
本文的主题为阿里多语言翻译模型的前沿探索及技术实践,将分三个部分介绍阿里巴巴在机器翻译方面的工作:首先是多语言神经网络机器翻译的动机、定义和挑战;其次是阿里在机器翻译方面的前沿探索;最后介绍多语言神经网络机器翻译在阿里巴巴的应用。

多语言神经网络机器翻译
多语言机器翻译的好处与挑战
机器翻译的目标是让全世界没有语言障碍。现在整个世界有 6000 种语言,但其实只有很少种语言(几百种)能在网络上搜索到,其中有 200 多种语言涵盖了大多数国家。阿里巴巴想要通过技术快速支持这 200 多种语言的翻译,然后扩展整个阿里巴巴的商业边界。

200 多种语言互译的话就会有四万多种语言对,对阿里巴巴团队来说,同时 handle 四万多种翻译方向无论是在模型还是数据处理方面都是极其困难的。
因此阿里的策略是采用多语言机器翻译,本质很简单,就是用一个模型来处理所有的翻译方向。

这样的话一个模型可以处理四万多个语言对。
多语言机器翻译有哪些好处?

① 首先多语言机器翻译采用独一的模型框架,它可以减少一些部署或训练开销。
② 统一训练一个模型会带来一些知识的共享。a.一些 rich language 能够把一些知识 transfer 到一些 low source language 的上面,能提升低资源语言对的翻译效果。b.同时因为有多语言混合,一些低资源语言对可以见到一些原来看不到的输入,可以提升低资源语言对模型的泛化能力。
但是,多语言机器翻译也带来一个挑战
① 如果同时做 200 多种语言的机器翻译,需要收集和筛选出 200 多个语种的高质量数据。
② 阿里内部拥有超过 10 billion 的句对数据,要同时训练这些数据的话,需要很强的工程能力。
③ a.四万多种语言方向用一个模型来做,这个模型的容量是不是够?这是个很大的问题。b.在采用一个大模型的情况下,我们怎样才能提升各个翻译方向上的性能或提升它的解码效率?
阿里在机器翻译方面的前沿探索
本次报告主要是针对算法方面,因为数据和工程方面其实已经有一些现成的方案了。
1. 机器翻译主流框架
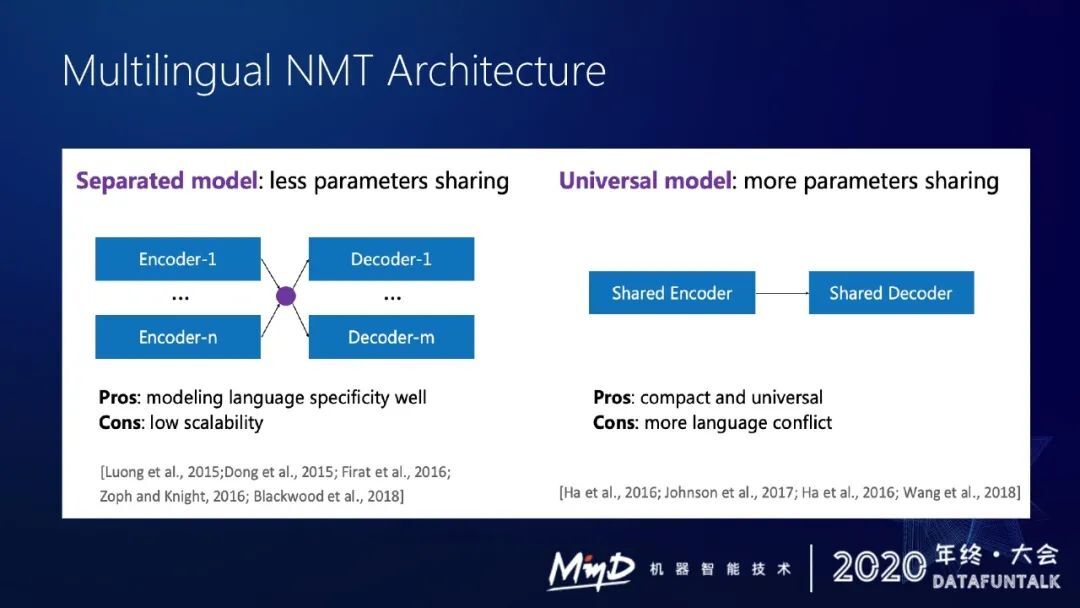
过去一年阿里在机器翻译算法方面做了一些探索,首先是多语言 NMT 的框架选择。目前有两套主流框架:
① 分离式模型。
假设要做 200 多个语种的机器翻译,我可以给每个语言对定义一个 encoder 和一个 decoder,这样的话我会有 200 多个 encoder,200 多个 decoder,在翻译其中某个语言对时,选择对应的 encoder 和对应的 decoder 去进行翻译。
这种框架的好处是每个语言有单独的 encoder 和 decoder,但是有个很大的问题,还是需要有 400 个模块来支持 200 多个语种的机器翻译。
以后增加语言会比较困难。模型规模化程度比较低,部署难度也比较大。
② Universal Model
所有语种共享编码器和解码器,在输入源语言的时候加一个语言标志,告诉这个模型要翻译到哪个语言去。
这种模型有一个很好的优势,就是说整个模型只有一个 encoder 和一个 decoder,模型很优雅。
但是它有个缺点,对模型容量有要求,200 多种语言同时用 encoder 和一个 decoder,模型表达能力肯定会受到挑战,在统一的模型框架里面会出现很多语言冲突问题。

阿里还是倾向于选择统一的框架,采用 shared encoder 和 shared decoder。单一模型具有很好的可扩展性,但是会面临一个很大的一个问题,语言的通用性和语言的特殊性这二者怎么能在模型里很好地表现出来?
