一个出发点
当谈起软件设计的目的时,能够获得所有人认同的答案只有一个:功能实现。 因为这是一个软件存在的根本原因。
而在计算机软件发展的初期,这一点也正是所有人做软件设计的唯一动机。因而,很自然的,整个软件都被放在单一过程中,然后用到处存在的 goto 语句控制流程。
尽管理论上讲,任意复杂的系统都可以被放入同一个函数里。但随着软件越来复杂,即便是智商最为发达的程序员也发现,单一过程的复杂度已经超出他的掌控极限。这逼迫人们必须对大问题进行分解,分而治之。
时至今日,尽管超大函数,上帝类依然并不罕见,但当大到一定程度,上帝类的创造者最终也会发现自己终究没有上帝般的掌控力。因而,哪怕是软件设计素养为负值的开发者,或多或少也会对一个复杂系统进行一定程度的拆分。
这就是模块化设计的最初动机。
两个问题
一旦人们开始进行进行模块化拆分,就必须解决如下两个问题:
- 究竟软件模块该怎样划分才是合理的?
- 将一个大单元划分为多个小单元之后,它们之间必然要通过衔接点进行合作。如果我们把这些衔接点看作 API,那么问题就变为:怎样定义 API 才是合理的?
更简单的说:怎么分?然后再怎么合?
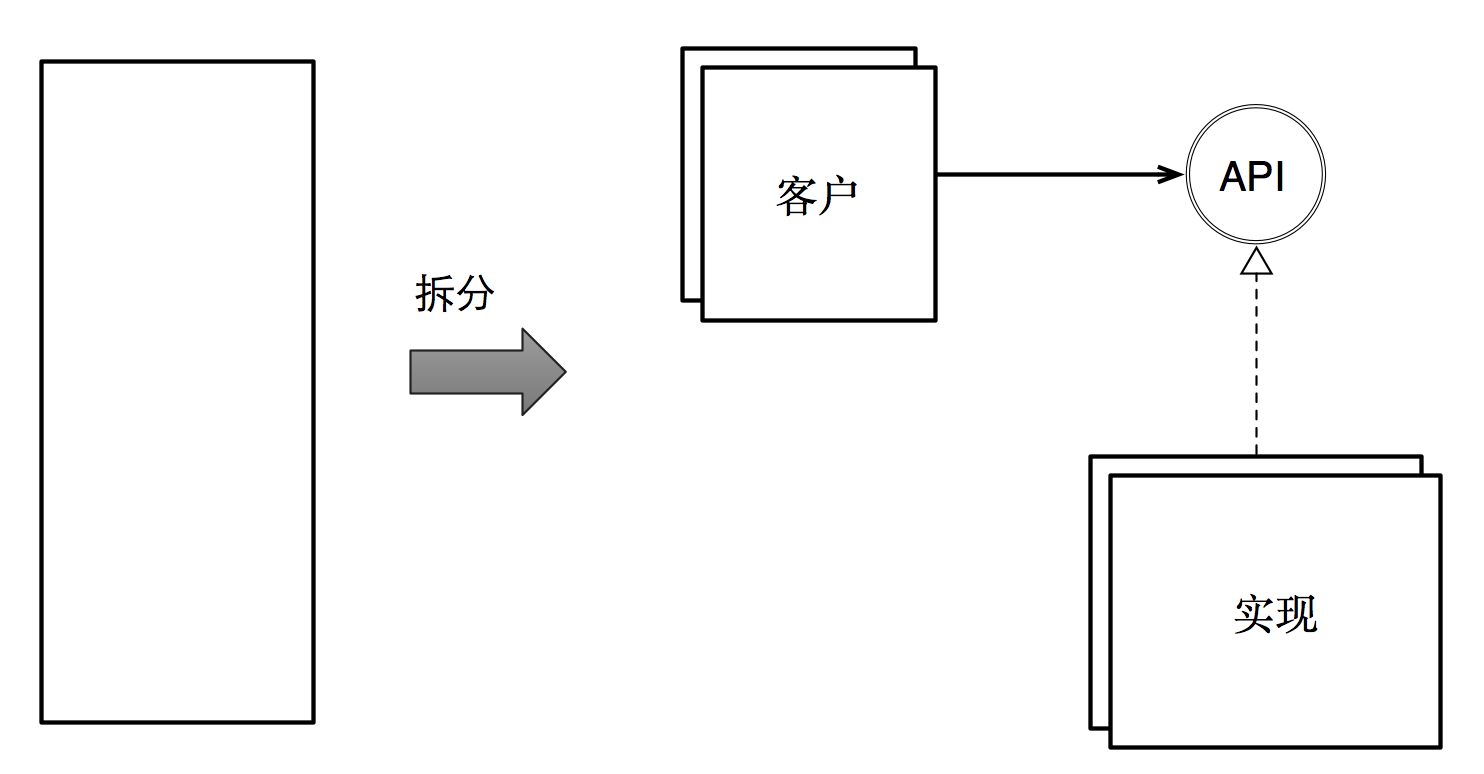
而这两个问题的答案,正是现代软件设计的核心关注点。
三方关系
为了找到这两个问题的答案,我们需要重新回到最初的问题:为何要做软件设计?
