关键点
- 了解数据科学学科需要的不同角色和相应的技能;
- 如何引领数据科学 Python 生态系统的发展;
- 就一个人(数据科学家)和一个团队(数据科学团队)而言数据科学的责任;
- 数据科学团队想在他们的领域做得更出色所要解决的挑战;
- 在数据科学领域的未来趋势;
数据科学是使用机器学习和预测性分析技术与工具等从数据(结构型和非结构型)中获取洞察,以此设计和开发解决方案。把数据科学做为一个学科和把数据科学家做为一个角色,最近这些年这两件事已经吸引了越来越多的注意力,将获得从欺诈检测到推荐引擎等等各种解决方案,用以解决现实世界中出现的问题。
Christine Doig 是 Continuum Analytics 公司的高级数据科学家,在今年的 OSCON 大会上做了一次演讲,主题是把数据科学做为一门团队学科,以及如何引领数据科学 Python 生态系统的发展。
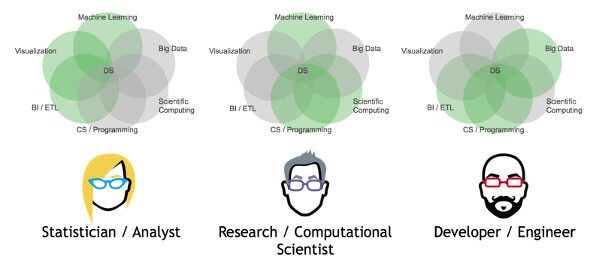
她谈到了如何从数据过渡到模型,再过渡到应用程序。Christine 也谈到了数据科学学科需要的不同的角色和技能:统计学家、计算科学家和开发者等。
她也进一步提到了这些角色的可交付成果。
- 统计学家:洞察、预测、可视化表达;
- 计算科学家:算法、库、性能;
- 开发者:软件、应用程序、容器;
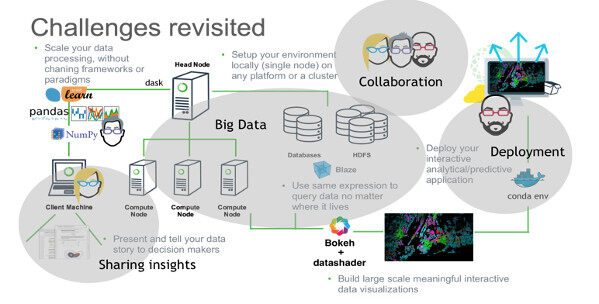
数据科学团队在许多领域都面临着挑战,比如合作、大数据、部分与分享洞察等等。
- 合作:让各式各样的数据团队(语言、工具、数据模型、交付物等)可以有效地合作;
- 大数据:让数据科学家(统计、分析)可以方便地使用大数据基础架构;
- 部署:将预测性模型部署到生产应用中;
- 分享洞察:与决策者分享洞察;
她也谈到了 Continuum Analytics 公司对 Python 生态圈做出的一些贡献,主要是象 Bokeh 、 Datashader 、 Dask 和 Blaze 等框架。
InfoQ 采访了 Christine,讨论了把数据科学做为一门团队学科,以及在大数据领域和公司内的数据科学初创团队中,数据科学团队要变得更高效所要解决的挑战。
InfoQ:您能定义一下数据科学吗?
Doig:根据维基百科的定义,数据科学是一门关于处理和系统的跨学科的研究领域,用于从各种不同形式的数据中获取知识或洞察。我倾向于把它当成粘合剂,把不同的领域和不同的想法引导到一起来,通常是解决关于数据的问题,以及把信息转换成知识或可以采取行动的洞察。
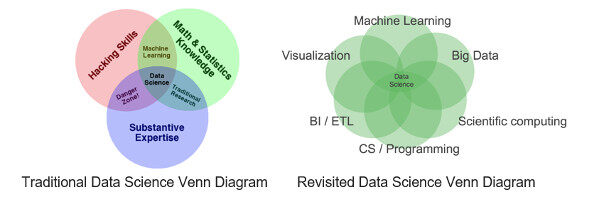
InfoQ:您能再谈谈在您的演讲中提到的数据科学文氏图吗?
Doig:我想把传统的数据科学图重构成基于领域的,要包含那些在传统里落在大家讨论范围之外的领域,比如数据可视化、传统分析学和商业智能等等。即使数据科学是一个新的词汇、新领域,也还是已经有很多商务人士、研究者和科学家们,已经对一些难题进行了相当长时间的研究,数据科学完全是建立在他们的成果基础之上的。
数据科学并不仅仅是机器学习。它还需要其他完全不同的领域内的知识。
- 可视化与讲故事:你如何把数据可视化并呈现给不同的观众呢?
- 商业智能、ETL 与数据库:你如何存储、抽取和转换数据?要从你的业务信息中挖掘出价值来,你到底需要些什么?
- 机器学习、统计学与人工智能
- 计算机科学与编程:我们该如何实现定制的流程和算法,以满足我们的业务对数据的需求?
- 科学计算与高性能计算:科学家们已经花了很长的时间去研究高性能计算和科学库,我们该怎样利用他们的研究成果?
- 大数据:伴随着数据量的不断增长,我们该如何扩展我们的处理和分析?