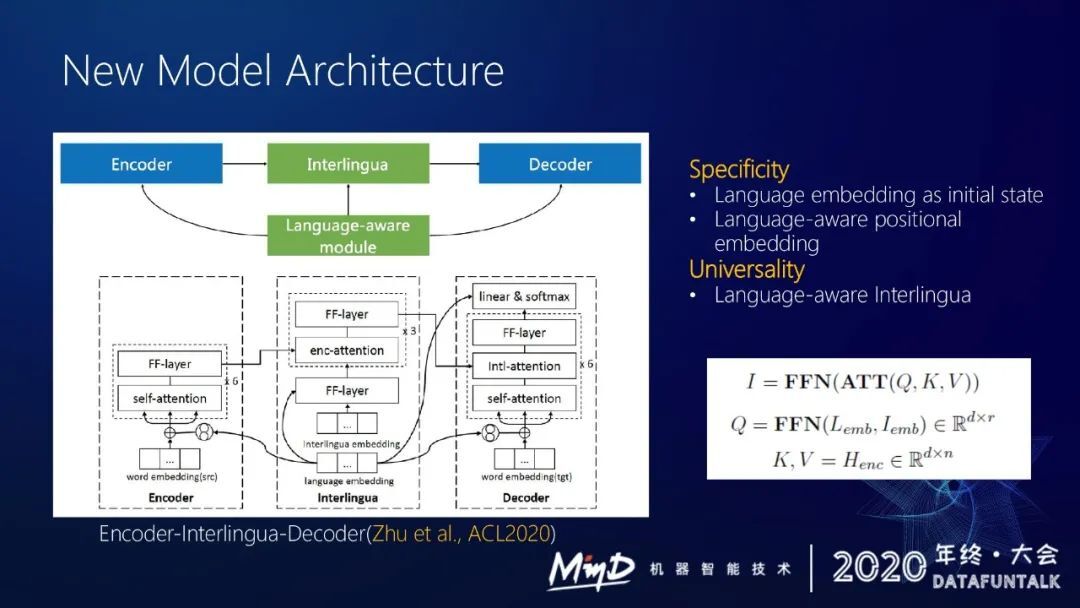
针对这个问题,我们在 ACL2020 的时候发表了一篇论文,提出了一个新的模型解决方案。假定原来只用单个 shared encoder 就不能足够的去充分地去 model 语言的相似性和特殊性。我们提出了编码器-中间语-解码器这样一个新的模型框架。
原来的编码器和解码器不变,在中间插了一个中间语模块,采用固定长度和固定内存。假设我要做中译英,中文进来的时候,先用编码器给中文做编码,再经过中间语模块,可能把中文一些特殊的信号去除掉,获得更通用的一个表示,最后采用这个表示来译出英文。
中间语模块有个好处,不管输入什么语言,都用一个共用的表示去表达。具有相同意思的一个中文或英文句子进入编码器,然后通过中间语模块可以抽取出很类似的表示,这样的话我能得到一个更好的通用语言表示。
同时引入一些跟语言相关的特性给解码器去区分不同语言。通过这样一个框架来协调语言的通用性和语言的特殊性。
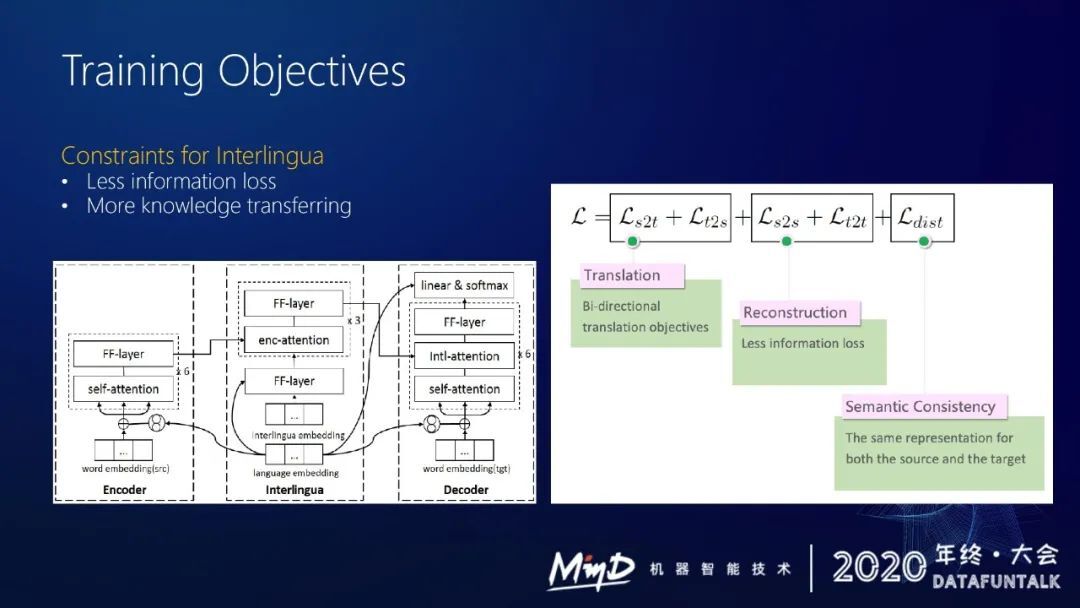
在训练中间语模块的时候,我们引入了两个损失函数来约束它,图右边的损失函数有五项。
第一部分是翻译的条件概率。
第二部分我们希望中间语这个模块 capture 的信息不会丢失掉,所以需要做一个编码解码的过程。假设源语言为中文进入模型,通过中间语模块之后得到一个表示,解码的时候通过中间语能把原来中文的信息完整地表示出来,这样的话能保证中间语模块学到有用信息,这是一个 reconstruction loss。
model 还需要跨语言之间 semantic 的一致性。无论是中文得到的中间语还是英文得到的中间语,在具有相同含义的情况下,中间语模块给出的隐变量应该是很接近的。通过这两个约束来训练这个模型。
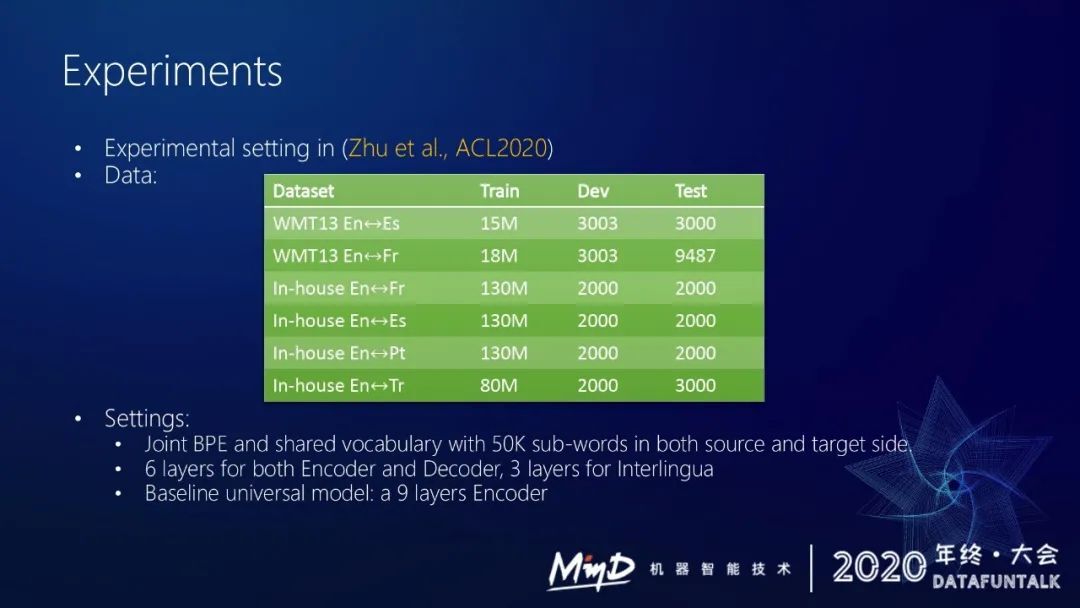
这是我们的实验结果,我们在 2013 年 WMT 公开测试集和我们内部的一些测试集上做评测。我们的 benchmark 是一个九层的 encoder,我们采用的模型结构是六层的 encoder、六层的 decoder、三层的中间语模块。
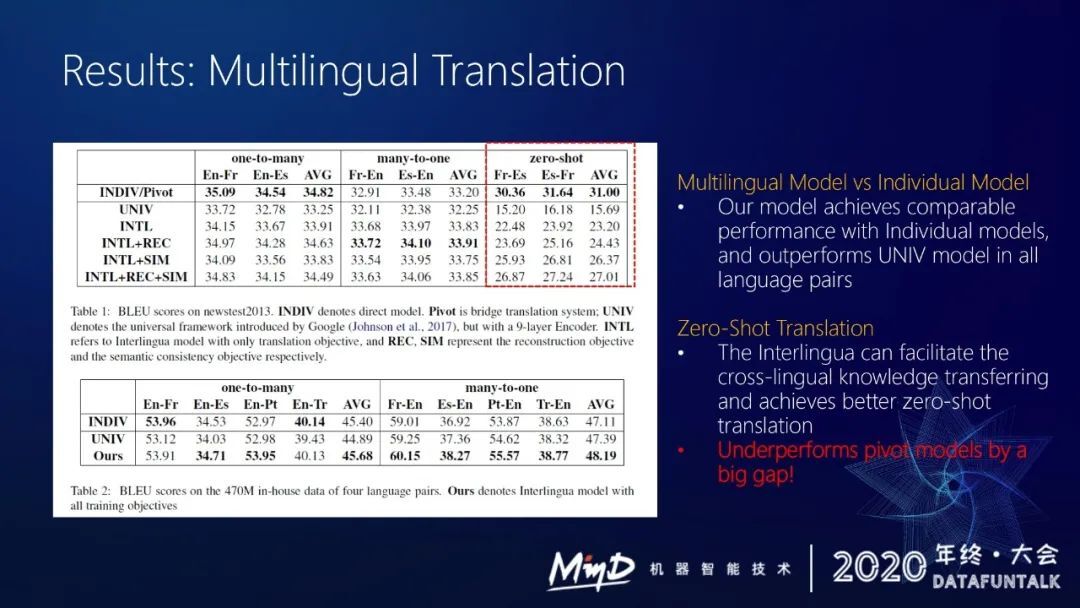
表一和表二是我们的实验结果。
我们的添加约束的多语言翻译模型与直接单独训练单个模型的效果相当,达到 comparable 的效果。同时也比 universal 的模型有更好的效果。
我们在训练模型的时候是没有法西或西法的数据的,但是因为我们构建了一个中间语模块尽量去 model 更通用的语义的信息,而且用固定的一个隐变量去存储,这样能有更好的跨语言 cross-lingual model 能力,能更好的做 zero-shot translation。
