
欢迎阅读新一期的数据库内核杂谈。先给大家道个歉,这次又双叒叕地拖更了。一来是工作有些忙;但更多的是,既上次写完 Vector database 系列后,一直没有新的输入,自己也没啥想法。直到最近读到了 Meta 的一篇关于数据库执行引擎的研究论文:Velox: Meta’s Unified Execution Engine。说起 Velox,在我离职 Meta 前,还听到了这个项目,当时就知道是要重新用 C++写一个执行引擎。希望用最新的技术比如 vectorization,使得这个执行引擎的速度更快更高效,同时希望这个引擎可以被用在多个数据处理系统里面。结合目前的论文来看,正如原先所期望的,已经被用在了内部多个系统里面。并且,Meta 也将 Velox 开源了(Github 地址:https://github.com/facebookincubator/velox)。咱们正好结合阅读这篇论文,一起复习一下执行引擎的知识。
为什么需要构建 Velox
Meta 内部有多个数据处理系统,每个系统都有自己的处理引擎,比如 Presto 有自己的基于 MPP 架构的执行引擎,Spark 有 Spark 执行引擎。为什么需要构建一个新的数据执行引擎呢?其实,恰恰是为了应对多样且不断增长的数据需求,才推出多个不同类型的数据引擎:包括 Presto(主要是做即系,交互式的 SQL 分析),Spark(批处理引擎),XStream(流式处理引擎),FBETL(离线 ETL),F3(针对机器学习特征工程的处理引擎)等数十个引擎。
这些执行引擎当然可以在各自的系统中发挥作用,但它们彼此之间是完全独立的,没有任何代码共享,可以认为,完全是独立的轮子。这就带来了下面这些挑战:
1)重复性的工作:虽然不同类型的数据处理逻辑不同,但一些核心功能,比如表达式计算,聚合操作,JOIN 操作,排序操作,以及数据读取操作等,在每个执行引擎都要重新实现一遍。
2)不同执行引擎的语义和用户体验也会不同,即便,有相似语义的 operator,数据类型等存在。
3)多个执行引擎不仅带来了重复性的工作,也增加了维护,优化和添加新需求的工作量。
为了解决上述问题,Meta 开发了 Velox,一个开源的、统一的执行引擎,旨在加速和标准化其生态系统中的数据计算逻辑。Velox 提供可重用的,可扩展的,高性能的,与编程语言无关的数据处理组件,可以用来构建新的或增强现有系统的执行引擎。下面这张图,很好地诠释了 Velox 的作用。
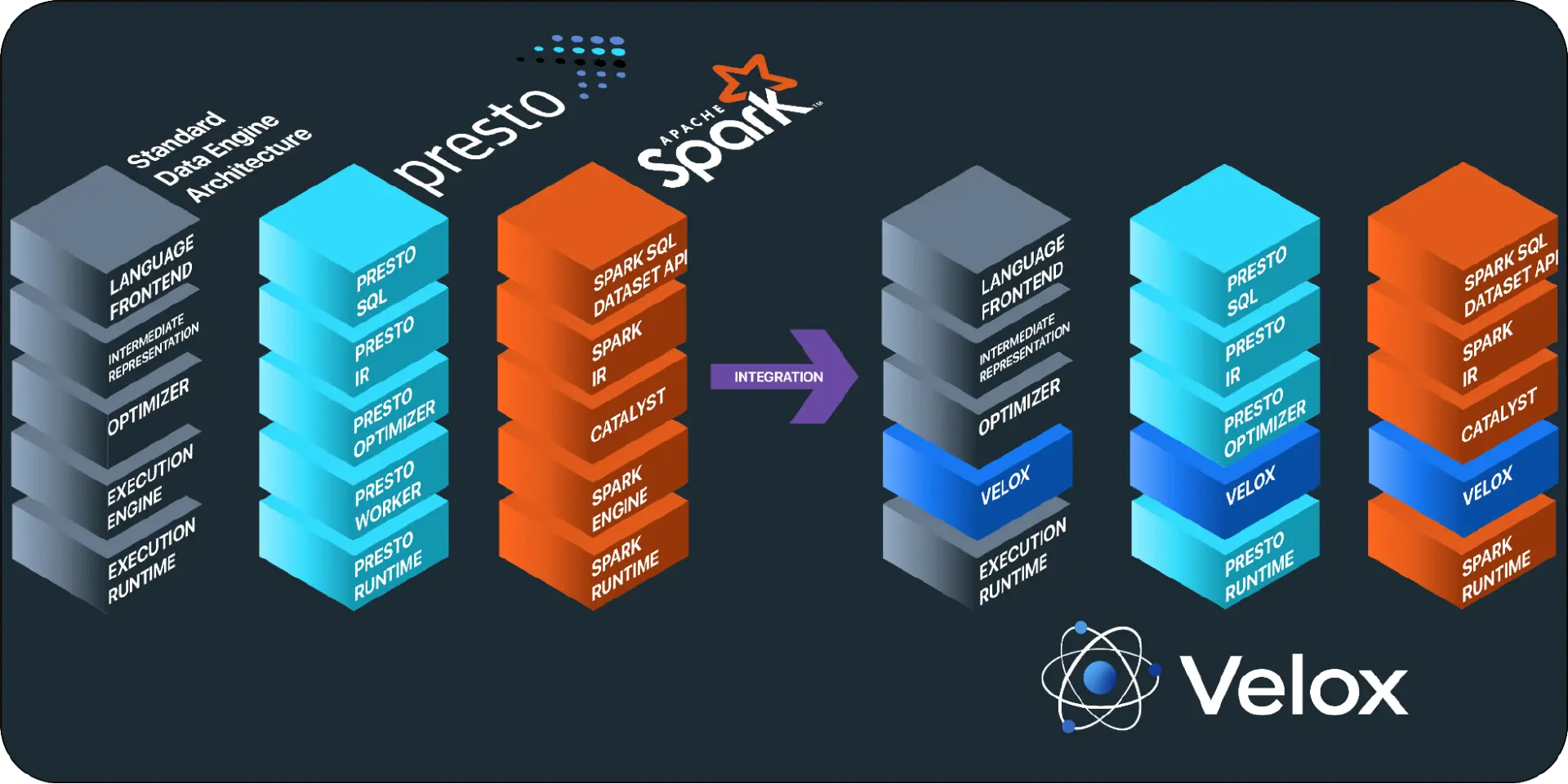
Velox 简介
以下是 Velox 执行引擎的一些关键特性:
1)向量化执行:Velox 大量依赖向量化技术,以批处理方式处理数据,利用现代 CPU 的 SIMD 指令等能力。这相比传统的单元数据处理方式,能带来显著的性能提升。
2)编译时代码生成技术:和向量化执行类似,Velox 也引入了编译时代码生成(code-gen)技术来提升某些 expression 的处理性能。
3)适应性:Velox 库在运行时利用自适应技术,例如 动态地对过滤器进行排序技术,以根据处理数据的特性来优化查询执行的效率。
4)支持复杂类型:Velox 从一开始就设计为高效处理现代工作负载中常见的复杂嵌套数据类型,如结构体、数组、映射和张量(tensors)。它使用字典编码(dict-encoding)等技术来优化这些类型的存储和处理。
5)可扩展性:Velox 库提了供可扩展 API,允许其他开发者通过 API 添加自定义数据类型、函数、操作(operator)、文件格式、存储适配器等插件。这使得 Velox 能够适应不同数据处理逻辑的具体需求。
