
两天内,市场上就出现了两个 GPT-4 级别的开源模型,这意味着开源正在经历一个高光时刻。
Mistral 发布开源旗舰模型,参数更小但性能不打折
对于前沿人工智能模型领域来说,这两天可谓热闹非凡,AI 科技竞赛正在以前所未有的速度推进。
继 Meta 日前发布全新开源 Llama 3.1 并作为其领先闭源“前沿”模型的替代方案之后,法国 AI 初创公司 Mistral 也摩拳擦掌加入战团。这家初创公司宣布推出其旗舰级开源模型的下一代产品,此模型拥有 1230 亿个参数,代号为 Mistral Large 2,并声称在代码生成、数学和推理方面与 OpenAI 和 Meta 的最新尖端模型不相上下。
Mistral Large 2 的发布恰逢 Meta 发布其最新、最出色的开源模型 Llama 3.1 405B 的第二天。Mistral 表示,Large 2 提高了开源模型的性能和成本标准,这些优化在一些基准测试中已经体现出来。
需要特别强调的是,Mistral 的模型与大多数其他模型一样,不是传统意义上的开源模型——任何商业应用都需要付费许可。这套模型仅被授权为以“开放”方式用于非商业研究用途,包括开放权重并允许第三方根据自身喜好对其进行微调。对于那些寻求将其用于商业/企业级应用的人来说,他们将需要从 Mistral 获得单独的许可和使用协议。
早在今年 2 月,Mistral 就推出过具有 3.2 万个 token 上下文窗口的初版 Large 模型。当时该公司称这款产品“对于语法和文化背景有着细致入微的理解能力”,因此可以推理并生成不同语言(包括英语、法语、西班牙语、德语和意大利语)与母语水平相当的流利文本。
新版模型在此基础之上将上下文窗口增加至 12.8 万个 token,与 OpenAI 的 GPT-4o 和 GPT-4o mini 以及 Meta 的 Llama 3.1 旗鼓相当。
新模型还支持数十种新语言,包括初版已经支持的语言外加葡萄牙语、阿拉伯语、印地语、俄语、汉语、日语和韩语。
Mistral 方面表示,这套通用模型非常适合需要强大推理能力或者高度专业化的任务,例如合成文本生成、代码生成以及 RAG(检索增强生成)等。
两大最新开源模型 PK,谁能更胜一筹?
Mistral 在一份新闻稿中表示,Large 2 训练过程中重点关注点之一是尽量减少模型的幻觉问题。Mistral 公司表示,Large 2 经过训练后,能够更敏锐地做出反应,能够意识到自己不知道的事情,而不是编造看似合理的事情。此外,Mistral 还声称 Large 2 的响应也比领先的 AI 模型更简洁,而领先的 AI 模型往往会喋喋不休。
那么,Large 2 与同样强大的 Llama 3.1 相比,在编码能力、推理能力、指令遵循与对齐、语言多样性方面谁高谁低?