我们在 zero-shot translation 上其实比 universal model 高出十个 bleu,但是跟单独的桥接的模型还是有差距的,还有四个 bleu 的差距。
后续我们打算采用数据增强的方法去解决这种 zero-shot 的问题。

2. zero-shot translation
在训练过程中我们可能采用中英或英法句对训练,但我们没有给模型喂中法句对数据,所以模型没有见过中法翻译句对。但是因为我们用的 multi-lingual 模型具备这样的翻译能力,那么这种中法的翻译对于这个模型来说是就是 zero-shot translation。
我们想要做 200 个语种的互译,其实我们统计过,大部分语言之间基本是没有平行语料的,99%的翻译方向上没有平行语料。大部分平行语料都是其他语言译为英文以及英文译为其他语言,很多非英语语种相互之间基本没有双语平行数据。
虽然我们之前的框架已经能缓解一部分问题,但是我们还想继续提升,接下来怎么做?
最直接的方式就是加数据。没有双语数据,但是有很多单语数据。现在最有效的一个策略就是反向翻译。训练好多语言模型之后,假设没有中法双语数据,可以将法语的单语反向翻译成中文,就得到了一批中法的双语数据,可以加进去训练。
但是反向翻译有个问题,因为我们多语言模型的 zero-shot 翻译效果很差。通过反向翻译造出的数据其实质量很低,直接用于训练可能不能充分发挥单语数据的效果。
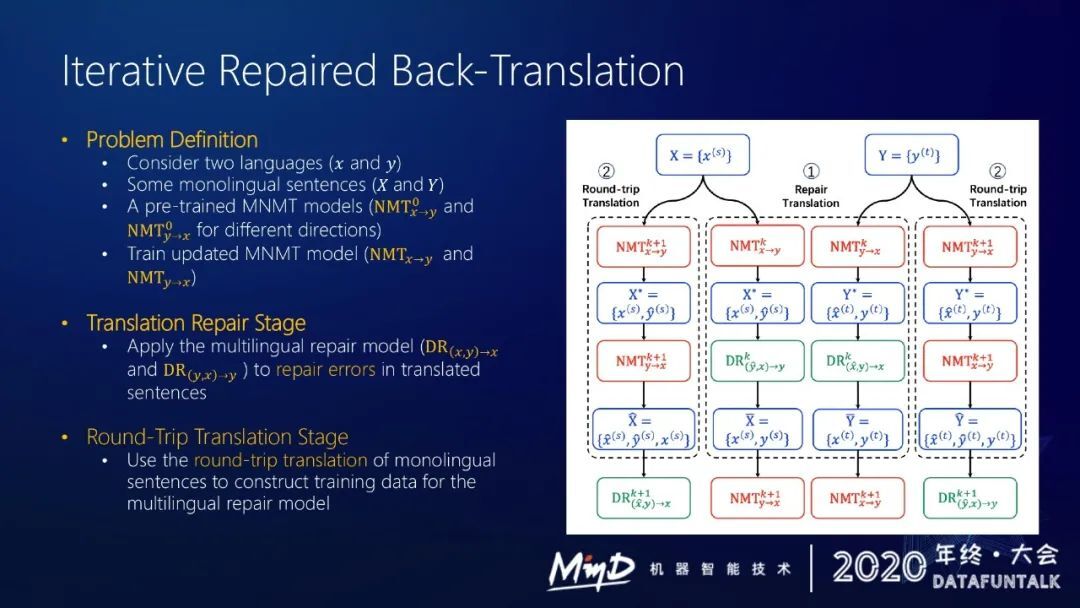
然后我们在今年 EMNLP 2020 的时候提出了一个新的策略,是基于反向翻译的一个改进,引入了一种修复模型,去对原本比较低质量的译文做修复,从而提升整个伪语料的质量,来充分利用单语数据。
① Repair Translation
首先给一个问题定义,假设只考虑两个语言,这两种语言有很多单语数据,假设有一个预先训练好的翻译模型,用 x 到 y 和 y 到 x 表示不同的方向。
引入了两个阶段,一个阶段是做翻译的 repair,对译文做修复,构建一个多语言修复模型去修复反向翻译得到的语料。这个模型用 DR 来表示,DR 也是一个多语言模型,可以用一个语言 tag 来标明要修复的语种。
怎么训练修复模型?需要给出真实的原文、模型翻译的译文以及修复好的译文,我们需要一个 3 元组。可以通过来回翻译的策略来构建这样一个 3 元组。假设给定中文原文,可以先翻译成英文,再翻译回中文,就可以得到一个在给定英文的情况下修复中文译文的一个语料。基于这种语料就可以去训练 DR,即多语言修复模型。
上图右部可以看到整个流程。假设做中法 zero-shot translation 翻译,预先基于中英和英法双语语料训练好一个多语言模型,给定一些中文和法文的单语数据,用训练好的模型对这些单语数据做反向翻译,将中文翻译成法语或将法语翻译成中文,得到一些伪语料,然后使用修复模型对伪语料做修复。
