)print(f1_score(preditions, y_test, average='micro'))
0.9701492537313433结果很不错,我们的模型用建议的超参数获得了约 97%的精度。下面是绘制时模型的样子:
随机搜索超参数调优
网格搜索非常简单,但它的计算成本也很高。特别是在深度学习领域,训练可能需要大量时间。此外,某些超参数可能比其他超参数更重要。于是人们提出了随机搜索的想法,本文接下来会具体介绍。事实上,这项研究表明,随机搜索在做超参数优化时计算成本比网格搜索更有优势。这种技术也让我们可以更精确地发现重要超参数的理想值。
就像网格搜索一样,随机搜索会创建一个超参数值网格并选择随机组合来训练模型。这种方法可能会错过最佳组合,但是与网格搜索相比,它选择最佳结果的几率竟然是更高的,而且需要的时间只有网格搜索的一小部分。
随机搜索实现
我们看看它是怎样写成代码的。我们再次使用 Sci-KitLearn 库的 SVC 类,但这次我们使用 RandomSearchCV 类进行随机搜索优化。
hyperparameters = { "C": stats.uniform(500, 1500), "gamma": stats.uniform(0, 1), 'kernel': ('linear', 'rbf')}random = RandomizedSearchCV( estimator = SVC(), param_distributions = hyperparameters, n_iter = 100, cv = 3, random_state=42, n_jobs = -1)random.fit(X_train, y_train)请注意,我们对 C 和 gamma 使用了均匀分布。同样,我们可以打印出结果:
print(f'Best parameters: {random.best_params_}')print(f'Best score: {random.best_score_}')
Best parameters: {'C': 510.5994578295761, 'gamma': 0.023062425041415757, 'kernel': 'linear'}Best score: 0.9700374531835205可以看到我们的结果接近网格搜索,但并不一样。网格搜索的超参数 C 的值为 500,而随机搜索的值为 510.59。仅从这一点你就可以看到随机搜索的好处,因为我们不太可能将这个值放入网格搜索列表中。类似地,对于 gamma,我们的随机搜索结果为 0.23,而网格搜索为 0.1。真正令人惊讶的是随机搜索选择了线性 kernel 而不是 RBF,并且它获得了更高的 F1 分数。要打印所有结果,我们使用 cv_results_属性:
print(f'All results: {random.cv_results_}')
Allresults: {'mean_fit_time': array([0.00200065, 0.00233404, 0.00100454, 0.00233777, 0.00100009, 0.00033339, 0.00099715, 0.00132942, 0.00099921, 0.00066725, 0.00266568, 0.00233348, 0.00233301, 0.0006667 , 0.00233285, 0.00100001, 0.00099993, 0.00033331, 0.00166742, 0.00233364, 0.00199914, 0.00433286, 0.00399915, 0.00200049, 0.01033338, 0.00100342, 0.0029997 , 0.00166655, 0.00166726, 0.00133403, 0.00233293, 0.00133729, 0.00100009, 0.00066662, 0.00066646, ....我们来重复上面网格搜索的步骤:使用建议的超参数创建模型,检查测试数据集的分数并绘制模型。
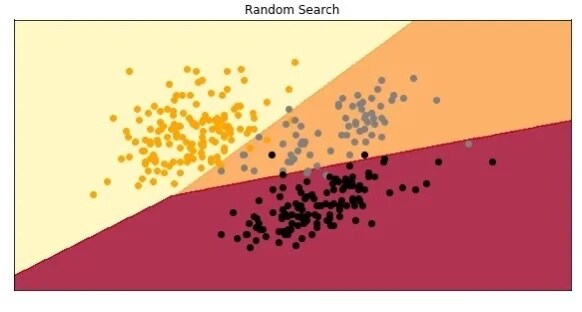
model = SVC(C=510.5994578295761, gamma = 0.023062425041415757, kernel = 'linear')model.fit(X_train, y_train)preditions = model.predict(X_test)print(f1_score(preditions, y_test, average='micro'))
0.9701492537313433哇,测试数据集上的 F1 分数与我们使用网格搜索时的分数完全相同。查看模型:
贝叶斯超参数优化
