
欢迎阅读新一期的数据库内核杂谈。这次拖更有点久,工作非常忙,外加疫情也反反复复(好吧,都不是拖更的理由。万幸,今年没立 flag)。本期的杂谈一起来学习一篇蒋晓伟老师发表在 VLDB2020 上的文章:Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing。本文介绍了 Alibaba 为了应对 HSAP(我理解和 HTAP 类似)的应用场景推出的云原生大数据处理引擎 Hologres。
先聊点八卦。最开始知道蒋老师,是当时他在 Microsoft 参与 SQL Server 的开发。后来知道他加入了 Facebook(现 Meta),再然后 2014 年就离职加入了 Alibaba。18 年的某个周末,我正好读到了阿里技术公众号里介绍蒋老师参与 Blink(流式系统)的工作,支撑双 11。之后就在第二天,突然有个微信加我,留言是“我是阿里蒋晓伟,知道你参与过 ORCA 的工作,下周来湾区出差,是否可以聊聊”。这之后,就在湾区的香锅大王见面,聊了很久,也吃了很多。蒋老师是个非常亲和的,对技术很执着的人。学到很多。后来断断续续有交流,这篇文章也是当时蒋老师发给我的。
什么是 HSAP,为什么需要 Hologres?
数据库场景一般分为,Online-transactional Processing(OLTP)和 Online-analytical Processing(OLAP)。前者偏重并发高,实时性要求高,数据规模小的增删改场景;后者偏重数据规模大,并发量没那么大,实时性要求没那么高的分析型场景。通常,一个数据库会根据适用场景,归类为 OLTP 数据库(比如 MySQL,Aurora)或者 OLAP 数据仓库(比如 GPDB,Redshift)。但是,用户总是希望鱼和熊掌兼得,这衍生了一系列新的数据库 NewSQL,通过技术手段来实现一个系统同时支持 OLTP 和 OLAP(比如 TiDB)。那文中提到的 hybrid serving/analytical processing(HSAP),又是什么呢?
文中,通过介绍 Alibaba 的推荐系统,展示了 HSAP 的应用场景。目前的推荐系统都重视实时推荐和精准的个性化推荐。为了满足这两点,底层的数据系统也演化到了非常复杂的设计。通过下图的架构示例,来看 Alibaba 的数据系统是如何支持推荐系统的。
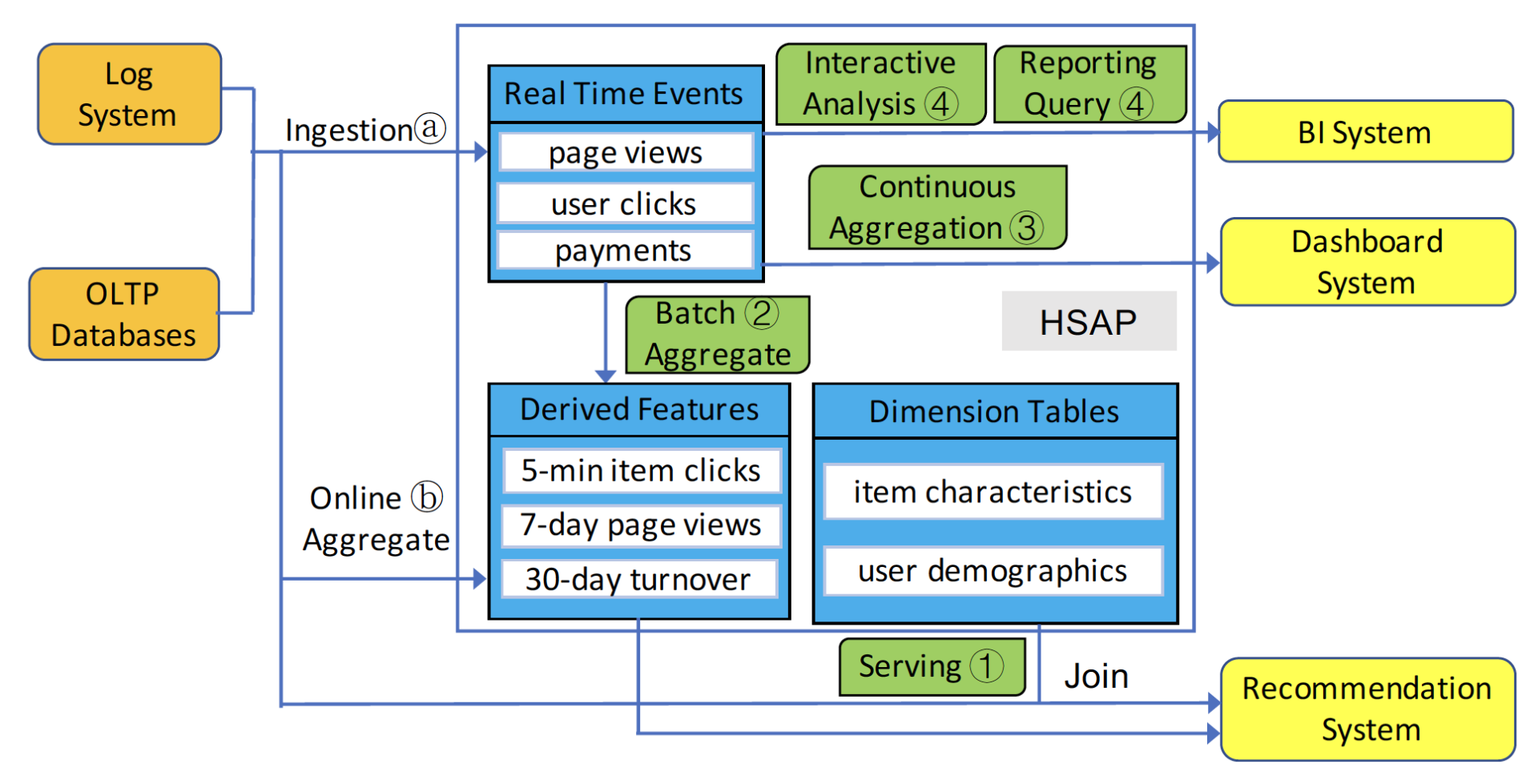
(HSAP 应用场景演示:大数据处理系统如何支持实时推荐系统)