如果把中文翻译成法语,那么法语译文就是伪造的部分,我们用修复模型对法语译文做进一步的修复,得到新的法语译文,得到更好的伪语料。
有了更好的伪语料,就可以去更新多语言模型,这是第一个阶段,即 repair translation。
② Iterative Repaired Back-Translation
第二个阶段,在 NMT 的训练过程中也可以优化修复模型。
给定单语,可以做两次翻译,得到修复语料,然后构建新的修复模型,这整个过程是一个持续迭代的过程。
假设给定一个修复模型,先用两种语言的单语数据得到一些伪语料,再用修复模型得到一些修复好的伪语料,然后去训练 NMT 模型,然后用新的 NMT 模型重新做来回翻译,得到一些新的修复数据,然后继续训练修复模型,这个过程会逐渐修复伪语料的质量。
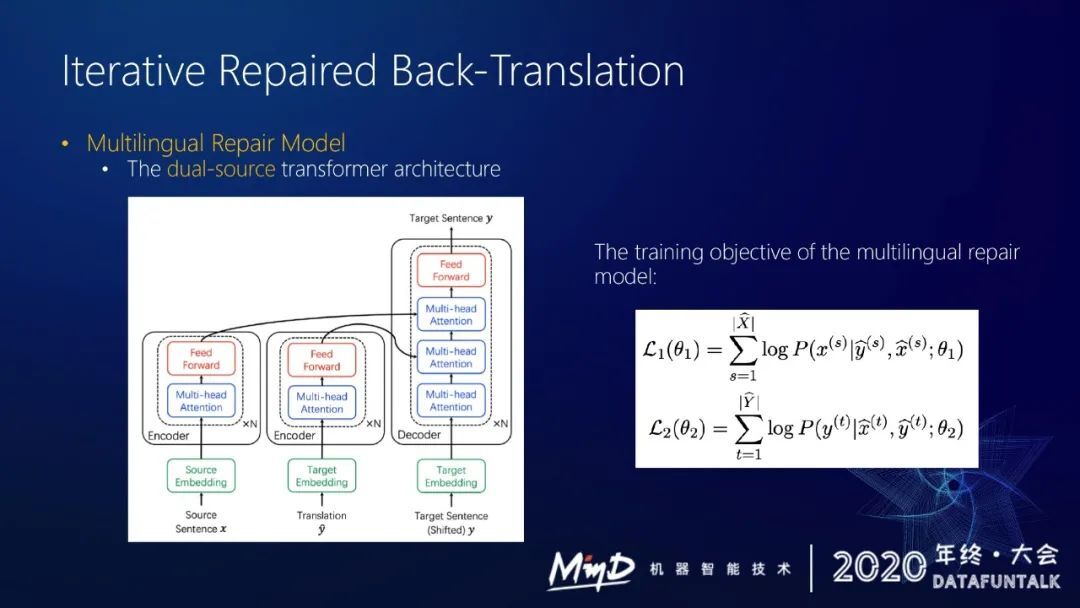
多语言修复模型其实很简单,有两个输入和一个输出,采用双源 dual source transformer architecture 来做。给出源语言 X,然后得到翻译,然后直接去预测目标语言句子 Y。loss 也很简单,给定一个句对,去预测要修复的目标句子,然后得到一个 loss。
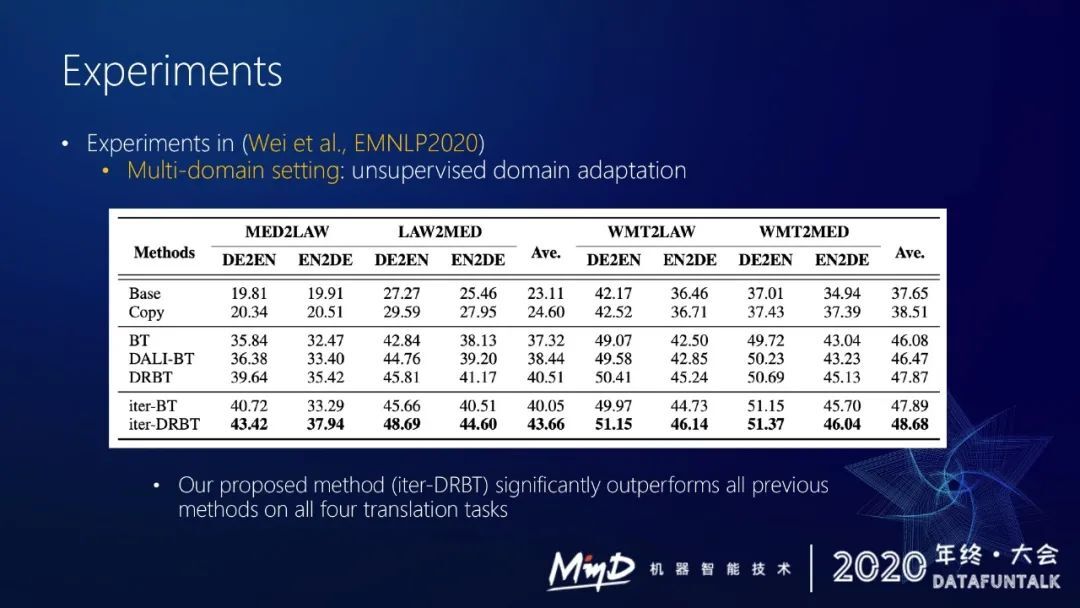
这套方法不止可以做多语言的翻译,其实它也可以做一些 model domain setting。在 EMNLP 2020 的时候,我们其实是在多领域的 setting 下进行实验,最后一行是我们方法的结果,可以看出我们的方法优于包括反向翻译或迭代反向翻译在内的过去的所有方法。其实证明了我们可以借助这种修复 model 去提前修复 back-translation 产生的伪语料中的错误,提高伪语料质量,从而提升整个训练的效率,充分利用单语数据。

虽然采用了修复模型去修复伪语料里面的一些错误,但是训练过程中的伪语料并不是越多越好,到达一定程度之后再加伪语料性能反而会下降。
不管是采用修复模型还是直接用 back-translation 构建伪语料,得到的伪语料其实不可能完美,跟人工语料还是有差距。所以加很多伪语料其实有可能会污染到训练数据。加的伪语料越多,整个语料的质量越可能会下降,从而影响到模型的训练效果。
另一方面,采用反向翻译这种策略去构造伪语料虽然能提升 zero-shot translation 的效果,但是它的 cost 很大,反向翻译这个过程很耗时,需要很多 GPU 资源。虽然反向翻译策略在实际过程中很好用,但是无法生成太多的伪语料,而且伪语料过多也会影响到模型的训练。

3. 怎么更好地去利用那些单语数据呢?
