
本文整理自 Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(莫问)在 Flink Forward Asia 2021 的分享。本篇内容主要分为四个部分:
1. 2021: Apache Flink 社区持续繁荣
2. Apache Flink 核心技术演进
3. 流批一体演进与落地
4. 机器学习场景支持
2021: Apache Flink 社区持续繁荣
1.1 Flink 大版本迭代

2021 年,Flink 社区共发布两个大版本:Flink 1.13 和 Flink 1.14。
在 Flink 1.13 中,Flink 的部署架构朝着云原生架构进一步演进,使得 Flink 能够更加适应云原生环境下的运行;此外,Flink 在易用性方面也有显著提升,使得用户可以非常便捷地对 Flink 任务进行调试、调优和监控等;在存储方面,Flink Checkpoint 格式得到统一,用户在不同的 State backend 之间无缝切换,不同的版本之间可进行流畅升级。
Flink 1.14 中最大的变化是完整地实现了 Flink 流批一体的架构和理念。在去年的 Flink Forward Asia 2020 会议上我重点分享了 Flink Unified SQL。今年,Flink 不仅在 SQL 和 Table API 上进行了流批一体的统一,在 Java API 本身、Data Stream,Data set API 上也进行了流批一体的统一。所有流批一体的语义都被统一到 Data stream API 之上,用户基于 Data stream 可以处理有限流和无限流从而实现流批一体的开发。此外 Flink 在资源层实现了细粒度的资源管理,令 Flink 任务在大规模场景下更高效;在网络流控方面 Flink 也进行了自适应流控的升级,经过自适应流控升级之后,用户可以更快地执行 Flink 的全局一致性快照。经过这些技术创新和技术演进之后,Flink 社区继续保持快速发展和生态活跃。
1.2 Apache Flink 社区层面表现持续亮眼
在 2021 年,Apache 软件基金会的财年报告中,Flink 社区的多项指标依然保持非常健康的发展:在邮件列表中继续排名第一;Github 项目访问流量排名第二;代码库的提交次数排名第二等。通过这些活跃的指标可以看到 Flink 社区的活跃度在整个 Apache 软件基金会的社区中名列前茅。
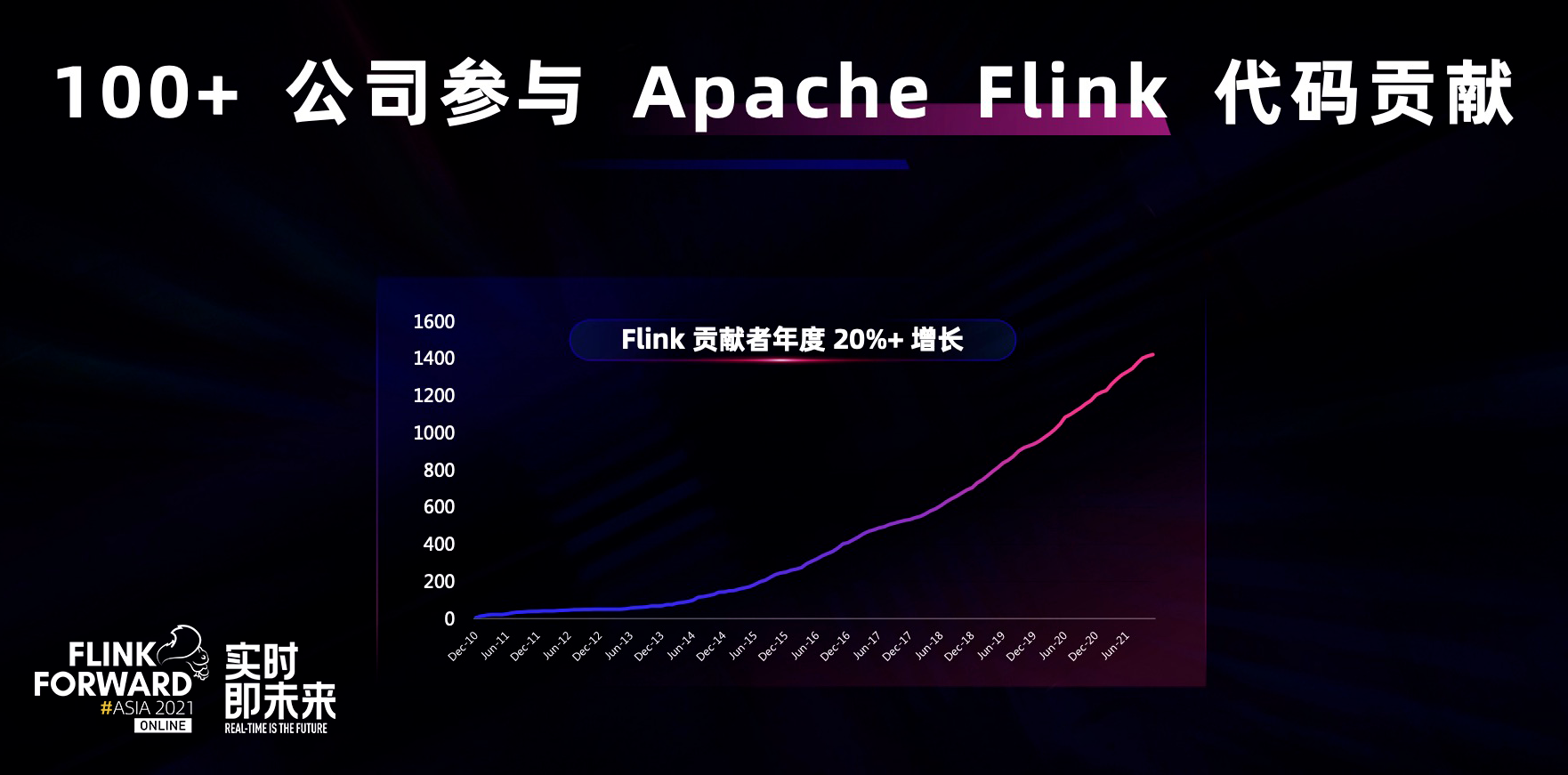