Kent Beck 给出的答案是:软件设计是为了在让软件在长期范围内容易应对变化。
在这个精炼的定义中,包含着三个关键词:长期,容易,变化。这意味着:
- 越是需要长期维护的项目,变化更多,也更难预测变化的方式 ;
- 软件设计,事关成本 ;
- 如何在难以预测的千变万化中,保持低廉的变更成本,正是软件设计要解决的问题。
对此,Kent Beck 提出了一个更为精炼的原则:局部化影响。意思是说:我们希望,任何一个变化,对于我们当前的软件设计影响范围都可以控制在一个尽量小的局部。
这当然是所有严肃的软件从业者都梦寐以求的。
可问题在于,如何才能做到?
内聚与耦合
每个读过基础软件工程教程的人都知道:一个易于应对变化的软件设计应该遵从高内聚,低耦合原则。
所谓内聚性,关注的是一个软件单位内部的关联紧密程度。因而高内聚追求的是关联紧密的事物应该被放在一起,并且只有关联紧密的事物才应该被放在一起。简单说,就是 Unix 的设计哲学:
Do One Thing, Do It Well。
而耦合性,则是强调两个或多个软件单位之间的关联紧密程度。因而低耦合追求的是,软件单位之间尽可能不要相互影响。
这样的解释,对于很多人而言,依然会感到过于抽象。但如果我们进一步思考,就会意识到:看似神秘的内聚与耦合,正好对应最初的两个问题:
- 当我们划分模块时,要让每个模块都尽可能高内聚;