现在一个主流的策略就是利用预训练模型。
我们也在整合预训练模型上做了一些探索。预训练模型在 NLP 领域已经成为了一个新的范式,对一些 NLU 和 NLG 任务都有很显著的提升。
预训练是怎么做的?首先通过 bert、RoBERTa 或者 MASS 利用大量单语数据预训练一个模型,然后在带 label 的下游任务上做 finetuning,就可以充分利用预训练模型的效果。这个方法对于 NLG 任务很重要,但是在用到 NLG 或 NMT 上会有一些问题。
第一,现在的预训练模型 finetuning 的策略是直接用 bert 去初始化,这样的话会有个灾难性遗忘问题。初始化之后在下游任务做微调,如果下游任务数据量足够大(类似于翻译),可能下游任务有几百万上千万的数据,这种情况下进行 finetuning,预训练的效果就很可能不存在。因为整个参数被调整了,所以模型会遗忘掉之前训练的一些知识。
第二,现在一些比较好的现成模型很难在 decoder 上整合,因为 NMT 是带条件生成式语言模型,而 bert 的训练往往是不带条件的,很难用到 decoder 里面去。
第三,预训练模型容量很大,往往很难 finetuning,而且对学习率很敏感,稍微调一下学习率,模型效果就有很大波动。
这就是为什么现在一些主流 pre-trained model 很难在 NMT 上有很好的推广。
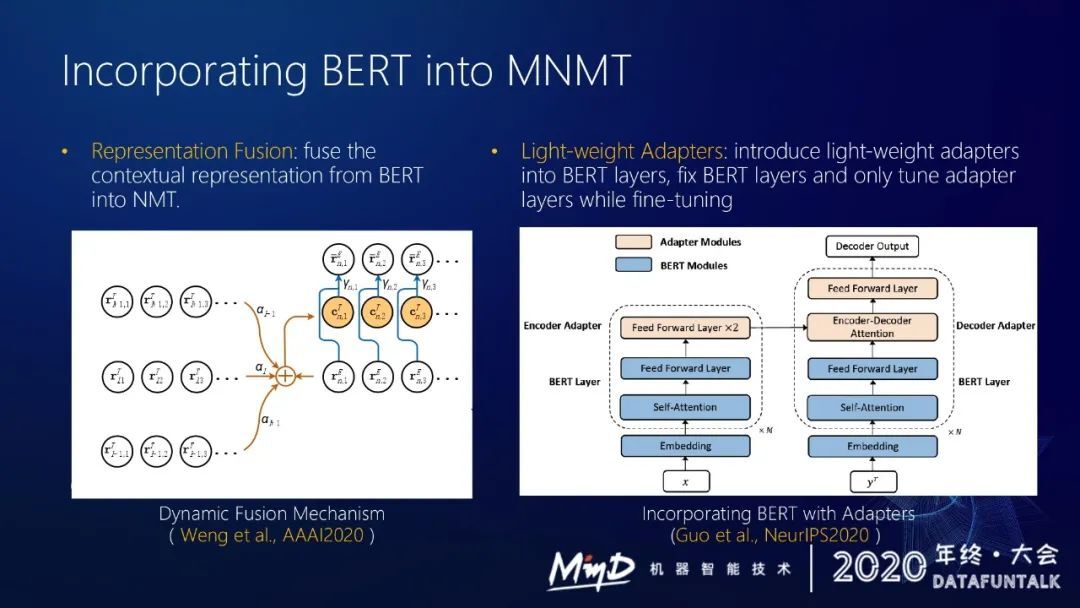
4. 进一步的探索
我们其实还是沿着这个方向做了一些探索,我们在想怎么更好地把 bert 用到 multi-lingual NMT 上。我们去年和今年分别做了两个工作去整合预训练模型。
第一个工作是表示融合,把预训练这种带有上下文的表示融合到 NMT 里面去。
第二个工作就是在第一个工作的基础上进一步简化,提出了一个很轻量的适配器,将其插入到 bert 的层数里面,在下游任务 finetuning 的时候,只要调一些调适配器的参数就能比较好地利用预训练模型的效果。
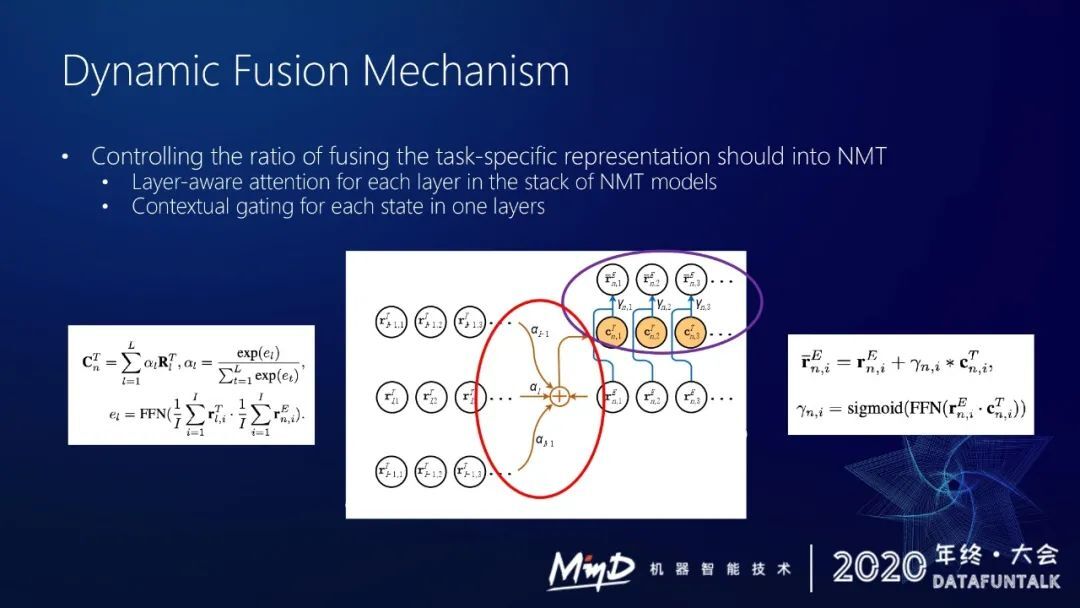
第一,动态融合的方法,如上图,左下是一个预训练模型,可以从中得到一堆向量表示,右边是一个 NMT 的 encoder 或者 decoder。在融合预训练表示的时候,我会做两个事情,首先我们要决定预训练模型的哪些层是重要的(不同的层输出不同表示)。对于当前 encoder 来说,需要做一个 attention 去找到预训练模型不同层的重要程度。
第二,我们得到 attention 之后,用 gating 的机制去选择哪些信息对当前的 encoder 是有用的。
其实这两个事情的本质是把预训练模型里面的有用信息更好地萃取到 NMT 模型中。我们可以用这套方法在 encoder 里面整合 bert,在 decoder 里面我们可以整合 GPT。
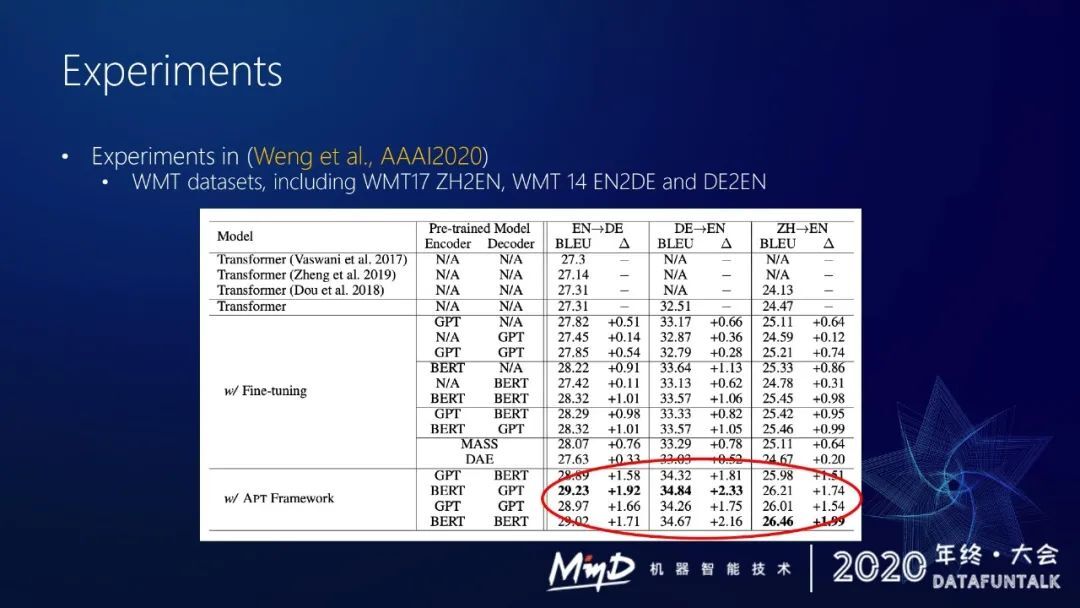
我们在 WMT 一些主流的 benchmark 上做了实验,通过动态融合的策略,我们可以很好地利用预训练模型的一些知识来提升当前的 NMT 的效果。这种策略分别在 WMT17 中英、WMT14 英德和德英上都有比较明显的提升,比之前直接 finetuning 能高出一个多点(bleu 值)。
我们今年在 NIPS 上重新反思了原来的萃取方法,做了进一步简化。之前的这套方法还是很重的,因为我们会有不同的模块,存在预训练模型和 NMT 模型两个模型,没有很好地融合在一起。

我们提出了一个更简化的新方法,就是用适配器来用整合 bert。采用用一个很轻量的适配器,这样的话我们就可以插到 bert 层里面,然后在下游任务 finetuning 的时候,只 finetuning 一些跟适配器相关的参数。这样做有什么好处?
