预测物品的点击率在计算广告、推荐系统等不同业务系统中都有一定需求,因此业界在这方面进行了不少研究。然而在机器学习领域,书籍出版远远落后于业界知识更新,这就要求每个从业者阅读大量资料和论文才能跟上知识更新的步伐,而这又需要耗费大量的时间和精力。本文是作者对阅读过的大量相关研究文献的小结,作者尝试结合文献与工作实践梳理广告点击率预测、推荐方面相关的技术脉络,希望能对大家有所帮助。
1. 背景
在计算广告系统中,一个可以携带广告请求的用户流量到达后台时,系统需要在较短时间(一般要求不超过 100ms)内返回一个或多个排序好的广告列表;在广告系统中,一般最后一步的排序 score=bid*pct^alpha;其中 alpha 参数控制排序倾向,如果alpha<1,则倾向于 pctr,否则倾向于 bid;这里的核心因子 pctr 就是通常所说的点击率(predicted click through rate)。
在推荐系统中,也有类似的需求,当用户请求到达后台的时候,我们需要返回一个排序好的文章列表或者 feeds 列表。早期的推荐系统主要以协同过滤和基于内容的推荐为主,近年来推荐系统的主流形式也变成和广告类似的两步走模式:先召回一个候选队列,然后排序;在排序这一步有很多种不同的策略,比如 pair-wise 的一些分类算法等,但更多还是类似 facebook、youtube 之类的计算一个分数然后排序;这个分数里往往也少不了 item 的 pctr 这个关键因子。
综上,在计算广告、推荐系统等不同业务系统中都对预测物品的点击率有需求,所以这方面的研究也比较多,本文试着梳理一下相关的技术脉络。
2. problem formulation:回归问题 vs 分类问题
我们可以有很多种不同的方式来定义点击问题,本文会列举两种方式。
第一种是将其看做一个分类问题,这种看法比较自然是因为我们原始的日志是曝光和点击;通过简单的归约以后,我们把点击看做正样本、曝光看做负样本的话,基于一段时间的数据样本,我们可以训练一个分类器。形式化来说,假设用户 u、物品 i、上下文 c,曝光和点击类别 e,每个样本可以看成一个<u,i,c|e>的元组;其中 e 的取值只有 0 和 1 两种,这时候对每一个用户、物品、上下文组合<u,i,c>我们需要一个模型来对其分类,是点击还是不点击。
从分类角度出发,我们有很多算法可以用,比如贝叶斯分类器、svm、最大熵等等,我们也可以使用回归算法通过阈值来处理。
另一种看法假设每个<u,i,c>我们可以预测一个 ctr(0-1 之间的值),这时候就变成了一个回归问题,可以使用 lr、fm、神经网络等模型。
在本文的结尾部分可能会有其他的问题定义的方法,大家也可以看到在实际业务中,不同的问题定义方式不仅决定了可以使用的模型范围,甚至决定了本质效果的差异。某个领域机器学习方法的进步,往往不只是模型的进步,有时候是先有问题定义的进步,然后才有模型和算法的进步;而问题定义的进步来源于我门对业务场景的理解,所以做算法的同学一定要多花时间和精力在业务场景的分析和挖掘上。
3. 逻辑回归介绍
将用户是否点击一个物品看成回归问题以后,使用最广泛的模型当属逻辑回归 Logistic Regression,[1] 是一篇很不错的关于逻辑回归的综述,这里不打算展开讲逻辑回归的细节,简单做个介绍并说明实际使用中的一些注意点。
首先逻辑回归使用 sigmoid 函数来建模,函数如下:

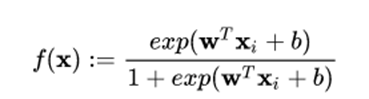
该函数对应的图像如下所示:
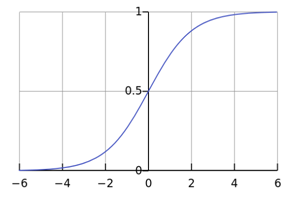
LR 的优点很明确,首先 sigmoid 函数的取值范围是 0-1,刚好可以解释为点击概率,而输入的范围却可以很宽广。所以 LR 是历史最悠久、使用最广泛的点击率、转化率模型。