Flink 社区的健康发展离不开广大代码贡献者对 Flink 项目的软件研发和技术应用的推动。截止目前,已有超过 1400 名开发者对 Apache Flink 项目进行过代码级的贡献。这些开发者分别来自于全球 100 多家公司,其中不仅包含全球知名的国际化公司,还有更多来自中国本土的科技公司,中国因素在 Flink 社区发挥着越来越大的作用。

阿里巴巴从 2018 年开始就积极建设 Apache Flink 中文社区,推动 Flink 在中国的快速发展。
从开通 Apache Flink 的公众号(Apache Flink)至今,已有 5 万名开发者订阅,仅去年一年,Apache Flink 公众号就发布了 140 多篇技术文章,主要围绕社区的动态、技术分享、以及各行业如何使用 Apache Flink 的用户案例。最近,Apache Flink 视频号也已正式开通,希望借助更加新颖的形式,从更多维度展示社区的发展,对社区的技术和应用进行分享。
2021 年 7 月份,Flink 中文学习网站(https://flink-learning.org.cn)正式上线。我们将网络中各种 Flink 的学习资料汇集到一起,让更多 Flink 开发者、Flink 用户能够非常方便地学习 Flink 的知识技术、应用场景和应用案例。
虽然 2021 年是充满疫情的一年,但社区运营活动没有停止。我们在北京、上海等地依然举办了 4 场 meetup。我们也期待在新的一年中,越来越多的公司愿意积极主动承担 Flink 社区的活动,推动 Flink 社区的发展。
Apache Flink 核心技术演进
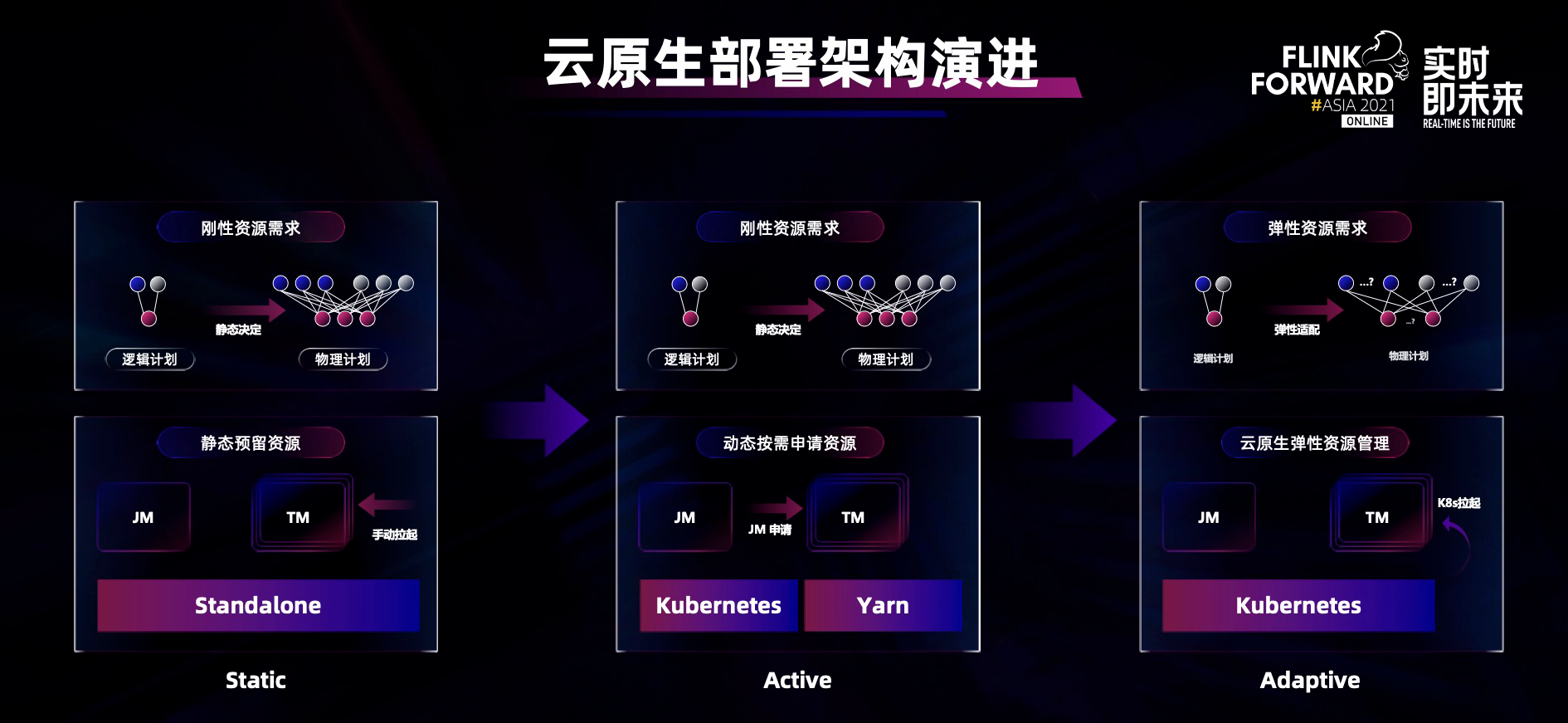
大数据和云原生是密不可分的两个场景,云上的环境和弹性可以给大数据计算更多空间,推动大数据更快普及。Apache Flink 在云原生的趋势下对部署架构和资源管理方式做出进一步演进,使其完全适应云原生模式:云上用户可以根据业务的流量变化随时动态扩缩容资源,做到按需使用,因此 Flink 也要适应云上按需使用的场景,根据云上资源动态扩缩容的变化在计算拓扑上以自适应模式调整并发,从而适应云上资源变化,具备更好的自动化运维和自适应运维能力。
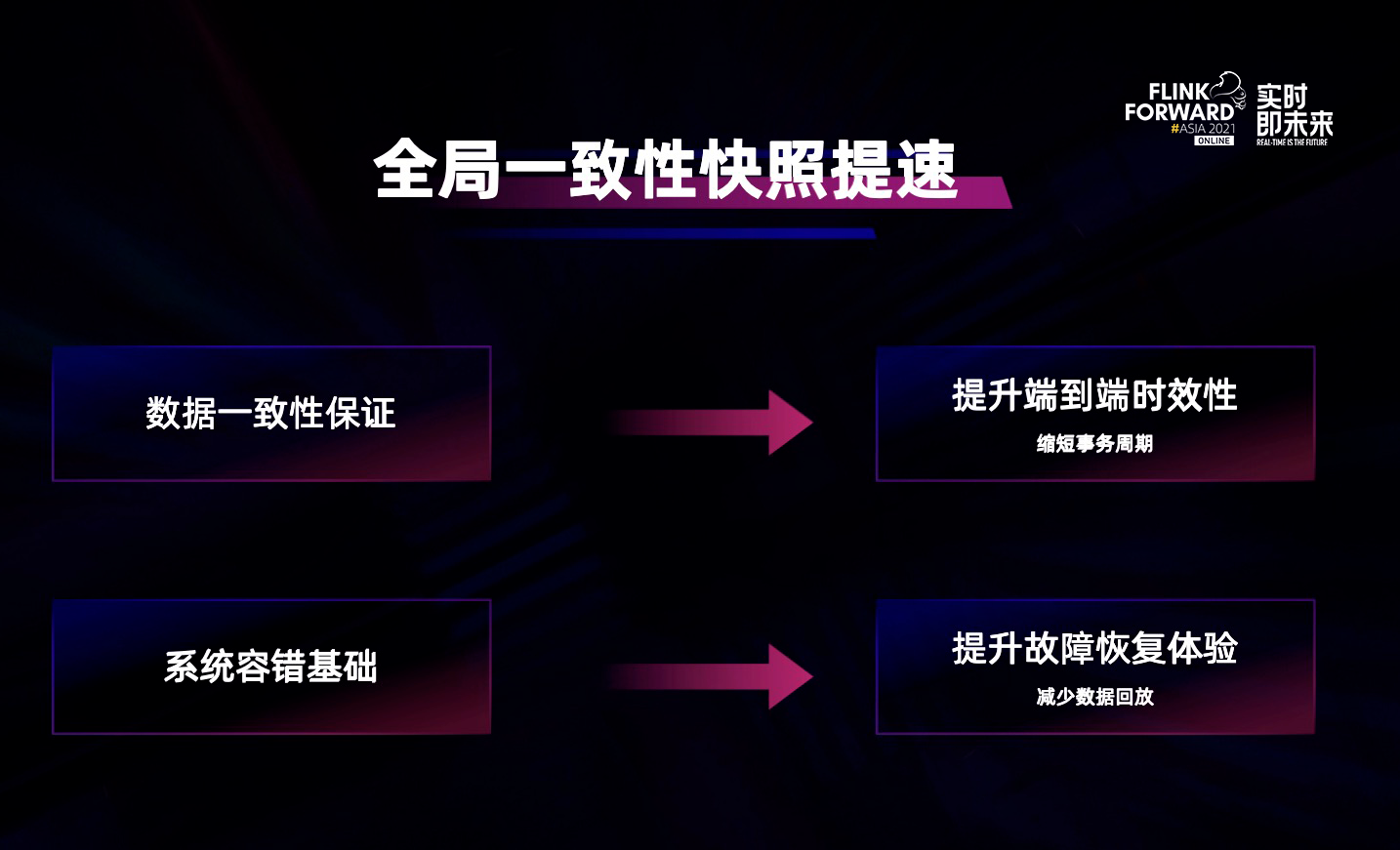
