
2015 年,Facebook 推出了 GraphQL(Graph-Query-Language)查询语言。到目前为止,IBM、Twitter、Walmart Labs、纽约时报、Coursera 等很多公司已经在内部从 RESTful 转向 GraphQL API。
作为一种查询语言,GraphQL 具有以下特点:
(1)无需关心如何更新文档,所有的查询(query)和变更会自动形成文档(cchema)。
(2)无需获取整个数据集,通过 schema 与 resolver(处理器)之间的映射关系,由对应的 resolver 去获取数据,将结果返回给前端,从而可以编写仅仅返回所请求数据的查询。
(3)对前端提供统一的访问点。从不同的 API 中获取数据并非易事,GraphQL 支持将所有 API 进行拼接。
爱奇艺号技术团队在实施微服务化的过程中,受到 Forrester Research 提出的低代码开发(Low-Code:即无需编码或通过少量代码就可以快速生成应用程序的开发理念)的启发,基于 GraphQL 构建 BFF(Backend for Frontends),帮助开发人员用拖拽式操作,直观地创建出一个供前端调用的 API,本文将对实施过程中的经验总结进行叙述。
GraphQL 介绍
与 RESTful API 一样,GraphQL API 设计用于处理 HTTP 请求并为这些请求提供响应。REST API 构建在请求方法和端点之间的连接上,而 GraphQL API 被设计为只通过一个端点,始终使用 POST 请求进行查询,其 URL 通常是 xxx.com/graphql。图 1-1 为 GraphQL 部署架构图,可以看到它处于系统“中间层”。
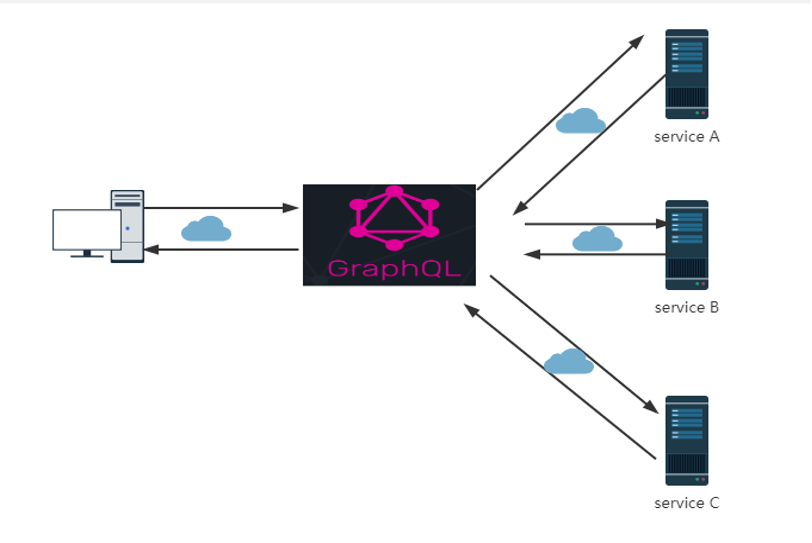
图 1-1