为了支持实时的个性化推荐,需要数据系统可以实时地推送 features,并且及时更新推荐模型。通常,这些实时 feature 包含两大部分:
1)系统收集到的大量的实时消息事件,包括 log 事件(如 page view,user clicks),以及一些 OLTP 数据库里的实时事务。从量产系统来看,这些事件的 QPS 可达 10^7/S(即 1000 万每秒)。这些消息在进入数据平台【a】后,除了被用作分析应用,还会和其他 dimension 数据做 online join(低延时,高吞吐地 online join),然后生成可以被推荐系统使用的实时 feature【1】。
2)除了实时 feature,这些数据也会根据需求,被聚合到某个 sliding window 里面作为 derived feature,比如 5-min click,7-day page views,等等。这些 feature 也会被作用到推荐系统里面。这些聚合操作可以通过流式处理【b】,或者是小规模批处理【2】来实现,通常取决于 sliding window 的大小。
实时数据处理除了用来做个性化推荐,也会被用来生成训练或者评测数据来更新推荐模型。而推荐引擎自身,也只是数据使用的冰山一角。这些数据还会被用来做实时报警,业务触发,在线分析(报表)【3】,以及 a/b testing,或者离线批量查询来生成 BI 报告【4】。除此之外,data scientists 还会对数据做复杂的交互式分析来寻找新的 business insights。
总结一下,上面的介绍展示了一个复杂的 HSAP 应用场景:从实时数据接入【a】,到离线批量接入【b】。消费端分为实时消费【1】,online 聚合【3】,交付式分析查询【4】以及批量离线分析【2】。通常,需要离线和在线多套系统合作来支撑上面提到的所有业务,如离线分析使用 Hive,实时消费使用 Cassandra,online 聚合使用 Druid,交付式分析使用 Impala 或者 GPDB。
Alibaba 推出 Hologres,旨在用一套数据系统,满足上面的所有需求,即 HSAP 场景。HSAP 的挑战在于:
1)高并发的混合查询支持:相比于 OLAP 系统,HSAP 需要支持更高并发的查询语句。文中提到,在生产环境中,serving 查询的 QPS 可以达到每秒千万级别而通常 OLAP 的查询 QPS 在每秒百级别。
2)高吞吐,实时数据接入:除了从 OLTP 系统接入实时数据,还要从大量的 log event,流式系统中接入非接结构化数据。文中提到了每秒千万级别的 tuple 接入量。并且,相比于 OLAP 系统的离线数据 batch 接入,HSAP 对数据的接入实时性也有要求。