除了云原生之外,Flink 最核心的技术理念是全局一致性快照。因为 Flink 最大的技术亮点就是它是有状态的实时计算引擎,通过 chandy Lamport 算法实现全局一致性快照,保证数据在完全实时的情况下实现完整的数据一致性保证和容错能力,所以全局一致性快照是 Flink 数据一致性保证和系统容错的关键。如果我们能够不断提升全局一致性快照的质量和性能,Flink 核心的实时计算体验就会得到提升,包括灾难恢复也会变得更加平滑。
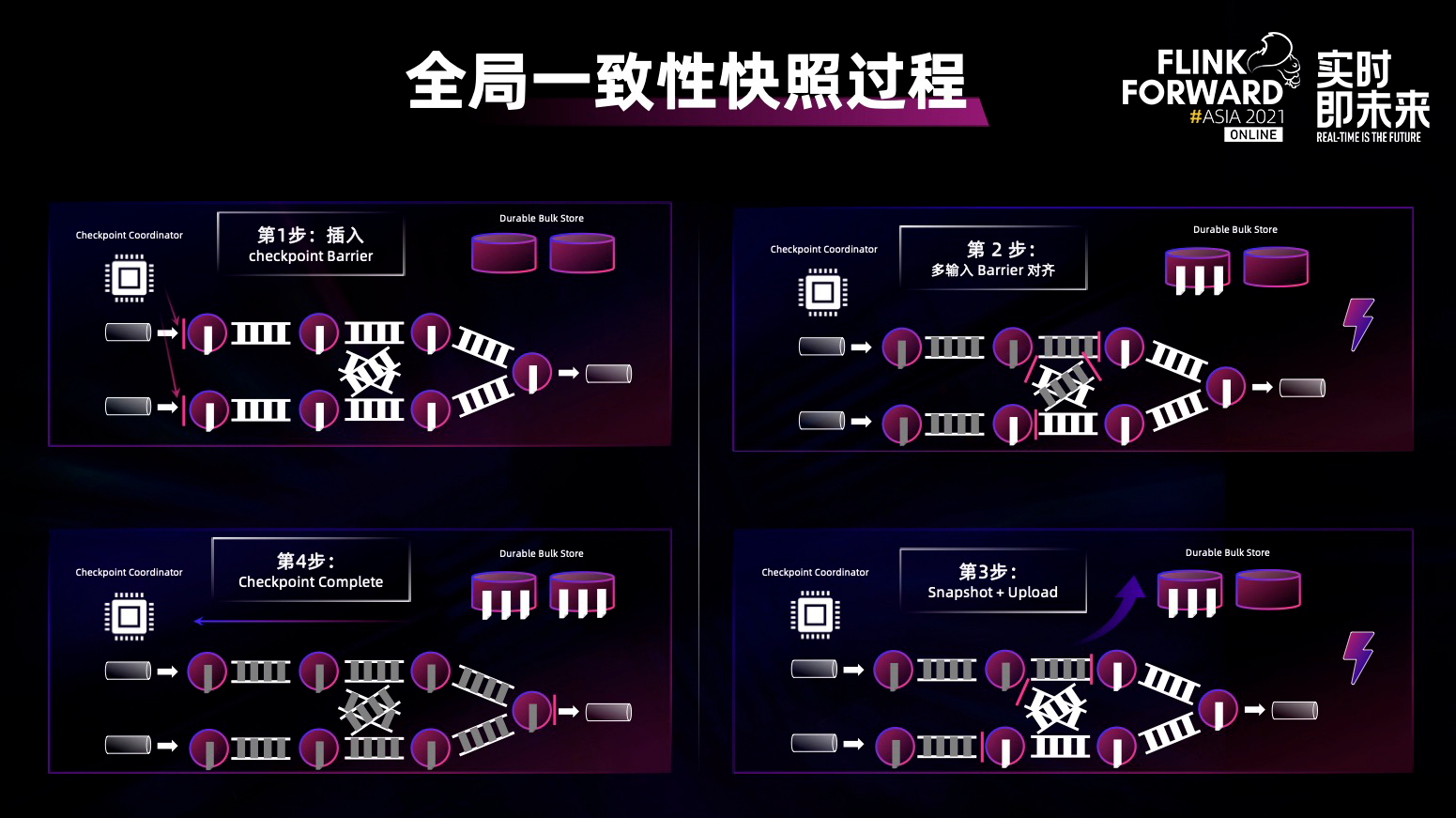
Flink 全局一致性快照的过程,总共分为四个步骤:
插入 checkpoint barrier:定期在 source 端插入特殊的 barrier,barrier 会顺着数据流向下游流动;
多输入 Barrier 对齐 :每一个算子收到所有上游的 barrier 之后,做 barrier 对齐,然后做下一步 snapshot;
Snapshot + Upload :在 snapshot 过程中需要将内部状态数据做持久化存储,比如存入 HDFS 之中;
Checkpoint Complete :将 snapshot 做完之后同步 master,当所有的算子做完之后,全局分布式的一致性快照流程完成。
在这个过程中,真正能够提升性能主要在第二点和第三点,即 barrier 对齐和将整个数据做一次 snapshot 并上传到 HDFS 上。
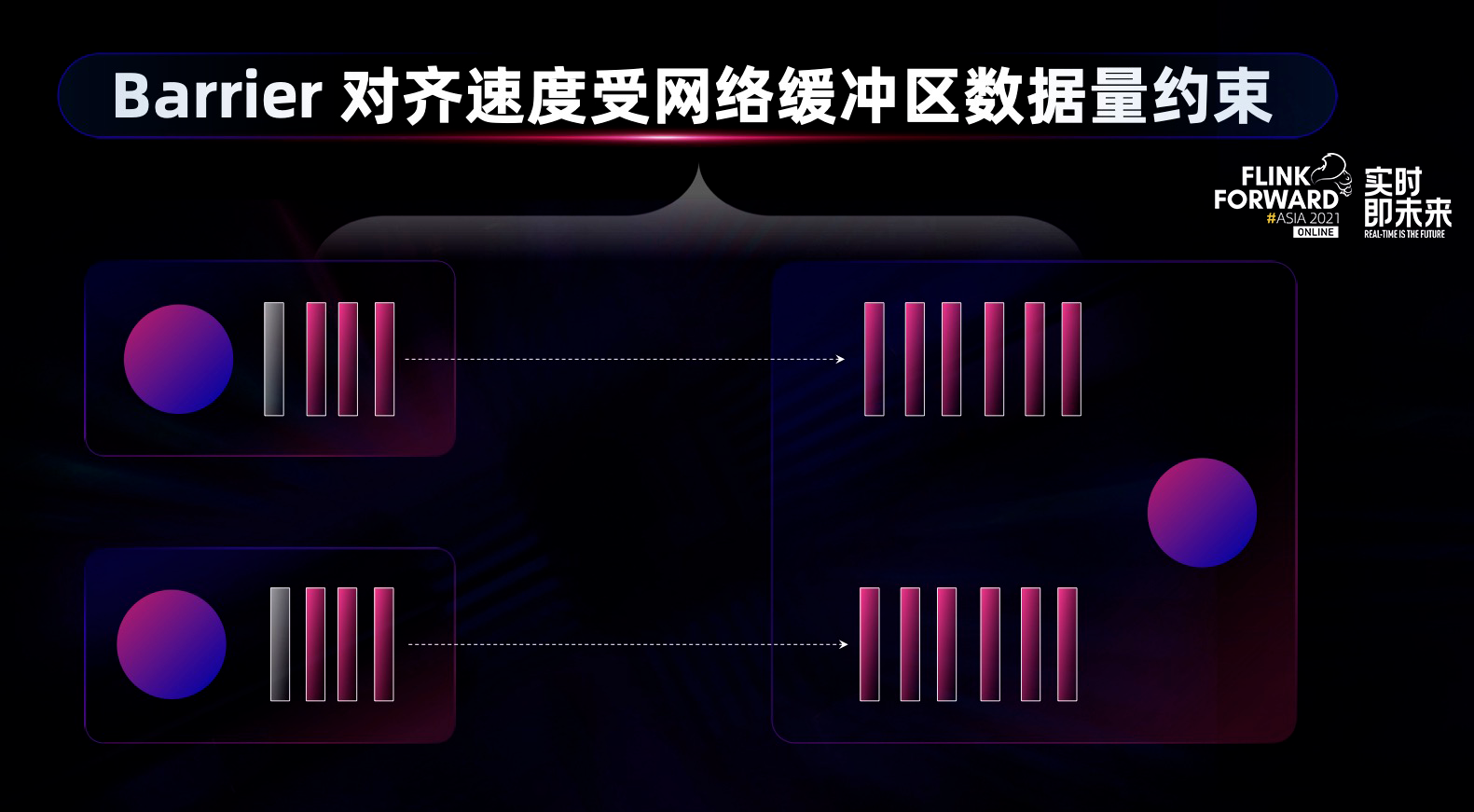
因此 2021 年,Flink 社区主要围绕第二步和第三步做 checkpoint 的优化。 barrier 对齐看起来是一个简单的操作,但有时候也会卡很久,尤其是在反压的情况下,当下游算子的计算能力突然下降,大量数据阻塞到网络层,使得 barrier 对齐耗时很久,将会导致时间不可控。
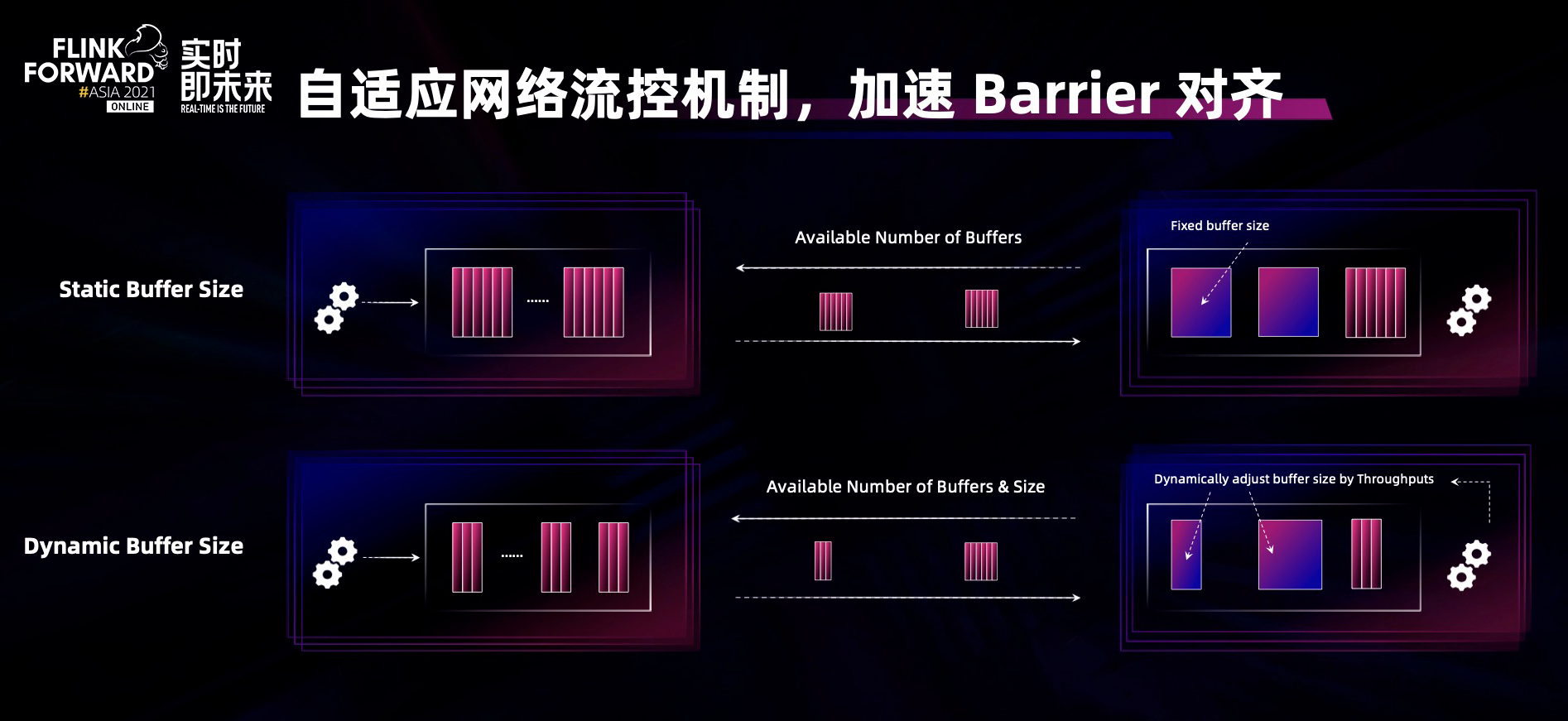
如何解决这个问题呢?Flink 的网络流控机制是 credit-based 的流控机制,即上下游通过协商和控制上下游之间 buffer 的数量,起到高效的网络流控。但当下游出现反压情况,计算能力急剧下降,这时不需要大量网络 buffer 进行数据缓冲,所以我们提出在 credit-based 的基础上实现了 adaptive,即自适应的网络流控机制:不仅考虑上下游协商时网络 buffer 的数量,还会考虑网络 buffer 的大小,根据计算能力动态调整 buffer size,这样在下游反压计算能力下降的情况下,网络 buffer 的数据量就会变少,从而缓解反压时对 buffer 对齐的影响。