GraphQL 全称叫 Graph Query Language,官方宣传语是“为你的 API 量身定制的查询语言”,用传统的方式来解释就是:将你所有后端 API 组成的集合看成一个数据库,用户终端发送一个查询语句,你的 GraphQL 服务解析这条语句并通过一系列规则从你的“API 数据库”里面将查询的数据结果返回给终端,而 GraphQL 就相当于这个系统的一个查询语言,像 SQL 之于 MySQL 一样。GraphQL 执行过程如图 1-2 所示:
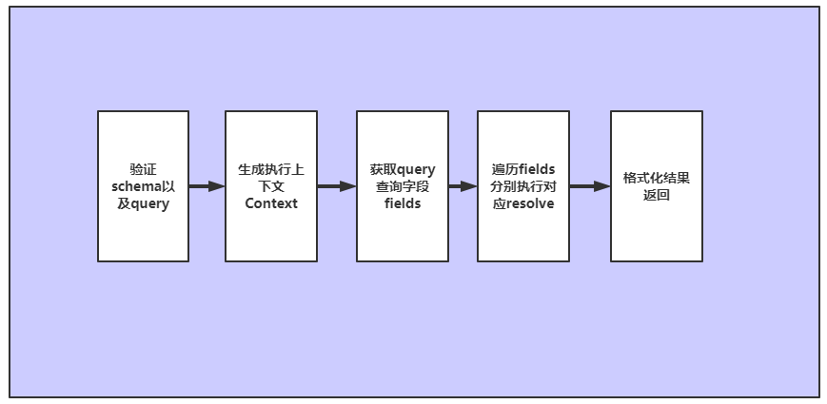
图 1-2
图 1-2 是 GraphQL 执行的大致流程,第一步去验证查询语句是否符合 GraphQL 的 schema 规范,确认查询内容的合法性,第二步生成执行的上下文,关键点在第三步和第四步,第三步是获取查询语句所需要查询的字段,这里叫 fields,所有需要查询的字段可以在查询语句里拿到,这就是 GraphQL 如何做到避免返回冗余数据的。拿到所有需要查询的字段后,第四步针对每一个字段去执行它的 resolver,可以从 resolver 返回的数据里面拿到字段对应的数据,最后是格式化结果并返回。
重点是第四步,展开说明一下,如图 1-3、图 1-4 所示:
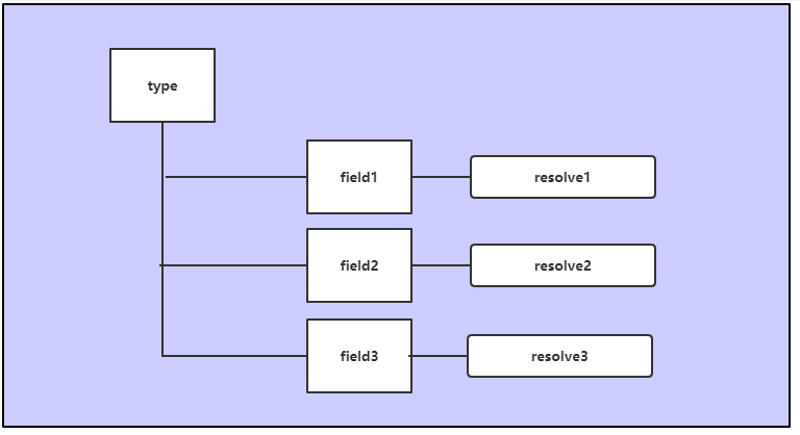
图 1-3
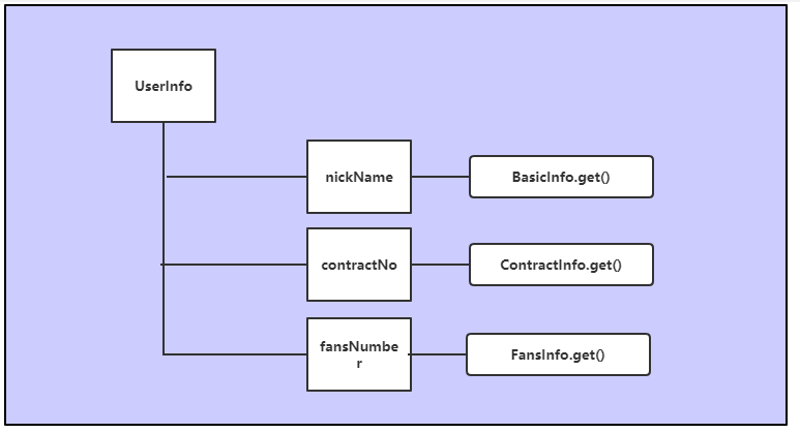
图 1-4
在 GraphQL 里面有一个概念叫类型 (type),每一个类型下面对应的是一个或多个字段(field),每个字段都会绑定一个处理器(resolver),这个 resolver 的作用就是获取字段对应的数据。