这里重点说下使用 LR 需要注意的几个事项。首先是训练算法,如果使用离线训练算法,有比较多的选择,比如 sgd、lbfgs、owlq、tron 等等;其中 sgd 是一种非常通用的优化算法,但个人认为理论研究模型可以用 sgd 快速理解,但实际业务中往往不是最佳选择,尤其是存在其他备选项的情况下;原因可以给一个直观的解释,从 sigmoid 函数图像可以看出来,在 x 大于 4 或者小于 -4 以后,函数的取值已经接近于 1 或者 0 了,此时函数的梯度方向接近平行,说明梯度很小,那单个样本对模型参数的贡献也会接近于 0,所以 sgd 的收敛速度越来越慢。这种收敛速度是敏感的,如果你跑一个模型几个小时收敛不了,和另一个算法几分钟就收敛了,那时间的量变就会带来模型性能指标的质变。
除了训练算法之外,LR 模型最需要注意的是特征的呈现方式,从 sigmoid 的解析式可以看到 LR 其实是广义线性模型的一种(GLM),所以 LR 既不能很好地处理连续型特征,也无法对特征进行组合。相反,对于 categorical feature 反而处理得很好。因此,使用 LR 模型的时候往往伴随着大量特征工程方面的工作,包括但不限于连续特征离散化、特征组合等。
3.1 特征离散化
对于 continous feature,如年龄、薪水、阅读数、身高等特征,如果要添加到 lr 模型中,则最好先进行离散处理,也叫 one-hot 编码;离散化处理的方式有几种,等值分桶、等频分桶等;或者直接根据对业务的理解分桶。例如对于电商类,可能 20 岁以下的没有什么经济能力,20-40 的经济能力差不多,这时候可以人工划分。
等值分桶是指每个区间同样大小,比如年龄每隔 5 岁为一个桶,则年龄特征变成一个 20 个区间(假设上限是 100 岁)的编码,如 15 岁对应(0、0、1、0、0、0…)。
等频分桶则是需要先对样本做一个分布统计,还是以年龄为例,首先我们要基于统计得到一个年龄分布直方图,通常这类特征都会大致符合正态分布,这时候对于中间阶段就需要多拆分几个桶,而对于两边的部分可以少一点;如 0-16 一个区间,16-18 一个区间,18-20 一个区间,20-30 一个区间。目标是使得每个区间里的人数分布基本持平。
特征离散化的好处我理解是风险均摊,不把鸡蛋放在一个篮子里。举个例子,如果年龄特征对最终的预测结果很重要,则可能在 LR 模型中获得一个比较大的权重 w,这时候如果有一个异常数据,某个人年龄写的是 200 岁,就会一下子将函数值推到接近 1 的区域。这明显不是我们想要的,相反如果通过离散化,年龄特征的权重会分散到各个桶对应的特征里,这时候单个特征的异常就不会造成很大的影响。
3.2 特征组合
假设模型里有年龄、性别、身高三个特征,这时候就会出现特征组合的问题。比如年龄 + 性别可以作为一个新的特征,可能某类物品对于这种组合特征有偏好,如 16 岁以下的小男孩对变形金刚很感兴趣(我实在想不到什么例子)。这种需求 LR 是没有办法自动完成的,只能人工来添加。
类似还有三阶特征、四阶特征等等,在比较长一段时间里,特征工程是算法工程师的主要工作,后来特征多到人力无法进行有效组合的时候,又想出来了其他一些办法,比如后面要介绍的 GBDT+LR 就是 facebook 提出的一种应对特征组合的处理方式。
3.3 特征设计
在这里也单开一个小节来介绍特征设计的内容,这块没有特别有效的现成方法,也没有相关的书籍总结,但又很重要。如果特征设计不好,很可能模型根本出不了效果,能给大家的建议就是多读读论文。从和自己业务需求相似的论文中去看别人设计特征的方式,然后结合自己的业务看看能否借鉴。
从我自己阅读的一些 paper 里,我总结了两个所谓的"套路"。