InfoQ:您能谈谈作为单个人(数据科学家)和作为一个团队(数据科学团队)时的数据科学责任吗?
Doig:因为在关于数据科学的正式教学出现以前,对数据科学家的需求就产生了,所以现在有着数据科学家的头衔的人的背景五花八门:统计学、数学、计算机科学、科学、运营研究、商业、人工智能,等等。因此,当我们组建一支数据科学团队的时候,公司就应该把注意力放在让团队成员可以相互辅助这一点上,在技能和知识两方面都是。千万别试着努力去寻找那些罕见的可称之为独角兽的所谓“数据科学家”。因为涉及的领域众多,因此不可能有哪个人会对每一个领域的掌握都非常深入。数据科学是一种团队活动,相应的,不同的队员有着不同的角色。他们对于这个游戏应该有着共同的理解,但又各自发挥所长各司其职。
InfoQ:在公司里数据科学团队要把效率变得更高,要解决哪些挑战呢?
Doig:我觉得数据科学团队主要面临着下面这几点挑战:
- 让团队之间合作得更有效:因为大家各自背景不同,每一位数据科学家都有自己偏爱的工具、语言等。很多时候他们还是习惯于在自己的笔记本电脑或者工作站上工作,搭建起自己喜欢的工作环境。因此,分享分析成果和合作永远都不是一件小事,比如搭建工作环境、软件包版本管理、运行云服务,等等。非常重要的一点是要确保你的团队的所有成员加起来可以拥有所有这些技能,这样你的数据科学家们就可以相互依靠。
- 利用大数据基础架构:大型公司都在应用着各种大数据基础架构,但对于数据科学家们来说,他们还需要花些时间才能把这些基础架构用起来,进而用熟用好,主要原因是他们所要用到的算法在相应的生态圈里面未必找得到,而且相应的新的工作流程他们也并不熟悉。
- 把预测性模型应用到生产中:数据科学团队在把他们的预测分析模型生产化、部署到生产环境中时总是非常痛苦。
- 与决策者分享洞察:要让公司的决策层理解在公司中数据团队的价值是一件非常有挑战的事。他们该怎样把复杂的数学模型翻译成投资决策过程的一个决定呢?在公司里该怎样才能把这些模型中提取出来的洞察投入实践呢?多讲讲故事,多提提数据,这样的做法都会有好处。
InfoQ:一个理想的数据科学团队的工作流看起来该是怎样的?
Doig:我觉得理想中,一个数据科学团队应该:
- 与经理们和决策者们分享洞察,即要保证团队在为公司业务增加价值,也要保证这些洞察最终会落实到行动,而这些些行动的影响最终会被跟踪到、被大家所理解。
- 有效地利用大数据技术。公司应该确保他们不只是在为分布式环境购买基础设施,还要确保他们的数据科学家有正确的工具可用,可以让他们轻松地从一个本地环境切换到一个分布式的环境里,不要花费太多代价。
- 在团队里合作和分享他们的分析成果,确保有流程可以展示数据科学的成果,并做好内部发布。与工程团队的密切合作是非常必要的。
InfoQ:数据科学家们和工程师们有什么工具可以用来做数据分析?
Doig:在数据科学和工程方面有很多不同的编程语言可用:Python、R、Scala、Java、Julia 和 Stan 等。他们都各自有自己的生态系统,有很多包,可以满足不同的数据科学需要。
InfoQ:您能谈谈在您的数据科学的项目中使用 Python 生态系统以及工具的情况吗?
Doig:在过去的二到四年里,Python 数据科学生态系统获得了迅猛发展。它有一个非常棒的社区,有非常成熟的开源库可供科学研究和矩阵计算使用,这些都是算法开发的基础。很多用户在从商业工具转移到像 SAS、Matlab 或 R 之类的语言上来,因为它们都非常通用,而且库也非常多。
InfoQ:在数据科学领域接下来会是怎样的发展趋势?特别是当它成为一门团队学科之后?
Doig:我们已经看到越来越多人开始产生了浓厚的兴趣,主要是深度学习、更好的可视化库来展示大数据集、以及让大数据技术对数据科学家越来越容易使用等。
关于受访者
 Christine Doig是一位供职于 Continuum Analytics 公司的数据科学家。Christine 非常喜欢 Python,喜欢与别人分享她在开源世界里的新发现。在 EuroPython、PyTexas、PyGotham、PyCon Spain、PyData (Dallas, Berlin)、SciPy 以及一些本地研讨会上,她会教授一些课程,也做了许多讲座,主要是关于数据科学方面和 conda、Blaze、Bokeh 和 scikit-learn 等 Python 库。在她的空闲时间里,Christine 喜欢旅游和发 Twitter 消息。
Christine Doig是一位供职于 Continuum Analytics 公司的数据科学家。Christine 非常喜欢 Python,喜欢与别人分享她在开源世界里的新发现。在 EuroPython、PyTexas、PyGotham、PyCon Spain、PyData (Dallas, Berlin)、SciPy 以及一些本地研讨会上,她会教授一些课程,也做了许多讲座,主要是关于数据科学方面和 conda、Blaze、Bokeh 和 scikit-learn 等 Python 库。在她的空闲时间里,Christine 喜欢旅游和发 Twitter 消息。