值得强调的是,Velox 并不是一个完整的数据库系统。它不提供 SQL 解析器、查询优化器、元数据目录或分布式执行运行时等组件。它是一个专注于单节点的高效执行数据处理操作的库。
Velox 是如何被使用的呢?它并不是直接作为终端被数据查询的用户使用。它被作为执行组件(library)集成到现有的数据引擎中。在一个查询语句的执行过程中,Velox 的代码作为操作符(operator)被优化器编排在整体的执行计划中。执行的过程中,Velox 库会被加载到机器上,利用这个机器的资源来高效执行数据处理逻辑。
通过将高性能、可复用的执行组件整合到一个开源 C++ 库中,Velox 使不同的数据处理系统都能够利用最新的,高级的执行引擎技术,提高终端用户的使用体验,并通过代码和库的复用减少整体工程工作量。目前,它已经和 Meta 内部的十多个数据系统集成,涵盖了上面提到的所有的数据系统,交互式分析,批处理和流处理,和机器学习等。
Velox 设计和架构细节(Velox Architecture Deep Dive)
Type System(类型系统)
我们先来聊最基础的类型系统。Velox 的类型系统,定义了基础的原始类型,包括不同精度的整数和浮点数,字符串(包括 varchar 和 varbinary 类型),日期,时间戳和函数类型(lambda)。除此之外,类型系统也支持了复杂类型。如变长数组,固定大小数组(用于实现机器学习中使用到的张量),Map 结构体和 Row 结构体等。所有这些类型都可以进行任意嵌套,Velox 也提供序列化/反序列化方法。比较特殊的是,Velox 提供了一种不透明的特殊数据类型,开发者可以用它轻松包装任意的 C++ 数据结构(有点类似 pointer)。
类型系统的另一设计是允许开发者添加适配特定数据引擎的类型,而且这个过程不需要修改和编译 main library。文中举了 Presto 系统的一些特殊类型,比如 HyperLogLog 类型用于 cardinality estimation,以及其他 Presto 的特殊的日期类型,如带时区的时间戳。通过类型扩展性添加的类型可以在构建自定义标量和聚合函数时被使用。
Vector Type(向量类型)
Velox 的 Vector 类型允许开发者在内存中使用各种编码格式来存储列式(columnar-based)数据集。数据集通常在计算执行中作为输出和输入存在。内存格式继承并扩展了当下最流行的开源的基于内存的,支持列存的 Apache Arrow 格式(https://arrow.apache.org/),它记录了一个数据 size 的变量(表示 Vector 存储的行数),数据类型,和一个可选的 bitmap 来记录 null 值。
Vector 类型还提供了一系列方法,支持复制,调整大小,哈希化(serialization),比较和打印 Vectors。Vectors 可以表示固定大小(例如整数和浮点数等原始类型)或可变大小的元素(例如字符串、数组、映射和结构体/行)。Vectors 还可以以任意方式嵌套(例如包含字符串和其他原始类型的结构体的数组的数组),并且可以支持不同的编码格式,这个格式由对应的系统组件在生成 vectors 时指定。
所有 Vector 数据都使用 Velox Buffers 存储,这些 Buffers 是从内存池中分配的连续内存块。所有 Vectors 和 Buffers 都是引用计数的,一个 Buffer 可以被多个 Vectors 引用。只有单一引用的 Vectors 数据是可变的,但任何 Vector 和 Buffer 都可以通过写时复制变为可变。
此外,Velox 还引入了 Lazy Vectors 的概念。即仅在首次使用时才会填充的 Vectors。Lazy Vectors 在 Cardinality reduction 操作(即输出的 row 数量远低于输入的 row,比如 Join 操作和 Conditonal projections(where 操作))中非常有用。根据选择性的比较情况,,可以完全避免物理生成这个 vectors,或者将其范围限定在少数被选中的行数。对于从远程的存储介质读取数据也有很大的性能优化,可以避免读取上层 operator 不需要的整个 columns。
因为 Velox 支持不同编码形式的 vectors,对于研发同学来说,在实现某些 operator 的时候,需要非常清楚输入的 vectors 是什么类型的,这当然可以让研发使用适合这个编码格式的优化操作,但同时这也对研发同学来说,增加了额外的工作负担。因此,Velox 也支持了 decoted Vector Abstraction,将不同类型的 vectors 实现都抽象成了一个扁平序列的数组,并支持 index 索引。
Expression Evaluation(表达式求值)
Velox 提供了一个向量化的表达式计算引擎,可以用于下面这几种计算场景:1)它被 FilterProject 操作符使用,用于求值过滤和投影表达式;2)它可被 TableScan 和 IO Connector 使用,来支持 predicate pushdown 操作;3)它可以作为一个独立的组件来做表达式求值,如实时计算组件或者机器学习的数据预处理组件。
表达式求值的输入是经过 parse 的表达式树。树中的每个节点可以是下面任意之一:1)输入列的引用;2)常量;3)函数调用,由函数名和输入表达式列表表示;4)CAST 表达式或者是 Lambda 函数。除了一般的函数,函数调用节点也用于支持合取(AND/OR)、条件(IF/SWITCH)和 try 表达式。
表达式求值分为两个步骤:编译和求值。
1)编译步骤接受一个或多个输入表达式树的列表,并生成编译的(可执行的)表达式代码。编译过程可以应用一些主流的运行时优化,如公共子表达式消除、常量折叠和自适应合取重排序。
2)求值步骤接受编译的表达式和输入数据集(使用 Velox Vectors 表示),计算结果后返回输出数据集(也是 Velox Vectors)。该过程包括对表达式树的递归下降,传递一个行掩码以标识活动的(非空且未被条件掩码掩盖的)元素。在每一步中,可以在两种情况下避免求值:(a) 如果当前节点是公共子表达式且结果已计算,或 (b) 如果表达式被标记为传播空值,且其任何输入为空值。
当输入是字典编码时,可以通过仅考虑 distinct values 来更高效地计算确定性表达式。这是通过首先验证所有输入列共享的字典(dictionary)。如果是这样,则剥离这些包装以提取内部向量集(不同值),在这些内部向量上评估表达式,并使用原始包装将结果重新包装成字典向量来实现的。
表达式求值过程,可以根据数据量被重复执行,使用一个编译的表达式求值代码来处理多个数据批次。例如,当从 TableScan 操作符读取多个数据批次时,批次通常是字典编码的,并引用相同的基础向量。在这种情况下,求值引擎利用这一特性,记住在底层内部向量上计算的表达式求值结果,并在随后的批次中重用这些结果,来提升运行效率。
总结
这一期,我们一起开启了一个新系统的学习,Meta 开源的数据处理引擎 Velox。我们介绍了 Meta 需要“重新造一个计算引擎轮子”的原因,对 Velox 进行了 overview 介绍,并学习了一些组件的细节。