- 而当我们定义模块之间的 API 时,需要让双方尽可能低耦合。
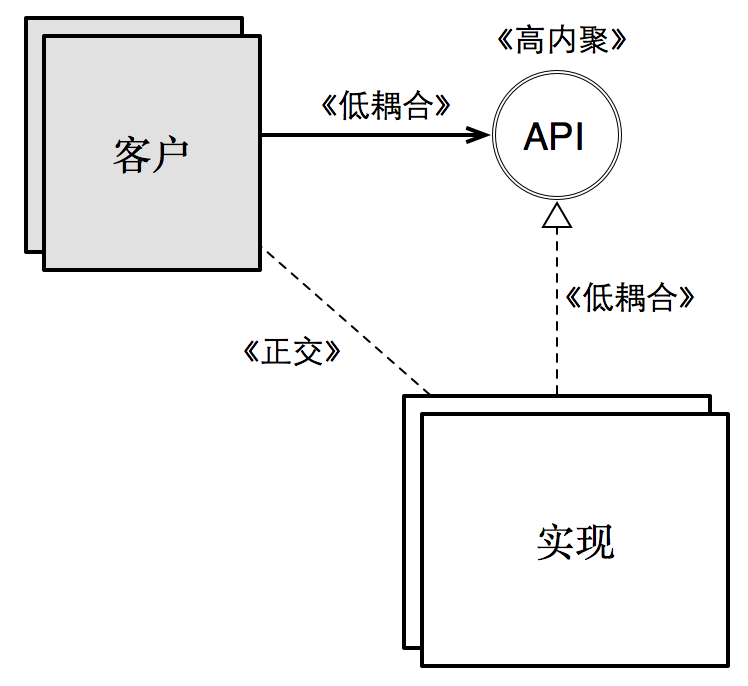
如果用图来展现,就是下面的过程与关系:
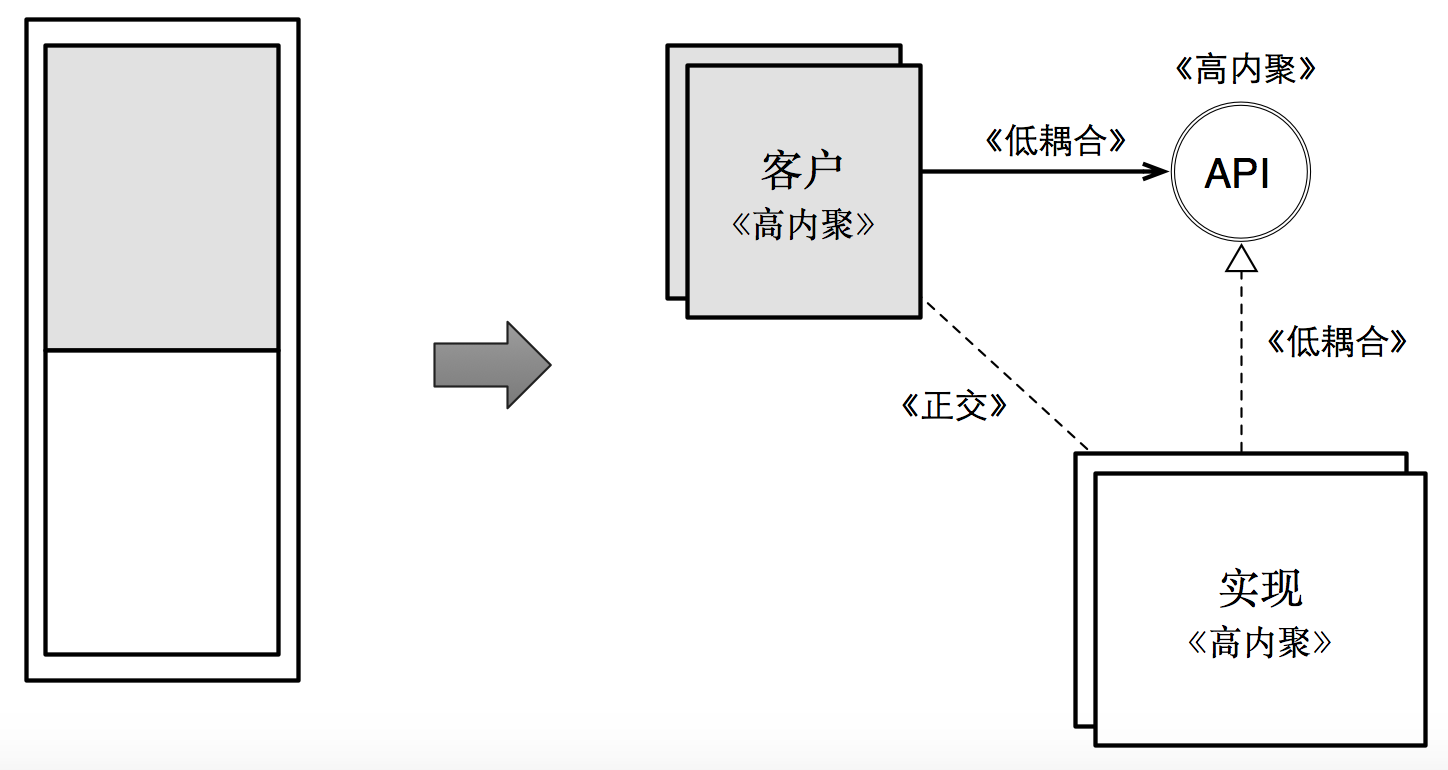
这幅图揭示了模块化设计的全部:首先将一个低内聚的模块首先拆分为多个高内聚的模块;然后再考虑这多个模块之间的 API 设计,以降低这些高内聚的软件单元之间的耦合度。
除了内聚与耦合之外,上面这幅图还揭示了另外一种关系:正交。具备正交关系的两个模块,可以做到一方的变化不会影响另外一方的变化。换句话说,双方各自独自变化,互不影响。
而这幅图的右侧,正是我们模块化的目标。它描述了永恒的三方关系:客户,API,实现,以及它们之间的关系。这个三方关系图清晰的指出了我们应该关注的内聚性,耦合性,以及正交性都发生在何处。
四个策略
相对于局部化影响,高内聚, 低耦合原则已经清晰和具体许多。但依然更像是在描述目标或结果,而没有指明该如何达成的方法。虽然《代码大全》列举了那么多的内聚性和耦合性的分类,但对于想应用它们的软件设计人员,依然感觉如隔靴挠痒,不得要领。
因而,我们需要从它推导出更为明确,更具指导性和操作性的设计原则。
为了做到这一点,我们必须首先搞清楚:内聚与耦合,和变化之间的关系是怎样的,以至于高内聚、低耦合的模块化方式能够更容易应对变化?