为了进一步提升 checkpoint 的性能和速度,需要加快每个算子做本地 take snapshot 的过程,为了改变整个 take snapshot 和备份 snapshot 的机制,于是 Flink 引入了 log-based 的 checkpoint 机制,加速单算子执行 checkpoint 的性能。
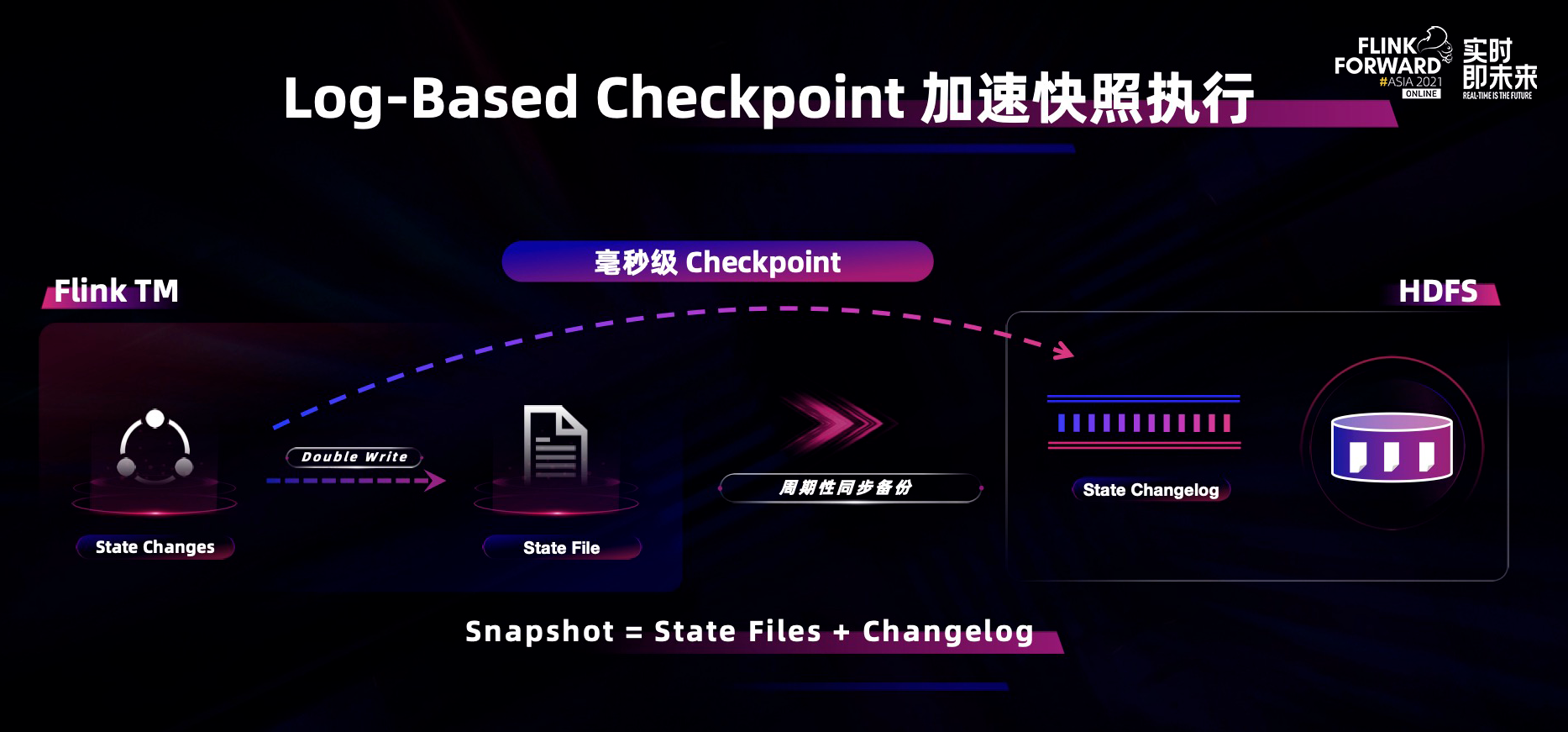
有了这个机制之后,用户就可以在写 state 时,一方面写 state backend,一方面写 changelog。当在做 snapshot 时,可以在 changelog 中打一个 meta 数据,表示 check point 已经做了,state 和 snapshot 数据就不仅是 state file,而且要加上 changelog。在这个过程中,可以把 state file 的数据向 HDFS 的拷贝作为定期规律化的过程,将它的频率和 checkpoint 的频率解耦,因此 check point 的速度就可以实现到秒级甚至毫秒级。这样不仅可以大幅度提升容错体验,全局一致性体验和端到端的数据体验都得到大幅提升。
Flink 不只有 SQL 的 API,也有 Java 的 API 去处理大数据的一些常规计算,在机器学习和科学计算领域被认为依然具有很大的潜力(实际上在机器学习领域 Flink 的确已经发挥了巨大作用)。
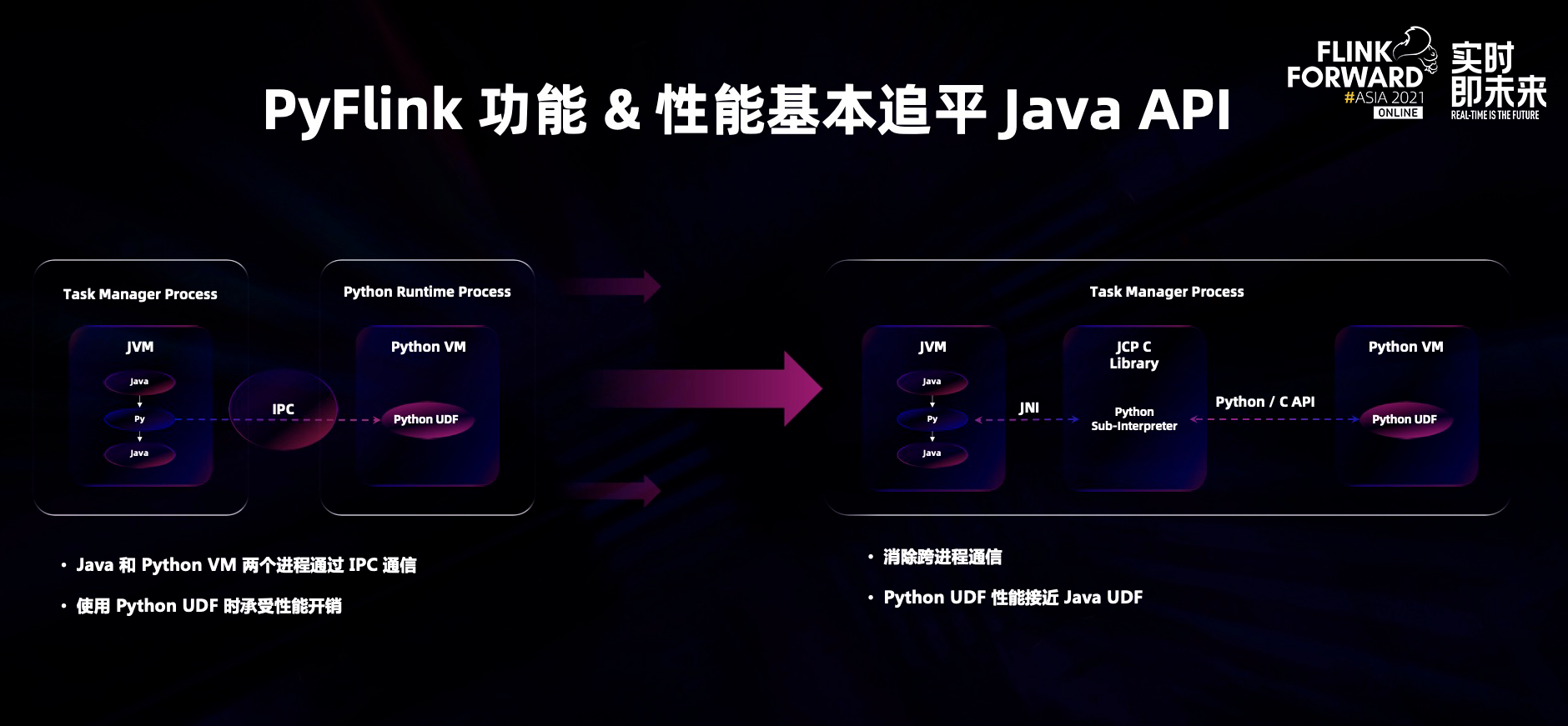
PyFlink 在 2021 完全追平了 table API 和 data stream API 的能力,同时在性能上做了很大的创新:在 PyFlink 里将 Java 代码,C 代码和 Python 代码运行在一个进程中,不需要进行跨进程通信。通过 JNI 的技术,Java 框架可以调用 C 的代码,在 C 里面又调用 Python 解析器去执行 Python UDF,成功去除跨进程通信的依赖,让整个 Python UDF 的性能可以达到接近 java 的性能从而兼顾开发和运行效率。

流批一体演进与落地
在传统经典的 stream processing 之外,流批一体是 Flink 社区最近几年一直在提的创新理念。接下来和大家分享流批一体在 Flink 的技术演进和实际落地场景。