3)高扩展性和可伸缩性:数据接入和查询需求会有周期性地波峰波谷(比如双 11,618 等),因此,HSAP 系统需要支持高扩展性并且,根据数据量做弹性伸缩。文中提到,通常,波峰的数据接入量是平均状态的 2.5 倍,波峰的查询吞吐量是平均状态的 3 倍。同时,数据接入和查询的增加规模不同,系统需要支持独立扩容计算和存储。
Hologres 系统简介
了解了 HSAP 的应用场景和实现挑战,我们来看 Hologres 是如何解决这些问题的。
数据存储简介
Hologres 在数据存储中应用了下面这些设计:
1)存储计算分离:Hologres,像其他云原生的大数据处理引擎一样,使用了存储和计算分离的实现来支持异构动态扩缩容。数据存储(包含原始数据,和 log 信息)存储在 Alibaba 的盘古存储引擎上(也支持开源的分布式存储如 HDFS)。
2)tablet-based Data layout(我把它翻译成小文件块数据管理):数据文件和 Index 文件都以一个一个 tablet 数据块形式进行管理。写操作会被分为多个小 task,并分发到相应的数据块进行操作。有关联的表和 index 的数据块们,根据对应的 primary key,会被分配到一个 shard 上,一个 shard 的数据在物理上是存储在一台机器上的来提高数据一致性和联合读取响应。Hologres 采用了 latch-free(lock-free)的设计来避免数据写竞争,并且保证每一个数据块只有一个写操作但可以同时有多个读操作。为了进一步提升读性能,Hologres 支持配置很高的并发读(甚至可以从一个 remote 服务器上做读取操作)。
3)读写分离设计:为了同时支持高性能高吞吐量的写入和查询,Hologres 采用了读写分离设计:写操作使用 LSM-tree 类似的结构来做高速地写入并进行版本记录,而读数据可以从一个稳定版本中读取数据。(其实 Hologres 的另一个创新在于对于每个 tablet,支持 row-store 和 column-store,来分别支持点查询和分析型查询,在后文中会介绍)。
执行器简介
为了支持高性能地语句执行操作,Hologres 在执行器上也有创新。