我们再次回顾内聚与耦合的定义:它们是用来衡量代码元素之间的关联紧密程度。很容易得知:元素之间的关联紧密程度越高,一个变化引起它们相互之间都发生变化的可能性就越高。反之,关联程度越弱,变化引起的连锁变化的概率就越低。
因而,我们要把容易互相影响的、关联程度紧密的元素,都封装在一个模块内部(而这正是我们老生常谈的封装变化的动机);同时让模块之间的关联紧密程度尽可能降低,以让模块间尽可能不要相互影响。从而最终做到局部化影响。
因而,Uncle Bob 说:一个类只应该有一个变化原因。他进一步谈到:所谓一个变化原因,指一个变化会导致整个类所包含的各个元素都要发生变化。为何会如此?因为它们的关联程度太紧密 (因而高内聚),以至于牵一发而动全身。
因此,Uncle Bob 将职责定义为变化原因。
在一些时候,我们可以直接判定一个模块是否包含多重职责。因为它们确实包含着明显没有什么关联的两组代码元素。
但在另外一些场景下,我们则无法清晰的判定:一个模块是否真的包含多重变化原因,或多重职责。比如如下代码:
struct Student
{
char name[MAX_NAME_LEN];
unsigned int height;
};
void sort_students_by_height(Student students[], size_t num_of_students)
{
for(size_t y=0; y < num_of_students-1; y++)
{
for(size_t x=1; x < num_of_students - y; x++)
{
if(students[x].height > students[x-1].height)
{
SWAP(students[x], students[x-1]);
}
}
}
}
这是一个对学生按照身高从低到高进行排序的算法。对于这段代码,如果我们进行猜测,会发现很多点都有变化的可能,如果对这些变化都进行分离和管理,确实会提高系统的内聚度。但如果我们现在就将整个系统每个可能的变化点都分离出来,无疑会让整个系统陷入无边无际的不必要的复杂度。
破解这类难题的方法是:既然我们知道高内聚,低耦合的设计是为了软件更容易应对变化的,那么我们为何不反过来,让实际发生的需求变化来驱动我们识别变化,管理变化,从而让我们的系统达到恰如其分的内聚度和耦合度?