在 API 层面,通过 unified SQL Flink 可以实现流批一体的开发。在去年天猫双十一项目中,阿里巴巴使用流批一体的 SQL 实现营销数据大屏实时和离线一体化的落地。今年,Flink 社区将 API stack 做得更加流批一体化,社区整合了 datastream 和 dataset 之后只保留了 datastream 的 API。在 datastream 的 API 上可以对接有限流和无限流,实现 java 层面流批一体的 API。
除此之外,Flink 的整个架构也彻底实现了流批一体的统一,可以同时处理有限数据集和无限数据集。用户可以开发一套代码同时对接两套数据源,因为 connector 框架不但可以兼容流式存储,而且可以兼容批式存储,甚至可以在流式存储与批式存储间自由切换。Flink 的调度是一套 scheduling 调度器,可以调度各种各样的任务。在数据网络 shuffle 上,不仅有 Flink 擅长的高性能流式 shuffle 框架,还引入了批式 shuffle 框架。阿里巴巴实时计算团队也贡献了第一版存算分离的 remote shuffle service,并放到了 flink 开源生态项目组下:https://github.com/flink-extended/flink-remote-shuffle
有了这套流批一体统一架构,Flink 社区真正实现了一套从 API 到系统架构的流批一体完整理念。
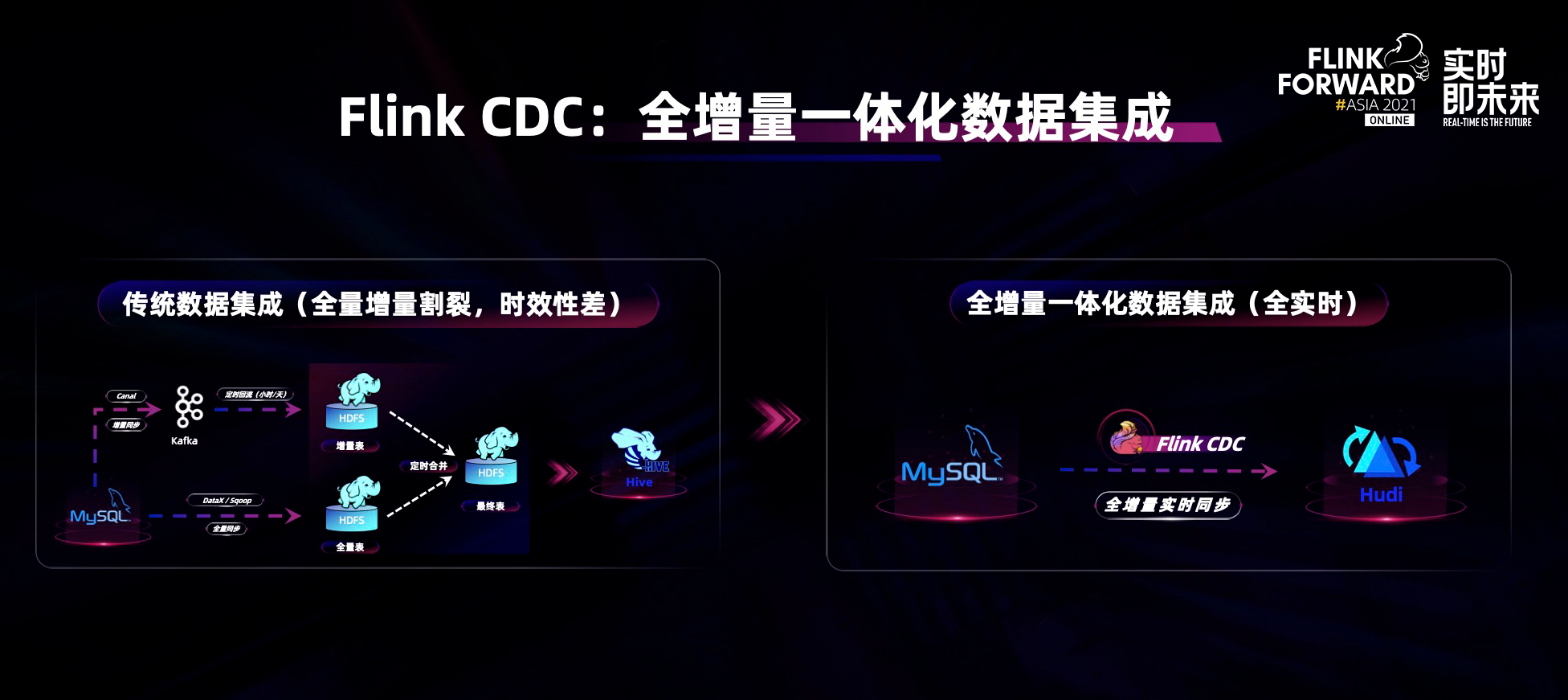
流批一体是技术架构理念,需要在具体业务场景中落地才能看到价值,接下来给大家举一个 Flink CDC 的例子。Flink CDC + 流批一体架构可以实现全增量一体化的数据集成。传统数据集成的离线数据集成和实时数据集成基本上采用两套技术栈,同时在两边进行复杂配合才能实现完整的数据集成方案。(PS:数据集成是刚需但同时又很复杂。)
Flink 的流批一体能力结合 Flink CDC 的能力可以实现一站式数据集成:先全量同步历史数据,然后自动接到断点续传增量数据,实现一站式的数据同步。比如我们可以使用 Flink CDC,用 1 个 job,一条 SQL 将 MySQL 全部数据同步到 Hudi 数据湖之中,并且自动进行增量的实时同步。
Flink CDC 已经可以对接主流数据库,比如 MySQL、MariaDB、PGSQL、MongoDB、Oracle 等等。基于 Flink CDC 2.0 可以一站式将数据全库同步到其他数据库或者数仓数据湖中。
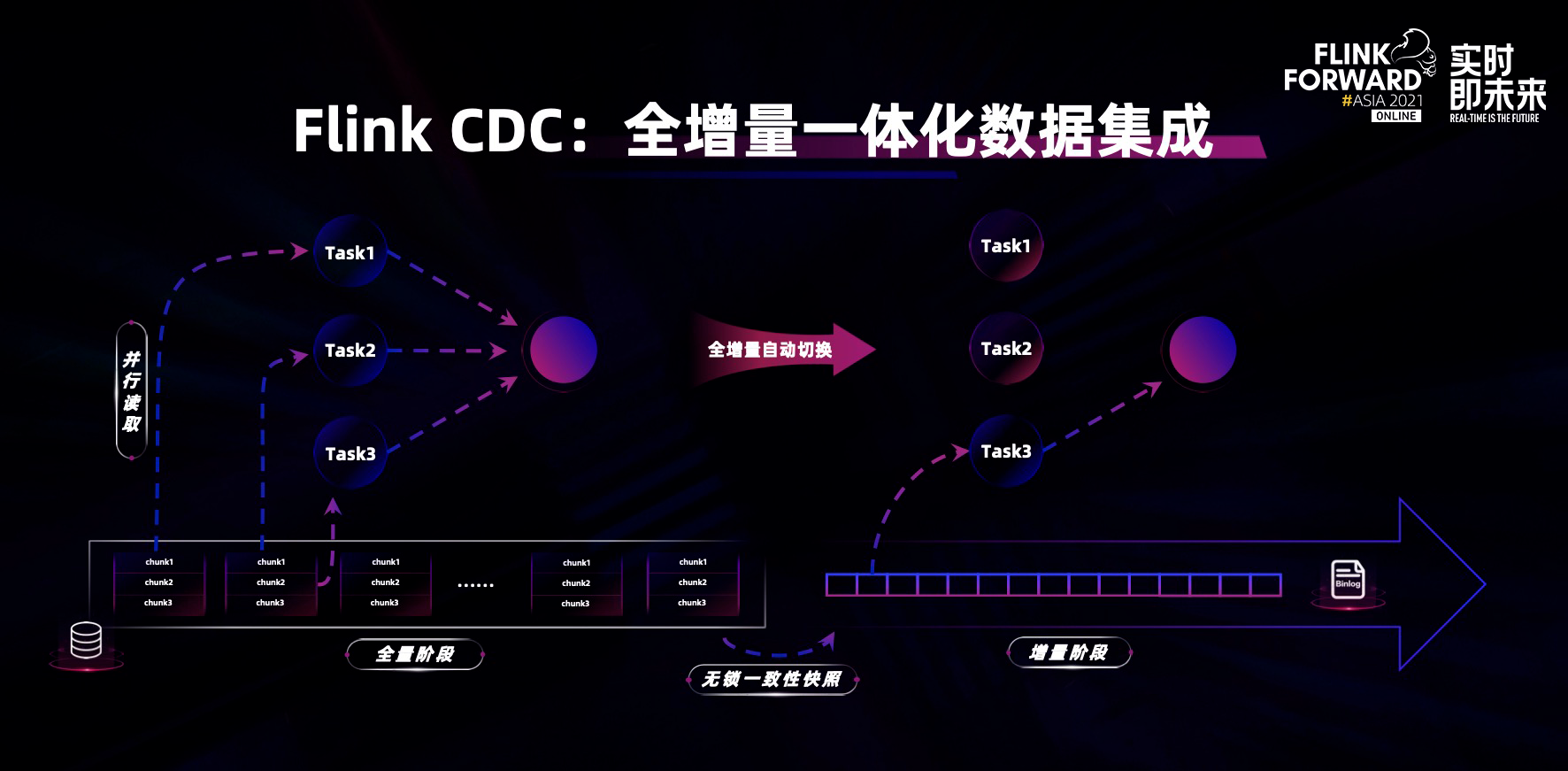
Flink CDC 如何实现全增量一体化的数据集成呢?