对应到图 1-4 所示,UserInfo 这个类型,它有三个字段:nickName、contractNo、fansNumber。每个字段都对应一个 resolver,resolver 需要被开发者重新定义,否则会报错。所以 UserInfo 下的三个字段 nickName、contractNo、fansNumber 需要通过实现各自 resolver 来分别从用户微服务、合同微服务、粉丝微服务去获取用户信息、合同信息和粉丝信息,然后再聚合返回,这样就达到了使用 GraphQL 进行数据拼接的目的。
BFF 架构
爱奇艺号在实施微服务化的过程中,加入了 BFF 的前后端架构,如图 2-1 所示:
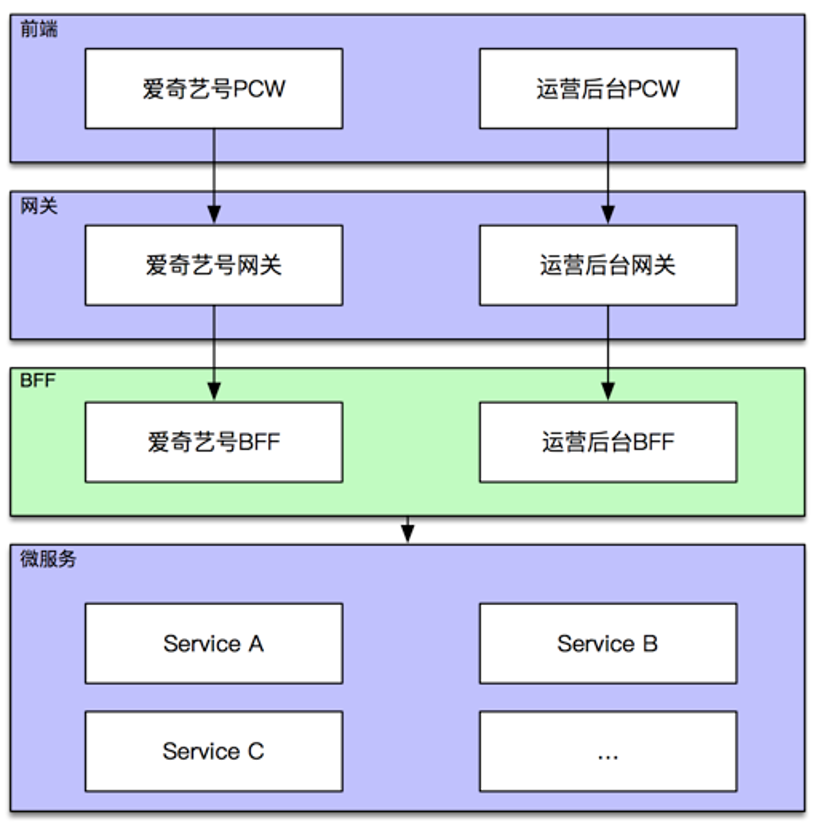
图 2-1
从图中可以看出,BFF 作为前后端的中间层服务。主要的业务逻辑都封装在 BFF 层,前端通过 BFF 进行访问,减少微服务之间的相互调用。BFF 层通过 REST API 方式提供服务,随着服务的增多,提供的接口越来越多,这会导致 REST API 越来越冗余。对于前端而言,有的 API 粒度较粗不满足需求;有的 API 又粒度太细,不仅增加了响应时间,还会造成流量的浪费。对于后端而言,前端需要的数据往往在不同的地方具有相似性,但却又不尽相同,比如:针对用户信息,有些地方需要用户简要的基础信息和详细的视频信息,而有些地方却需要用户详细的基础信息和简要的视频信息。这往往需要开发不同的接口去满足各种定制需求,增加了开发人员的工作量,提升了开发工作的重复度。
GraphQL 与 Rest API 对比:
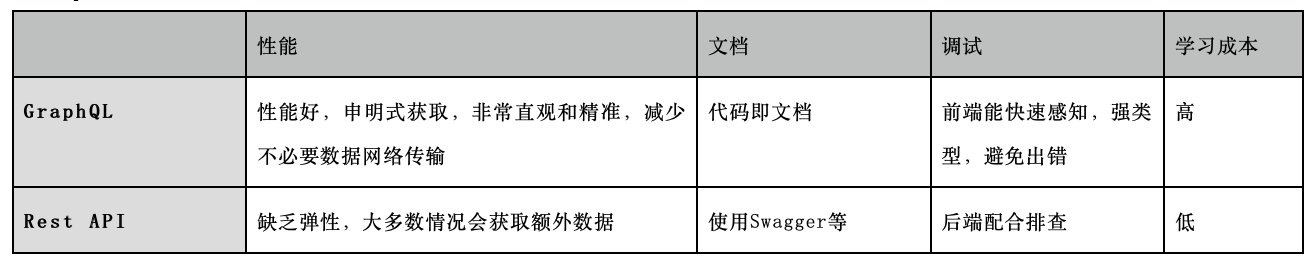
表 2-1
从表 2-1 中的对比可以看出,GraphQL 相对于 Rest API 方式,性能更好,能有效减少前后端开发沟通成本。但是 Facebook 的官方只有 JS 版本实现,查询方式和 Rest API 也有所不同(如表 2-2 所示),对于老项目有一定的迁移、学习成本。

表 2-2
接下来,本文将主要探讨如何基于 graphql-java,做到减少迁移成本的同时,又能提升后端开发人员的效率,避免重复开发。