策略一:消除重复
首先进入我们射程的就是重复代码。编写重复代码不仅仅会让有追求的程序员感到乏味。真正致命的是:“重复”极度违背高内聚、低耦合原则,从而会大幅提升软件的长期维护成本。
我们之前已经讨论过,所谓高内聚,指的是关联紧密的事物应该被放在一起。没有比两段完全相同的代码关联更为紧密。因而重复代码意味着低内聚。
而更为糟糕的是,本质重复的代码,其实都在表达(即依赖)同一项知识。如果它们表达(即依赖)的知识发生了变化,这些重复的代码统统都要修改。因而, 重复代码也意味着高耦合。
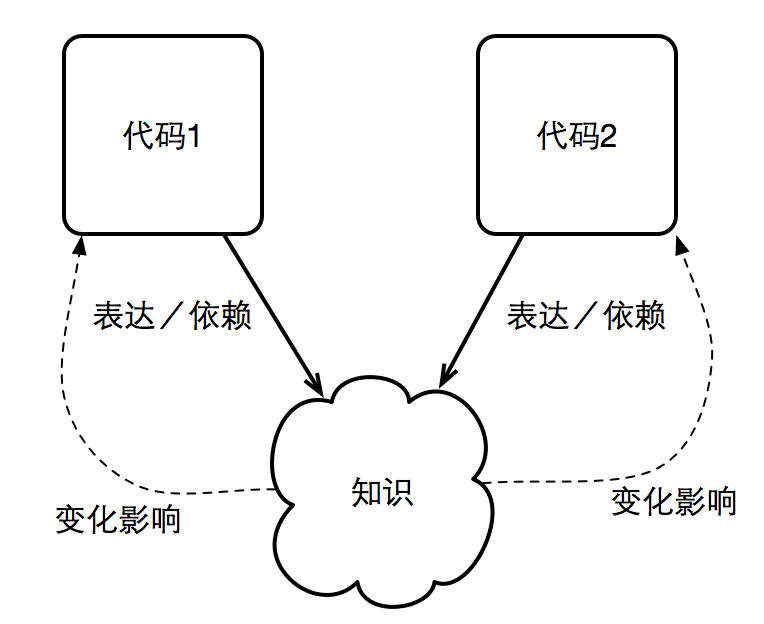
因而,对于完全重复的代码进行消除,合二为一,会让系统更加高内聚、低耦合。
而更为关键的是:如果两个模块之间是部分重复的,则发出了一个重要的信号:这两个模块都至少存在两个变化原因,或两重职责。
如下图所示,两个模块存在着部分重复。站在系统的角度看,它们之间存在着不变的部分(即重复的部分);也存在变化的部分(即差异的部分)。这意味着这两个模块都存在两个变化原因。
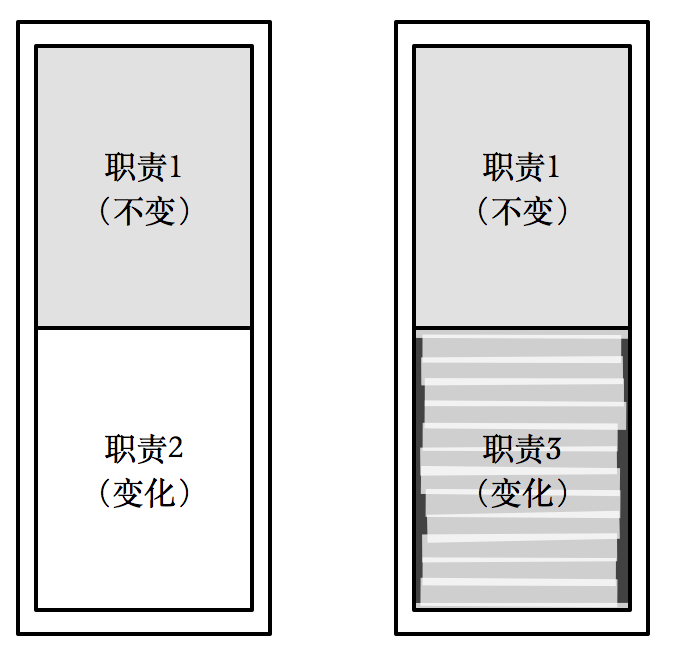
对于这一类型的重复,比较典型的情况有两种:调用型重复,以及 _ 回调型重复 _。它们的命名来源于:在
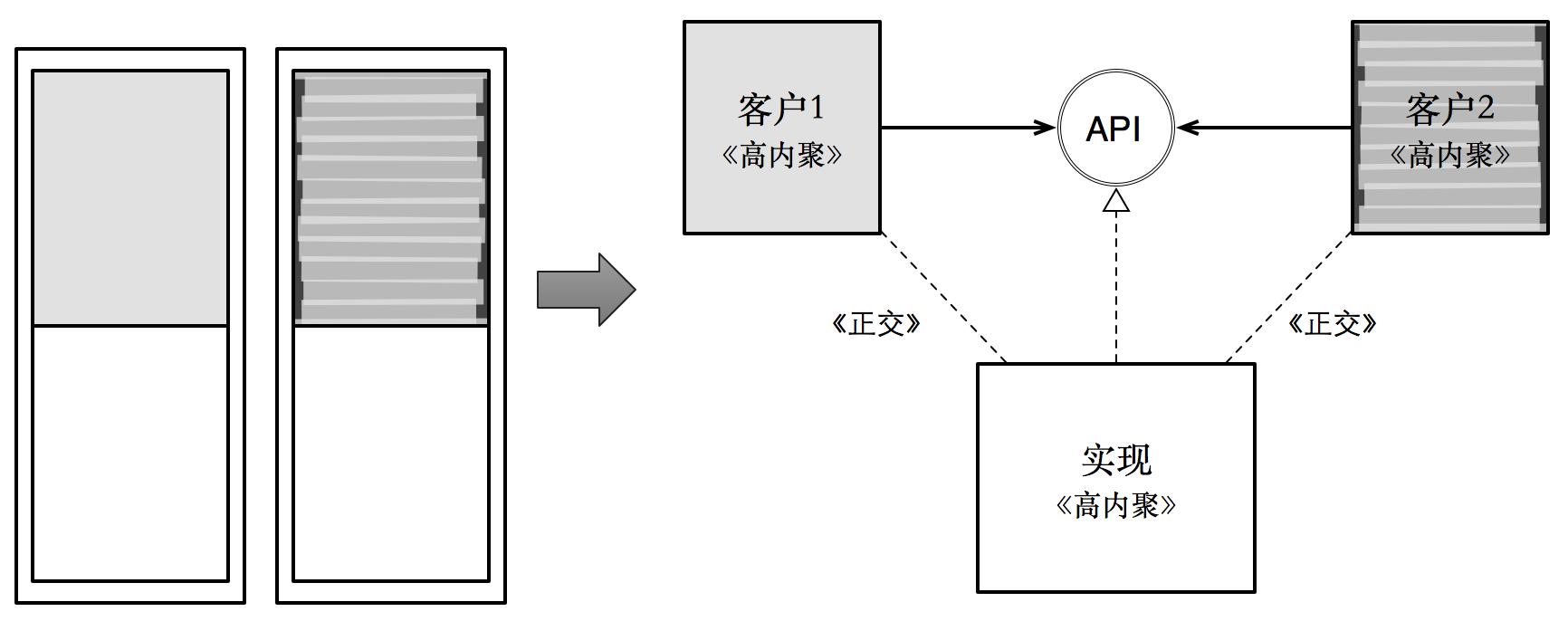
由此,我们得到了第一个策略:消除重复。
这个策略,非常明确,极具可操作性:当你看到重复时,尽力消除它。
这个策略,明显提高系统的内聚性,降低了耦合性。除此之外, 还得到一个重大收益:可重用性。事实上,消除重复的过程,正是一个提高系统可重用性的过程。
另外对于回调型重复的消除,也是一个提高系统可扩展性的过程。
策略二:分离不同的变化方向
除了重复代码外,另外一个驱动系统朝向高内聚方向演进的信号是:我们经常需要因为 _ 同一类原因 _,修改某个模块。而这个模块的其它部分却保持不变。
比如,在之前我们对学生按照身高从低到高排序的例子中,如果现在我们需要增加对老师按照身高从低到高排序的需求,我们就知道,排序对象是一个新的变化方向。于是,我们将代码重构为:
template
void bulb_sort(T objects[], size_t num_of_objects)
{
for(size_t y=0; y < num_of_objects - 1; y++)
{
for(size_t x=1; x < num_of_objects - y; x++)
{
if(objects[x].height > objects[x-1].height)
{
SWAP(objects[x], objects[x-1]);
}
}
}
}
如果随后又出现一个新的需求:按照学生身高从高到低排序(原来为从低到高)。此时我们知道排序规则也是一个变化的方向。因此,我们将这个变化方向也从现有代码中分离出去。然后得到:
template
void bulb_sort(T objects[], size_t num_of_objects)
{
for(size_t y=0; y < num_of_objects - 1; y++)
{
for(size_t x=1; x < num_of_objects - y; x++)
{
if(objects[x] > objects[x-1])
{
SWAP(objects[x], objects[x-1]);
}
}
}
}
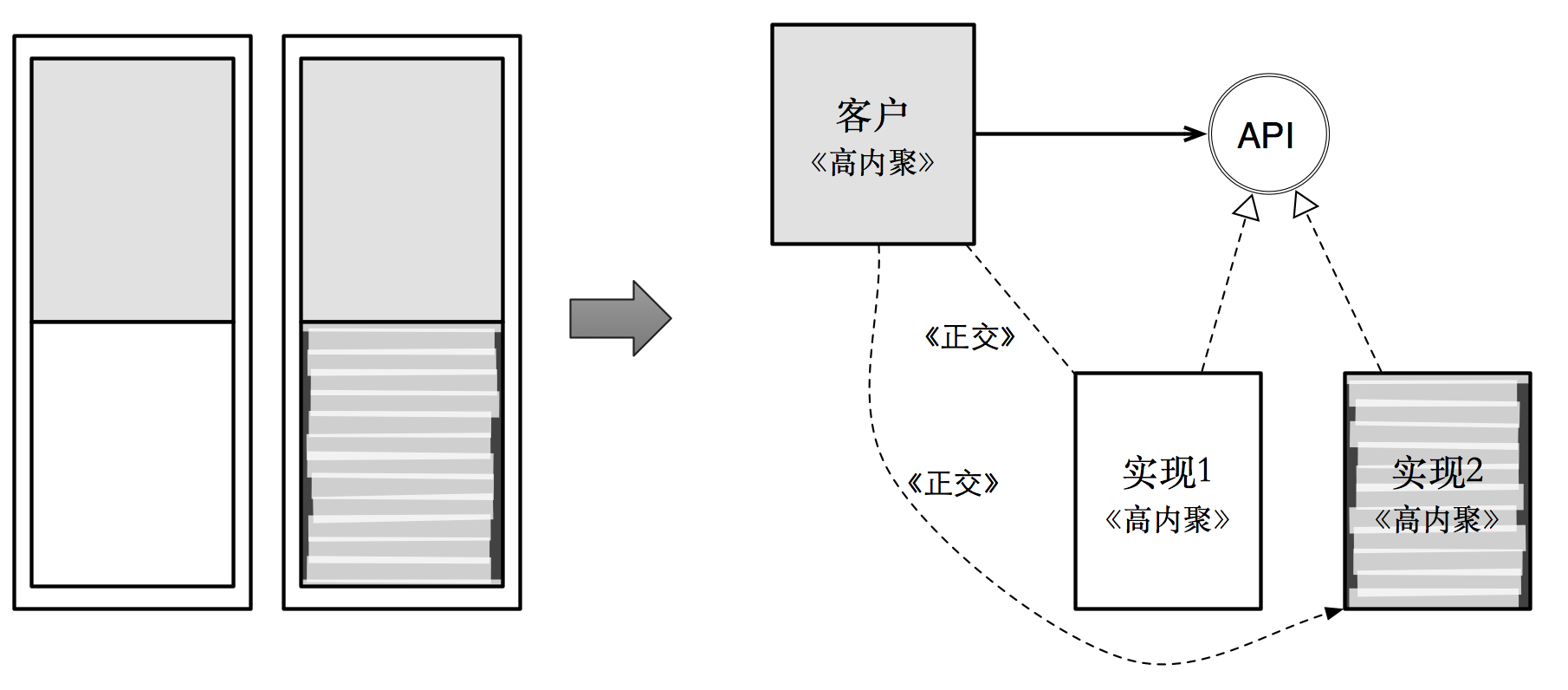
分离不同变化方向,目标在于提高内聚度。因为多个变化方向,意味着一个模块存在多重职责。将不同的变化方向进行分离,也意味着各个变化方向职责的单一化。
从这个例子可以看出,此策略的应用时机也非常明确:当你发现需求导致一个变化方向出现时,将其从原有的设计中分离出去。
对于变化方向的分离,也得到了另外一个我们追求的目标:可扩展性。
如果我们足够细心,会发现策略消除重复和分离不同变化方向是两个高度相似和关联的策略:
它们都是关注于如何对原有模块进行拆分,以提高系统的内聚性。(虽然同时也往往伴随着耦合度的降低,但这些耦合度的降低都发生在别处,并未触及该如何定义 API 以降低客户与 API 之间耦合度)。
另外,如果两个模块有部分代码是重复的,往往意味着不同变化方向。
尽管如此,我们依然需要两个不同的策略。这是因为:变化方向,并不总是以重复代码的形式出现的(其典型症状是散弹式修改,或者 if-else、switch-case、模式匹配);尽管其背后往往存在一个以重复代码形式表现的等价形式(这也是为何 copy-paste-modify 如此流行的原因)。
策略三:缩小依赖范围
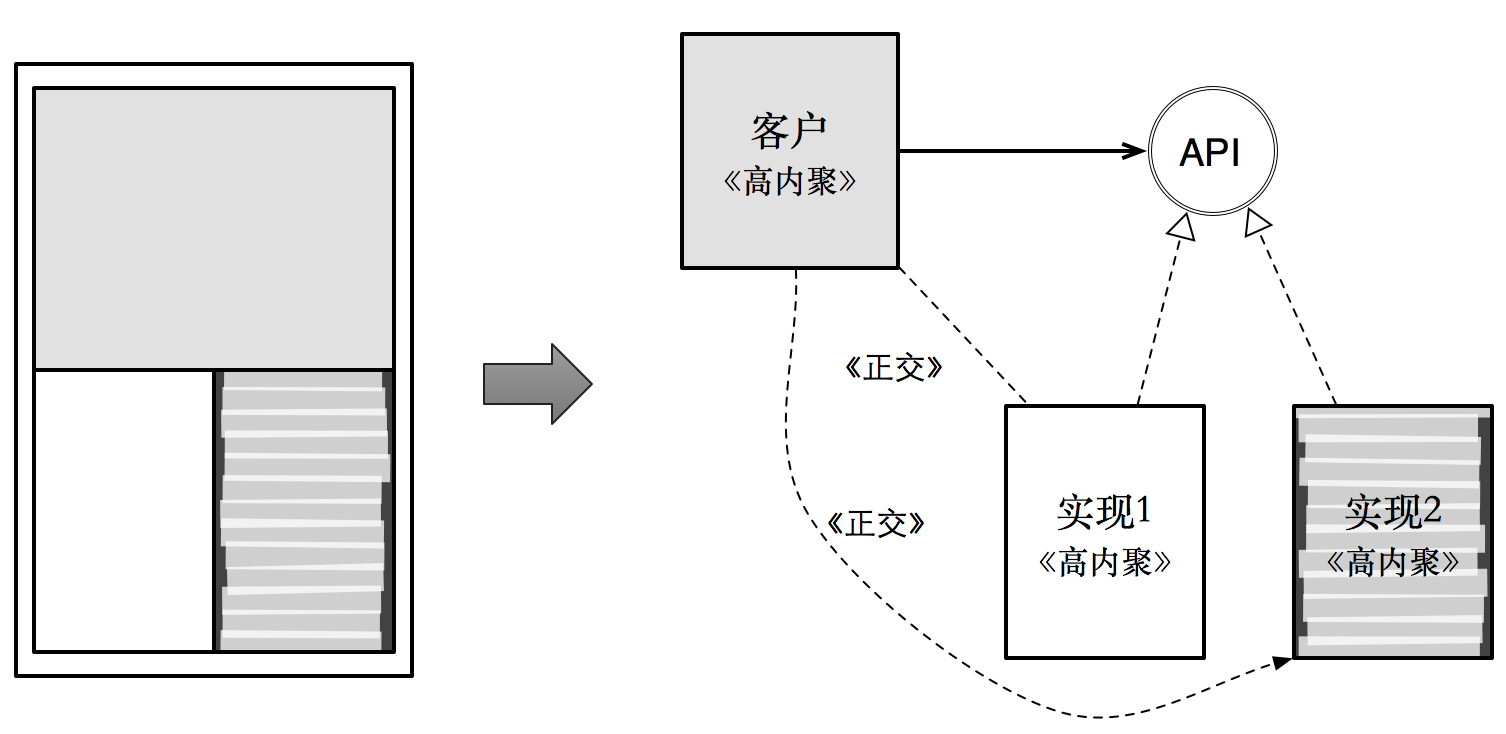
前面两个策略解决了软件单元该如何划分的问题。现在我们需要关注模块之间的粘合点——即 API——的定义问题。
需要强调的是:两个模块之间并不存在耦合,它们的都共同耦合在 API 上。因而 API 如何定义才能降低耦合度,才是我们应该关注的重点。
从这幅图可以看出,对于 API 定义所带来的耦合度影响,需要遵循如下原则:
- 首先,客户和实现模块的数量,会对耦合度产生重大的影响。它们数量越多,意味着 API 变更的成本越高,越需要花更大的精力来仔细斟酌。
- 其次,对于影响面大的 API(也意味着耦合度高),需要使用更加弹性的 API 定义框架,以有利于向前兼容性。
而具体到策略缩小依赖范围,它强调:
- API 应包含尽可能少的知识。因为任何一项知识的变化都会导致双方的变化 ;
- API 也应该高内聚,而不应该强迫 API 的客户依赖它不需要的东西。
策略四:向着稳定的方向依赖
但是,无论我们如何缩小依赖范围,如果两个模块需要协作,它们之间必然存在耦合点 (即 API)。降低耦合度的努力似乎已经走到了尽头。
我们知道,耦合的最大问题在于:耦合点的变化,会导致依赖方跟着变化。但这也意味着,如果耦合点从来不会变化,那么依赖方也就不会因此而变化。换句话说,耦合点越稳定,依赖方受耦合变化影响的概率就越低。
由此,我们得到最后一个策略:向着稳定的方向依赖。
那么,究竟什么样的 API 更倾向于稳定?不难知道,站在 What,而不是 How 的角度;即
站在需求的角度,而不是实现方式的角度定义 API,会让其更加稳定。
而需求的提出方,一定是客户端,而不是实现侧。这就意味着,我们在定义接口时,应该站在客户的角度,思考用户的本质需要,由此来定义 API。而不是站在技术实现的方便程度角度来思考 API 定义。
而这正是封装或信息隐藏的关键。
小结
这四个策略,前两者聚焦于如何划分模块,后两个聚焦于如何定义模块间的 API。换句话说,前两者关注于“如何分”,后两条聚焦于“怎么合”。