一个是 获取外部关联信息,比如对于新广告,我们要预测点击率的话,因为没有历史数据,我们可以从层次结构来获取一些信息,比如这个广告的 publisher 下面其他广告的点击情况,这个广告的落地页的 url 层次关系,比如 xx.com/food/x.html 这类 url,我们是否可以对 food 做一个聚合,看看这类落地页对应的广告的数据情况,以此作为我们新广告的特征。还有一种技巧,将广告相关的文本,或者广告购买的关键词列表,丢到搜索引擎上去跑一下,取返回的 top10 页面聚合以后做一个分类(类别体系可以提前设计),然后根据关键词列表在不同类别上分布形成的信息熵作为一个 feature,放到 LR 里。在 [2] 中使用这种方法得到了一定的提升。
另一个套路是 使用数据不同方面的信息,这个策略更加隐晦。举个例子,我们可以根据用户的资讯阅读历史计算一个兴趣画像,但是这个画像我们可以分成几个画像,比如拿一周的历史算一个,一个月的历史算一个,然后通过实践 decay 算一个历史全量的。这样场中短期分开的画像可以作为独立的特征放到模型中去。另一个例子是 cf 论文中一个很有意思的做法,在 Netflix 的数据集里,user-item 矩阵嵌入了一个隐藏信息是 user- 打分 item 的对应关系,所以我们可以从 user-rating 矩阵里提取一个二元取值的 user-item 关联矩阵,如果 u 对 i 打分了,则这个矩阵对应 ui 的位置为 1,否则为 0。把这个矩阵作为一个 implicit feedback 加入到 cf 里,会有进一步的效果提升,这就是数据信息的不同 facet。
特征设计还有很多其他的技巧,这里就不一一列举了,还是需要去搜寻和自己业务场景相关的论文,阅读、总结,后面我会再写一篇协同过滤的综述,那里会介绍另外一些技巧。
3.4 评价指标
这一小节是后补的,主要介绍几种常用的评价指标以及他们各自的优缺点,主要取材于 [21]。这里选取 AUC、RIG、MSE 三个来重点说下,其他的指标有需要的请参考原文。
AUC 是 ROC 曲线下的面积,是一个 [0,1] 之间的值。他的优点是用一个值概括出模型的整体 performance,不依赖于阈值的选取。因此 AUC 使用很广泛,既可以用来衡量不同模型,也可以用来调参。比如
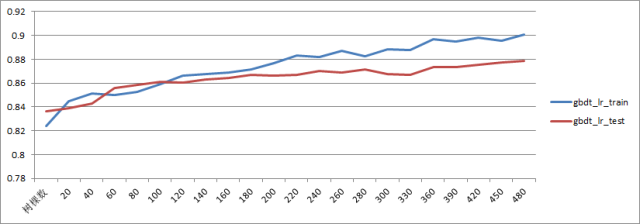
这是用 AUC 用来调超参的一个例子,横坐标是 GBDT 的树的棵数,纵坐标是对应模型收敛后在 test 集和 train 集上的 AUC 值,从图中可以看到在 120 棵树附近 GBDT 就开始出现过拟合情况了,不过两个集合的 AUC 都还在持续上升。除此之外,AUC 还可以作为一个在线监测的指标,用来时刻监测在线模型的表现。
AUC 指标的不足之处有两点:一是只反映了模型的整体性能,看不出在不同点击率区间上的误差情况;二是只反映了排序能力,没有反映预测精度。 简单说,如果对一个模型的点击率统一乘以 2,AUC 不会变化,但显然模型预测的值和真实值之间的 offset 扩大了。
Netflix 比赛用的 RMSE 指标可以衡量预测的精度,与之类似的指标有 MSE、MAE,以 MSE 为例,计算公式如下
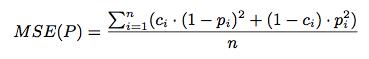
公式里的 ci 和 pi 分别对应真实的 laber 和预测的 ctr 值;前者用 0、1 表示曝光和点击;后者用 [0,1] 之间的实值即可。MSE 指标不仅可以用来调参,也可以在参数选定以后用来分区间看模型的拟合程度;熟悉 Netflix 比赛相关 paper 的同学可能知道缺点在哪,就是区分度的问题,很有可能 MSE 很小的提升,对线上的效果,比如 F 值会有较大的变化,因此在业务优化的时候还可以参考其他更有区分度的指标。
如果我们要对比不同的算法的模型的精度怎么办呢?除了 MSE 有没有其他选择?这里提供一个 RIG:
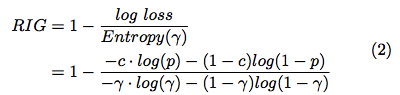
这张图直接取自 [21],表达式有点问题,我先留给大家来发现吧,正确的表达式在本文另一篇参考文献里有,先留个悬念:)
这里要强调的一点是 RIG 指标不仅和模型的质量有关,还和数据集的分布情况有关;因此千万注意不可以使用 RIG 来对比不同数据集上生成的模型,但可以用来对比相同数据集上不同模型的质量差异。这一点尤为重要。
4. 几种常用点击率模型介绍
4.1 BOPR
[3] 是微软内部竞赛推出的一个算法,也被后续很多算法作为对比的 baseline。
这个算法的细节可以直接去看原文,这里只对优劣做一个简单介绍。该算法的基本思想是参数 w 是一个先验分布为正态分布的分布,参数为 u、ó;在贝叶斯框架下,每一个样本都是在修正对应的分布参数 u、ó;对应的更新公式为
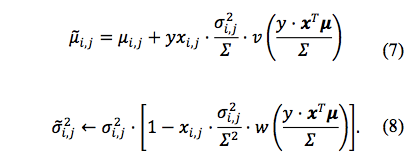
该模型的优点是基于贝叶斯模型,因此可以做到在线学习,每个样本都可以对参数进行微调,同时 online learning 带来了在线学习的能力,可以及时应对用户兴趣的变化。
不足之处在于每个 feature 对应权重都需要两个参数来描述,模型的尺寸是 LR 的两倍,在复杂模型场景下这个成本可能比较难接受。
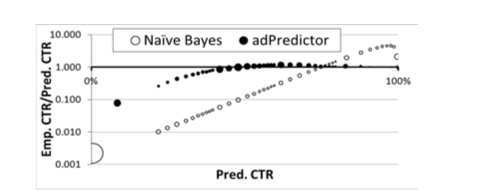
从文末的评测来看,BOPR 和朴素贝叶斯相比,BOPR 能在比较宽的 pctr 维度很好地拟合经验点击率的情况。
4.2 GBDT+LR
[4] 是 14 年 facebook 出的一篇 ctr 领域非常经典的论文,15 年去北京参加 QCon 大会时,机器学习方向的演讲几乎都提到了这篇论文,可见该方法的成功。
前文提到,随着特征的增加,特征组合这件事将变得尤为困难,人力很难应付。假如一个点击率预测的系统涉及到 100 个特征,则熟悉二项式定理的同学可以心算出来所有可能的组合特征接近 2100;这个数据有多恐怖呢?一张纸对折 50 次对应 250,出来的高度是 1125899906 米,大约是几十万个珠穆朗玛峰那么高。而特征组合是在特征离散化以后做的,稍微几个特征分桶可能就不止 100 了,再组合,特征就会爆炸掉。
特征爆炸带来两个问题,一是不太可能再用人力的方式去做特征组合的事,这简直就是太平洋里捞一个水分子了。另一个问题是维度灾难,这个可以参考我 km 另一篇文章。
[4] 就是尝试提出一种解决特征组合问题的方案,基本思路是利用树模型的组合特性来自动做特征组合,具体一点是使用了 GBDT 的特征组合能力。整体架构如下:
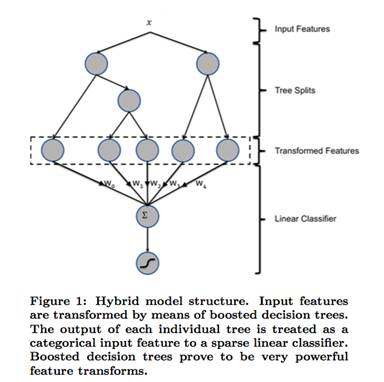
先在样本集上训练一个 GBDT 的树模型,然后使用这个树模型对特征进行编码,将原始特征 x 对应的叶子节点按照 01 编码,作为新的特征,叠加到 LR 模型里再训练一个 LR 模型。预测的时候也是类似的流程,先对原始特征 x 通过 GBDT 计算一遍,得到叶子节点情况,以图中为例,如果 x 落到第一棵树的第二个节点,第二棵树的第一个节点,则转换后的输入特征为 (0、1、0、1、0);
GBDT+LR 模型确实明显优于单独的 LR 模型,我们在浏览器多个场景做了测试,AUC 都有非常明显的提升,接近 10 个百分点。从训练来看,GBDT 也确实像 [5] 所说那样,很容易过拟合,但叠加 LR 以后却能取得很不错的性能。GBDT 因为是在函数空间对残差进行连续逼近,所以优点和缺点一样明显:优点是可以逼近几乎任何函数的任何精度,缺点就是很容易过拟合,需要根据业务场景注意在树的棵数和深度上做一定的裁剪,才能平衡精度和过拟合。详细的推导请参看论文,我也只大概看明白原理,因为对泛函还不熟悉,以后有机会再来细讲这个模型的原理。
4.3 FTRL