第一,其实跟之前的方法是一个思路,我们保证 bert 不变,这样的话 bert 就不会存在遗忘问题,就可以尽量缓解之前提到的灾难性遗忘问题。
第二,如果要用 bert,可以在 decoder 里使用 mask-predict 来解决带条件和不带条件的问题。
第三,因为用了适配器这种很轻量的结构,所以不需要对整个 bert 做 finetuning,所以整个模型的训练对学习率很鲁棒。
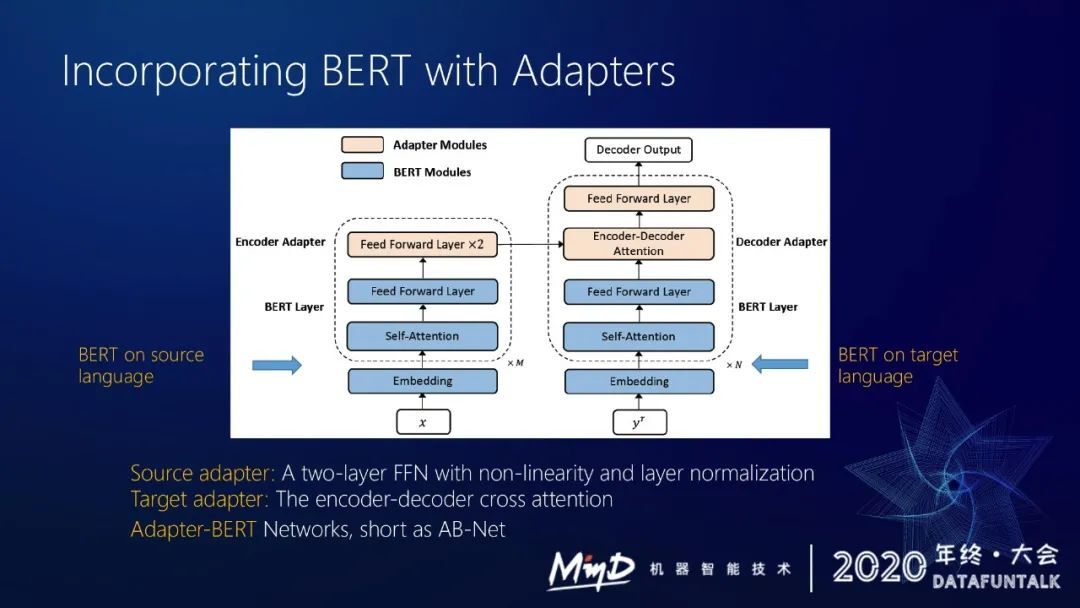
拿非递归的 NMT 来举例,假设 encoder decoder 都用 bert 做初始化,然后我们在 bert 上面插两个 layer,即两个 adapter。Source adapter 插入到 encoder 部分,由两个 feed forward layer 组成。Target adapter 包括 encoder-decoder attention 和一个 feed forward layer。训练的时候 bert 的相关参数固定不变,只调 adapter 就能取得比较好的效果。

训练的时候把 Y 里面的某些词屏蔽掉,然后预测这些词。整个训练的 loss 跟 bert 更相似,这样的话也能更充分地保证预训练和 finetuning 更接近。
我们采用 mask-predict 的策略做解码。
这套策略其实还能用到正常的 NMT 上。例如对源语言用 bert 做初始化,然后插入一个 source adapter,对 decoder 端做完全随机初始化,这样去训练,后面实验也会说明这样的策略效果也不错。
或者我们直接去训练一个 mbart,直接采用 sequence to sequence 的 pre-trained model,在其上插入 adapter 也有效果。
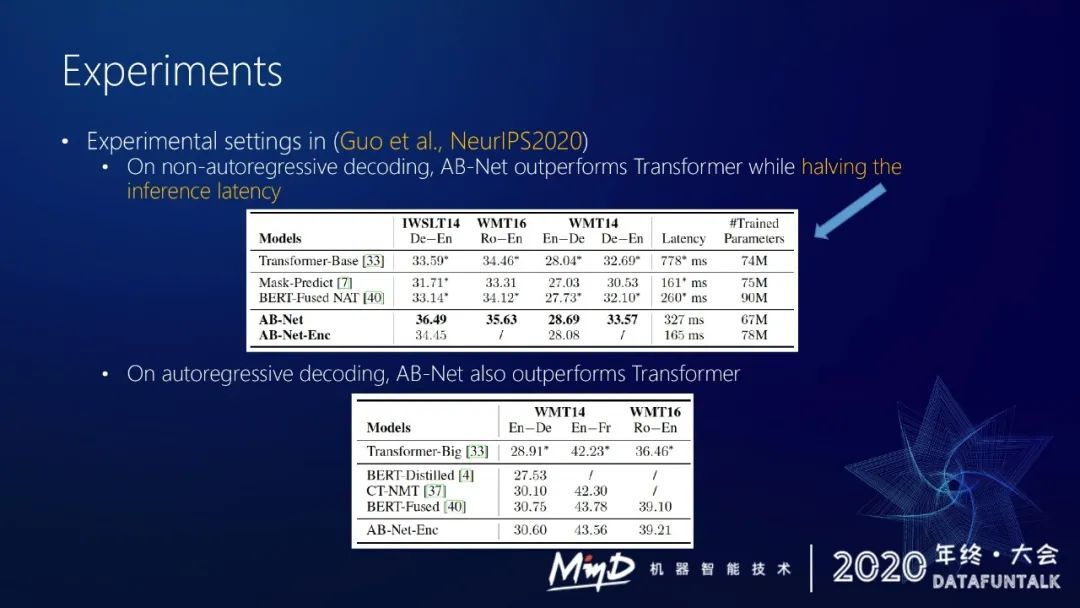
下面讲一下我们内部的一些实验,上图是我们在非递归解码 NMT 上取得的结果。我们在 IWSLT14 和 WMT16 和 WMT14 上都做了一些实验。可以看到我们的这个策略比之前直接做 bert fusion 要好很多,而且这个策略不需要有两个 encoder,解码速度也较快。
在一些正常的 NMT 上我们也做了实验,例如直接在 encoder 上用 bert 做初始化,同时固定住 bert,然后插入 adapter,decoder 随机初始化,然后做训练。这种方式在 WMT14 的英德和英法上都取得了不错的效果,能达到之前微软 bert fusion 策略的效果,但是我们整个模型容量更小,因为我们的 encoder 部分不需要用额外的参数,只需要用 adapter。
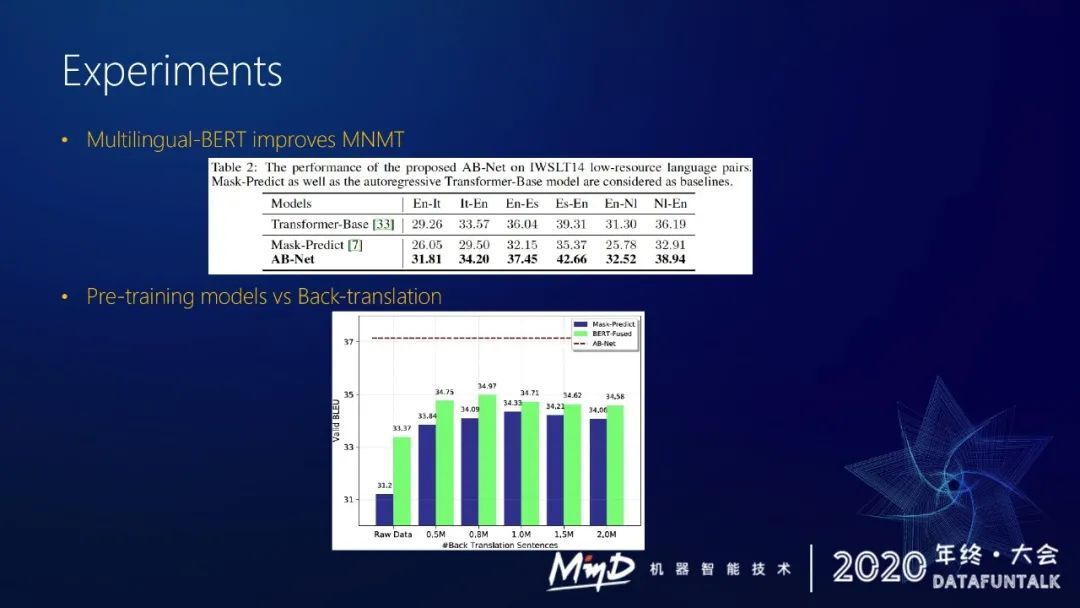
后续我们还探索了 multi-lingual bert 的效果。我们可以用 multi-lingual bert 做初始化,然后采用 adapter。可我们在 IWSLT 上做了实验,可以看出这种策略能比 mask-predict 方式高出五个点(bleu 值)。这个策略也好于直接训练的 transformer-base 模型。
后续还有一个比较有意思的发现,back-translation 生成的伪语料不是加得越多越好,加到一定程度之后反而翻译性能会下降。
但是借助 pre-training 策略就能很好地利用这种单语信息,能比直接用 back-translation 高出两个点(bleu 值)。
多语言神经网络机器翻译在阿里巴巴的应用
有了预训练模型之后,我们就可以很好的去提升多语言 NMT 场景下的低资源和零资源问题,因为大部分的语言对(翻译方向)的语料资源都很少,借助预训练模型和 adapter 策略,我们可以融合更多的单语数据来训练,提升 multi-lingual NMT 的效果。这套策略其实已经用到了我们的线下系统上。

后面会讲一下落地的实现。使用预训练模型会有个很大的问题,因为模型很大,解码速度会很慢。为了上线我们会做一些优化,其实大部分时间开销是在 decoder 部分,它占了 80%到 90%的开销。
我们采用了 deep encoder shallow decoder 策略、share attention 策略,最后我们还做一些工程上的改进,采用 short list 预测来提升速度。
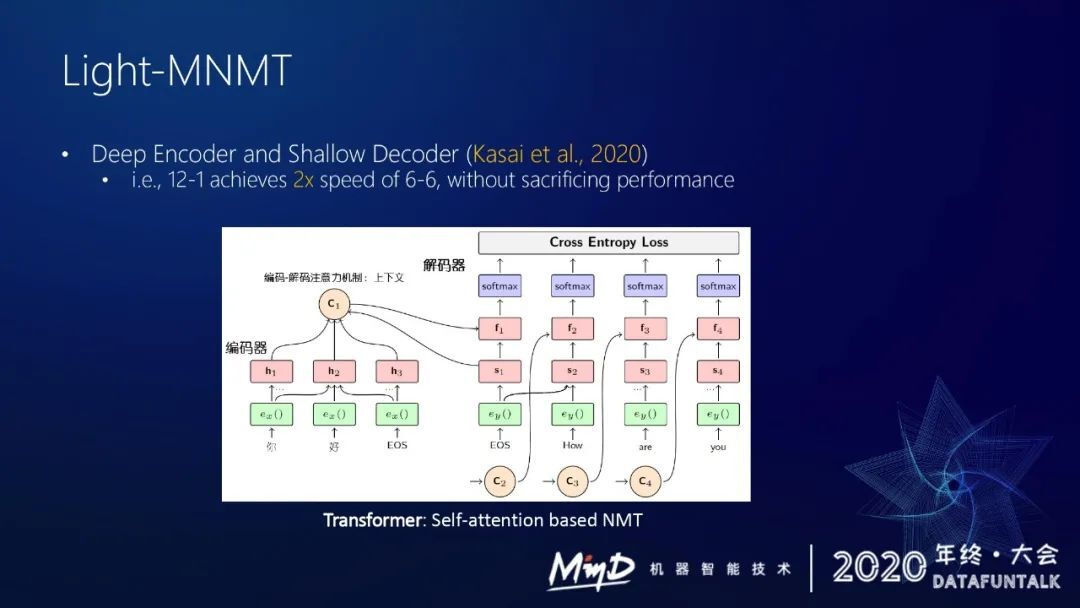
因为 decoder 解码是一步一步执行的,所以整个瓶颈都在 decoder 端。之前有论文做了一些分析,如果把 encoder 加深,把 decoder 层数降低,基本不怎么损失翻译效果,但是速度上能有两倍提升。
论文里面很极端,把 decoder 层数从六层减到了一层。实际过程中我们发现一层的 decoder 的表达能力很受限,语言模型能力会比较弱。我们的 decoder 一般用三层。我们把 encoder 的层数加得很深,这样能在整个模型容量、表达能力不怎么下降的情况下加速解码。
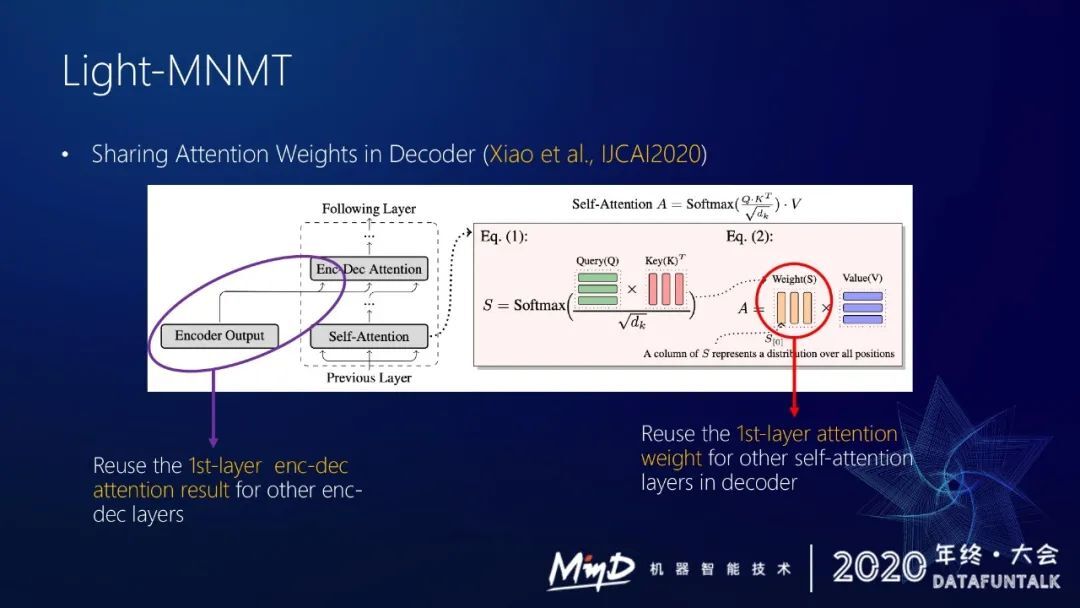
根据肖桐博士在 IJCAI 的论文 Sharing Attention Weights for Fast Transformer,我们也做了实验去验证,得到一些相似的结论,即 decoder 里面有几部分的 attention 其实没有那么重要。
① encoder decoder attention 这部分,假设用六层,每层都要做一次计算。后来发现后面五层 encoder decoder attention 其实可以被第一层复用,如果直接用第一层的 encoder decoder attention,结果基本没什么差距。
