
本文是数据库内核系列文章之一。
本文我们将和大家一起深入学习 code-gen,基于 Thomas Neumann 的论文:Efficiently Compiling Efficient Query Plans for Modern Hardware。
Volcano 模式的不足
稍稍复习一下传统的 Volcano(火山模型)执行模式:优化器会生成由物理算子构成的物理执行计划;执行计划呈树状结构,上层的算子通过 pull 模式拉去数据:调用下层算子的 next 方法获取下一个 tuple。Volcalno 模式的优势在于,容易理解,非常通用,并且容易实现。但是,通用性却带来了性能的损失,仅从 next 方法的调用来看,首先,由于通用性,会牵涉到 dynamic binding,其次是方法调用本身会造成开销。并且,每一个算子在处理每一个 tuple 都需要调用 next 方法。试想一个复杂的查询语句由 20 个算子构成,处理大约 10Million 个数据。光调用 next 方法就有约 200Million 次。其次,由于数据是一个 tuple 一个 tuple 处理,数据的 locality 不好,即,要被处理的数据在内存中可能并不是挨得很近,这使得 CPU 寄存器使用效率降低(因为需要不断地将待处理的数据换入和换出寄存器),导致性能降低。
手写代码的洞见
本文引用了 MonetDB/X100 的另一篇文章(MonetDB/X100 - a DBMS in the CPU cache)中的一个观点:给定一个 SQL 语句,如果让一个技术精湛的程序员(比如 Jeff Dean),手写一段代码来实现这个语句,那一定能得到比 Volcano 模型更好的性能。仔细想想,这个观点很容易被证实。首先,因为已经了解了所有的 SQL 查询算子,完全可以把所有的算子放在一个方法中实现。