上一篇文章中,广发证券的首席架构师梁启鸿先生论述了云计算对于金融系统的意义,如他所说,云计算的出现,有利于帮助IT 构建强韧系统,并且让“反脆弱”系统成为可能。伴随云计算出现的是DCOS、APM、Infrastructure As Code、DevOps 等等技术方案、技术产品、技术理念和方法论。这些都是构建强韧系统的有力武器,而在云计算时代之前,它们严格意义上不曾存在过。
在本篇文章中,作者将会接着前文继续聊如何让云计算在证券系统中落地,以及容器技术对于金融系统的弯道超车机会点在哪里。另外,如果你对容器技术感兴趣,不要错过InfoQ 主办的 CNUTCon 全球容器技术大会。
云计算,其中一个最基本目的,是计算资源的集合管理与使用。其实 IT 界在计算资源的集合使用方面,过去 20 年起码尝试过三次:
- 90 年代中后期,出现网格计算(Grid Computing),用于蛋白质折叠、金融模型、地震模拟、气候模型方面的应用。
- 本世纪初,出现效用计算(Utility Computing)- 推行运算资源按需调用(On-demand)、效用计费(Utility billing)、订户模式(Subscription model)的概念。IBM、HP、Sun 这些 IT 公司都尝试推动过这个领域的解决方案,虽然成效不彰。
- 10 年前,亚马逊 AWS 发布,算是云计算的标志性事件。云计算覆盖含义更广,网格计算可以是云计算平台上的一类应用,而效用计算则可以被视为云计算服务商所采用的商业模式
华尔街可以算是网格计算商业化产品的积极使用者 – 不少投行采用诸如 Gigaspaces、Gemstone、GridGain、Terracotta、Oracle Coherence(原 Tangosol)这些商业技术开发它们的交易系统,实现低延迟、高并发并且支持事务的技术架构。这些技术一般来说比较“重”- 有复杂的中间件、使用者需要去适应一整套的开发理念和掌握专门的框架、编程模型“入侵性”比较强(intrusive),开发者与应用架构均被迫需要去适应它们。
云计算和大数据技术出现后,这些技术逐渐变身“事务型内存数据库”、“内存网格”(in-memory data-grid)、“流式计算平台”(stream processing)等等,然总体来说变的越来越小众。无论如何,这些技术在云计算出现前已经帮助华尔街机构掌握了计算资源集合运用、分布式架构的一些理念和思维。而国内证券界甚至金融业 IT 总体来说,对这类技术是相当陌生的。
就对标华尔街同行的证券业 IT 而言,可以说基本上错过了上述计算资源集合应用的三个浪潮。云计算兴起后,OpenStack 之类的技术在证券 IT 甚至金融界的成功落地、大规模采用的案例极其罕有(如果有的话)。即便是近年来互联网云服务商兴起,部分金融机构因为试水互联网金融而开始使用公有云,很大程度上使用方式也不过是使用了一些虚拟机运行一些互联网边缘(Edge)服务。
然而这个时代有趣的地方在于,一些新技术的出现可以让“弯道超车”、“后发制人”成为可能 – 上一个阶段错过了一些东西,但是也可能下一个阶段少了很多历史包袱从而可以轻易跳进最新的技术世代。容器,恰好就是这么一种技术 – 假如你能把握的话。
在英语里,“容器”、“集装箱”、“货柜”都是同一个字 – Container。容器技术之于软件业,很有可能可以类比集装箱对运输业的巨大影响。
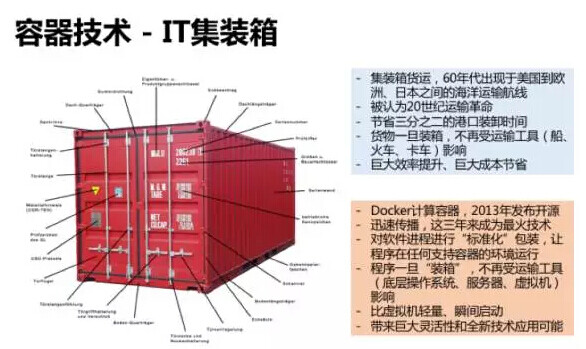
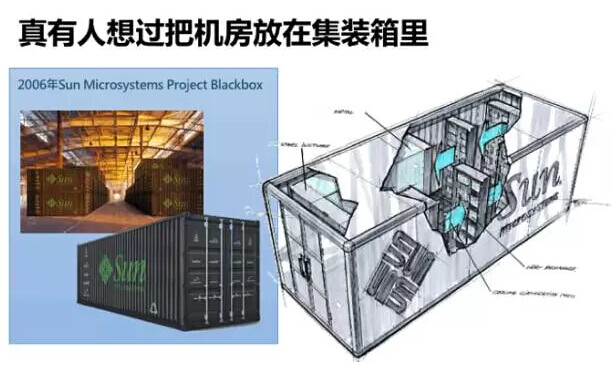
实际上,确实有人想过把整个机房放在集装箱里,例如 2006 年 Sun Microsystems 推出的 Project Blackbox –刚好是亚马逊发布 AWS 的同一年。但这个集装箱是钢铁的、有物理形体的、重量以吨为单位的;而其中的内容,自然也是各种物理的服务器、网络设备、发电机。那一年,可能谁也没有想到,10 年后有一种“数字化”的虚拟集装箱大行其道。
技术界不乏认为容器对软件技术产生革命性影响的观点,本人倾向于认同这种观点,因为:
- 容器影响开发者的开发方式、开发习惯,“强迫”他们去思考例如无状态的服务、业务逻辑粒度的控制、资源的弹性伸缩、应用代码的发布形态、系统里面每一个细节的可监控性等等。
- 让真正的 DevOps 成为可能 – 自动化测试、持续集成(CI)、持续交付(CD)、自动化部署、无人值守的运维… 开发与运维的角色差异进一步缩小,而效率则最大程度提升。
- 让“不可变基础设施”(Immutable infrastructure)成为可能 – 这将颠覆传统软件系统的升级发布和维护方式。
关于容器与虚拟机的区别,不在本文展开论述 – 业界有足够多的技术文章供参考。在此仅陈述一下,为什么作为金融系统、交易平台的研发者,我们挑容器出现的时候跳进云计算,而在更早阶段虚拟机系列相关技术成熟时却并没有大的投入。
最根本原因在于,作为研发组织,我们从研发视角,基于具体应用场景去持续、积极寻觅能解决强韧性、健壮性问题的解决方案 – 这是一种“Top-Down Thinking”,例如在交易量波动过程中,我们能否有自动化的技术去可靠的应对、实现计算资源的弹性伸缩并且保持超级高效?有什么技术可以帮助我们解决复杂交易系统发布、升级、打补丁的危险和痛苦?交易故障出现时系统内部防止雪崩效应保持快速响应的“熔断”(circuit-breaker、fail-fast)机制有什么更规范的做法?用现有云计算的理论和技术倒着去套,显然是无解的,因为:
- 虚拟机级别的资源调度,太沉重,可编程接口太弱,无法“融入”到一个高性能运算(HPC – High Performance Computing)的应用中。
- 仅仅为了资源的弹性伸缩,去引入一个第三方解决方案,例如一个 PaaS(诸如 CloudFoundry、OpenShift 等),对于交易系统而言,代价太大、可控性太低、编程模型受入侵程度太高。
- 不是为了云计算而云计算 – 一切“革新”需要合理、充分的应用理由,场景不符合,架构就不合理。
“Bottom-up Thinking”,即从基础设施的可管理、资源充分共享、运维更高效等角度去看问题,是一个典型的“运维”视角或者所谓 CIO 的视角,这种思考,关注的是 TCO(Total Cost of Ownership)- 成本的降低(IT 在垂直行业一直被认为是一个成本中心 – 在现在这个时代这是一个错误观点,但这是另一篇文章的讨论范围了);可是和核心业务应用非常脱节。
对于一个传统行业尤其是受监管行业的 IT 而言,技术氛围往往是保守和审慎的,采用云技术这种在互联网界以外还很大程度被认为是“新生事物”的东西,并不是一件容易的事情:在行业繁荣、企业赚钱的时候,公司很可能并不关注运维除了稳定以外的事情 – 包括用虚拟机还是用物理机、能否节省一点成本等等;在市场不景气、公司亏钱的时候,IT 却又需要以非常充分的数据来证明建立或者采用云平台能带来显著的大幅的成本节省效果,但是这往往首先涉及第三方软件的采购、机房的改造… 这本身就是一个巨大障碍。
所以,悲观一点的看,很大一部分传统行业 IT,很可能需要等到云技术成熟为新世代 IT 系统的标配,就像 mainframe 时代向 client-server 时代转变、client-server 时代向多层架构 /web 技术时代切换,云技术成为一个主流的、企业决策者不再需要加以思索的事物(“no-brainer”)时,才会顺利进入企业世界。此时,运维的视角也许才能被充分接受。但是,对于以创新为本业的金融科技,那已经太迟。
早期的云技术,从运维视角去看是自然的,因为虚拟化技术最开始是把基础设施数字化的一个进程。容器化技术的出现,改变了这一切。容器天然与应用服务结合的更紧密、天然需要程序员的深度介入,“上帝的归上帝,凯撒的归凯撒”,容器里面的归程序猿(code monkey),容器外面的归运维狗(watchdog) - 不一定对,只是作为笑话简单粗暴的类比一下,但想说明的是容器内外的关注点是不一样的、而运维与研发的协同则是深度的。
在 Docker 刚出现的时候,一直带着前述问题的我们,从其理念已经体会到容器技术对构建一个强韧交易系统的好处。