FTRL 是从 RDA、FOBOS 等针对 LR 的在线学习算法改进而来,主要是工业界强烈的在线学习的需求驱动而来。有意思的是前面提到的微软的 BOPR 也是一种天然支持在线学习的算法。为什么要做在线学习?有哪些注意点呢?
在线学习背后的理念是每个人的兴趣是 non-stationary 的,离线训练的模型在线上可能不能快速对用户最新的行为作出反应。为了解决这个问题,一种做法是我们加快模型的频率,比如原来一天更新一次,现在一个小时更新一次,这种做法有很明显的瓶颈,比如如果我们的时间窗设置的比较长,用一个月或者两个月数据来跑模型,则可能导致模型在更新间隙内完不成训练;如果我们采用增量训练的方式,则增量时间窗的设置是个技术活,太短,很多曝光对应的点击还没有上来,导致训练数据的无效曝光比例偏高,如果太长,可能跟不上节奏;这也是在线学习的一个难点,在线学习一般也不会每一个回流数据立马更新模型,这会导致模型震荡频繁,攒一小段时间是个不错的选择,为此 Facebook 的系统里有一个 online joiner 的组件来做曝光和点击的归约。
从今日头条披露的资料来看,在模型更新方面他们采用了增量更新 + 定时校准的策略;类似于在线学习 + 定时离线校准。这种策略应该也可以用到点击率的场景。
在线学习另外一个要重点解决的问题是学习率;离线训练的时候 sgd 往往使用一个公用的学习率η,但是在线学习这样做会带来问题;因为样本分布不均衡,某些覆盖不是很高的特征对应的权重因为样本少得到的更新次数比较少,如果使用相同的学习率,则这些权重的收敛势必落后于覆盖率高的样本的特征对应的权重,尤其是有做学习率衰减的情况下;因此我们需要针对不同的权重来设置不同的学习率,做法也比较简单,基本思路是统计该维度样本数,多的衰减快点,少的衰减慢点以期能做到基本持平,详见 [6],相关的 rda、fobos 已经是前浪了,没时间可以不看,有时间酌情。
这里也顺带提一下 FTRL 和 GBDT+LR 的关系,FTRL 主要是针对 LR 部分的 online learning;GBDT+LR 是两种不同模型的级联,这两个方案是可以很方便的糅合在一起的变成 GBDT+FTRL-LR;但这里 GBDT 的更新没法做到 online learning;可以做定期更新。理论上这种做法可能会效果更好一点。
4.4 FM
[7] 提出的 FM 是一种可以自有设置特征组合度数的回归算法,通常 d=2 的 FM 拟合公式如下:
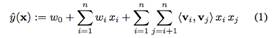
选择一种损失函数后很容易用 sgd 之类的优化算法来计算 w 和 v;原文这块的论述有点模糊,没有指明目标函数的情况下对拟合公式使用了 sgd,有兴趣的同学可以一起探讨。
FM 的优势是可以自动进行特征间的组合,这解决了两个问题:一个是系数数据因为特征组合而能得到不错的 backgroud model 效果;另一个是特征组合解决了人工组合的尴尬,GBDT+LR 与此有异曲同工之妙,因此 FM 常常和 GBDT+LR 一起讨论。从应用范围来看,业界 GBDT+LR 的使用范围应该是比 FM 要广的,国内我所知只有世纪佳缘 [8] 是使用 FM 替代了 GBDT+LR。
FM 的另一个优点是会算出每个 feature 对应的向量 v;这个向量可以看做对 feature 的一种 embeding,例如后面 WDL 的场景,或者是 GBDT+LR 里对 categorical feature 做 embeding,后者我们正在计划尝试;前者因为可以通过 joint learning 直接学习最佳的 embedding 向量,所以一般不会单独使用 FM 来对 feature 做 embeding。
FM 的不足之处是在 dense 数据集情况下,反而可能表现不佳,鱼与熊掌不可兼得啊!
