
AI 训练场景的算力 Scaling 核心是网络,依赖于大规模、高性能的数据中心网络集群来实现算力的规模扩展,为此,阿里云设计了 HPN7.0 架构系统,基于 Ethernet 来构建超大规模、极致性能的网络互联。
本文整理自阿里巴巴资深网络架构师席永青在 AICon 2024 北京【大模型基础设施构建】专题的演讲“网络驱动大规模 AI 训练 - 阿里云可预期网络 HPN 7.0 架构”,内容经 InfoQ 进行不改变原意的编辑。
在 8 月 18-19 日即将举办的 AICon 上海站,我们也设置了【大模型训练以及推理加速】专题,本专题将全面剖析大模型训练和推理过程中的关键技术与优化策略。目前大会已进入 8 折购票最后优惠期,感兴趣的同学请锁定大会官网:https://aicon.infoq.cn/2024/shanghai/track
大家好,我是席永青,来自阿里云。阿里云的 PAI 灵骏想必大家都熟悉,已经是 AI 领域的标杆算力平台,服务了众多知名的 AI 大模型公司。我有幸负责灵骏智算集群网络架构设计。今天非常高兴有机会在 AICon 这个优秀的平台上与大家交流,希望能够与各位进行深入的探讨。
我在阿里云工作已经有近十年的时间,专注于数据中心网络架构和高性能系统的设计。从 2021 年开始,我专注于 AI 智算领域,负责智算集群网络的规划演进。在大模型还未如此火热之前,阿里云就开始设计 AI 计算的万卡集群。回顾整个过程,智算最初在自动驾驶领域应用较多,许多自动驾驶客户希望通过 AI GPU 集群进行视觉模型训练,在 2021 年阿里云就非常有远见地构建了第一代万卡集群,当时我们称为 HPN 6.0。
这几年来,从网络到 GPU、机器、整个 IDC,再到平台系统和上层 AI 模型框架,AI 基础设施领域的发展速度非常快。我有两点明显的感受:第一,随着 GPT 的爆发,我们几乎每天都需要更新知识库,虽然网络是底层技术,但也需要密切关注模型发展和框架变化带来的对网络使用上的变化,也包括 GPU 硬件更新迭代对网络互联和带宽的影响等。第二,集群规模的迅速变化,从一开始的千卡 GPU 到现在万卡十万卡规模,如果没有前瞻性的技术储备和规划,基础设施将面临巨大的挑战。
我今天要分享的内容主要分为四个部分,首先我会介绍高性能网络系统的发展历程以及它目前所处的阶段。接着,我会探讨在构建大规模 GPU 集群,比如万卡甚至十万卡集群时,对于网络来讲最关键的要素是什么。接下来,我将重点介绍阿里云 HPN 7.0 架构,它是阿里云 PAI 灵骏智算集群的核心网络技术。最后,我将展望以 GPU 为中心的基础设施及其高性能网络系统的未来发展趋势。
在座的可能有些是网络领域的专家,有些可能是更上层的系统、AI 平台或算法的专家,还有一些可能是 GPU 领域的专家,希望在今天的分享中,我能回答大家三个问题。第一个问题是网络对于 AI 计算意味着什么,网络在整个 AI 计算系统中扮演的角色以及它的重要性。第二个问题,如果你的公司正在做 AI 模型相关工作,无论是在构建大模型平台还是自行研发大模型,基础设施网络的方向应该如何选择。第三个问题是,一旦确定了网络方向,网络方案和一些关键技术点应该如何实施。
高性能网络系统进入可预期时代
让我们回顾一下网络的整个发展历程。在 2000 年左右,互联网刚刚兴起时,网络主要是由设备供应商提供的基础设施,用于支撑 IT 业务系统。那时,数据中心开始起步,电商业务如淘宝,搜索业务如百度、Google 等开始规模化使用数据,产生对数据中心大规模计算的需求。那时,数据中心内部主要使用 TCP 协议,那时的 TCP 能够满足算力连接服务的需求,随着摩尔定律的持续推进,CPU 不断升级,TCP 的能力也随之提升,网络并没有成为瓶颈。
随着云计算和大数据的兴起,网络进入了第二个发展阶段。在这个阶段,因为集群规模的扩大,网络的规模和稳定性要求以及带宽需求都在增加。这时,网络进入了软件定义网络(SDN)的时代,这是许多网络专业人士都熟悉的一个时代,诞生了许多新技术,也涌现了许多网络领域的创业公司。
随着云计算数据中心的进一步扩大,AI 智算时代逐渐到来。智算集群与传统云计算数据中心有很大的不同,它对网络的要求也截然不同。这也是我接下来要分享的重点,希望带大家了解为什么在 AI 数据中心中,网络如此重要,网络在其中扮演了多么关键的角色。我们目前正处于第三个阶段,这个阶段的网络技术架构的发展将决定 AI 计算规模化发展的趋势,这是接下来讨论的重点。
在讨论集群算力中网络所扮演的角色之前,我们首先需要明确 AI 基础设施的关键要求。对于 AI 基础设施来说,一个至关重要的要求是训练时间。训练时间对于业务创新至关重要,因为它直接关系到公司是否能高质量得到 AI 模型,是否能快速将产品推向市场,同时这个过程中训练时间所带来的创新迭代效应也将更加明显。
训练时间的关键因素包括模型的时间加上中断时间。其中模型训练的时间,与整体计算量有关,在模型、数据集确定的情况下,这是一个固定值,这个算力需求的总量,除以集群的算力,就是模型训练的时间。此外,还需要考虑中断时间,这可能包括模型调整、数据调整或因为故障导致的训练暂停从而从上一个 checkpoint 恢复。
集群算力与通信效率密切相关。组成 AI 训练集群的千卡、万卡 GPU 是一个整体,所有人在协同完成同一个计算的任务。我们往往通过增加 GPU 的规模来增加集群的总算力,比如从 1000 张 GPU 增加到 2000 张、4000 张,整个集群所表现出的算力是否还能保持“单 GPU 乘以 GPU 数量”的算力,这是我们通常所说的线性比。这个线性比怎么做到最优,核心是通过高性能的网络系统来实现的。如果网络出现问题,哪怕是影响到一块 GPU 的网络问题,都会导致整个集群的任务变慢或者停下来。因此,网络在“集群算力”中扮演着至关重要的角色,它不仅关系到算力的线性扩展,还直接影响到训练任务的稳定性和效率。

AI 计算中的通信模型与传统计算有着显著的不同。AI 计算过程是迭代,包括计算、通信、同步,然后再回到计算。以模型训练过程为例,首先将模型所需的数据加载到 GPU 上,然后 GPU 进行前向计算、反向计算,在反向计算完成后,关键的一步是同步模型收敛的梯度参数到每一个 GPU。这样,在下一轮的数据训练开始时,所有的 GPU 都能够从最新的模型参数开始迭代,这样将整个参数收敛到我们期望的结果。
在这个过程中,网络要做的核心工作对梯度进行全局同步。在每一轮的迭代计算中,都需要将梯度数据同步。而图中蓝色部分所表示的,正是网络所承担的工作。网络负责在各个 GPU 之间传输和同步这些梯度数据,确保每个 GPU 都能够接收到最新的模型参数,从而进行有效的并行计算。
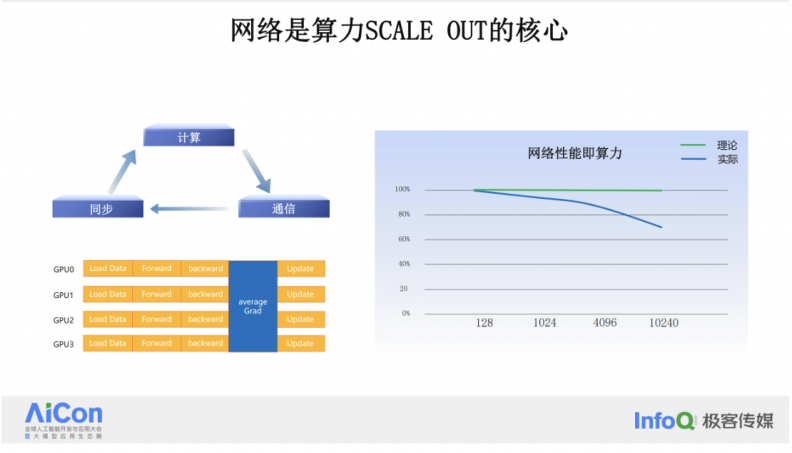
网络在 AI 计算中的重要性体现在它对算力规模扩展的影响上。当算力规模扩大时,如果网络的线性比下降,实际体现出来的算力也会随之下降。如果我们将 GPU 的数量从 128 张增加到 1024 张、4096 张,再到 1 万张,理想情况下,只要扩展 GPU 规模,就能获得相应的算力提升。但实际情况往往并非如此。网络在梯度同步过程中需要时间,这个时间的长短直接影响到 GPU 在计算过程中的等待时间,尤其随着规模的扩展,梯度同步所需要的网络交换数据量也会变大,网络通信的时间也会变长,相当于损失了 GPU 算力。好的网络架构设计,高性能的网络系统,可以做到随着规模的增加仍然保持较好的线性比,充分发挥大规模 GPU 的算力,网络性能即规模化的算力。
GPU 集群对网络的关键要求
传统网络集群设计不再适用 AI 计算
在 AI 计算中,GPU 集群对网络有着更高的性能要求,希望网络在算力扩展过程中能够保持高效的通信。这引出了一个问题:GPU 集群对网络提出了哪些关键要求?
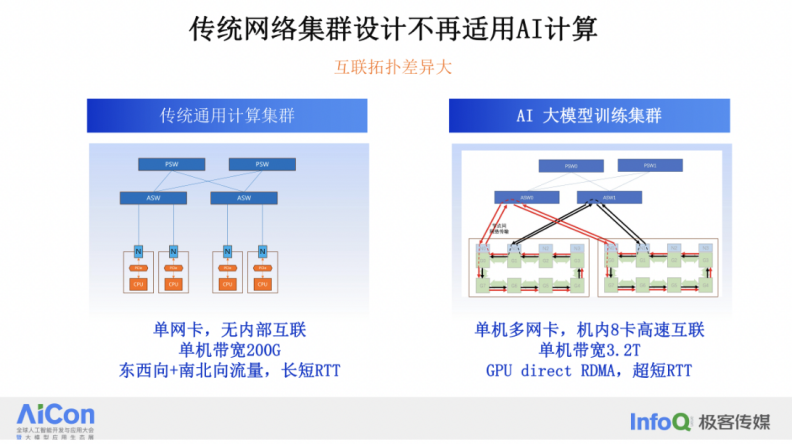
首先,我们可以得出一个结论,即传统的网络集群已不再适用于 AI 计算。过去 20 年左右,数据中心的核心算力主要来自 CPU。如果我们观察 CPU 系统和网络系统的组成,可以发现几个特点:CPU 系统通常是单张网卡的,从 CPU 通过 PCIe 到网卡出口,内部没有特殊的网络互联。CPU 系统的单机带宽最大到 200G 就已经足够,因为它们主要服务于 APP/Web 类型的应用,这些应用需要进行互联网访问和数据中心内机器的协同工作,处理各种流量。
GPU 网络的情况已经发生了很大变化。每个 GPU 都有自己的内部互联,例如 NVIDIA 的 A100 或 H800,它们内部的 NVLink 互联可以达到 600GB 甚至 900GB。这种内部互联与外部以太网网络集群设计之间存在耦合关系。GPU 是单机多网卡的,单机内的多张网卡之间有高速互联,单个服务器的带宽可以达到 3.2T,与通用 CPU 计算带宽相比至少有 6 到 8 倍的关系。GPU 需要使用 GPU Direct RDMA 来实现显存之间的数据迁移,并且需要超短的 RTT(往返时延)。
因此,在 AI 场景下,传统的数据中心集群设计很难发挥其作用。GPU 集群需要网络能够支持更高的带宽、更低的延迟和更高效的通信机制,以满足 AI 计算的需求。
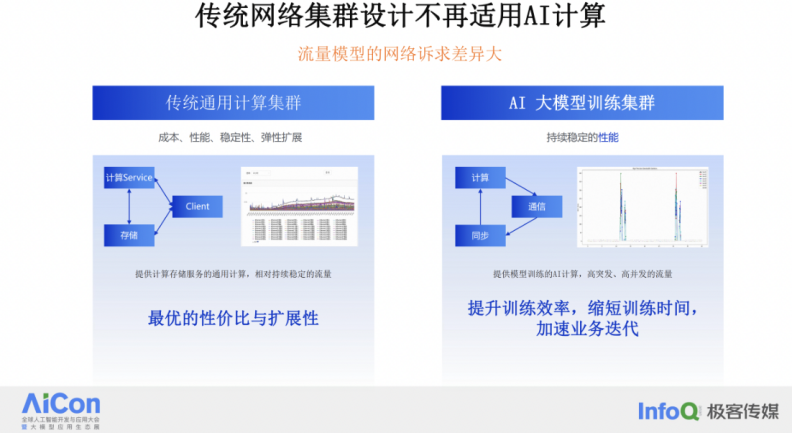
在传统的数据中心集群中,任务模式通常包括计算、存储以及客户端 / 服务器服务。这些服务之间需要建立大量的会话连接来交换数据,而这些连接的数量通常取决于用户量和负载等因素。因此,这些连接的数量很高,流量趋势会随着业务负载的变化而变化。例如,在淘宝上,网络流量的高低峰与交易高峰密切相关。
而在 AI 计算中,特别是在模型训练过程中,网络表现出的是周期性的行为。计算、通信和同步循环是连续不断的过程。例如,一个 400G 的网卡在每一轮计算迭代的通信部分可以在瞬间将网络带宽用满。
网络的任务是尽可能缩短计算的等待时间,这样,GPU 就可以更充分地发挥其 Tensor Core 的能力来进行计算任务,而不是浪费在等待数据同步上。所以在 AI 模型训练任务中,尤其是在大型 AI 模型的训练中,网络表现出的特点是高并发和高突发流量。
在讨论网络连接数量的特点时,我们可以看到通用计算和 AI 训练集群之间存在显著差异。在通用计算中,采用的通常是客户端 / 服务器模式,连接数量与用户的请求量和业务模型的设计紧密相关,可能会非常大。例如,一台服务器上可能有高达 10 万级别的 HTTP 连接。
在 AI 训练集群中,一个网卡上的连接数量却非常固定,通常只有百级别连接。从训练任务开始的那一刻起,每一轮对网络的操作都是相同的。在每个循环中,活跃的连接数量以及所需的连接数量都非常少。连接数量少在网络上可能会引起 HASH 问题,这是我在后续讨论 HPN 7.0 设计时会重点提到的一个关键问题。HASH 问题是目前网络领域在 AI 计算中需要解决的核心问题之一。简单来说,连接越多,熵就越大,在选路径时分散均衡的概率也更大。而当连接数量减少时,HASH 问题就会变得更加明显。
AI 集群高性能网络系统关键要求
当我们深入探讨 AI 网络系统时,如果从端到端的角度审视 AI 系统的网络构成,我们可以发现在 AI 训练过程中,有三个非常关键的组件。
集群架构设计:集群架构虽然看起来只是一张拓扑图,但实际上它决定了物理带宽的使用和路径的简化程度。这个架构直接影响到模型训练过程中的网络 HASH、时延和带宽。就像城市规划中的道路规划一样,只有设计得当,交通(在这里比喻为数据包)才能高效运行。
端到端传输协议:它决定了数据包在网络中的传输效率。就好像交通网络的效率,需要每辆车都足够安全足够快,同时也要避免交通拥堵的发生。传输协议需要考虑传输效率、重传、流控等因素以确保高效传输。
监控运维和资源管理系统:虽然在今天的分享中不会详细讨论,但这个系统非常关键。整个系统依赖于监控运维的能力进行快速的问题发现,性能分析,和问题解决。

在 AI 计算网络设计中,如果我们将前述的三个部分进一步拆解,会发现在 AI 训练过程中,网络有四个关键点。
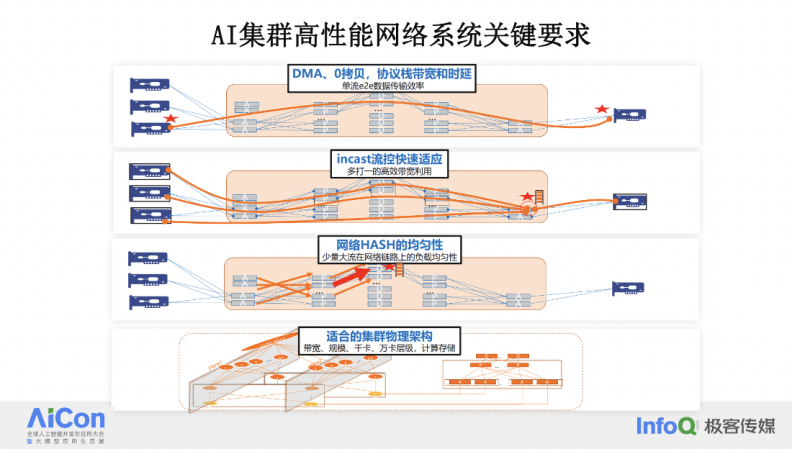
集群架构设计:合理的集群架构设计是重中之重。这个设计决定了带宽和规模能达到的程度,比如是连接千卡、万卡还是 10 万卡,带宽是 3.2T、6.4T 还是更大,网络层级是一层、两层还是三层,以及计算和存储的布局等。这些因素都会影响 AI 训练中迭代时间或每秒样本数。
点到点传输协议:在集群设计的基础上,点到点之间需要使用最快的协议来实现梯度传输。这要求协议能够实现直接内存访问(DMA),减少拷贝操作,实现大带宽和低延迟。目前,无论是 RoCEv2 还是 IB,DMA 技术已经实现了这些能力,协议栈已经写入硬件,实现了零拷贝操作。
incast 问题:在训练通信过程中,会出多对 1 的数据交互场景,这会导致尾跳网络出口成为瓶颈。如果没有有效的流控方法,这会在网络出口形成队列堆积,导致缓冲区溢出发生丢包,严重影响通信效率。流控的目标是保持缓冲区的能力足够不会溢出,同时确保流量带宽始终 100% 输出。
网络 HASH 问题:由于 AI 计算流量波动大,带宽高,瞬间可以打满一个 400G 端口,但流的数量又非常少,这使得网络路径上的 HASH 不均匀的概率很大,这导致中间路径的不均衡,产生丢包、长尾,影响整体通信效率。
在 AI 训练中,长尾问题是非常明显的,它具有木桶效应。如果在一个迭代中有 1000 张卡,其中 999 张已经传输完毕,但有 1 张卡的梯度传输慢了,那么整个训练过程都要等待这张卡。因此,无论是 HASH 还是流控,目标都是补齐木桶的短板,充分利用带宽的同时降低长尾,确保整个网络能够实现高带宽、低时延和高利用率的统一状态。
阿里云 HPN 7.0 架构:AI 计算网络集群架构演进
在审视了 GPU 集群对网络的关键要求之后,让我们来探讨阿里云的 HPN 7.0 架构是如何解决这些问题的,以及它是如何提高模型训练的效率,达到更极致的性能。
阿里云从去年年初开始设计研发 HPN7.0,在去年 9 月份上线规模化,是专为 AI 设计的高性能计算集群架构。这个架构的特点是单层千卡、两层万卡,存算分离。
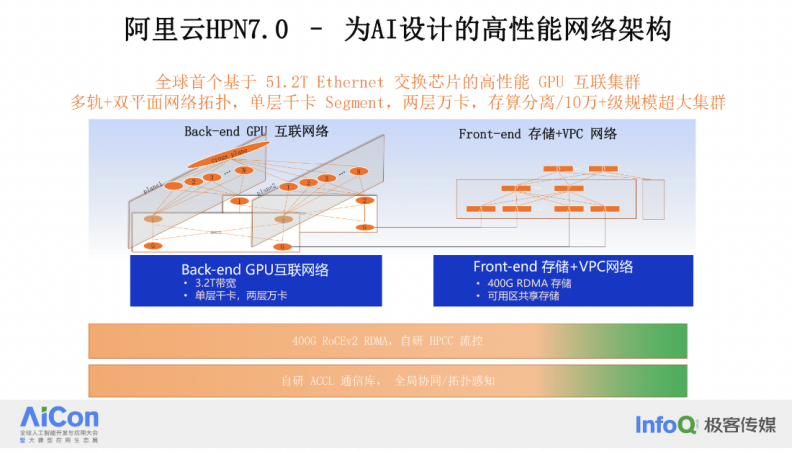
千卡 Segment 设计:我们实现了一个设计,允许 1000 张 GPU 卡通过单层网络交换完成互联。在单层网络交换中,由于是点到点连接,因此不存在 HASH 问题。在这样一个千卡范围内,网络可以发挥出极致的性能,测试结果表明,这种设计下的计算效率是业界最优的。
两层网络实现万卡规模:通过两层网络结构,我们能够支持多达十几个千卡 segment,从而实现万卡规模的网络交互。两层网络不仅减少了时延,还简化了网络连接的数量和拓扑。在三层网络结构中,端到端的网络路径数量是乘数关系,而两层网络只有两跳,简化了路径选择,提高了哈希效果。
存算分离。计算流量具有明显的规律性,表现为周期性的波动,我们的目标是缩短每个波峰的持续时间,而存储流量是间歇性的数据写入和读取。为了避免存储流量对计算参数同步流量的干扰,我们在设计中将计算和存储流量分配在两个独立的网络中运行。在最近的 GTC 大会上,有关网络设计是采用一张网还是两张网的问题进行了深入探讨。北美几家主要公司的 AI 基础设施网络负责人都参与了讨论,并得出了一致的结论,即分开两张网是最佳选择,这与我们的设计原则相符合。
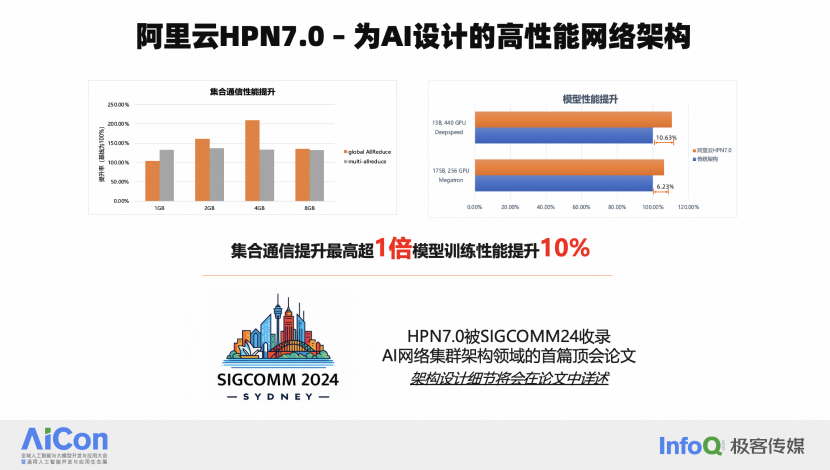
值得一提的是,HPN 7.0 架构,在两周前被选为国际网络顶会 SIGCOMM 的论文。SIGCOMM 是网络领域内最顶级的会议之一,每年仅收录大约 50 篇论文,这些论文都是由网络领域的全球顶尖专家的创新和实践成果。阿里云的 HPN 7.0 架构论文被选中,这具有重大意义。在 SIGCOMM 上发表关于网络架构设计的论文是相当罕见的。上一篇与网络架构相关的论文是 Google 的 Jupiter 网络,第一代 Jupiter 网络在 2015 年发布,第二代则是在 2022 年发表。而 HPN 7.0 的发布标志着 AI 领域内第一篇网络架构的国际顶会论文的诞生,会成为 AI 领域网架构设计的标杆。
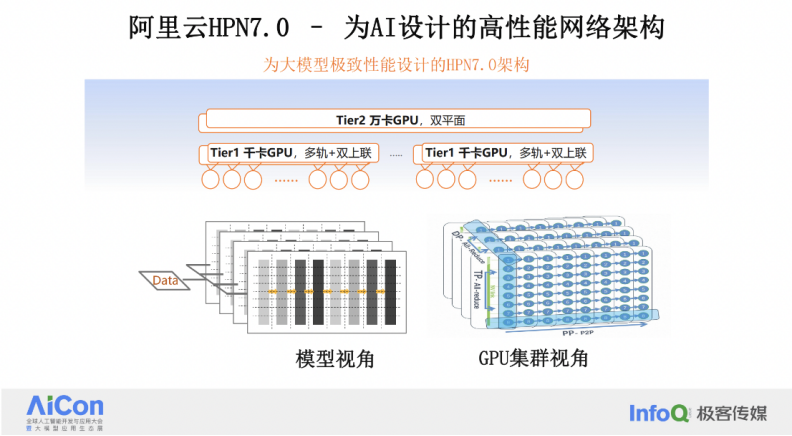
在 HPN7.0 架构下,我们可以通过流量排布,来优化模型训练过程。从 GPU 的视角来看,在整个网络映射过程中,我们可以看到在 1 千卡的范围内,DP 过程可以在千卡范围内完成,无任何网络 HASH 导致的问题。PP 流量较少,可以让其跨越不同的 segment 进行传输。这样的设计使得带宽的利用率能够与模型训练过程紧密结合,从而实现更优的性能。
HPN 7.0 在端到端的模型训练性能上取得了显著提升,测试数据显示性能,模型端到端的性能提升超过 10%。除了软件架构的优化,HPN 7.0 的硬件和光互联系统也是其成功的关键因素。我们采用了基于阿里云自研的 51.2T 交换机,和 400G 光互联。
GPU centric 高性能网络系统未来展望
展望未来,高性能网络系统的发展将指向一些明确的方向,这些方向已经随着 AI 基础设施的变革而逐渐显现。从最近 GTC 的发布中,我们可以感知到这一变革的脉动。变革将涵盖从数据中心的电力设计、制冷设计,到网络互联的 scale out 和 scale up 设计等多个方面。
从物理层面来看,未来的数据中心将面临更高的功率密度。例如,以前一个机架(Rack)可能只有 20 千瓦的功率,但未来的机架可能达到 50 千瓦甚至 100 千瓦。这样的高功率密度将带来散热方面的挑战,因此,液冷技术将成为必须采用的解决方案,包括交换机在内的设备都将采用液冷技术。
GPU 之间的内部互联,如 NVLink 也将在机架内部甚至更大范围内进行扩展,以支持 scale up 的扩展需求。这种 scale up 的扩展需要与网络的 scale out 扩展紧密结合,以确保整个系统的高效性和可扩展性,这也是业界最热门的互联创新话题。

面向未来,我们面临的规模挑战将更大。随着 scale up 网络的发展,我们可能会看到从当前的 8 卡配置扩展到 72 卡或更多,这样的扩展会对网络拓扑带来变化,从而影响 scale out 群网络架构的设计。包括通信框架、容灾设计,以及电力和物理布局等方面都将发生显著变化。这些变化指向了一个以 GPU-centric 的数据中心设计理念。
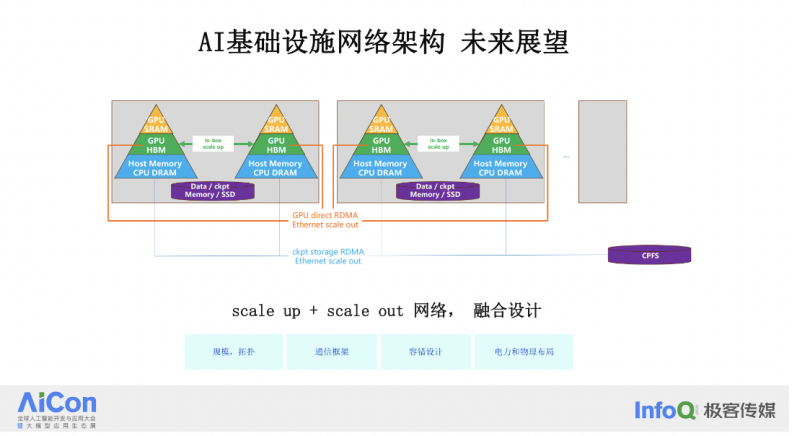
此外,网络技术的发展正朝着更高的单芯片交换能力迈进,未来一年内,我们有望看到阿里云的 HPN 8.0,它将是基于 100T 芯片的下一代架构。从 SCALE up 与 SCALE out 结合的架构设计、硬件设计,到液冷系统、IDC 设计的结合,端到端的 AI 基础设施发生变化,以网络设计为中心的 GPU-centric 基础设施时代已经到来。
高性能网络协议也将针对 AI 计算持续演进。为了推动这一进程,业界已经成立了超级以太网联盟(UEC),近期阿里巴巴入选该联盟决策委员会,是决策委员会中唯一的一家中国公司,接下来阿里云将在 AI 基础设施网络的高性能方向上重点投入,与各主要公司一起,共同致力于下一代更高性能网络系统的设计和开发。
活动推荐:
InfoQ 将于 8 月 18 日至 19 日在上海举办 AICon 全球人工智能开发与应用大会,汇聚顶尖企业专家,深入端侧 AI、大模型训练、安全实践、RAG 应用、多模态创新等前沿话题。现在大会已开始正式报名,6 月 30 日前可以享受 8 折优惠,单张门票节省 960 元(原价 4800 元),详情可联系票务经理 13269078023 咨询。