交易系统,无论是股票交易、债券交易、期货交易、外汇交易还是多资产投资交易,本质上是一种非常专业的软件系统。在华尔街,它很有可能是某家投行作为自身的核心技术进行研发的;在国内,由于绝大部分券商缺乏开发能力,它更有可能是由某些第三方厂商作为商业软件的半成品进行维护和订制的。但是无论国内外,其作为软件系统都缺乏商业软件(COTS – Commercial Off-the-Shelf)的“专业性”,例如:
- 和 Oracle、IBM 等的数据库及中间件套件比对:通常缺乏安装工具。重新部署一套,需要一帮熟悉该交易系统的工程师,费九牛二虎之力去部署。使用完也不敢、不舍得轻易舍弃。即便是后来虚拟机出现,让安装工作可以部分重用,依然是一个高难度技术活,不是张三李四可以在生产环境(通常多个)、测试环境(起码两位数字个数)、开发环境(N 个)可以随意低成本复制的。
- 和 Redhat、Windows 比对:通常没有补丁工具,任何补丁都需要手工、半手工的去打。在 Docker 出现之前,我们一直在想,为什么交易系统不可以实现一个类似 apt-get 或者 yum 的工具,能列出已打的补丁、能获取最新的补丁包、甚至能管理和删除一些补丁包?
- 和例如 WebLogic JEE 应用服务器以及很多商业中间件相比:通常交易系统里非常复杂的系统级的底层配置(非业务参数设定)只能手工进行,因为开发者(包括开发商)并不愿意投入时间资源去开发提供非常专业的可视化配置工具。尤其是很多交易系统是开发商从小系统逐步摸索开发出来的,很多东西并无考虑,也没有把多年累积的经验教训抽象好,经常只能手工“优化”。
- 和领先的互联网技术平台比:金融业的应用(不仅限于交易系统),可能都没有好办法实现滚动发布、灰度发布、在线升级、多版本在生产环境并存、回滚 - 一个以关系型数据库为主导的系统,是很难做到这些的。
结论就是,传统交易软件缺乏专业商业软件的“专业性” – 开发商通常缺乏大型软件公司(如 Oracle)的软件工程能力、缺乏“packaged solution”的思维、缺乏对其客户在运维方面遭遇到的实时挑战的认识(想象一下日交易量达到十几亿手时的券商机房和里面的“救火”团队)。显然,这样的软件系统,是一个“脆弱系统”,是无法应对黑天鹅挑战的。
容器技术的到来,让我们在观念上“弯道超车”:
- 在软件安装、发布方面,我们还需要去学习、模仿 Oracle、IBM 们研发什么工具吗?不需要了 – 采用容器、容器编排技术、容器镜像管理技术、容器目录(catalog),我们轻易的“一键发布”,而且谁都可以执行。
- 在打补丁方面,我们还要去参考 Redhat 开发个升级工具吗?没必要了,因为我们不打补丁,已经发布的容器里内容永远不会改变(Immutable),需要修复缺陷或者升级版本,我们就发布新容器 – 发布组件乃至整个全新交易系统,成本都是很低的(并且必须永远维持那么低)。因此,我们也不一定需要什么中心化的、统一的、集中的可视化配置管理工具。
- 灰度发布、在线升级、多版本生产环境、回滚现在都是容器化系统天然自带的 – 因为整个系统的发布、部署是低成本的和快速高效的,只要有硬件资源就再发布一套,不行就切换回旧的那套 – 技术界已经在不断总结最佳实践,总有一款套路适合你。基于容器的微服务,天然支持多服务版本并存;对于回滚,数据库可能是个问题,但首先一切以数据库为中心就是个很有可能是错误的观念(当然,视应用场景而定),在分布式架构里,关系型数据库有可能不在系统关键路径上、事务有好些办法可以规避、通过很好的面向对象设计解耦内存与持久层的耦合… 实际上,经验告诉我们,关系型数据库被滥用是企业应用软件的通病。
而比解决运维问题更有趣的,是这几方面:
- Infrastructure As Code – 现在总算不是口号了,对着容器、容器编排技术进行编码,让“无人值守”、“智能运维”真正成为可能。虽然 Puppet、Chef、Ansible 这些技术早就存在,但是它们基本上仅限于操作基础设施的物理、虚拟资源,与一个专业应用系统通过 API 深度结合然后基于业务场景、系统业务指标来自我维护,是非常困难的。而容器,基本上只是一个进程,通过其 API 可以轻易深度整合到交易系统里。