这样,就完全避免了方法调用,因此减少了不计其数的 next 方法调用。其次,因为完全不需要兼顾数据和代码通用性,可以通过直接访问内存来访问和操纵数据。抛开其他的优化方式,仅上述提到的两种优化,就能明显地提高执行语句的性能。MonetDB 文中一个给出了了一个比较数据,参见下图。
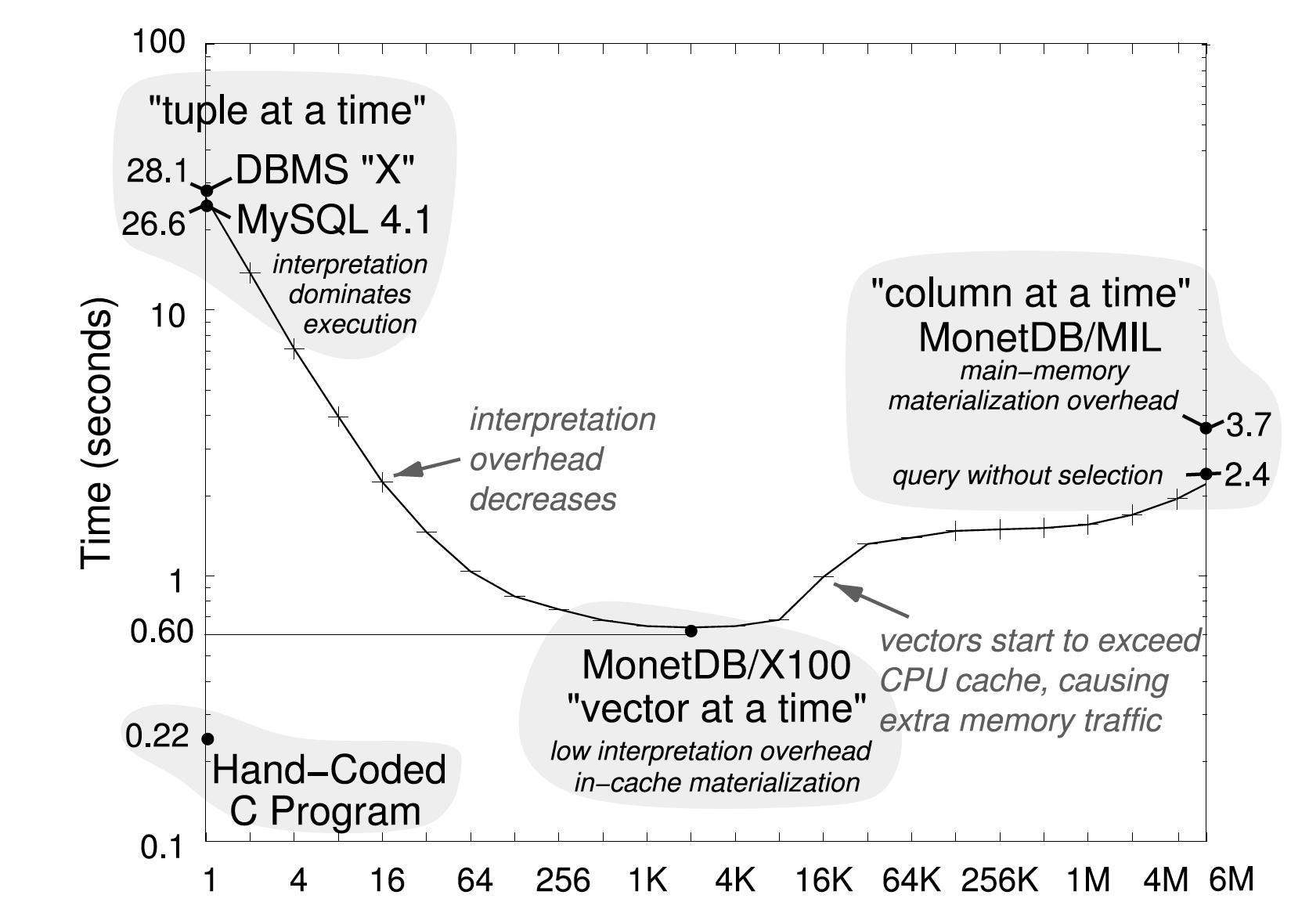
基于上述的洞见,本文提出了一个新的执行模式和优化方法:给定一个 SQL 语句,除了生成优化后的执行计划,更进一步,生成执行计划的机器代码。这个机器代码只服务于执行这一个语句,完全不用考虑各种通用和兼容性。虽然,生成的代码可能不能真正达到 Jeaf Dean 的水准,但是完全可以通过一些优化方式来逼近最佳性能。
如何定义最佳性能呢?因为程序最终都是由 CPU 执行,本文定义的优化函数是,尽可能地减少 CPU instructions。如何才能减少 CPU instruction 呢?文章给出的答案是,以数据为中心来执行 SQL 语句,而不是算子。这句话听起来有点玄学,但本质很简单,要尽最大可能,使被处理的数据,保存在 CPU 寄存器中。如此,减少了把数据换入和换出寄存器的无用操作,最终达到减少 CPU instructions 的目的。
新的执行模式
本文提出的执行模式是最大化以数据为中心来处理执行逻辑。
首先,文章定义了一个新的概念来辅助介绍这种执行模式,pipeline-breaker。Pipeline-breaker 的定义是,在执行语句中的某一个算子,如果它的执行逻辑需要把一个待处理的 tuple 从 CPU 寄存器中去除,那这个算子就被定义成一个 pipeline-breaker。如果一个算子需要等待子算子把所有的 tuple 都送给它,才能处理数据,那这个算子就被定义成 full-pipeline-breaker。(当然,实际情况中,可能某个 tuple 已经大到 CPU 寄存器无法存下,文章这边做了个小假设, 假设有足够的寄存器)。
有了这个定义后,下一个问题就是,如何才能一直将数据放在寄存器中呢?上面介绍的传统火山模型显然是做不到这一点:因为火山模型算子之间通过方法调用来传递 tuple,方法调用牵涉到方法栈的更新,数据早就被移出寄存器了。本文提到的方法就是,通过不断地把数据 push 给下一个要处理的算子,直到遇到 pipeline-breaker。但这个解释不直观。我的理解就是,对于某一个 tuple 数据,把要对其进行处理的算子(直到遇到 pipeline-breaker)排成队,依次对数据进行操作,在这个 pipeline 处理过程中,数据始终是存放在 CPU 寄存器中,因此,执行一个 pipeline 是非常高效的。而根据 pipeline-breaker,一个执行计划就会被 pipeline-breaker 算子分解成几个 pipeline,数据在这个维度下,总是从一个 pipeline,被处理完,进入另一个 pipeline。
通过一个例子,更直观地来了解一下整个过程。给定下面这个 SQL 语句:
一个 join 查询内部夹带一个子查询语句。

正常生成的执行计划如下图所示:
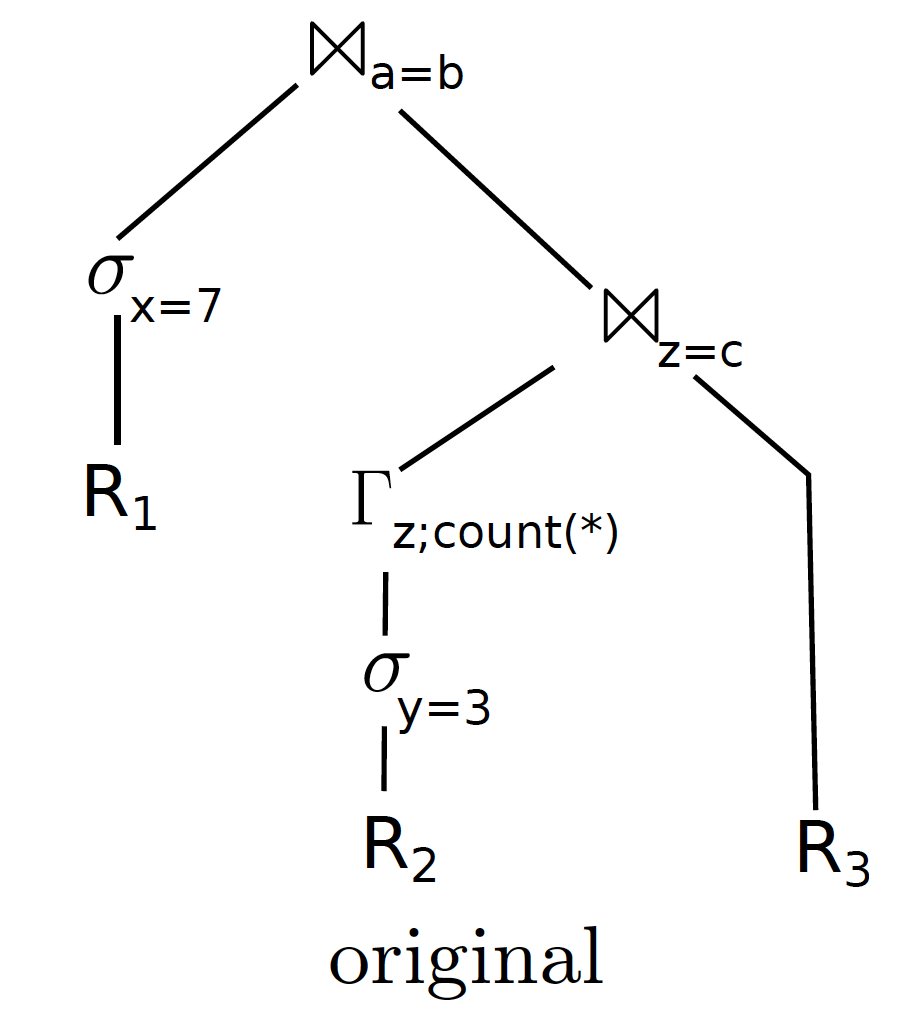
先对 R2 进行扫描,filter,然后对 R2.z 做 group by count(*)计算,得到一个临时的表;然后和 R3 进行 join,最后再和处理过的 R1 的 tuple 进行 join。