② self-attention 里面的权重,这里也可以被简化,我们发现每一层的 self-attention 权重其实差异不大,采用这个策略也能加速。

③ Shortlist Prediction。
多语言机器翻译模型会 share 一个大字典,但我们在向某个语种做翻译的时候不需要采用整个字典做预测,只需要采用与这个语种相关的一些词,这样的话我们可以动态地调整字典,用一个字典子集也能对整个模型做提速。
有了这三个策略再结合一些工程上的图优化改进,解码效率能提升三到四倍。这样能使我们基于大规模预训练模型的 NMT 能上线运行。

阿里翻译主要做的一个事情是让商业没有语言障碍,其实我们想要贯彻的是阿里巴巴的全球买、全球卖、全球旅游、全球支付理念。为什么需要阿里翻译,如果没有解决语言问题,这些理念就无法实现。商业边界会很受限。
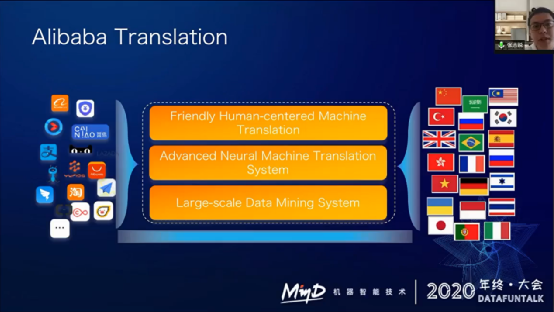
阿里翻译构建了一个大规模的知识挖掘系统,然后在上面构建了各种各样的机器翻译模型,包括多领域机器翻译模型、多语言机器翻译模型,以及人机协同平台。阿里翻译支持了阿里内部大部分跨语言相关应用。
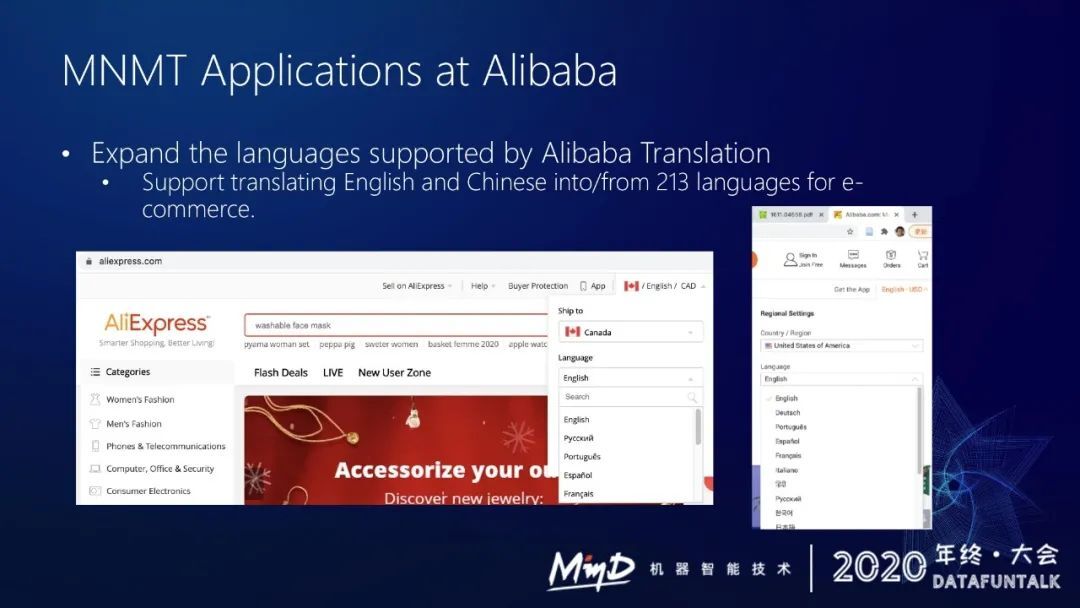
下面简单介绍一下多语言 NMT 在阿里巴巴的应用。我们最近九月份刚上线了支持 200 多个语种的机器翻译服务,已经用于阿里巴巴速卖通,在速卖通上可以看到阿里翻译可以支持 200 多个语种。
我们的 200 多个语种的机器翻译服务最近也在阿里云上线了,可以直接在阿里云上搜机器翻译做一些产品体验。
简单总结一下。

为了支持阿里巴巴全球买全球卖的策略,我们想要直接构建一个 NMT 系统,能够支持涵盖全球大部分国家的 200 多种语言。为了更好、更方便的部署,我们采用了 multi-lingual NMT 框架。我们设计了一个基于中间语的多语言模型结构,以及基于迭代修复的反向翻译的数据增强方法,然后我们设计了两种不同的策略去整合预训练模型,最后为了整个模型上线还做了一些加速。
分享嘉宾:
张志锐 博士
阿里巴巴达摩院 | 算法专家
演讲者简介: 现阿里巴巴达摩院算法专家,中国科学技术大学与微软亚洲研究院联合培养博士,主要研究方向是机器翻译、自然语言生成、对话系统等,曾在微软亚洲研究院、微软雷德蒙德研究院实习,已在 ACL/EMNLP/NAACL/NeurIPS/AAAI 等国际顶级会议上发表相关论文 10 余篇,并担任多个国际顶级会议审稿人,Google Scholar 的论文 Citation 达到 500, H-index 为 10。目前在阿里巴巴达摩院翻译团队负责基础通用模型优化和先进翻译技术研究。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:阿里多语言翻译模型的前沿探索及技术实践