4.5 FFM
[9] 介绍了 FFM 在美团的一些应用,个人理解是 FM 的一个小改版,不多说。
5. 新用户:MAB、CB、泛精准
对于系统的新用户,在没有历史消费数据的情况下,想要预测用户的点击率是一件比较困难的事。这里提供一种按照数据丰富度划分阶段的思路,一共划分为四个阶段:1. 全新用户;2. 少量消费数据用户;3. 一般消费数据用户;4. 充分消费数据用户。每一个新用户和系统的交互分为这四个阶段,分段的标准可以根据具体场景的实验数据来拍一下脑袋,在不同的阶段,我们用不同的策略来进行用户数据的获取。
全新用户阶段,将用户和广告的匹配看做一个多臂老虎机(MAB)问题,可供使用的 bandit 方法有 UCB[10]、汤普森采样 [11] 等。这两者的区别在于 UCB 几乎没有随机性,根据预估收益率 + 置信度作为总的排序 score,选择最高的悬臂。汤普森采样是贝叶斯框架,将每个悬臂的收益概率 r 视为一个 Beta 分部;根据历史情况修正分部的参数,而需要选择的时候则对每个悬臂的分布进行采样,根据采样结果排序来选择悬臂,保持较好的随机性;在一些内容推荐系统也会经常使用汤普森采样来解决 expolore&exploit 问题。在点击率场景的全新用户阶段,我们使用 MAB 不失为一个选择。
在 少量消费数据阶段,我们可以使用 CB[12],CB 的核心思想是给用户展示他消费过的物品最相似的物品,比如一个用户消费了盗梦空间,则他有可能想继续观看泰坦尼克号。CB 的难点在于对物品向量化。
对于 第三个阶段的用户,有一定的数据又不是很多,此时可以采用 [13] 这种降级的 ctr 模型,并且对其中的一些特征使用 smoothing 技术,如贝叶斯平滑、指数平滑等;可以参看后面部分的介绍。
第四个阶段就是常规用户,使用我们前面提到的各种点击率模型就好了。
6. 新广告:lookalike、相关广告信息挖掘
新广告的点击率预测是另一个比较大的话题,这里我先简单分为两类,一类是临时性投放,比如某个新广告主偶然来试投一下汽车广告。如果广告主能提供一批种子用户,我们可以使用 lookalike 的方法来优化之,可以参考 fandy 的 [15],我的理解是一个迭代处理,先基于种子用户和采样用户训练一个 model,然后用 model 对采样的用户做一轮 predict,把得分高的用户刨除掉,剩下的用户定义为有效负用户,然后再和种子用户一起训练一个新的 model,将这个 model 作为候选 predict 并圈取用户的指示器。
另一类新广告是广告主或者代理商在广告投放系统里投放的一个新的素材,这个时候虽然广告是全新的,但是我们任然可以从系统里挖掘出大量相关的信息,比如该广告对应的 pushlisher 的历史信息,对应的 advertiser 的信息,对应类比的信息等,具体可以参考 [14]。
7. rare event:贝叶斯平滑、指数平滑
这节单独介绍下 [16] 这篇论文,和 [6] 不同,这篇文章主要是针对发生频率比较低的事情的一些优化,可以用于新广告,但也可以用于比较老只是频率低的广告。
想法的初衷是我们经常需要使用一些点击率特征,比如曝光两次点击一次我们可以得出 0.5 点击率,另一个广告是曝光一万次,点击五千次,也可以得到 0.5 的点击率,但是这两个 0.5 代表的意义能一样吗?前者随着曝光的增加,有可能会快速下滑,为了解决经验频率和概率之间的这种差异,我们引入平滑的技巧。
[16] 中使用了指数 decay 和 beta 分布平滑两种技巧,这两个技巧也可以一起使用。对于 decay,既可以将历史信息融入到特征里,又保持了对历史信息的遗忘速度,是一个不错的平衡,从各个实践来看,使用平滑对模型性能都会有显著的提升。
8.WDL 介绍
随着深度学习的火爆,在图像识别、推荐系统等领域都出现了深度学习的模型,那么深度学习是否可以应用到点击率模型呢?答案是肯定的,在国内公开的资料中可以查到深度学习点击率的资料应该是 kintocai 所作,之前 kinto 也在内部做过一次分享,主要的出发点是 google 的这篇 paper[17];核心的图片截取如下:
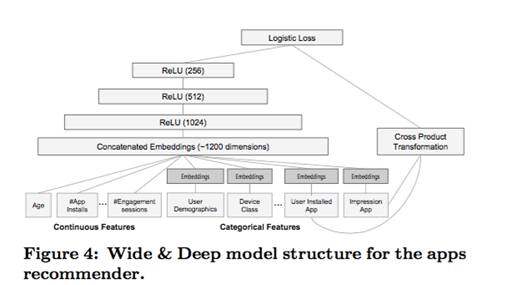
从这张图可以看出,在最上层还是使用了 LR 模型,和 GBDT+LR 对比可以看出两个模型的相似性和区别:前者使用 GBDT 来做特征的组合, 后者使用两项不同的技术来处理,首先是对 categorical feature 进行 embedding,然后和 continous feature 一起 concatenate 成一个向量,通过三层 ReLU 网络来做特征的表示学习;另一方面对于 categorical feature 还可以进行人工交叉组合,与左边网络自己学习到的特征一起加入到顶层 LR 模型里作为最终特征。
这里需要提到的一点是对于 categorical feature 的 embedding,没有使用独立的 FM 之类的方法,而是通过 joint learning 直接学习出来的,具体做法是对最 embedding 层使用类似 EM 的做法,固定 W 后使用 bp 训练向量,交替进行。和 FM 之类独立训练的 embedding 向量相比,为什么联合训练的向量可能会更好呢?这个思想起源是哪里呢?