- 容器技术出现后,也衍生出更多其他新兴技术,例如 CoreOS、RancherOS、Unikernel。对于无止境追求极速性能的交易系统,交易软件到底层硬件之间的耗损越少越好,这和我们所遵循的 mechanical sympathy 技术理念完全一致。类似 Unikernel 这样的所谓“library OS”非常有趣,因为整个操作系统萎缩成一系列的基础库,由应用软件直接调用以便运行在裸机(bare metal)上。想象一个超级轻量的交易中间件,无缝(真正意义上)运行在裸机上的毫无羁绊裸奔的“爽”…
- 在广发证券 IT 而言的所谓“弯道超车”,其实更包括几方面的含义:一是观念上的,颠覆传统软件研发的思维,不必要去做追随者;二是技术成长方面的 – 虽然有些技术如 Unikernel 并未成熟到可以真正运用,但是两三年前的 Docker 不也一样吗?重要的是团队和一个革命性技术的共同成长,前瞻性技术的研发投入终将回报(capitalize);三是实际效果上的,虽然在云计算发力的前几年,我们并未投入到 IaaS、PaaS 的“基建”,但是从容器化入手,忽然间就获得了一定的“计算资源集合使用”的能力 – 此前只有技术实力较强的科技企业能做 Grid Computing。
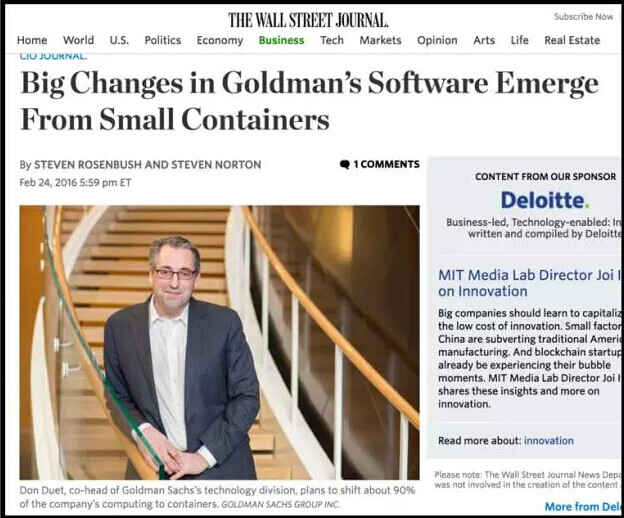
在证券业,我们不是孤独者。华尔街投行的表率高盛,今年 2 月份宣布了他们一年内把 90% 的运算能力容器化的计划。
时至今天,在 Docker 已经被团队广为接受、被应用到各种业务系统中去的时候,我们从两个方向同时继续推进容器化技术:
- 第一个方向,继续沿用上文所述的“Top-Down”思路,基于业务场景、具体应用需要,把容器(Docker)、容器编排管理(Rancher)的技术深度整合到交易系统中去,让其获得自伸缩(elastic)、自监控(self monitor)、自修复(self-healing)的自动化能力 – 这是“反脆弱”系统的一个必要非充分条件,至于什么时候伸缩、什么时候自修复、如何学习自己的运行行为以作自我调整、如何把低级的系统指标换算成业务级别的性能指标作为自己的健康“血压计”… 这些是需持续学习挖掘、测试验证的东西。
- 第二个方向,是上文所述的“Bottom-Up”思路,采用例如 Kubernetes 建立起一个多租户的 CaaS(容器即服务)平台,支持非交易的应用系统(例如电商平台、机器人投顾服务、CRM 等等)的跨云(公有云、私有云、传统机房)容器化。
第一个方向,我们认为是真正的证券领域“云计算”应用场景,符合所谓的“计算”(computing)这个概念,它要求研发团队对容器技术深刻理解,把一个专业的、垂直领域的技术解决方案“云化”。第二个方向,是使用“云平台”的场景,它只要求应用开发者遵循预定义的标准、最佳实践去开发微服务,应用系统部署到多租户的 CaaS 平台上,即起码理论上获得云服务基本属性和好处。前者把云的技术“内置”于自己的垂直技术平台以服务客户,后者使用成熟通用的云平台(自己的或者第三方的)。
软件工程没有银子弹
99 年图灵奖获得者 Fred Brooks(也就是 Brooks’ law 的发现者:“往一个已经延误的项目里加人力资源,只能让那个项目更延误”)说过,软件工程没有银子弹。在各种标榜“云”的科技公司层出不穷的今天,其实依然还没有任何“黑科技”帮阁下把你的脆弱系统瞬间变成一个强韧系统甚至一个具备反脆弱能力的系统。所以,容器技术也不过是一个也许必要但不充分的有用工具而已。

能否释放云计算的威力,取决于很多因素。到一个公有云上使用几个虚拟机,也算一个小小的进步,毕竟它可能(1)缩短了一些传统企业采购硬件、机器上架等等的周期;(2)帮不擅长互联网技术的传统企业解决一部分“互联网最后一公里”问题。然而,这只不过是使用了一些虚拟化基础服务,如果部署在上面的系统本身是一个脆弱系统,那么它在云上依然是一个脆弱系统。
实现一个强韧甚至反脆弱的技术系统,你首先得有一个恰当的技术架构,而实现这样的技术架构,你首先需要有研发团队 – 不错,个人观点是,在现阶段如果不具备软件研发能力,那么你的组织其实无法真正利用、享受到云技术带来的福利。
怎样的架构才能利用和释放云计算能力?受篇幅所限在此无法深入,业界有非常多好的文章,本文仅作高度概括的总结以陈述个人观点。
首先,架构设计需要遵循 Reactive(响应式)原则(根据“响应式宣言”):
- Elasticity – 弹性响应系统负载变化,基于实时性能监控指标以便通过预测性(predictive)和响应性(reactive)算法来对系统进行扩容。
- Resiliency – 通过复制(replication)、包容(containment)、隔离(isolation)和委托(delegation)等机制,保障在故障发生时系统能继续高度可用。
- Responsive – 系统及时探测侦察问题并解决问题,保障对外的及时响应。
- Message-driven – 采用消息驱动的、非堵塞的异步通讯机制,降低系统内部组件模块间的耦合度,提升吞吐量。
“Reactive”既是一种架构风格、也是一系列符合这种风格的技术与工具。过去二十多年来华尔街的交易系统,设计逻辑很大程度上是符合这个理念的,例如高性能交易系统都依赖于异步非阻塞的消息中间件(并且这类技术通常是某家投行独门的技术杀手锏)、都高度强调可用性可靠性,只不过无论工具、技术、基础设施、开发意识都不如今天开源软件世界的技术与软件工程理论来的完备、成体系。
Reactive 宣言里很有趣的一个字眼是 Resiliency,在英文里它是这么定义的:

它表示一种在“坏事情发生后变强壮、健康、成功的能力”、“因被拉扯、拉伸、按押而变形后重新恢复原状的能力”。符合这一原则的技术系统,基本上已经符合塔勒布的“强韧”标准。但显然,Reactive 的技术理念,更是衡量变化、响应变化的,其宣言中提到的支持 scaling 的“predictive and reactive algorithms”,显然是系统自身应对变化而产生的“经验积累”,是一个自我学习和壮大的过程。能够采用响应式架构理念和响应式技术工具实现的系统,很有可能是一个“反脆弱”的系统 – 这正是我们所研发的交易技术所严格遵循的。
其次,在技术研发过程中,我们采用一系列的所谓“Cloud-native patterns”(原生,或者说“天然”的云计算架构模式)来实现我们的系统,以便让系统达到 Cloud-ready(具备云感知能力 – 借用 IBM 与 Intel 相关中文版论文的概念)。
“云感知”的一些要求,其实是常识性的,是一个合格的架构师在设计系统架构时本来就应该遵循的,例如:云感知的应用需要有“位置独立性”- 应用程序应该动态发现服务,而不是通过硬编码固化依赖关系;“避免依赖于底层基础架构”- 应用程序应该通过对操作系统、文件系统、数据库的抽象来避免对底层基础技术进行假设;“带宽感知”- API 和应用协议的设计需要考虑应对带宽问题和拥堵…
此外,“云感知”和上述“响应式”原则,是完全一致的,云感知也关注“故障恢复能力”、“延迟恢复能力”、“扩展的灵活性”。事实上,在一流的金融 IT 团队里,这些原则、实践要求,从来都是被遵循的,因为金融的应用系统天然需要这些能力。无论是否在云计算时代,这些原则、要求均非常合理。
原则归原则、口号毕竟是口号,具体的实施才是一个现实问题。在这个方面,我们崇尚“设计模式”(Design Patterns),尤其是架构方面符合云计算环境的设计模式 – Cloud-native Patterns – 一系列由各方技术“大拿”共同总结归纳出来的“最佳实践”。学习和运用设计模式,本身并非“教条主义”,而是让一支也许平均从业年限只有 3-5 年的工程师团队更快的掌握整个技术界不断总结归纳的经验;更重要的是,一个个人、一支团队、一家公司所遭遇到的应用场景是有限的,架构模式是拓宽视野的最佳途径。有助于“云感知”的、符合响应原则的 Cloud-native 架构模式,在此罗列以下一些常见常用、易于理解的:
- Circuit-breaker:断路器,快速“熔断”应用系统里的某个链路,避免系统进入局部假死并造成请求堆积。这是交易系统常用的模式。
