正如 Apache Cassandr a 的名称是来自于著名的物洛伊女巫一样,在它身上确实存在着各种误解。和大多数误解一样,至少在一开始时它们确实是有那么一点道理的,但随着 Cassandra 不断地深化与改善,这些误解的内容已经不复存在了。在本文中,我将针对五个常见的疑惑作出解释,澄清人们的困惑。
误解:Cassandra 就是一个嵌套的 map
随着使用 Cassandra 的应用程序变得越来越复杂,以下观点正在逐渐变得清晰起来:与“任何东西都是一个数组缓冲”或者“任何东西都是一个字符串”这种设计方式相比,schema 与数据类型会使大型应用的开发与维护更加简单,
现如今,理解 Cassandra 的数据模型的最好方式是将其想像为表与行的组合,并且与关系型数据相似的是,Cassandra 的列也是强类型的,并且可以进行索引。
你也许还听到过其它这些说法:
- “Cassandra 是一种列数据库。”列数据库会将某个列的全部数据一起保存在磁盘上,这种方式对于数据仓库的检索方式是比较适合的,但对于那些需要对特定的行进行快速访问的应用程序来说就不太适合了。
- “Cassandra 是一种宽行数据库。”这种说法有一定的道理,因为 Cassandra 的存储引擎是由 Bigtable 所启发而设计的,而后者可以说是宽行数据库的祖先了。但宽行数据库的数据模型与存储引擎结合得太过紧密,虽然实现起来比较容易,但针对它进行开发就增加了困难,而且它还使许多优化方式变得不可行了。
我们之所以在开始的部分选择避开“表与行”这种方法,原因之一是因为 Cassandra 的表与你所熟的关系型数据库的表的确存在着某些微妙的差别。首先,主键的首个元素是分区键,在同一个分区中的所有行都会存储在同一台服务器上,而分区是分布在整个集群中的。
其次,Cassandra 不支持关联查询与子查询,这是因为在分布式系统中跨越硬件进行关联查询的性能很差。Cassandra 的做法是鼓励你采用去正规化(denormalization)的方式,从一个单独的表中获取你所需的数据,同时提供集合等工具以简化操作。
举例来说,考虑一下以下代码所表示的 users 表:
CREATE TABLE users (
user_id uuid PRIMARY KEY,
name text,
state text,
birth_year int
);
目前多数主流服务都会考虑到一个用户可以拥有多个 email 地址的情况。在关系型数据库中,我们必需建立一个多对一的关系,随后使用关联查询将地址与用户关联起来,如以下所示:
CREATE TABLE users_addresses (
user_id uuid REFERENCES users,
email text
);
SELECT *
FROM users NATURAL JOIN users_addresses;
而在 Cassandra 中,我们会以去正规化的方式将所有 email 地址直接加入用户表中,使用一个 set 集合就可以完美地实现这一点:
ALTER TABLE users ADD email_addresses set<text>;
随后我们可以以如下方式为用户添加多个地址:
UPDATE users
SET email_addresses = {‘jbe@gmail.com’, ‘jbe@datastax.com’}
WHERE user_id = ‘73844cd1-c16e-11e2-8bbd-7cd1c3f676e3’
关于 Cassandra 数据模型的更多内容,包括自届满数据(self-expiring data)以及分布式计数器,请参考在线文档,
误解:Cassandra 的读取速度较慢
Cassandra 采用的日志结构存储引擎意味着它不会在硬盘中寻找更新,也不会造成固态硬盘的写入放大,而同时它的读取速度也很快。
以下图示是关于随机访问读取、随机访问及顺序扫描,以及混合读写情况下的吞吐数据,它们来自于多伦多大学的NoSQL 性能指标分析结果:
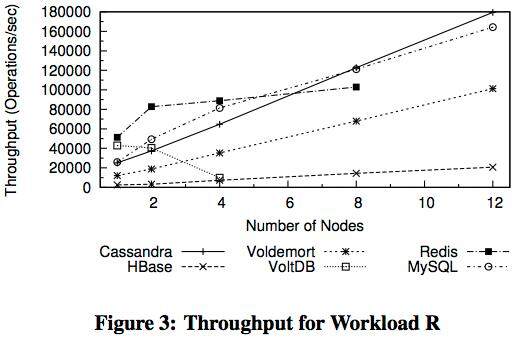
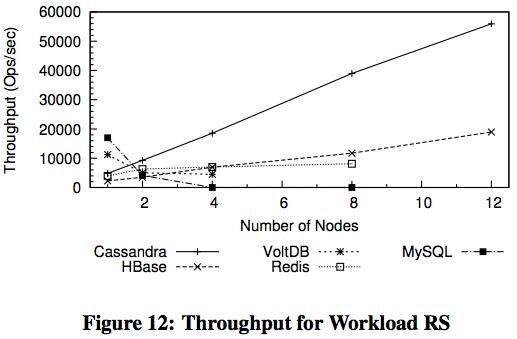
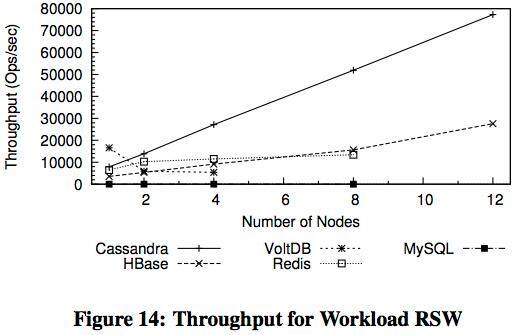
来自Endpoint 公司的性能指标检测对Cassandra、HBase 与MongoDB 进行了比较,也证实了以上结论的正确性。