而根据 pipeline-breaker 的定义,图中的 GroupBy 算子和 Join 算子就是 pipeline-breaker。因为它们都需要得到子算子的所有 tuple,才可以执行:GroupBy 算子需要得到所有的结果才可以对 Z 进行 count 聚合操作,而 Join 算子,则需要把左侧结果生成 hash 表来做 hashJoin。根据先前的定义,这个执行计划被分解成 4 个 pipeline。如下图所示:
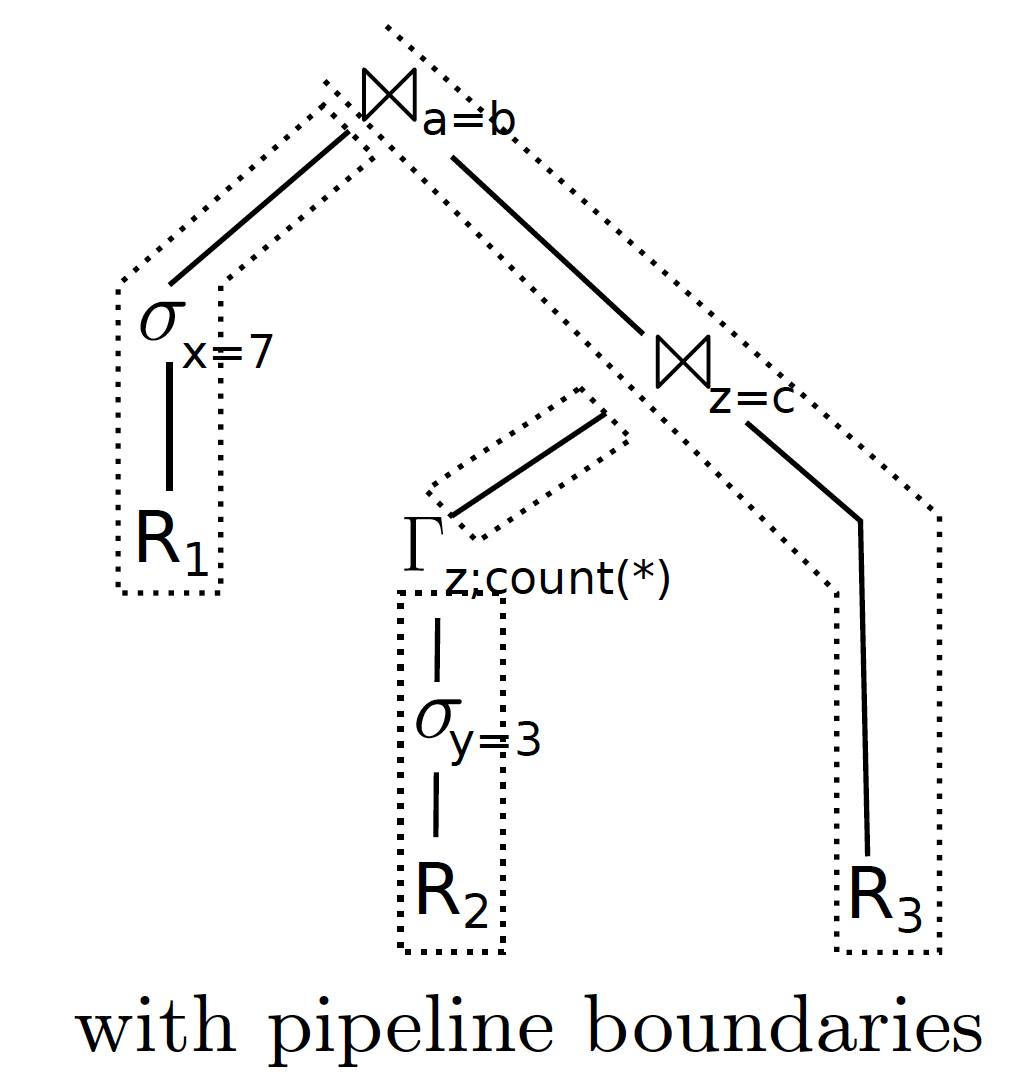
而每个 pipeline 在执行的过程中,是可以最大化将数据保存在 CPU 寄存器中的。根据这个结果,就可以生成出下面的执行语句代码:

可见,每个 pipeline 对应一个最外层的 for 循环,总共有 4 个外层 for 循环,最后一个三层 for 循环嵌套就是对两个 join 的执行。在执行每一层 for 循环的时候,都可以通过代码优化,尽可能地将数据保留在 CPU 寄存器中。
文中还介绍了一种新的 algebra 来描述对算子的改造,并且示例讲解,如何根据新定义的 algebra,把一个执行计划拆分成多个 pipeline,然后生成出伪代码。我觉得有点抽象,就不在这深入讲解了,有兴趣的同学可以去参考原文。
code-gen 代码生成
刚才的示例展现了拆分成 4 个 pipeline 后的 4 段 for 循环的伪代码,现在来讨论如何来生成计算机能看懂的机器代码。作者提到,一开始想直接让优化器,优化 SQL 语句后生成出 C++代码(类似上面的 for 循环伪代码),然后编译成机器码,但在实验的过程中发现了弊端,最重要的问题就是生成优化的 C++代码的这个过程非常耗时,时间消耗以秒计算,这个性能是无法接受的。
