
刚刚,阿里 Qwen 团队发布了最新的 QwQ-32B 推理模型。其参数规模为 320 亿,但在推理能力上可媲美 DeepSeek-R1——后者总参数量高达 6710 亿,其中激活参数为 370 亿。
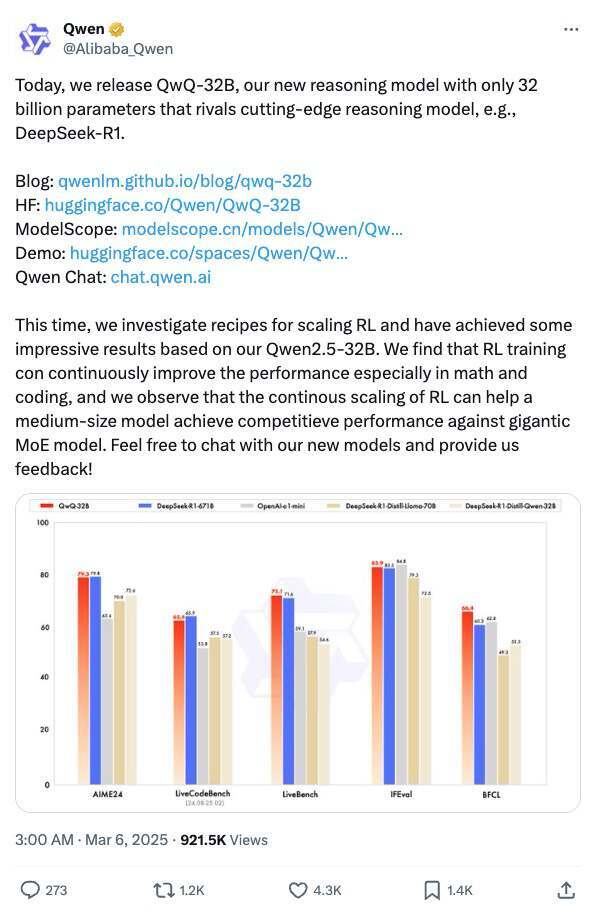
阿里 Qwen 团队近日对 QwQ-32B 进行了一系列基准测试,全面评估其在数学推理、代码生成及一般问题解决能力方面的表现。测试结果显示,QwQ-32B 在多个关键指标上展现出强劲竞争力,并与当前领先的多个模型——包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始 DeepSeek-R1——进行了对比分析。
Hugging Face 和 ModelScope 的介绍页面显示,QwQ-32B 是一个密集模型,未采用 MoE 结构,并支持 131k 的上下文长度。
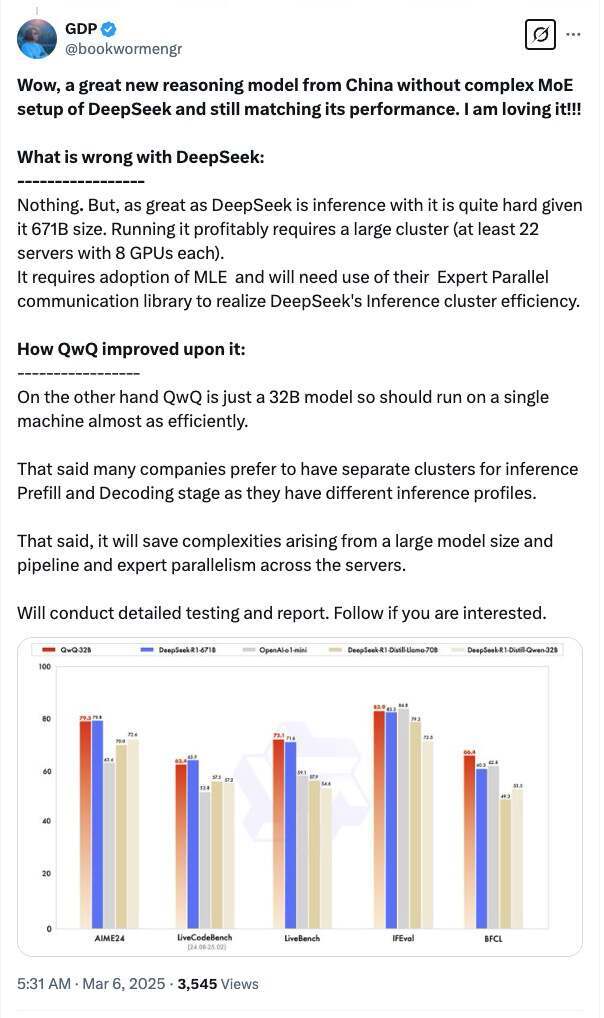
有网友分析指出,由于 DeepSeek 模型规模高达 6710 亿参数,推理部署难度较大。要高效运行 DeepSeek,至少需要 22 台服务器,每台配备 8 张 GPU,这对企业来说是一个不小的成本和运维挑战。相比之下,QwQ-32B 仅有 320 亿参数,意味着它几乎可以在单机上高效运行,大大降低了推理部署的门槛。
“当然,许多企业在推理部署时会将预填充(Prefill)和解码(Decoding)阶段分开运行,因为它们的推理需求不同。但无论如何,QwQ-32B 避免了超大规模模型带来的复杂管道调度和专家并行(Expert Parallelism),简化了推理部署流程。”
还有网友调侃道:“关键问题是,Qwen QwQ-32B 能‘做空’英伟达(NVIDIA)吗?”
据阿里 Qwen 团队介绍,这是他们探索了强化学习(RL)扩展的成果,RL 训练可持续提升模型性能,特别是在数学和代码生成方面。同时,他们观察到,持续优化 RL 训练能使中等规模模型在性能上媲美超大规模 MoE 模型。
此外,QwQ-32B 还集成了智能体相关能力,能够在使用工具的同时,根据环境反馈动态调整推理过程,使推理更具批判性与适应性。这一技术进展不仅进一步验证了 RL 的变革潜力,也为通用人工智能(AGI)的发展提供了新的思路。
QwQ-32B 以 Apache 2.0 许可证开源,用户可通过 Qwen Chat 直接进行体验。