这四个策略的背后动力非常明确:变化。前两者,都是在明确的变化方向被第一次识别之后(所谓第一颗子弹),进行策略运用,以让模块在变化面前越来越高内聚。而后两者,则是在模块职责分离之后,需要定义模块间 API 时,尽可能考虑不同的 API 定义方式对于依赖双方的影响,以达到低耦合。
由于这四个策略致力于让系统朝着更具正交性的方向演进,因而它们也被称做正交策略,或者正交四原则。
总结
本文首先从一个出发点出发:为了降低软件复杂度,提升可重用性,我们需要模块化。
由此得到了两个问题:模块划分必然要解决如何划分,以及模块间如何协作(API 定义)的问题。
基于软件易于应对变化的角度出发。高内聚、低耦合原则是最为核心和关键的高层原则。基于此我们得到了在模块化过程中,我们真正需要关注的三方关系。
为了让高内聚、低耦合更具指导性和操作性,我们提出了四个策略。它们以变化驱动,让系统逐步向更好的正交性演进的策略,因此也被称做正交策略或正交原则。
我们已经在多个系统的设计和开发中,以这四个原则来驱动我们的软件设计,不仅让我们的系统在保持简单的同时,具备所有必要的灵活性。也让设计和开发活动变得高度有章可循,让团队生产率得以大幅提升。
最后,推荐刘光聪的文章《实战正交设计》。这篇文章通过一个例子,来展示了正交策略是如何驱动出更加正交的设计的。
而正交设计与 SOLID 的关系,可参阅《正交设计,OO 与 SOLID》。
附录
而我的朋友及前同事李光磊对此精炼的总结道:
变化导致的修改有两类:
1. 一个变化导致多处修改(重复);
2. 多个变化导致一处修改(多个变化方向);
由此得到前两个策略:消除重复;分离不同变化方向。
除此之外,我们要努力消除变化发生时不必要的修改,也有两种方式:
1. 不依赖不必要的依赖;
2. 不依赖不稳定的依赖;
这就是后面两个策略:缩小依赖范围,向着稳定的方向依赖。
从光磊这个精彩总结中可以清晰的看出:
- 一切围绕着变化:由变化驱动,反过来让系统演进的更容易应对变化;
- 这四个策略都是在让系统更加局部化影响。
- 这四个策略的完备性。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