爱奇艺号 API 生成平台实践
爱奇艺号 API 生成平台,是一个低代码平台。由于爱奇艺号的技术栈主要基于 Java,所以使用的是 GraphQL 的 Java 实现。基于 graphql-java,API 生成平台主要做了以下功能优化及增强。
(1)支持 Rest API:降低前端接入成本。
(2)动态接入监控:动态生成的 API,与其他普通接口一样支持 Prometheus 监控,保证监控的灵活性和服务的稳定性。
(3)灵活配置:可以动态生成 GraphQL 的 schema,方便后端接入新服务。
(4)可视化 API 管理平台:API 接口提供可视化操作,方便查看、新增、修改和重用。
接下来将对以上功能进行详细介绍:
1.支持 Rest API
graphql-java 通过 Spring 的封装,位于整个架构的网关层或 BFF 层。项目 user-info-graphQL 依赖 graphql-java-spring,支持 Rest API 请求。平台的整体架构图如图 3-1 所示:
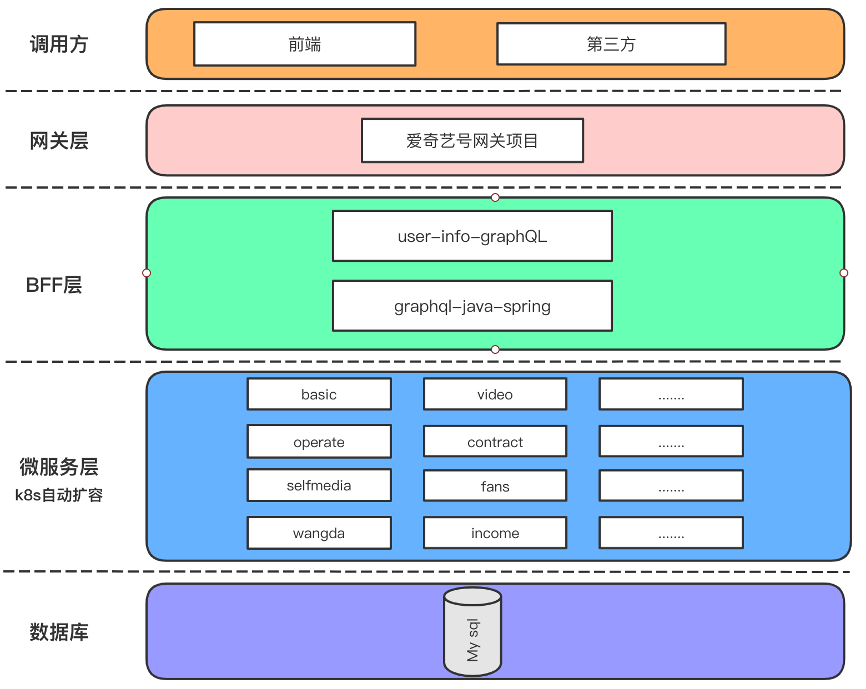
图 3-1
User-info-graphQL 的服务流程图如图 3-2 所示。客户端通过 graphql/前缀的 Rest API 方式请求,后端通过前缀与 GraphQL Query 绑定,从 DB 获取映射关系,最终转换成 GraphQL 支持的查询语法。
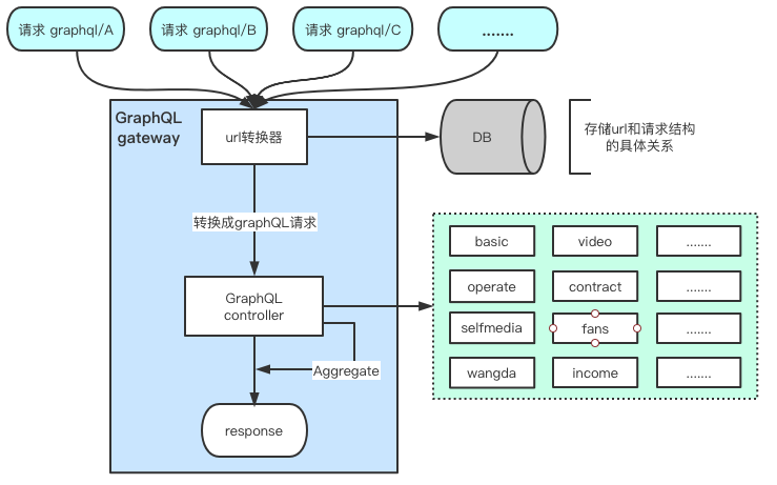
图 3-2
2.动态接入监控
在 user-info-graphQL 项目中,原本是通过 template url 来匹配任意自定义 url;导致监控平台只能显示 template url 的请求信息,如图 3-3 所示。这个问题可以通过重写 spring-boot-actuator 中获取 tags 的方法,将真实的 url 请求信息暴露到 Spring boot 的/actuator/prometheus 端点这个方法来解决,如图 3-4 所示。

图 3-3

图 3-4
通过暴露的监控端点接入 Prometheus,实现对新生成的 API 进行实时动态监控,示例效果如图 3-5 所示:
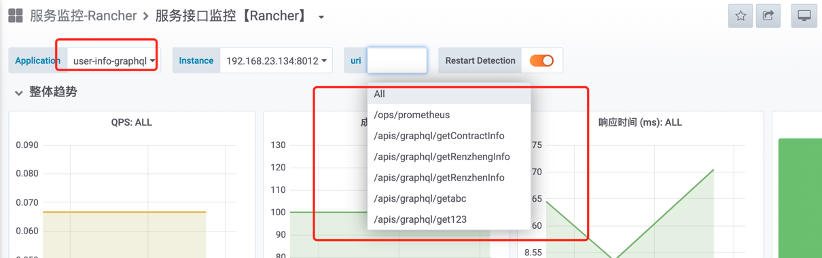
图 3-5
3.灵活配置
为了方便后端快速接入新增微服务,达到支持 API 动态扩展目的。项目中通过 Velocity 定义 schema 模板,通过 Java 注解、反射机制动态生成 graphqls 模板文件,如图 3-6 所示:
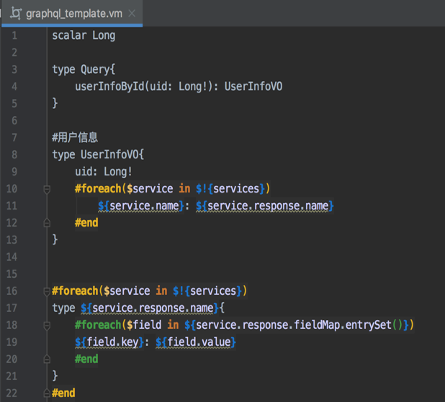
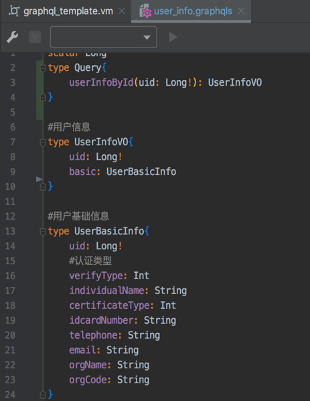
图 3-6
图 3-6 中的 GraphQL schema 模板,支持通过用户 UID 查询用户信息。用户信息是由多个微服务聚合而成,采用异步调用多个微服务并行获取数据。基于此模板,用户只需要实现 SPI 定义好的接口,就能实现对新增微服务的支持。
4.可视化 API 管理平台
通过 API 生成管理平台,开发人员可以实现 API 接口的可视化配置、生成、动态监控等功能,达到开箱即用的效果,极大提升开发和运维效率。
总结
通过 GraphQL 动态构建 BFF 服务层 API,聚合不同的微服务,相比于 Rest API 方式,能够减少后端重复开发,加快响应前端需求。后端开发人员只需要开发维护新增微服务,并通过 SPI 方式,增加 BFF 层对新增微服务的支持即可。
价值:
通过在爱奇艺号后端微服务引入 GraphQL 构建 BFF 服务层,可以达成以下效果:
开发方面的优势