- Fail-fast:有些服务一旦出现问题,与其去耗费时间资源处理它,不如让它迅速失败(“自杀”),以避免调用者反复请求、等候,导致整个系统陷入假死。这也是交易系统为保障系统响应而常用的模式。借用塔勒布在《反脆弱》里的一句话,“what is fragile should break early, while it is still small” – “脆弱”的东西应该被尽早扼杀在襁褓里。
- CQRS(Command and Query Responsibility Segregation):著名的“读写分离”,也许你一直在用,只是没有意识到。读写分离的目的,通常也是为了让频繁大量的查询获得较好的响应。
- Retry:重试(没想到吧?这也是一个模式),在一个服务请求或者网络资源请求失败后,一定程度下透明的、持续的重试请求,假设服务和资源的失败是暂时的。
- Throttling:流控,避免服务资源被个别的服务请求者的频繁请求消耗尽而无法再服务其他请求者,从而保障当前服务能在一个“服务水平协议”(SLA)下向所有使用者公平的提供服务。显然这是从交易所到券商的交易系统都必须实施的机制。
从上述例子可以看到,Cloud-native 的架构模式,很多是与 Reactive 原则一致的,因而也是有助于构建 Cloud-ready 应用的。
那么容器化技术在这其中有什么作用呢?实践告诉我们,作用很大。最重要一点是,很多 pattern 的具体技术实现,可以挪到容器层面去处理。例如 Circuit-breaker 和 Fail-fast 这类模式,过去的做法,是各个具体的服务,采用自己的技术工具(例如 Node.js 的守护进程 PM2)和办法,基于开发者自己的理解,各自实现。
可以想象一下,在一个巨大而复杂的技术系统里,有很多服务、组件、模块需要实现熔断、快速失败、流控之类的机制,而这类系统很可能是采用所谓 polyglot programming(混合编程)、polyglot persistence(混合存储)、polyglot processing(混合数据处理)的方式实现,涉及多种语言、多类异构技术,如果流控、熔断在各个模块、服务、组件里各自随意实现,显然最终导致系统综合行为的不可预测。
容器化的好处,是把复杂系统里一切异构的技术(无论以 Go、Java、Python 还是 Node.js 实现)都装载到一个个的标准集装箱里,然后通过调度中心基于各种监控对这些集装箱进行调度处理。也就是说,Cloud-native 的架构模式,有不少是可以在容器编排调度与协同的这一层实现的。
注意这种调度本身也是“智能”的 – 与业务逻辑、业务语义的性能指标(例如交易委托订单的吞吐、堆积)监控深度结合,甚至利用大数据技术进行自我的监督学习,实现“无人值守”的运维。
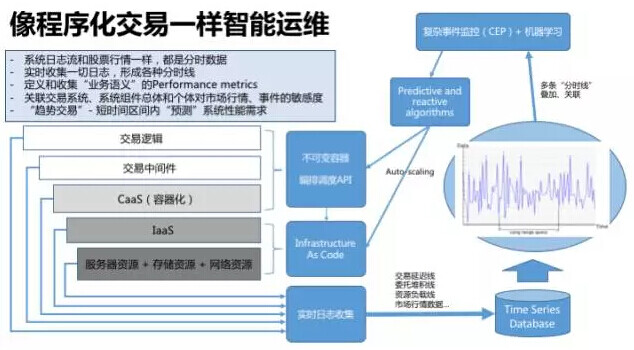
综上所述,云、容器、容器编排等等这些技术,不是银子弹,不会魔术般的把一个本身“脆弱”的 IT 系统变成一个强韧的、甚至“反脆弱”的系统。构建一个能充分发挥云计算系列技术之能力的系统,需要深刻理解容器技术和 Reactive 之架构风格,以及熟练运用各种 Cloud-native 的架构模式,才能实现 Cloud-ready 的解决方案。
而这一切,如上文所提出,需要“研发的视角”,需要研发团队驱动。这对于没有研发组织或者缺乏工程师文化和一流研发团队的机构组织(尤其是垂直行业尝试投入到所谓“互联网 +”的),是一个巨大的挑战。
DevOps:云计算时代的方法论和文化
南怀瑾在某本著作里举过一个剃头匠悟道的例子 – 无论何种行业,技艺追求到极致可能悟到的道理都是共通的。《黑天鹅》和《反脆弱》的作者塔勒布本人也许算的上是这样的一个触类旁通的好例子 – 由金融而“悟道”于哲学(起码被称之为本世纪有影响力的思想家之一)。
IT 领域不知道有无类似的人物,诸如面向对象设计、架构设计模式、敏捷开发领域的大师级人物 Martin Fowler 等,显然是抽象思维特别强的人,能够对复杂的技术世界进行“模式识别”而作出一些深刻思考。在技术世界里,我们一向强调方法论,可是有时候也需要形成“世界观”、“信仰”。在无数次的项目危机管理、技术故障攻坚、运维救火之后,IT 人也许应该对“世间唯一不变的是变化本身”有深刻体会,从而接受“拥抱不确定”的观念。