前两种算法有一点很棒,那就是使用各种超参数值的所有实验都可以并行运行。这可以为我们节省很多时间。然而这也是它们最大的缺陷所在。由于每个实验都是孤立运行的,我们不能在当前实验中使用来自过去实验的信息。有一个专门用于解决序列优化问题的领域——基于模型的序列优化(SMBO)。在该领域探索的那些算法会使用先前的实验和对损失函数的观察结果,然后基于它们来试图确定下一个最佳点。其中一种算法是贝叶斯优化。
这种算法就像来自 SMBO 组的其他算法一样,使用先前评估的点(在这里指的是超参数值,但我们可以推而广之)来计算损失函数的后验期望。该算法使用两个重要的数学概念——高斯过程和采集函数。由于高斯分布是在随机变量上完成的,因此高斯过程是其对函数的泛化。就像高斯分布有均值和协方差一样,高斯过程是用均值函数和协方差函数来描述的。
采集函数是我们用来评估当前损失值的函数。可以把它看作是损失函数的损失函数。它是损失函数的后验分布函数,描述了所有超参数值的效用。最流行的采集函数是 Expected Improvement(EI):
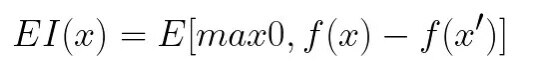
其中 f 是损失函数,x'是当前最优的超参数集。当我们把它们放在一起时,贝叶斯优化分 3 个步骤完成:
使用先前评估的损失函数点,使用高斯过程计算后验期望。
选择最大化 EI 的新点集
计算新选择点的损失函数
贝叶斯优化实现
将其带入代码的最简单方法是使用 Sci-Kit optimization 库,通常称为 skopt。按照我们在前面示例中使用的过程,我们可以执行以下操作:
hyperparameters = { "C": Real(1e-6, 1e+6, prior='log-uniform'), "gamma": Real(1e-6, 1e+1, prior='log-uniform'), "kernel": Categorical(['linear', 'rbf']),}bayesian = BayesSearchCV( estimator = SVC(), search_spaces = hyperparameters, n_iter = 100, cv = 5, random_state=42, n_jobs = -1)bayesian.fit(X_train, y_train)同样,我们为超参数集定义了字典。请注意,我们使用了 Sci-Kit 优化库中的 Real 和 Categorical 类。然后我们用和使用 GridSearchCV 或 RandomSearchCV 类相同的方式来使用 BayesSearchCV 类。训练完成后,我们可以打印出最好的结果:
print(f'Best parameters: {bayesian.best_params_}')print(f'Best score: {bayesian.best_score_}')
Best parameters: OrderedDict([('C', 3932.2516133086), ('gamma', 0.0011646737978730447), ('kernel', 'rbf')])Best score: 0.9625468164794008很有趣,不是吗?使用这种优化我们得到了完全不同的结果。损失比我们使用随机搜索时要高一些。我们甚至可以打印出所有结果:
print(f'All results: {bayesian.cv_results_}')
All results: defaultdict(<class 'list'>, {'split0_test_score': [0.9629629629629629, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.46296296296296297, 0.9444444444444444, 0.8703703703703703, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, 0.9444444444444444, .....使用这些超参数的模型在测试数据集上的表现如何?我们来了解一下:
model = SVC(C=3932.2516133086, gamma = 0.0011646737978730447, kernel = 'rbf')model.fit(X_train, y_train)preditions = model.predict(X_test)print(f1_score(preditions, y_test, average='micro'))
0.9850746268656716太有意思了。尽管我们在验证数据集上的结果要差一些,但我们在测试数据集上获得了更好的分数。下面是模型:
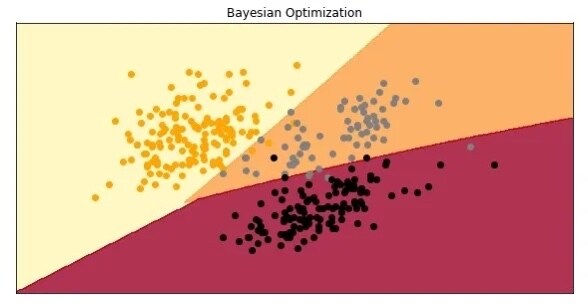
加点乐趣,我们可以把所有这些模型并排放置:

减半网格搜索和减半随机搜索
几个月前,Sci-Kit Learn 库引入了两个新类,HalvingGridSearchCV 和 HalvingRandomSearchCV。他们声称,这两个类“可以更快地找到一个理想参数组合”。这些类使用连续减半方法来搜索指定的参数值。该技术开始使用少量资源评估所有候选者,并使用越来越多的资源迭代地选择最佳候选者。
从减半网格搜索的角度来看,这意味着在第一次迭代中,所有候选者都将在少量训练数据上进行训练。下一次迭代将只包括在前一次迭代中表现最好的候选者,这些模型将获得更多资源,也就是更多的训练数据,然后再做评估。这个过程将继续,并且减半网格搜索将只保留前一次迭代中的最佳候选者,直到只剩最后一个为止。
整个过程由两个参数控制——min_samples 和 factor。第一个参数 min_samples 表示进程开始时的数据量。每次迭代时,该数据集将按 factor 定义的值增长。该过程类似于 HalvingRandomSearchCV。
减半网格搜索和减半随机搜索实现
这里的代码与前面的示例类似,我们只是使用了不同的类。我们先从 HalvingGridSearch 开始:
hyperparameters = { 'C': [0.1, 1, 100, 500, 1000], 'gamma': [0.0001, 0.001, 0.01, 0.005, 0.1, 1, 3, 5], 'kernel': ('linear', 'rbf')}grid = HalvingGridSearchCV( estimator=SVC(), param_grid=hyperparameters, cv=5, scoring='f1_micro', n_jobs=-1)grid.fit(X_train, y_train)有趣的是这段代码只运行了 0.7 秒。相比之下,使用 GridSearchCV 类的相同代码跑了 3.6 秒。前者的速度快得多,但结果有点不同:
print(f'Best parameters: {grid.best_params_}')print(f'Best score: {grid.best_score_}')
Best parameters: {'C': 500, 'gamma': 0.005, 'kernel': 'rbf'}Best score: 0.9529411764705882我们得到了相似的结果,但并不相同。如果我们使用这些值创建模型将获得以下精度和图:
model = SVC(C=500, gamma = 0.005, kernel = 'rbf')model.fit(X_train, y_train)preditions = model.predict(X_test)print(f1_score(preditions, y_test, average='micro'))
0.9850746268656716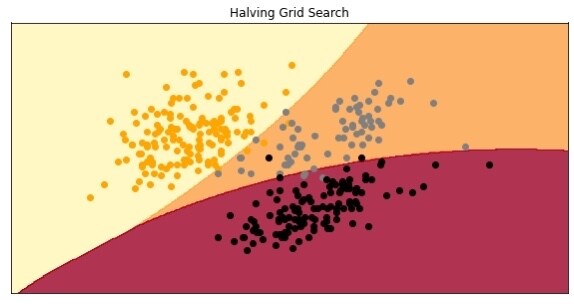
然后我们对减半随机搜索重复上述过程。有趣的是,使用这种方法我们得到了最奇怪的结果。我们可以说以这种方式创建的模型很难过拟合:
hyperparameters = { "C": stats.uniform(500, 1500), "gamma": stats.uniform(0, 1), 'kernel': ('linear', 'rbf')}random = HalvingRandomSearchCV( estimator = SVC(), param_distributions = hyperparameters, cv = 3, random_state=42, n_jobs = -1)random.fit(X_train, y_train)print(f'Best parameters: {random.best_params_}')print(f'Best score: {random.best_score_}')
Best parameters: {'C': 530.8767414437036, 'gamma': 0.9699098521619943, 'kernel': 'rbf'}Best score: 0.9506172839506174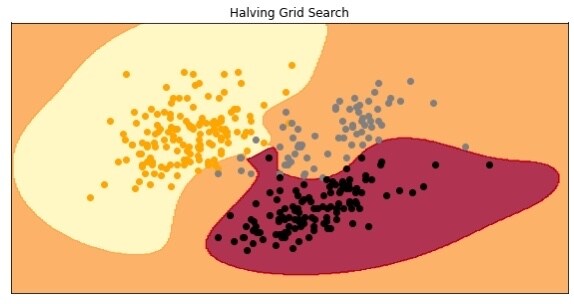
其他替代品
一般来说,前面描述的这些方法是最流行和最常用的。但是,如果上面介绍的方案不适合你,你还可以考虑多种替代方案。其中之一是基于梯度的超参数值优化。该技术会计算关于超参数的梯度,然后使用梯度下降算法对其进行优化。这种方法的问题在于,要让梯度下降过程正常运行,我们需要凸且平滑的函数,但超参数这个领域并不是总有这样的条件。另一种方法是使用进化算法进行优化。
小结
在本文中,我们介绍了几种众所周知的超参数优化和调整算法。我们学习了如何使用网格搜索、随机搜索和贝叶斯优化来获得超参数的最佳值。我们还学到了如何利用 Sci-KitLearn 类和方法在代码中做到这一点。
感谢阅读!
原文链接:https://rubikscode.net/2021/08/17/ml-optimization-pt-3-hyperparameter-optimization-with-python/