第一个问题我认为联合训练的 embedding 向量确实会比 FM 单独 embedding 出来的要好,原因比较细微,熟悉 CF 发展流程的同学应该知道,对传统 Item-based CF 和 User-based CF 的一个改进就是将 pearson 系数替换为可以联合训练的 wij,以 capture 到数据之间 interpolation 信息。详细的介绍可以参考我下一篇关于 CF 的综述。
使用了类似 joint learning 以同时获得 embedding 向量和权重矩阵的还有 [18]。有兴趣的可以参考。
关于 WDL 的性能,普遍认为会比传统 LR 高两位数百分点,浏览器正在尝试在 app 推荐场景下做一个横屏,从目前初步结论来看,GBDT+LR 相比于纯 LR 大约是两位数的提升,而 WDL 还没有看到明显效果,不过我们会进一步在参数调优上下些功夫,以期取得更好的效果。
WDL 的缺陷主要体现在两方面,一方面是在线 predict 时的性能瓶颈决定不能使用太宽、太深的网络,另一方面是如果做 online learning,这个问题据说百度凤巢是有做过,具体方案不得而知。
9. 强化学习
[19] 对强化学习做了基本介绍,而国外对强化学习投入比较大也引起足够关注的应该是 DeepMind 以及阿尔法狗了。个人看来强化学习和监督学习的关系有如随机过程和概率论的关系。前者强调的是动态过程,后者强调的是静态概率。从这个角度讲,前面所有的点击率模型都是在追踪静态概率,哪怕使用 online learning 也只是做了某种程度的 approximation。
是否可以直接使用强化学习来做点击率或者推荐呢?答案我觉得是肯定的。这方面阿里应该是走在前沿,[20] 中提到因为采用深度强化学习和自适应学习的技术,阿里的双十一销量有 10%-20% 的提升。这是一个非常恐怖的数字,尤其是在阿里这样的体量下。请允许我引用其中一段文字来做个简单说明:
“2014 年双 11 通过排序特征实时,引入商品实时转化率,实时售罄率模型进入搜索 match 和 rank,让售罄商品额无效曝光大幅减少,并实现了成交转化的大幅提升;2015 年双 11 推出双链路实时计算体系,在特征实时的基础上,引入排序因子的在线学习,预测,以及基于多臂机学习的排序策略决策模型,在预热期和双 11 大幅提升了搜索流量的成交转化效率;2016 年实时学习和决策能力进一步升级,实现了排序因子的在线深度学习,和基于强化学习的排序策略决策模型,从而使得淘宝搜索的智能化进化至新的高度,并在今年的双 11,分桶测试效果表明,成交金额取得了近 20% 的大幅提升。”
从这段描述可以看出阿里的技术演进思路,特征实时化 ->MAB->DL->RL。这套方案能否在鹅厂或者浏览器内部找到落地场景是我比较感兴趣的一个地方,接下来也会花一些时间来调研强化学习。
结语
本文主要对笔者一段时间以来的阅读做一个小结,在机器学习领域,书籍出版是远远落后于业界知识更新的,这就逼迫我们每个从业者都需要大量阅读资料和论文,对一个已经工作几年的后台开发来说,是一个不小的挑战。
笔者为此做了不少的准备,包括花了两年的晚上时间把数学分析、概率论、线性代数、数值计算等数学基础复习一遍;然后才能够相对比较顺利地阅读 paper。在领略了一些点击率和算法的文章以后,深深感觉大家能看到的书籍太少,因此尝试做一个总结,试着梳理一个脉络,给后来者一个学习的 roadmap。然而由于本人生性驽钝,错误不实之处在所难免,唯望大家莫笑,以此顽石引出美玉,提升自己造福后人,如是而已。以上。
引用文献
[1] Predicting Clicks: Estimating the Click-Through Rate for New Ads;
[2] Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine;
[3] Practical Lessons from Predicting Clicks on Ads at Facebook;
[4] greedy function approximation:a gradient boosting machine
[5] Ad Click Prediction: a View from the Trenches
[6] Factorization Machines.SteffenRendle
[7] http://www.csdn.net/article/2015-09-30/2825828
[8] http://tech.meituan.com/deep-understanding-of-ffm-principles-and-practices.html
[9] https://zhuanlan.zhihu.com/p/21388070
[10] An Empirical Evaluation of Thompson Sampling
[11] Content-based Recommendation Systems;
[12] Predicting Clicks: Estimating the Click-Through Rate for New Ads
[13] Click-Through Rate Estimation for Rare Events in Online Advertising
[14] Wide & Deep Learning for Recommender Systems;
[15] Deep Neural Networks for YouTube Recommendations
[16] Reinforcement Learning: An Introduction
[17] http://www.10tiao.com/html/639/201703/2247484414/1.html
[18] Predictive Model Performance: Offline and Online Evaluations
本文系张红林原创文章,首发于腾云阁,已经授权 InfoQ 公众号转发传播。
作者介绍
张红林,11 年加入腾讯无线事业群做后台开发,13 年转做算法开发,先后负责小说书架数据聚合、热门视频数据聚合;15 年开始负责广告点击率预估、个性化应用分发等业务;在个性化推荐、点击率预估、用户画像方面有一些经验。
感谢蔡芳芳对本文的审校。