1)引入 Execution Context: 这个,我理解为轻量级的协程(文中也写了,引入了一个用户态的线程 execution context,这个 execution context 非常轻量级,可以低成本地创建和销毁)。Hologres 的调度引擎 HOS,把这些 EC 调度在操作系统的线程池上。EC 提供了异步的任务接口来提升性能。HOS 会把读写任务分别调度到分管读写的 EC 上。并且,EC 池可以快速地根据任务需求来扩缩容。
2)支持不同的调度策略和分组管理:HOS 将调度策略和 EC 调度抽离出来,支持将不同的查询语句按照类型调度到不同的 EC 组里。HOS 负责管理所有 EC 组确保资源隔离和调度公平性。
架构图 + 总结
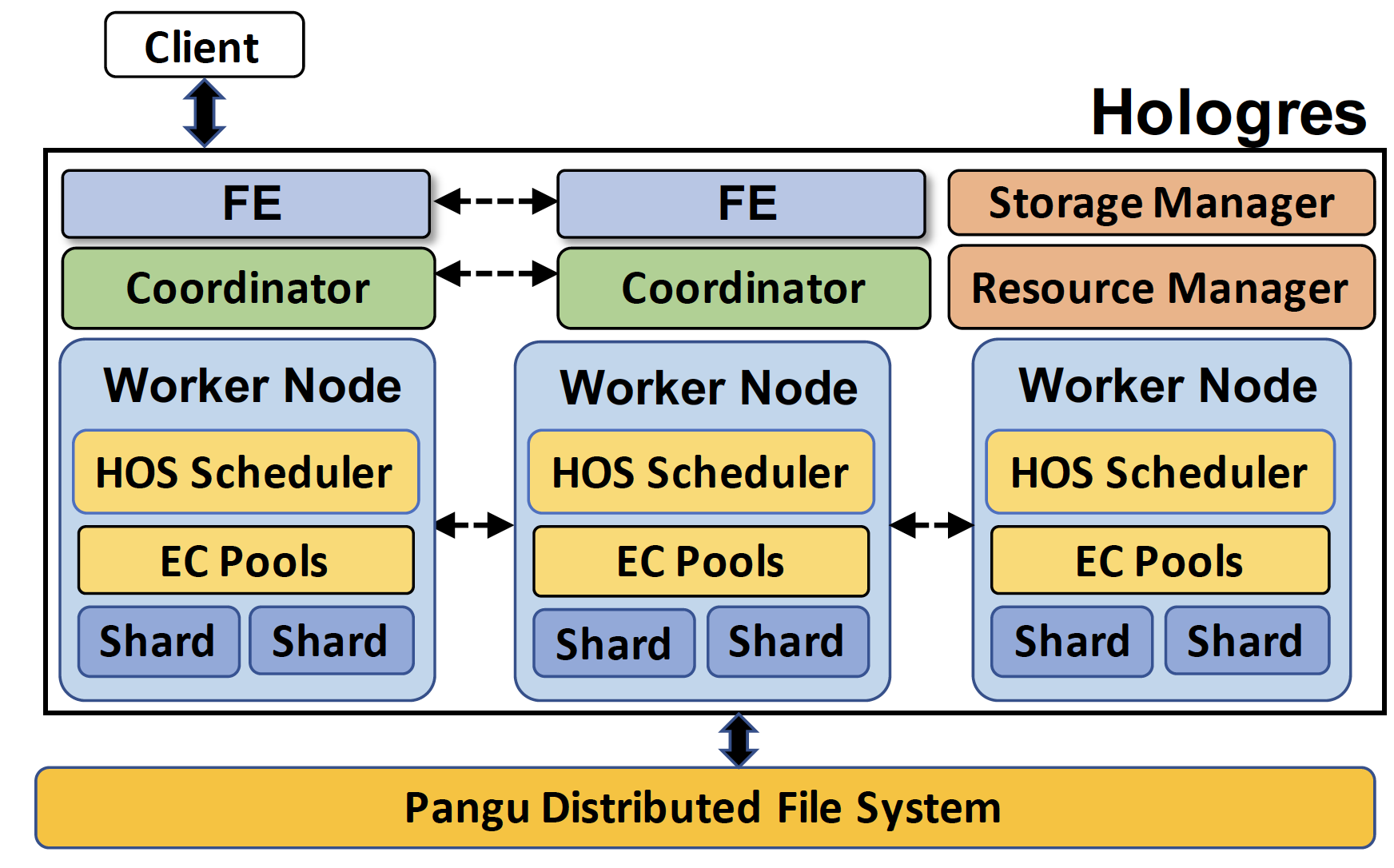
(Hologres 架构图)
本文的最后,结合架构图来看一下 Hologres 的整体设计。用户提交的所有操作和查询都会打到最上层的 Front-end nodes(FE)。对于每一个语句,FE node 里面的优化器(query optimizer)会生成执行 plan DAG,并通过 Coordinator 节点发送到各个 worker 节点上。每个 worker 节点都有 local 的 HOS 调度器和 EC 资源池来对接到的任务进行执行。Resource manager 记录着数据在不同 worker 节点上的分布,同时也负责动态地新增和删除 worker 节点(worker 节点通过发送周期心跳和 resource manager 来告知目前状态)。Storage manager 记录着 worker 节点里的数据 shard 信息(key range 和 metadata,包括在盘古存储的路径等等)。
说一些自己不成熟的思考。HSAP 和 HTAP 类似,都是希望通过一个系统来实现更全面,更复杂的应用场景。两边的实现也类似,把复杂度留给系统,把简单的接口留个用户。对用户而言,接口就是简单,统一的 SQL。对系统内部,可以通过 RAFT 将 row-store 同步到 column-store 来更好地支持 analyitcal 查询,也可以像 Hologres 那样,直接实现两套存储针对不同的 workloads。通篇读下来,HSAP 和 HTAP 的区别在于,HSAP 没有过分强调事务的一致性和分布式事务的支持(虽然有些,可以通过异步的方式支持分布式事务,并且从架构层面也提到,数据的来源就是 OLTP 数据库),而是突出更高吞吐量的数据写入和实时点查询以及分析型查询。
下一篇,我们一起来学习存储和执行器的细节。感谢阅读!
2022 年,虽然不立 flag,但还是想做出一些改变。创建了一个数据库内核杂谈交流群,如果你是忠实读者,欢迎加入交流。