编码能力
初版 Large 模型在编码任务方面表现不佳,Mistral 似乎在最新版本中专门利用大量代码进行了训练,最终成功纠正了这个问题。
Mistral 表示,根据他们在代码模型 Codestral 22B 和 Codestral Mamba 上积累的经验,他们在很大一部分代码上训练了 Mistral Large 2。Mistral Large 2 的表现远远优于之前的 Mistral Large,并且与 GPT-4o、Claude 3 Opus 和 Llama 3 405B 等领先模型相当。
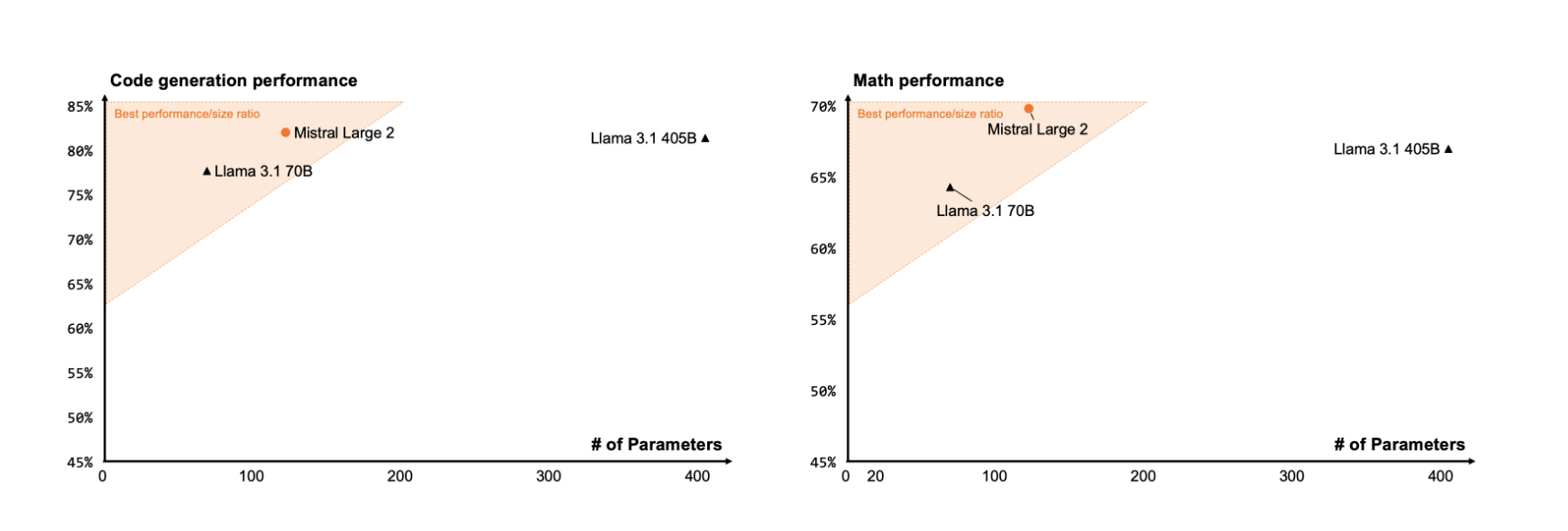
推理能力
Mistral 还投入了大量精力来增强模型的推理能力。训练期间的重点关注领域之一是尽量减少模型产生“幻觉”或产生看似合理但实际上不正确或不相关的信息的倾向。这是通过微调模型来实现的,使其在响应时更加谨慎和敏锐,确保它提供可靠和准确的输出。
此外,新款 Mistral Large 2 经过训练,能够在无法找到解决方案或没有足够的信息来提供自信答案时识别。这种对准确性的承诺体现在流行数学基准测试中模型性能的提高,展示了其增强的推理和解决问题的能力:

代码生成基准上的性能准确性(所有模型都通过相同的评估流程进行基准测试)
基准测试与 Llama 3.1 405B:
MMLU:84.0% (Mistral Large 2) vs 88.6% (Llama 3.1 405B)
HumanEval: 92% (Mistral Large 2) vs 89% (Llama 3.1 405B)
GSM8K: 93% (Mistral Large 2) vs 96.8% (Llama 3.1 405B)
在 HumanEval 和 HumanEval Plus 代码生成基准测试当中,其表现优于 Claude 3.5 Sonnet 与 Claude 3 Opus,仅次于 GPT-4o。同样的,在以数学为重点的基准测试(GSM8K 与 Math Instruct)当中,其成绩也移居第二。
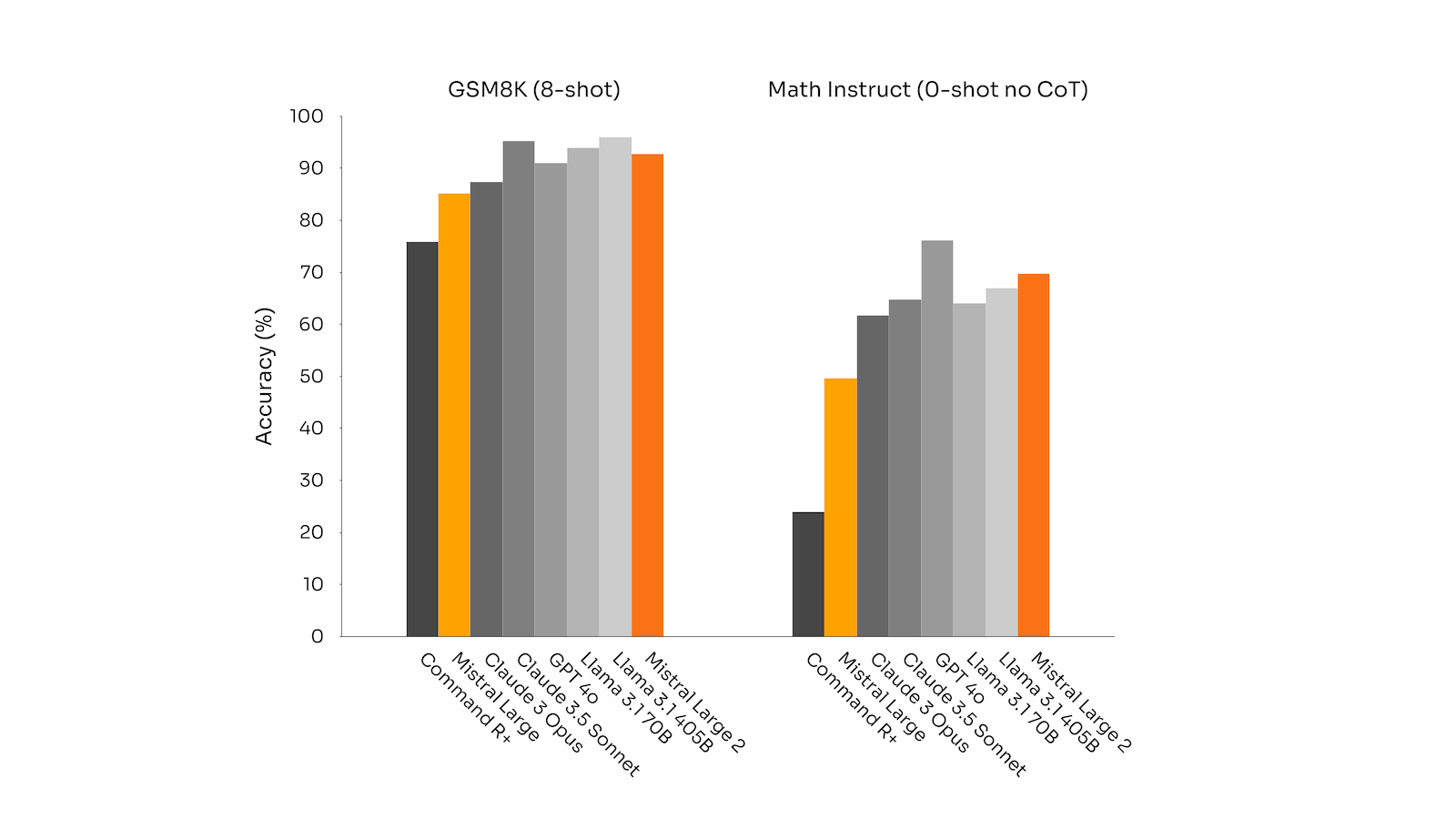
GSM8K(8 次)和 MATH(0 次,无 CoT)生成基准上的性能准确度(所有模型都通过相同的评估流程进行基准测试)
多语言能力
在涵盖不同语言的多语种 MMLU 基准测试当中,Mistral Large 2 的表现与 Meta 全新的 Llama 3.1-405B 相当,而且由于体量较小,所以有着更加显著的成本效益。
Large 2 支持 80 多种编码语言,包括 Python、Java、C、C++、JavaScript 和 Bash。该公司在博文中解释称,“Mistral Large 2 专为单节点推理而设计,而且照顾到长上下文类应用场景——其 1230 亿参数的规模使其能够在单个节点以大吞吐量方式运行。”

MultiPL-E 上的性能准确度(除“论文”行外,所有模型都通过相同的评估流程进行基准测试)

Mistral Large 2 模型在多语言 MMLU 中的表现
指令遵循与对齐
随着企业越来越地采用 AI 技术,Mistral 还专注于减少 Mistral Large 模型的幻觉。具体方法就是微调模型,使其在响应时更加谨慎且有选择性。如果没有足够的信息来支持答案,它也会直接告知用户以保持完全透明。
此外,该公司还改进了模型的指令遵循能力,使其能够更好地听众用户指引并处理长时间内的多轮对话。新模型还经过调优以尽量让答案保持简洁明了——这一点在企业环境下同样非常重要。