最终通过实验,决定直接使用 LLVM,将语句生成 LLVM 的汇编代码,然后用 LLVM 自带的 JIT 编译器来运行生成机器代码。文中提到 LLVM 的好处如下:1)生成的汇编代码质量很高,会尽可能提高 CPU 寄存器的使用率,并且,LLVM 汇编代码是可 portable 的,可以通过不同平台的 LLVM 的 JIT 编译器最终生成机器码。2)LLVM 的汇编代码是强类型的(我也不太清楚好处在哪,可能强类型在运行时就性能更好)。3)LLVM 已经被广泛使用在工业界,质量有保证,而且,不断在进步。4)编译时间短,是以毫秒计算。
但是,文中指出,也并不是把整个 SQL 语句,一股脑地全部编译成 LLVM 代码,最重要的原因就是,实现工程量太大了。文中指出,其实一个 C++执行引擎代码都在那里,并不需要把所有的代码都重新用 LLCVM 汇编,而且 LLVM 汇编代码的好处在于,和 C++代码,双向之间可以无缝调用。一些复杂的逻辑和复杂的算子可以用 C++的现有实现,比如复杂数据结构的 access,包括需要把数据暂存到文件中等等的逻辑。LLVM 相当于把这些 C++代码根据具体的执行语句,动态地把这些预编译的 C++代码结合起来,生成一个完整的执行计划的汇编代码。对于热点代码(某些 code 会被几乎全部的 tuple 都运行的代码),可以完全由 LLVM 生成汇编代码来提高性能。LLVM 和 C++代码的嵌合,文章给出了示意图。
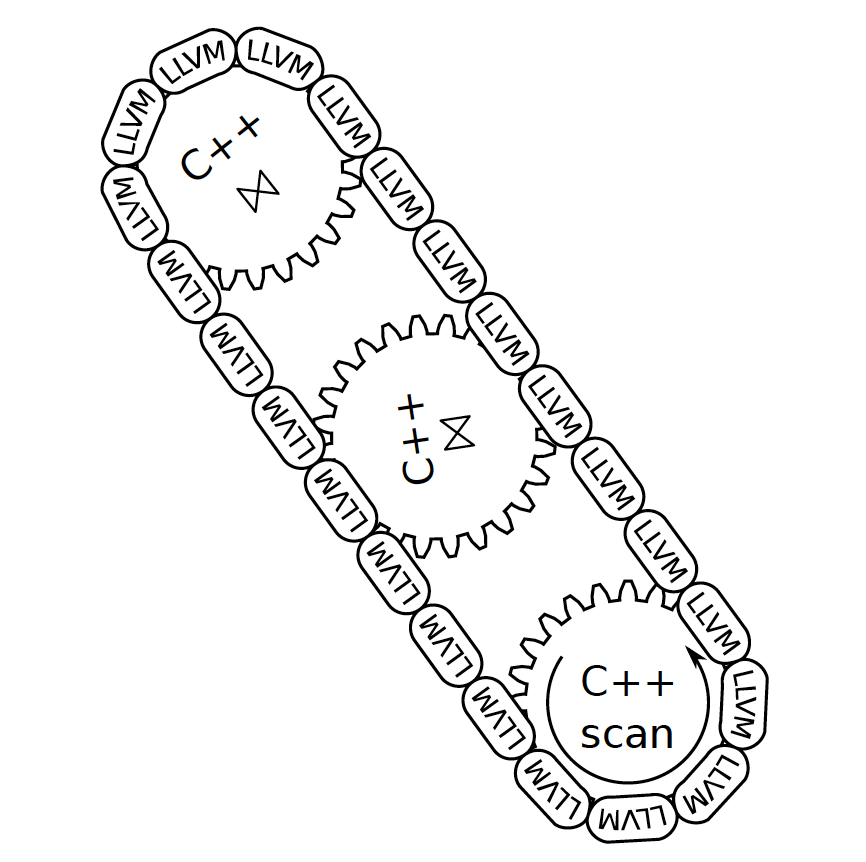
另外,在测试中,由于会遇到复杂的算子,很难完全生成一个完整的方法来执行语句的所有逻辑,因此可以在 LLVM 汇编代码中调用现成的 C++代码来执行。
文中还介绍了用 SIMD 来进一步提升性能的高级优化方法。因为在 for 循环中,如果 block 如果过大,对 CPU 寄存器不友好,就会影响性能。可以通过减少数据 block 的大小,让所有的数据还是能存放在寄存器内,然后通过 SIMD instructions 来提升速度。