IT 界面对变化与不确定性的态度,这十多年来看也是一个有趣的演变:
-
直到本世纪初,很多项目管理及软件工程的方法论,依然强调所谓的“Change management”(变更管理),通过组织(“变更委员会”)、流程来“管理”业务系统需求方不断提出的需求管理,视需求变化为项目延误、系统不稳定的根源,以项目“按时”交付为终极目标,可以说这些方法论本质上“厌恶“变更。
-
互联网风起云涌后,出于应对瞬息万变的激烈竞争、在线高效运营的刚需,接受“需求变化是常态”、对变更友好的“敏捷”(Agile)方法被自然而然引入到日常项目中,成为过去十年的主流方法论,并且终于把传统企业 IT 牵引其中(例如广发证券 IT 启动金融电商系列项目研发前的第一件事就是先把敏捷实践建立起来 – 对口的方法论才可能带来对的结果)。
然而,绝大部分企业的敏捷实践都局限在垂直业务线的项目团队里,而运维作为一个维护全企业 IT 生产资源的横向平台型组织,通常被排除在敏捷实践之外。敏捷迭代方法解决得了业务需求变更的问题,解决不了系统上线后各种突发性的变化 – 故障的及时解决、版本的迅速更新(业务部门总是迫不及待的)、在线经营的瞬间生效(运营人员分分秒秒催着)… 在一切都嫌慢的“互联网时间”里,运维貌似成为最后掉链的一环,以“稳健”为主导的运维团队与“进取”的研发、运营团队无可避免产生冲突
-
时至今天,随着“把基础设施数字化”的云计算的普及,一个新的方法论 – DevOps,闪亮登场。之所以说这是一个方法论,是因为它绝不仅仅是“Dev + Ops”这样简单粗暴的把开发工程师和运维工程师捆在一起,用“同一个项目组”、“同一套 KPI”来强迫他们分享“同一个梦想”了事。它是在 APM(应用性能监控)、Infrastructure As Code(可编程运维)、Virtualization(虚拟化)、Containerization(容器化)等等这些云计算时代的产物出现后,基于新的技术工具、技术理念而自然产生的。持续集成(Continuous Integration)、持续交付(Continuous Delivery)、持续运维(Continuous Operation)是 DevOps 的具体环节和手段,它相当于把一条纯数字化链路上不同的参与者关联到一起 – 无论是开发工程师还是运维工程师,最终都不过是身份稍微差异的 Information worker。
改一下毛泽东《满江红》的名句,“一分钟太久,只争朝夕”,可以形容这就是 IT 技术、方法论演变的动力 – 一切都是为了更高效。DevOps 的“哲学”,开玩笑的说,是“可以自动的绝不手动”,而容器化技术以其轻量敏捷和丰富的 API 接口“加剧”这一可行性和趋势。
DevOps 可能不仅仅是个概念、方法论、技术新名词,它是伴随云计算自然发生的。但它的接受与运用,对于传统企业的 IT,尤其是“维稳”为主导思想的受监管行业的 IT,可能是一种文化冲击。传统 IT 甚至是今天的很多技术相对前沿的互联网公司,依然把团队拆分成“运维”、“开发”,在组织结构层面建立相互制衡,以避免开发团队的“冲动冒进”导致生产系统的不稳定,但运维职能往往变成一种“权力”(privilege)- 系统的迭代更新都需要获得运维“审批”,这本身显然就是一个“脆弱系统”,因为对变更是绝不友好的。在技术进步、时代变迁的大环境下,这种过去合理的做法,早晚变成一个将要被颠覆的存在。
无论如何,我们认为割裂的讨论一个高性能运算(HPC)的技术系统(如证券交易系统)的容器化、“云化”是不够的,DevOps 是构建“反脆弱”技术系统的方法论(起码到目前为止。也许将来有新的思维出现),也是我们系统能力的天然一部分。
结语
《奇点临近》(Singularity Is Near)的作者、谷歌未来学家库兹威尔(Ray Kurzweil)有句话可以借用来描述这个世界的变化:“There is even exponential growth in the rate of exponential growth”- 指数级的变化率本身之变化也是指数级的。世界在加速朝着“Matrix”演变(well,believe it or not),本身就已经数字化的金融,显然是数字世界的一块基石。