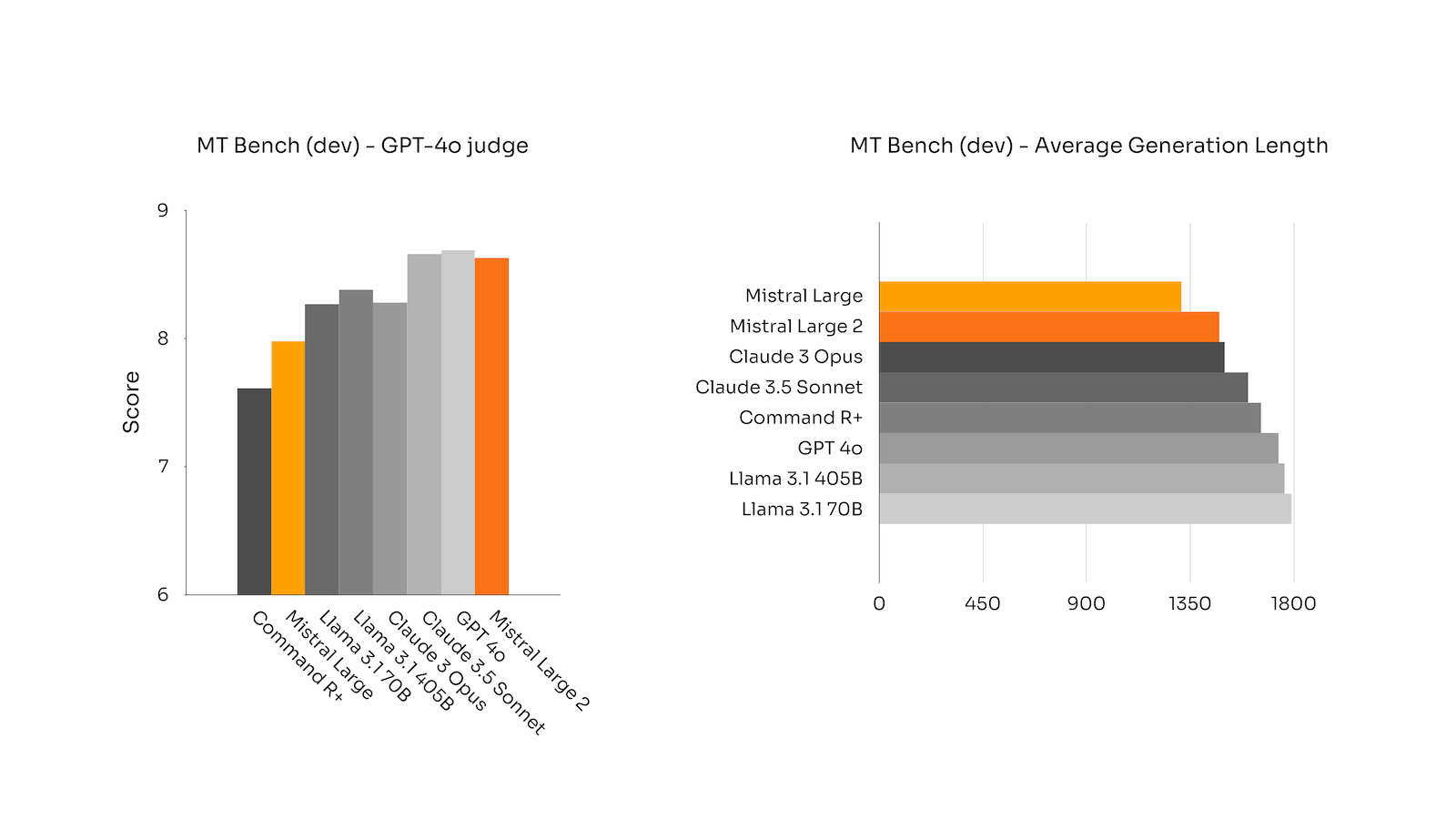
新款 Mistral Large 2 在遵循精确指令和处理长时间多轮对话方面表现尤为出色。下面是 Mistral Large 2 在 MT-Bench、Wild Bench 和 Arena Hard 基准测试中的表现:

在一般对齐基准上的表现(所有模型都通过相同的评估流程进行基准测试)
在某些基准测试中,生成较长的响应往往会提高分数。然而,在许多商业应用中,简洁性至关重要——较短的模型生成有助于加快交互速度,并且推理更具成本效益。这就是为什么 Mistral 花费了大量精力确保生成尽可能简洁明了。下图报告了 MT Bench 基准测试中不同模型生成的平均长度:
目前,Mistral 公司已经通过其 API 商战平台以及 Google Vertex AI、Amazon Bedrock、Azure AI Studio 以及 IBM WatsonX 等云平台开放 Mistral Large 2 模型访问。用户甚至可以通过 Mistral 的聊天机器人对新模型进行测试,看看它在现实场景下究竟表现如何。
经过多方面对比,最终得出的结论是:在代码能力数学基础测试中,Mistral Large 2 的性能要优于 Llama 3.1 405B,语言多样性方面的基准测试中,Mistral Large 2 表现略逊于 Llama 3.1 405B,在推理方面和指令遵循与对齐方面,Mistral Large 2 与 Llama 3.1 405B 的表现不相上下。
Mistral 方面指出,该产品将继续“突破成本效率、速度与性能的极限”,同时为用户提供更多新功能,包括高级函数调用与检索,用以构建起更多高性能 AI 应用程序。