除了 SIMD,还可以利用 multi-core processing,主要就是把要处理的数据分成多分,然后通过多 CPU 并行处理来提高性能。回顾上面介绍的例子中,不同的 pipeline 可以并行处理,比如处理 R1 的 pipeline 和 R2 的 pipeline,可以并行处理。
文章在最后对这项技术进行了一些测试,测试结果结果肯定显而易见,

从图上很容易得出:
1)C++代码的编译时间远高于 LLVM 编译。
2)即使算上代码的编译时间,LLVM 编译加执行的性能也是最高的。
3)Vec-exec 的性能也不错。
4)这两种技术都远优于传统的数据库执行引擎。
总结
这篇文章,通过对 Thomas Neumann 的文章 Efficiently Compiling Efficient Query Plans for Modern Hardware 进行解读,深入了解了 code-gen 是如何提高性能的。文章通过定义 pipeline-breaker 的算子,将一个执行计划分成多个 pipeline,不同的 pipeline(如果没有依赖关系)可以并行执行;并且,每个 pipeline 都可以尽可能地优化来将数据始终保存在 CPU 寄存器中来提升性能。文章还验证了使用 LLVM 编译代码的可行性,并且认为比 C++代码生成要更优秀。在商用的数据库系统中,除了上次介绍的 Snowflake,也有使用 code-gen 来提升执行性能的。GreenPlum GPDB 的这篇博客介绍了如何通过 code-gen 来提升性能,贴在这里作为参考,有兴趣的同学可以继续阅读。
感谢阅读这一期杂谈!2021 年的愿景之一是做更多对于技术和管理的输出,如果想要和我更多交流,欢迎关注我的知识星球:Dr.ZZZ 聊技术和管理。