但这也是一个典型的“极端斯坦”,黑天鹅(或者就是佛教所谓的“无常”?)将更多的光临,而数字金融里的负面黑天鹅,危害最巨大。事实上整个金融体系本身就是一个“脆弱系统”-《高频交易员》(Flash Boys,作者 Michael Lewis)提到 SEC 其实往往因弥补市场规则漏洞而造成新的漏洞。技术的高速发展则将让发现、利用漏洞进行套利的行为变得更容易、更频繁,而这些行为带来的后果也是不可预测的。
我们从软件研发的视角、证券交易的视角来看待云计算,深感把促进基础设施数字化、运维代码化的容器化技术,运用到交易系统技术中,是天作之合 – 假如运用得当的话,结合机器学习和智能算法,能帮助我们构建一些“反脆弱”的技术方案(既然有能下围棋的阿尔法狗,我们是否也可以开始憧憬懂得自救的运维狗?)。
但是云计算前沿技术在金融业的更广泛应用,目前取决于行业监管、企业文化、技术人才素质。例如领导者一句“云会不会引起信息安全问题”这样“放诸四海而皆准”的深沉状问话,总是可以让行业、企业内一切科技创新打回原形。
不过,再借用本文开头所引用黄仁宇先生的“大历史观”,可以看到的潮流脉络是,世界是越来越数字化的、变化是越来越频繁的、而 IT 是需要拥抱变化的,云计算则只是这个潮流里完全符合趋势而自然出现的技术阶段。有一天 Oracle、SAP、各种著名与非知名的专业软件都把它们自身的产品基于容器来构建(例如一个多进程组成的数据库实例里的进程各自运行在自己的容器中),也许对于行业监管者、企业技术决策者而言,云已经无需概念上的存在,而能被毫无质疑的接受。这一天不会太远,据 Gartner 称,2020 年企业中无云战略将极为罕见 – 和今天的企业无互联网一样难以想象。
但是这一天到来之前,大部分企业也许可以先尝试调整一个对云服务友好的财务制度 – 项目立项的时候,硬件预算按 CPU 核数、内存量、存储量来报算,有形的物理机器不再作为资产稽核到各条业务线各个项目组,一切物理硬件归 IT。制度和文化,往往才是隐形的决定因素,不是吗?
全球容器技术大会
广发证券是国内较早应用 Docker 的金融企业,在 InfoQ 主办的 CNUTCon 全球容器技术大会上,广发证券的资深架构师将会分享广发在容器方面的技术细节,欢迎关注。
演讲将介绍容器技术在证券交易系统的应用实践经验。证券交易互联网接入,面临跨地域、跨机房部署,实时性要求高,海量并发。而传统金融企业运维保守,基础设施不完备导致云技术难以落地。我们引入容器技术弯道超车,实践微服务与 CloudNative 理念,使用 Docker、Shipyard、Compose、Rancher、Gogs、Drone、Statsd、Grafana、Cabot 等开源技术,一步一步摸索出适合企业组织架构与 IT 系统的最佳实践,实现服务的持续集成,一键部署、灰度更新、自动化监控,并将服务部署到十余个机房和多个公有云,支撑日交易额百亿,行情推送支持百万并发连接接入。
作者介绍
梁启鸿,哥伦比亚大学计算机科学系毕业,出道于纽约 IBM T.J. Watson 研究院,后投身华尔街,分别在纽约 Morgan Stanley、Merrill Lynch 和 JP Morgan 等投行参与交易系统研发。本世纪初加入 IT 界,在 Sun Microsystems 大中华区专业服务部负责金融行业技术解决方案。此后创建游戏公司并担任 CTO 职位 5 年。后作为雅虎 Senior Principal Architect 加入雅虎担任北京研究院首席架构师角色。
三年前开始厌倦了框架、纯技术的研发,开始寻找互联网前沿技术与线下世界、传统行业的结合;目前回归金融业负责前端技术、大数据、云计算在互联网金融、股票交易系统的应用。
个人兴趣是把前沿的互联网技术应用到垂直行业中,做一点能改变传统面貌的、最重要是有趣好玩又有用的事情;紧跟 Go、Docker、Node.js、AngularJS 这些技术但更关注如何把技术用到应用场景里,从中获得乐趣。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