网友怎么看?
两天之内,两家大模型明星公司纷纷推出高端大模型的做法引发业内热议。
有网友评论,Large 2 虽然不是完全开源有些令人沮丧,但仍然比完全关闭要好得多。
我认为 Large 2 的发布有两大很重要的进步: 第一是幻觉的减少;第二是略大于 100B 是一个不错的规模,因为它显示了 LLama 3.1 的收益递减(这里概括为数据不同,但它显示了趋势)。在我看来,这些研究发布将始终有助于改进其他开源模型。
仅在 Meta 发布模型的隔天就推出自家模型,Mistral 难免被人猜测是想蹭科技巨头的热度。但也有网友为 Mistral 辩护称:
“Mistral 绝非想借 Large 2 模型蹭 Meta 或者 OpenAI 掀起的这波 AI 热度。相反,Mistral 一直在技术领域积极行动、筹集资金,并在发布各种任务特定模型(包括编码与数学模型)之余,与行业巨头合作以扩大自身影响力。”
网友 Drew Breunig 强调了目前一个有趣的模式:最好的模型都在向 GPT-4 类能力靠拢,同时在速度和价格上展开竞争——变得更小更快,这适用于专有模型和公开许可模型。
我们都在将模型变得更小、更便宜、更快、更简洁。当 GPT-5 类模型开始出现时,我们是否会看到能力的大幅飞跃?很难得到肯定的答案。
参考链接:
https://techcrunch.com/2024/07/24/mistral-releases-large-2-meta-openai-ai-models/
https://venturebeat.com/ai/mistral-shocks-with-new-open-model-mistral-large-2-taking-on-llama-3-1/