它利用了 Flink 流批一体的基础技术能力,结合 CDC 的 connector。在 Flink CDC 任务内部,第一步是全量读取数据库全表,基于 Flink 并行计算能力,快速将全表数据进行同步;然后自动切换到 binlog 的增量数据源上,利用 Flink hybrid source 的能力,做内部流批数据源的切换;切换到增量之后实时同步 binlog,从而达到离线实时全增量一体化的数据集成。在这个过程中能天然保证数据的一致性,对用户来说没有任何额外的操作。
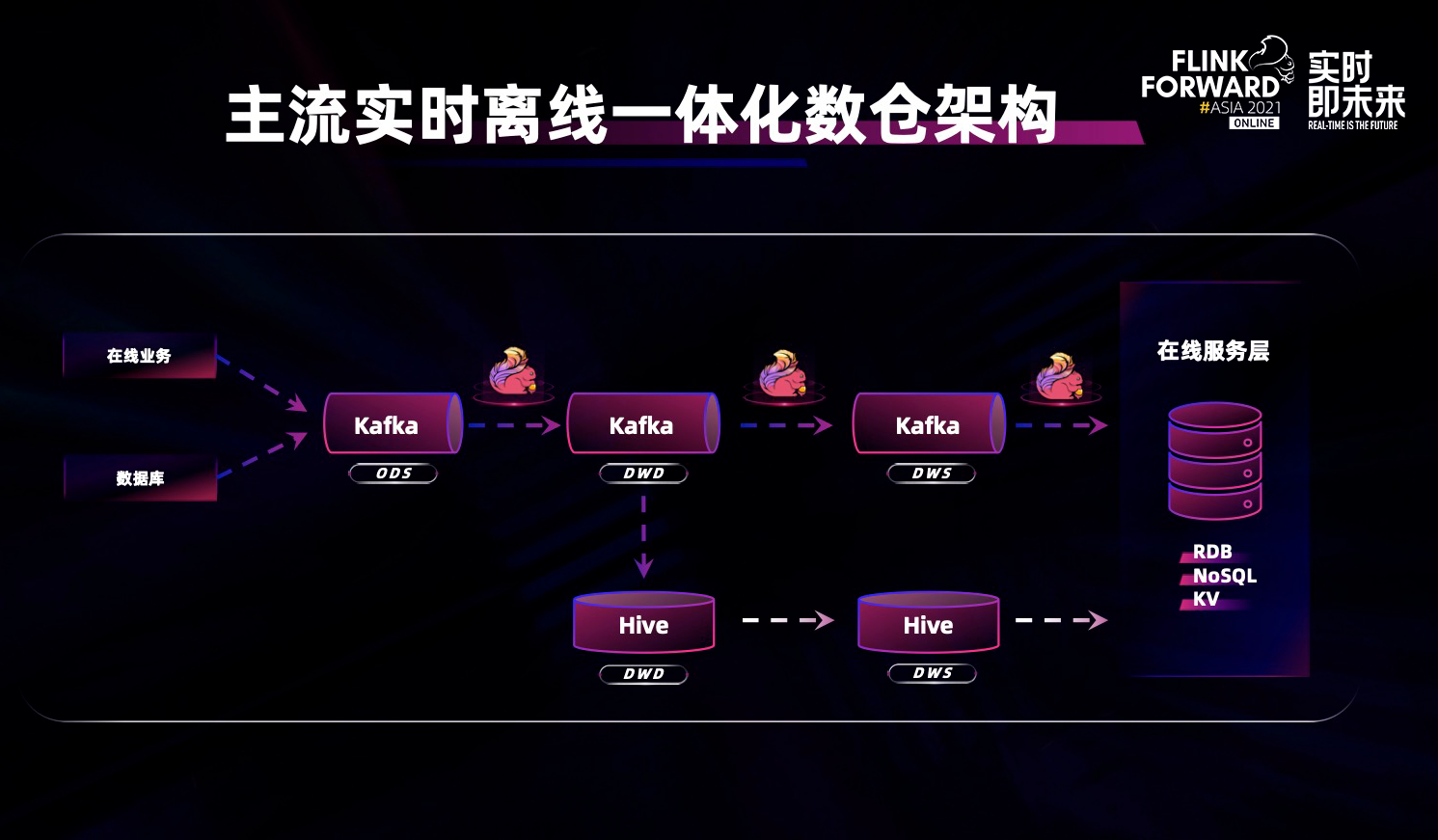
接下来,向大家着重介绍下实时离线一体化数仓场景。上图是非常经典主流的实时离线一体化数仓架构,绝大部分的用户场景都会使用 Flink 加 Kafka 做实时数据流处理,将分析结果写入在线服务层对用户进行展示或进一步分析,同时在后台有一个异步离线数仓架构,对实时数据进行补充,每天定期大规模的批量运行/全量运行或对历史数据定期修正。
但这个架构存在着几个问题:
1. 由于采用不同的技术栈,所以实时链路跟离线链路有两套 API,不但增加了开发成本,而且降低了开发效率;
2. 实时数仓和离线数仓的数据口径难以保持天然的一致性;
3. 在整个实时流动的链路中,以 Kafka 为代表的消息队列中的数据不便于实时探索和分析
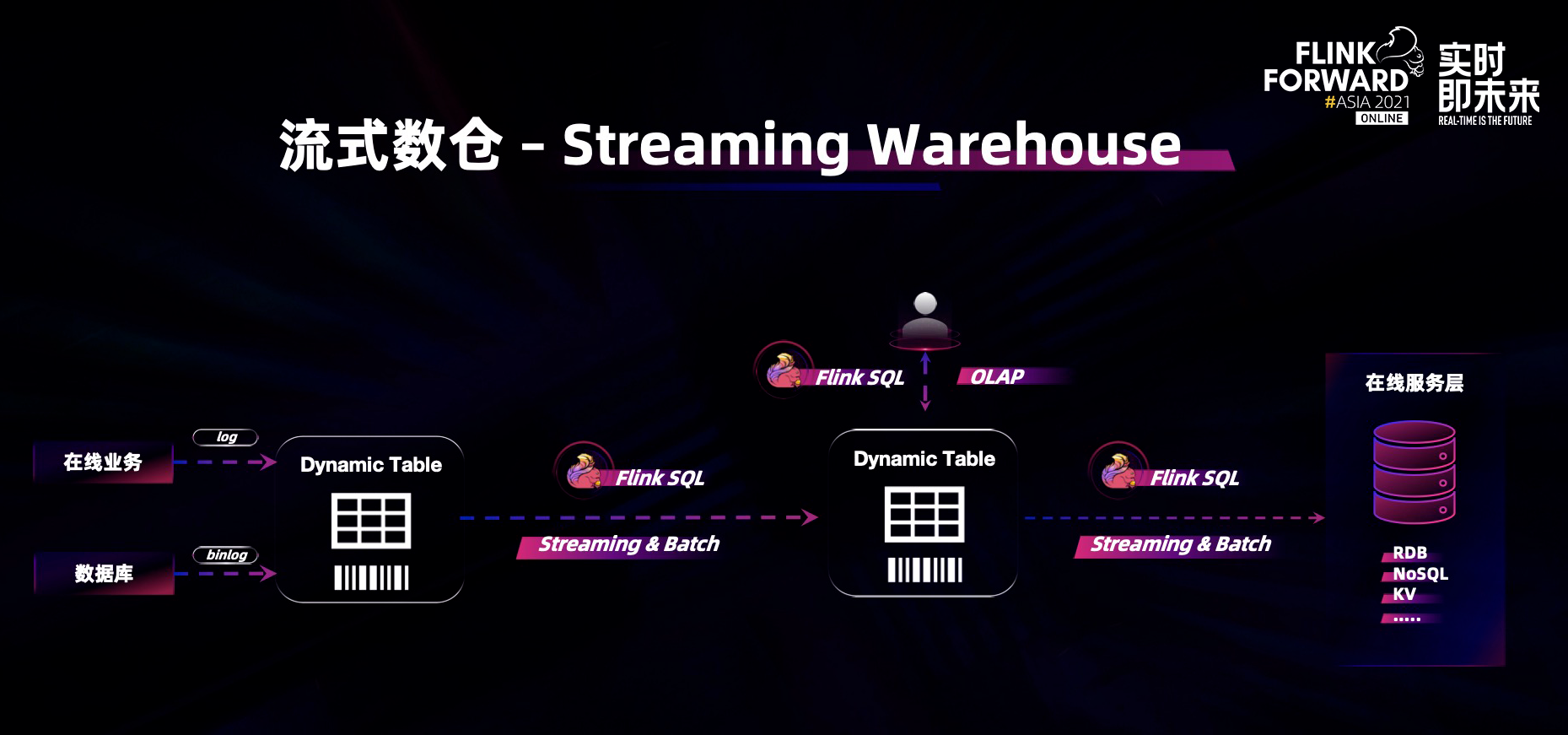
在新的 Streaming Warehouse 的架构中,我们引入了 Dynamic Table 的概念,即 Flink 的动态表,数仓的分层数据全部放到 Flink Dynamic Table 中,通过 Flink SQL 实时串联整个数仓的分层, 数据在各个分层间进行实时流动,并可以对历史数据进行实现离线修正。与此同时,用户可以利用 Flink SQL 实时探索和分析 Dynamic Table 中流动的数据。这个架构真正做到了实时离线分析一体化:统一的 SQL、统一的数据存储、统一的计算框架,并让数据在数仓中能够实时流动起来,因此我们称其为:Streaming Warehouse 即流式数仓,该架构有三个优势:
1. 全链路数据实现秒级和毫秒级的实时流动;
2. 所有流动中的数据皆可分析,没有任何数据盲点;
3. 实时离线分析一体化,用一套 API 完成所有的数据分析。