提升开发效率:后端开发人员职责分工明确,微服务与 BFF 层独立开发及维护。新增微服务接入方便,因 BFF 层对外的 API 支持动态生成,所以无需更改 BFF 层的代码,只需集中维护微服务。前端可以通过 GraphQL 的 schema 查看接口返回数据,减少前后端沟通成本。
形成低代码平台:随着构建的微服务基础措施足够完善,BFF 层支持动态生成 API 接口,极大减轻重复工作量。
运行维护时的优势
便于监控:新增 BFF 层 API 接口,通过支持 Prometheus 端点监控,无开发成本。
支持系统高吞吐量:BFF 服务、微服务都是基于 docker 部署,支持 QPS 动态扩容,能够支持高并发。
便于维护和扩展:基于 GraphQL 构建的 BFF 层,API 接口动态生成,层次清晰,更易维护、扩展。
难点:
动态扩展查询支持,目前 schema 的定义都是基于明确字段的情况下,如果需要支持动态的查询支持,需要支持动态 schema 扩展和解析。
中文文档少,Facebook 官方只发布了 JS 实现,Java 实现都是基于开源社区,文档和功能都不是很完善。
未来规划:
随着 BFF 端对 API 请求的多样化,需要动态支持新方法扩展及监控。目前 API 与请求的映射关系持久化在 MySQL 中,需要支持集群和高性能,后续逐步迁移到 ZK 或 Redis 中,并缓存到本地。
随着云原生和 K8s 的兴起,基于 K8s 部署的 Go 服务,更易扩容和维护。基于 Java 实现的 GraphQL,如果迁移到 K8s 上部署,很难实现快速扩缩容的效果。而 graphql-go 在 github 上的 star 高达 7k,可见热度极高。如果基于 Go 实现 BFF 端,API 与请求的映射关系可以存储于 K8s 的 Pod 配置文件中,并且通过一个 API 部署一类 Pod,进行服务隔离,可以更高程度的保证服务稳定。
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