Cassandra 是怎样实现的呢?从一个较高的层次来看,Cassandra 的存储引擎看起来与 Bigtable 很像,它们都使用了一些相同的术语。更新内容会添加到某个 commitlog 中,随后收集到某个“memtable”里,该表会最终将数据写入磁盘并进行索引,类似于一个“sstable”:
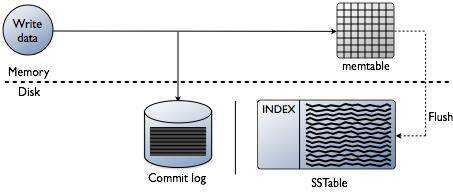
原生的日志结构存储系统确实会倾向于在读取时稍慢,而由于同样的原因,它们在写入时会比较快:因为新的数据不会替换每一行中的原始数据,而是在后台压缩后再进行合并。因此在最坏的情况下,为了获取某个“碎片化”的行中的每一列的值,你将不得不检查多个 sstable。
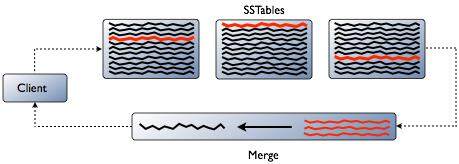
为了达到更好的读取性能,Cassandra 对此基本设计方式进行了一些改善:
- 压缩策略是以插件形式提供的。例如 LeveledCompactionStrategy会通过更为激进的方式组合重叠的 sstable,以实现对读取的优化。
- Cassandra 以时间倒序对 sstable 进行检查,如果你要求 Cassandra 执行 SELECT x, y FROM foo WHERE key = 42 语句,当 Cassandra 找到 x 和 y 对应的某个最新写入的数据时,它就不会再去检查时间更早的 sstable 。同样的原则也可以应用在对某个范围内的扫描上,虽然稍有些麻烦,但并非不可能实现。
- 在必须要从多个 sstable 中进行读取的情况下,我们将会在读取时将去碎片化的结果重新写入,这样之后的读取操作就只需要访问一个单独的表了。
- 当某个分区被访问时,它的索引就会被缓存起来,因此只需(每个 sstable)一次查找就可以访问分区中的所有行了。
- 存储引擎的元数据中会从堆中被剔除出去,这样就避免了垃圾回收带来的影响问题。
误解:Cassandra 的运行很麻烦
比起在一台独立的机器上运行数据库,在一个分布式系统上运行会在以下三个方面遇到更多的困难:
- 初始化时的部署与配置
- 日常维护工作,例如升级、添加新节点、或者替换故障节点
- 故障检测
Cassandra 是一个完整的分布式系统:因为 Cassandra 集群中的每一台机器都具有相同的角色,不存在专门的元数据服务器以调整内存中的各种信息,也不存在专门的配置服务器以进行分发,同样也不存在主服务器或者是故障转移服务器。这种特性使运行 Cassandra 从各方面而言都要比其它的一些替代产品来得更简单。这也意味着可以很方便地搭建一个单节点的集群以进行开发与测试任务,而它的功能表现与在一个包含大量节点的完整集群中的表现完全一样。
从某种意义上说,初始化时的部署工作其实是一项最不重要的任务,因为如果其它方面的表现相同,那么即使是初始化时的安装稍为复杂一些,随着系统生命周期的推移,这一点麻烦也不是很大的问题,并且自动化的安装工具能够为你隐藏大多数头疼的细节问题。但是!如果你因为对某个系统的了解太小而选择放弃手动安装,那么当你需要对某个问题进行故障诊断时就会遇到麻烦,因为解决问题需要你完全掌握系统中的各个部分是怎样在一起动作的。
因此我的建议是,如果你打算利用某些工具来进行安装,例如 Windows MSI 安装文件、Oracle 的 Ops Center Provisioning 、或是自配置的AMI ,请确保你已经深刻理解了安装过程中的细节。你可以研究一下这个搭建Cassandra 集群的两分钟示例。
Cassandra 的日常维护工作很简单。任一时刻都可以在某台节点上进行升级工作,而当某个节点停机时,其它节点会保留本应应用在该节点上的升级内容,并在该节点恢复后将升级内容重新发送给它。此外,添加新节点的操作可以在整个集群中并行进行,在操作完成后也无需重新进行平衡。
即使是对那些时间较长的、计划之外的停机状态进行处理也非常方便。Cassandra 可在运行时进行修复,如同其它数据库中的rsync 一样,它只需传输丢失的数据即可,这就将网络数据传输降至最低。如果你没有特别留意的话,也许根本不会意识到它的发生。
Cassandra 在对多数据中心的支持方面在整个业界都处于领先地位,即使是整个AWS 区域挂掉,甚至是整个数据中心在飓风中被摧毁这些极端情况下,也可以顺利地进行恢复。
最后, DataStax OpsCenter 能够让你随时看到集群的各种重要系统指标,这样就可以方便地将历史活动数据与造成服务性能下降的事故相关联起来,以达到简化故障检测的目的。 Cassandra 的 DataStax 社区版本自带了一个“轻量级”版本的 OpsCenter,可以在生产环境中免费使用。而 DataStax 企业版则包括了备份与恢复的调度,可配置的系统警告以及其它各种特性。
误解:在 Cassandra 上进行开发非常困难
早先的 Cassandra Thrift API 的目标是尽量减少用户开发一个跨平台的应用所付出的精力,而它也达到了这一目标,但现在业界已公认这套 API 是难以使用的。随后Cassandra 推出了一套自己的SQL 语言:CQL。它提供了一套更易于使用的接口,学习曲线更为平滑,同时还推出了一套异步协议,因此取代了Thrift API 的使用。
CQL 的早期使用者在两年前就可以使用 0.8 版本了,而今年 1 月份发布的 1.2 版本终于使 CQL 成为一个可用于生产环境的产品了。新版本包含了多种驱动程序,性能也比Thrift 更好。DataStax 也为最流行的各种CQL 驱动程序提供了官方支持,从此就可以不必再依赖来自社区的Thrift 驱动程序的支持了,有时这种支持真的很差。
除了在线文档中所介绍的CQL 基础知识外,Patrick McFadin 的演讲“Next Top Data Model”(第1 部分、第2 部分)也是一个很好的CQL 介绍。
误解:Cassandra 依然是一种无人问津的边缘产品
从开源的角度来说,Apache Cassandra 已有5 年的历史,并且已经发布了多个版本,最新的版本2.0 还是在今年七月刚刚发布的。而从企业的角度来说,DataStax 提供了 DataStax 企业版,其中包含了一个经过认证的 Cassandra 版本,该版本经过了特定的测试、性能指标衡量、并且得到认可在生产环境中进行使用。
各个商业机构都看到了 Cassandra 为他们的组织所带来的价值,财富榜上的百强内有 20 个机构都依赖于 Cassandra 为他们的关键应用程序提供服务,这些机构来自几乎每个行业,包括金融、医疗、零售、娱乐、在线广告与市场。
将应用迁移至 Cassandra 平台上的最常见原因之一,是现有技术的伸缩性已经不足以满足现代化大数据应用程序的需求了。全球最大的云应用 Netflix已经将其95% 的数据从Oracle 迁移至Cassandra ,而Barracuda Networks 也用Cassandra 取代了MySQL ,因为MySQL 已经不能够应对巨量的垃圾请求了。而Ooyala每天都要进行20 亿次数据处理,它所使用的Cassandra 已有超过两个PB 的数据量了。
对于那些管理和维护成本过高的陈旧的关系型数据库,Cassandra 也在逐步取而代之。Constant Contact 的首个基于Cassandra 的项目开发了三个月,成本为25 万美元,而他们之前基于关系型数据库的方案则开发了九个月,花费了250 万美元。如今,他们已经搭建了 6 个集群,共有超过 100TB 的数据存放于 Cassandra 中。
在 DataStax 的案例学习页面,以及Planet Cassandra 的用户访问页面上还可以找到许多其它案例。
这一条并非误解:关于在旧金山举办的2013 Cassandra Summit 大会
我们刚刚结束了本次会议,这可以说是学习更多Cassandra 知识的最好机会了。本次会议有超过1100 名与会者和65 场演讲,主讲者分别来自Accenture、Barracuda Networks、Blue Mountain Capital、Comcast、Constant Contact、eBay、Fusion-io、Intuit、Netflix、Sony、Splunk、Spotify、Walmart 和其它一些公司。演讲的幻灯片已上传,而演讲视频也即将开放下载,具体时间请密切关注 Planet Cassandra 的公告。
关于作者
 Jonathan Ellis是 DataStax 公司的 CTO 兼联合创始人。在创办 DataStax 之前,他在受雇于 Rackspace 公司时在工作中大量使用了 Apache Cassandra。而在 Rackspace 之前,他基于 Reed-Solomon 编码技术,为内容备份提供商 Mozy 编写了一个可容纳多个 PB、伸缩性良好的存储系统。
Jonathan Ellis是 DataStax 公司的 CTO 兼联合创始人。在创办 DataStax 之前,他在受雇于 Rackspace 公司时在工作中大量使用了 Apache Cassandra。而在 Rackspace 之前,他基于 Reed-Solomon 编码技术,为内容备份提供商 Mozy 编写了一个可容纳多个 PB、伸缩性良好的存储系统。
查看英文原文: Cassandra Mythology