流式数仓 Streaming Warehouse(简称 Streamhouse)将是 Flink 社区后续重点演进的方向。
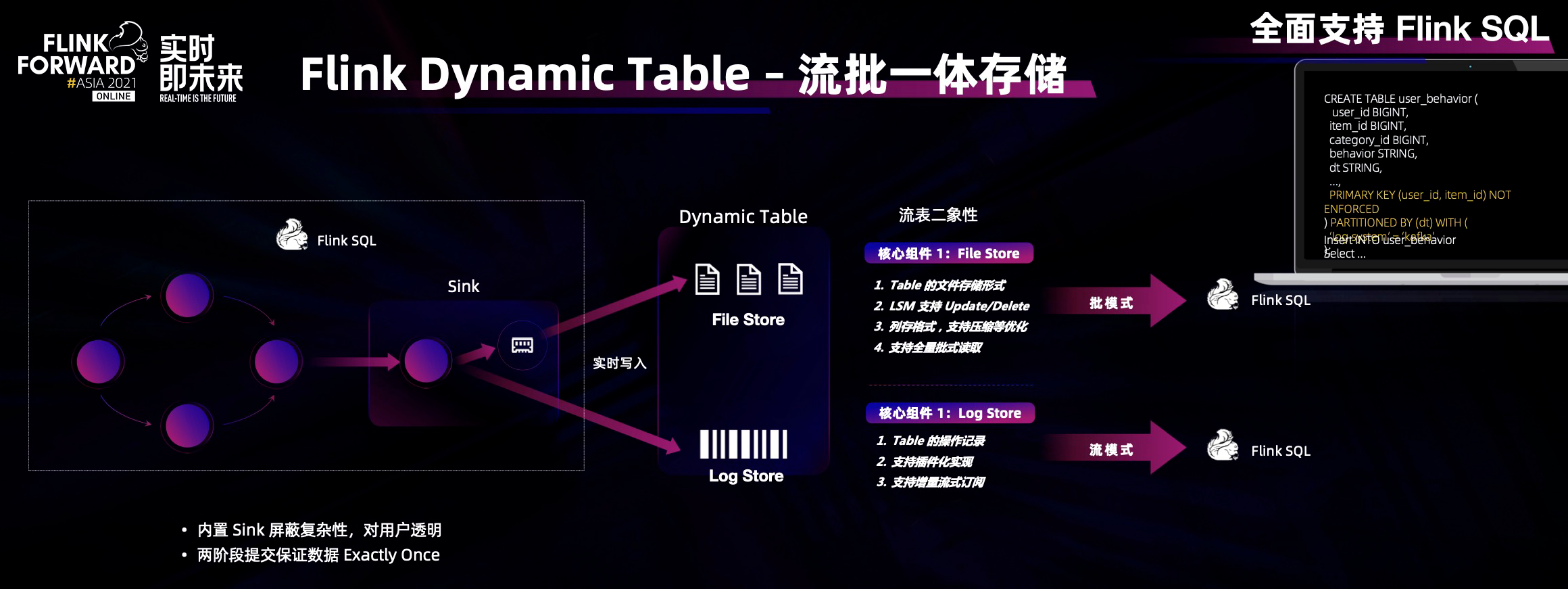
在 Streamhouse 之中我们引入了一个新的概念叫作动态表,可以把 Flink 动态表理解为一套流批一体的存储(Flink SQL / datastream 等都是 flink 流批一体的计算,Dynamic Table 对应流批一体的存储)。Dynamic Table 具备流表二象性,因此其在数据结构上有两个存储属性:第一个是 File Store,第二个是 Log Store。
顾名思义,File Store 存储 Dynamic Table 的持久化数据,采用经典的 LSM 架构,支持实时流式的更新、删除、增加等语义,同时采用开放列存结构支持压缩等高性能,可以对接 Flink SQL 批模式进行历史数据分析。
Log Store 存储 Dynamic Table 的变化序列,是一个不可更改的序列,可以对接 Flink SQL 流模式,通过订阅 Dynamic Table 的增量变化,进行实时分析。
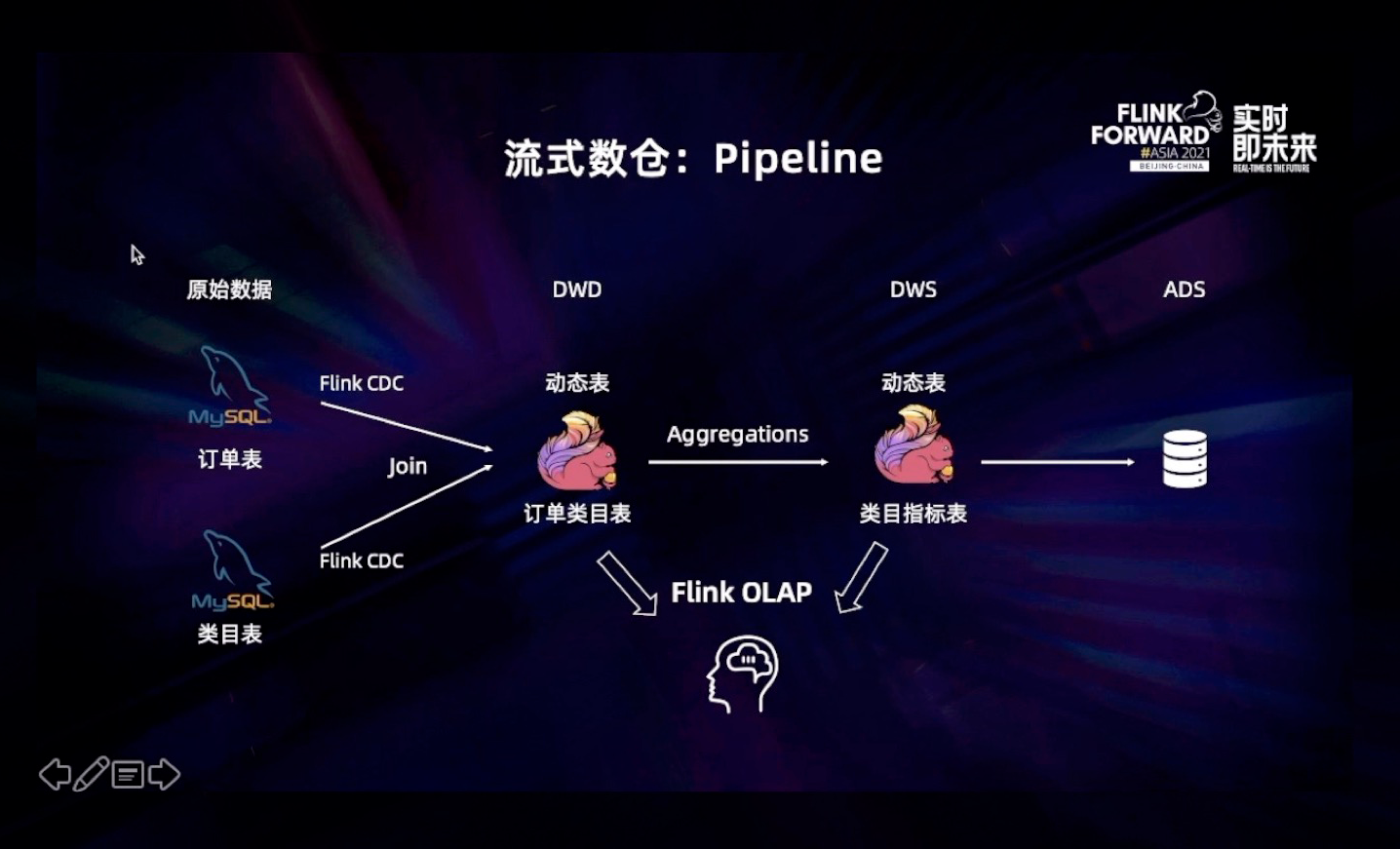
接下来,我们通过一段 demo 介绍如何利用 Flink CDC 和 Flink SQL、Flink Dynamic Table 构建一套完整的流式数仓,完成实时离线一体化的体验。
机器学习场景支持

接下来向大家介绍 Apache Flink 在机器学习生态的演进情况。Flink 的很多应用场景都与机器学习相关,比如互联网公司大量使用 Flink 做在线机器学习和离线机器学习,将 Flink 广泛应用于推荐,广告和搜索等业务场景。
今年借力 Flink 流批一体技术的演进和升级我们重构了 Flink ML 的基础框架升级为 Flink ML 2.0。基于新的流批一体 datastream API,构建新的迭代计算能力和 ML 算法,并将这个项目贡献到了 Flink 社区。与此同时,很多开发者或公司在 Flink 上贡献了很多机器学习生态的开源项目,比如阿里巴巴贡献的 deep learning on Flink,希望未来有更多的公司积极参与贡献。
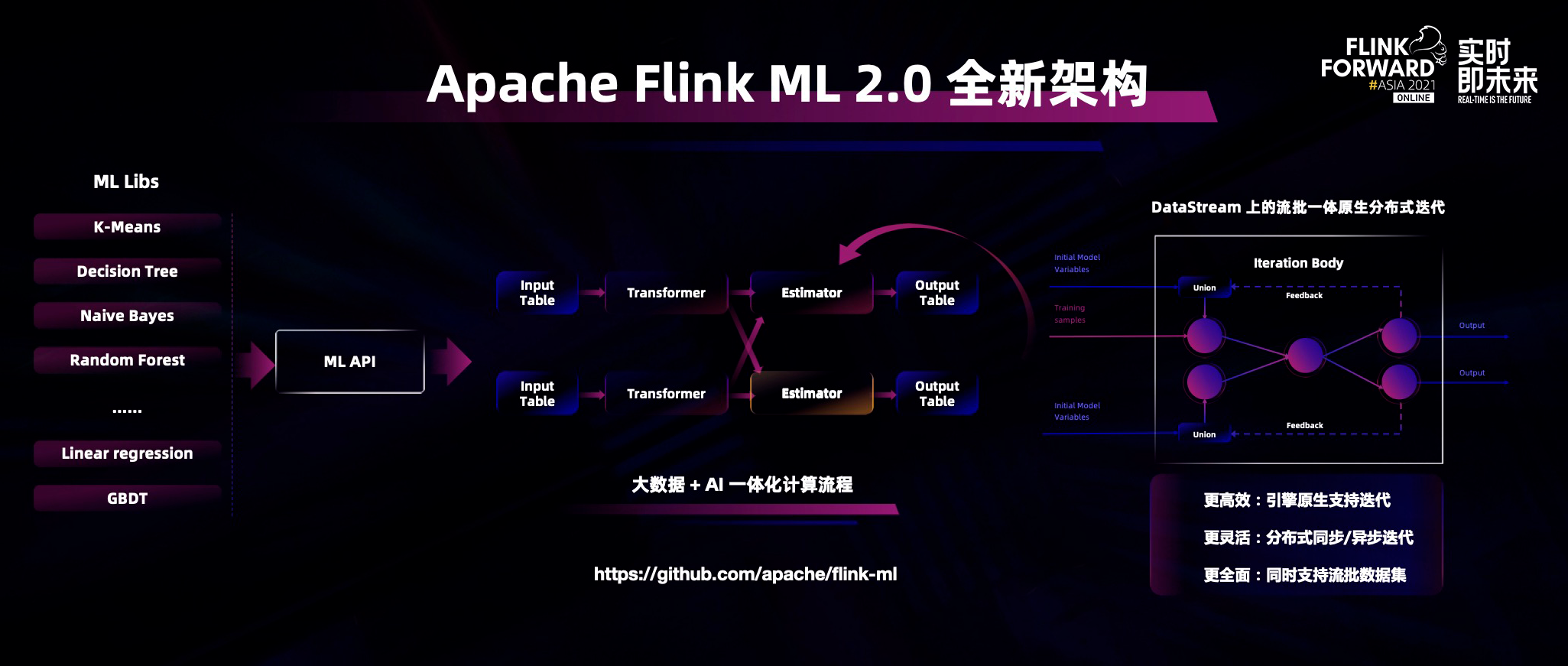
Flink ML 2.0 新架构
首先,机器学习架构是建立在流批一体的底层架构之上,因为新的 datastream 兼具流和批的处理能力,所以我们在 datastream 上构建了一套全新的迭代计算能力,这套迭代计算能力是 Flink 引擎原生的迭代计算能力,可以同时实现同步迭代以及异步迭代,让迭代的效率更加高效。Flink 的流批一体能力可以对接不同的数据源,包括流式数据源、批式数据源、不同的计算能力等等,令特征工程和模型训练变得更加高效。此外,新的 Flink ML pipeline API 也参考了经典的 scikit-learn 风格,让传统机器学习的开发者更方便的上手。
基于 Flink 自身大数据计算能力的优势,包括实时化、实时处理能力的优势,在这个架构下可以将数据清洗、数据预处理、特征计算、样本拼接和模型训练完全串联,形成一套高效的大数据+AI 一体化的计算流程,与此同时还可以兼容业界比较成熟的深度学习算法。
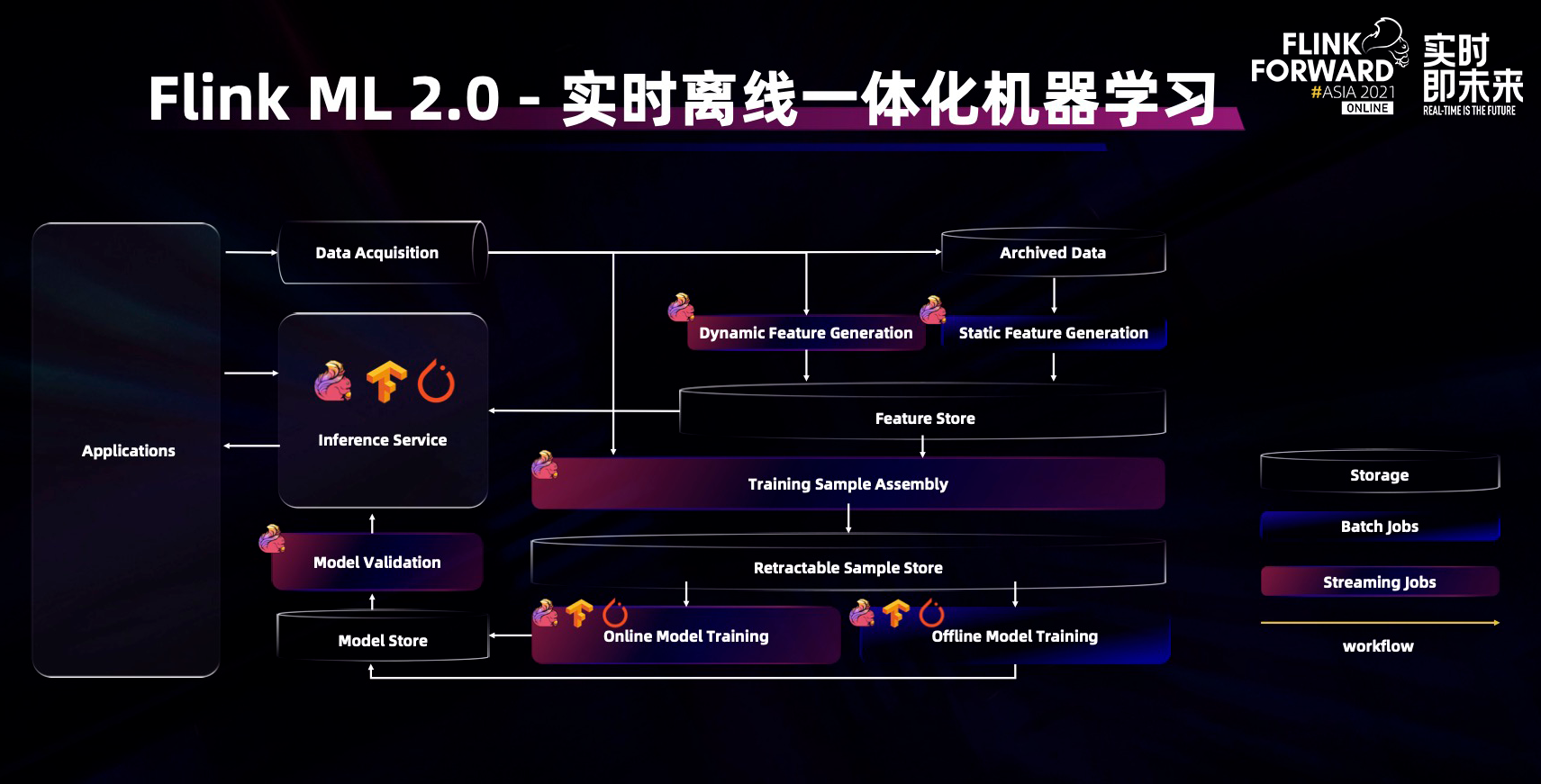
Flink ML 最大的特点是其框架可以兼容流式和批式的数据源,实现在线机器学习流程和离线机器学习流程一体化。目前,阿里巴巴的机器学习团队在陆续推进算法的贡献,希望以后有更多开发者或公司能够参与进来一起贡献。同时 Flink ML 可以嵌入主流的深度学习算法库,例如:tensorflow 和 PyTorch,创建全链路的深度学习流程。
整个机器学习流程中工作流的调度管理是大数据和 AI 的一个跨界问题。针对这个问题,阿里巴巴实时计算团队去年开源了一个项目叫 AI flow( https://github.com/flink-extended/ai-flow),这个项目可以围绕 Flink 实现从特征计算到模型训练、模型预测、模型验证全流程的管理调度系统。目前,业界已经有多家公司参与到这个项目的贡献和使用中,非常希望有更多的公司和开发者参与进来,共同推动生态发展。
Flink 社区经过最近几年的快速发展,技术创新仍在不断向前演进,从最初的流处理引擎向更加全面的流式数仓方向进化,并在数据湖、机器学习等大数据算力驱动的场景下发挥更大的价值。期待未来有更多的公司和开发者参与到 Flink 社区,共同拓展 Flink 生态进一步发展。
延伸阅读:




