
导读: 近年来,网易云音乐作为一匹黑马迅速在移动音乐 APP 占据市场,2016 年用户量就突破了 2 亿,而这与它优质的推荐系统必不可分。网易云音乐推荐系统致力于通过 AI 算法的落地,实现千人千面的个性化音乐推荐系统。本文将重点介绍推荐系统在云音乐的落地实践,以及在音乐推荐系统中遇到的挑战和解决方案。使大家了解音乐场景下的多行为域的序列建模,包括用户多兴趣点挖掘、多空间长短期兴趣建模,以及音乐场景下的用户兴趣演化网络建模。主要内容包括:
网易云音乐简介
召回体系探索
精排模型演化历程
音乐推荐场景 AI 思考
01 网易云音乐简介
1. 关于网易云音乐

网易云音乐是专注于发现与分享的音乐产品,依托专业的音乐人、好友推荐、算法推荐,以及社交功能,为用户打造全新的音乐生活方式。网易云音乐有一个非常受用户喜爱的乐评社区,加深了人和人之间的联系,用户会经常分享与歌曲有关的想法,形成了一个比较温暖的社区。另一个受用户好评的是云音乐精准推荐功能,它有很多推荐场景供用户进行选择,可以帮助用户快速发现更多更优质的歌曲,让我们千万的曲库,能够分发到每一个属于他的用户。同时,为了音乐产业的发展,我们对音乐人进行了大力支持。目前我们音乐内已经入驻了 10 万+的音乐人,每年可以产出 2 万多首原创歌曲,给音乐人创造了良好的音乐环境。
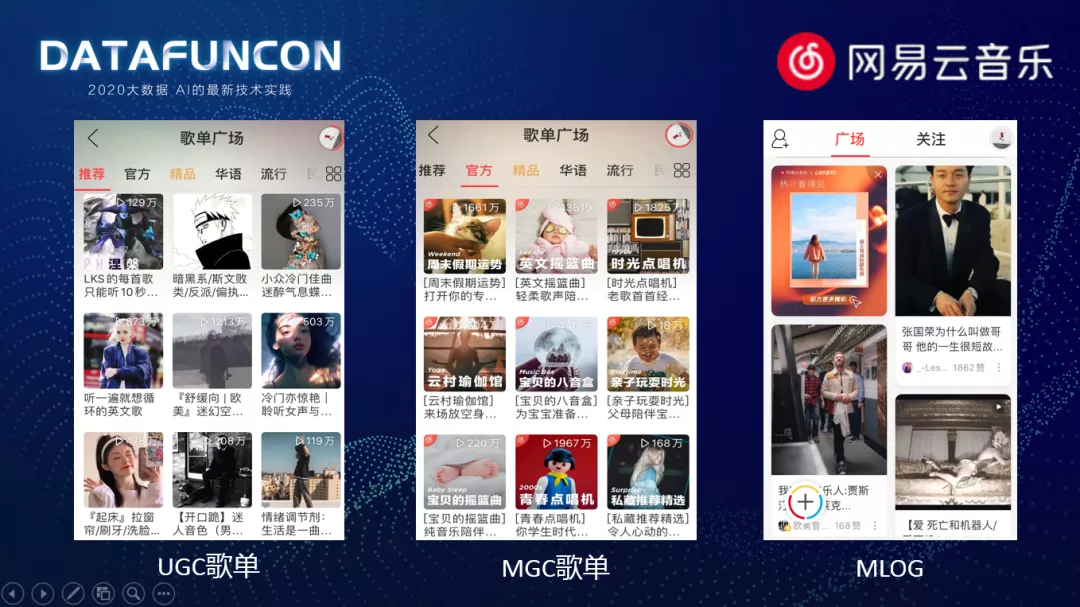
以 UGC 用户创建歌单,使云音乐打破了传统专辑歌手分类组织的方式。以歌单为核心的播放模式,可以以社交化的分享和个性化的推荐来解决用户发现寻找音乐的需求。19 年,推出了 MGC 的歌单形式,通过算法来动态生成各种主题的歌单,这种全新的形式给用户带来了全新的体验。使我们可以有更多优质的歌曲在歌单中得到有效的曝光。同时,我们还推出了 MLOG,一种图片音乐文字相结合的产品,让音乐不仅可以听,还可以看和玩。
2. 多形式推荐场景

回到我们最关注的音乐推荐算法:在云音乐内有非常多形式的推荐场景,供用户自行选择。
每日推荐:以列表形式展示,该场景会比较关注用户长期的偏好,让用户每天在这个场景中获得他喜欢的歌曲。
私人 FM:一种流式推荐方式,能根据用户实时播放行为去分析用户对之前对推荐歌曲的反馈,从而去影响后续要给他推荐的内容。对于那些想要寻找一些新奇新颖歌曲的用户,这种方式会是很不错的场景。
歌单推荐:同时对于歌单这种特有的播放形式,在首页和歌单广场上,也会进行丰富的推荐。
3. 音乐推荐 VS 电商推荐

大家可能对电商领域的推荐系统更了解,并且有很多团队做出了比较优秀的工作。所以,我们在音乐领域内想要完成一个推荐系统,与电商推荐系统有哪些不同?又有哪些差异?
两种推荐系统的相同点:
都是帮助用户去更快速的获取他们想要的资源
都是以用户使用体验为导向
但是这里的资源在电商领域是商品,而商品具有特定的功能和用途。所以对用户来说,有一个特定的现实作用。而对于音乐领域,一首歌曲,该怎么去理解?每个用户对歌曲的理解是千差万别的,如何把握住用户对音乐的感受是我们非常关注的。
其次一个非常大的不同点在于:商品是不可重复消费的。例如用户购买了一台电视机,可能在较长的一段时间之内,用户没有电视机的需求了。但是对于音乐来说,完全可以重复消费。比如一周之前听过的歌曲,可能今天还在听;昨天听过的歌曲,今天还可以单曲循环;甚至一个月之前一年前的那些老歌,都能拿来反复的进行播放。这一点就是非常大的不同。
同时,消费一首歌曲的时间成本是远高于点击商品的。可能几秒钟之内就曝光了非常多的商品,并且可以通过浏览商品的图片查看商品的标题。用户就能在短时间之内大致的了解到这些商品。但是歌曲就不一样,用户可能会对歌手有一定的了解。但是在很多情况下,演唱者对用户是陌生的。只有真正的去播放这首歌曲,甚至是需要播放到中间的副歌部分,才能真正感受到这首歌曲,对他的感觉,这就需要 1~2 分钟的消费时间。所以很多时候,用户历史的歌曲消费行为,包含着非常多的信息。如何把其中的关联关系挖掘出来,是我们研究的一个重点方向。
02 召回体系探索
接下来介绍下,我们在召回体系中做的一些探索和想法。
云音乐召回系统简化框架:
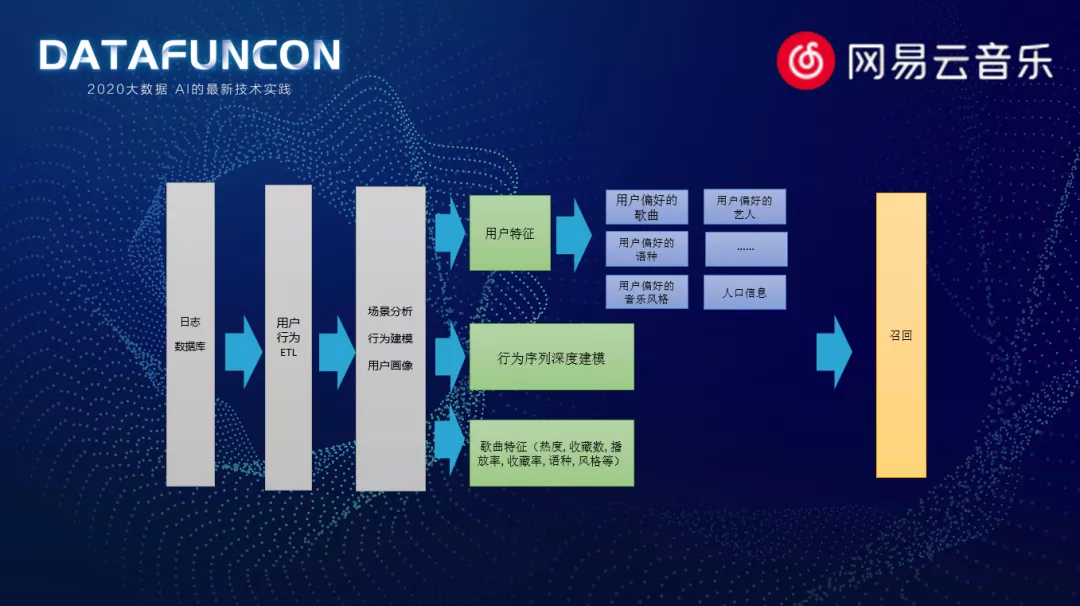
我们会从数据库中清洗、抽取用户行为序列,对用户进行偏好分析,对歌曲进行理解,以及对行为训练的深度建模。我们会从多个角度来进行歌曲的召回。之前云音乐做的部分召回算法,主要以 CF 协同过滤为主,我们在协同过滤算法中,也做了非常多的创新和优化,并取得了显著的效果。但是我们也非常想从用户自身行为中挖掘到隐式的信息。
问题思考:

所以在准备建立我们全新召回体系时,我们带着两个思考。
用户的兴趣点在哪里能够体现出来?用户的兴趣是单一不变的吗?
对于这两个问题,我们进行了比较多的调研和数据分析。最终,我们找到了两个方向:
一个是从用户的听歌记录中挖掘用户的兴趣点,就像前面说所说的音乐消费时间成本,从听歌记录中抓住用户的偏好
其次用户对音乐的感受是非常多样化的,并且会随着时间和用户的兴趣产生偏移
基于这两点,为大家介绍云音乐结合音乐相关知识的一些召回算法,并且其中的一些召回算法成功的在云音乐上线了。
1. 实时兴趣向量建模
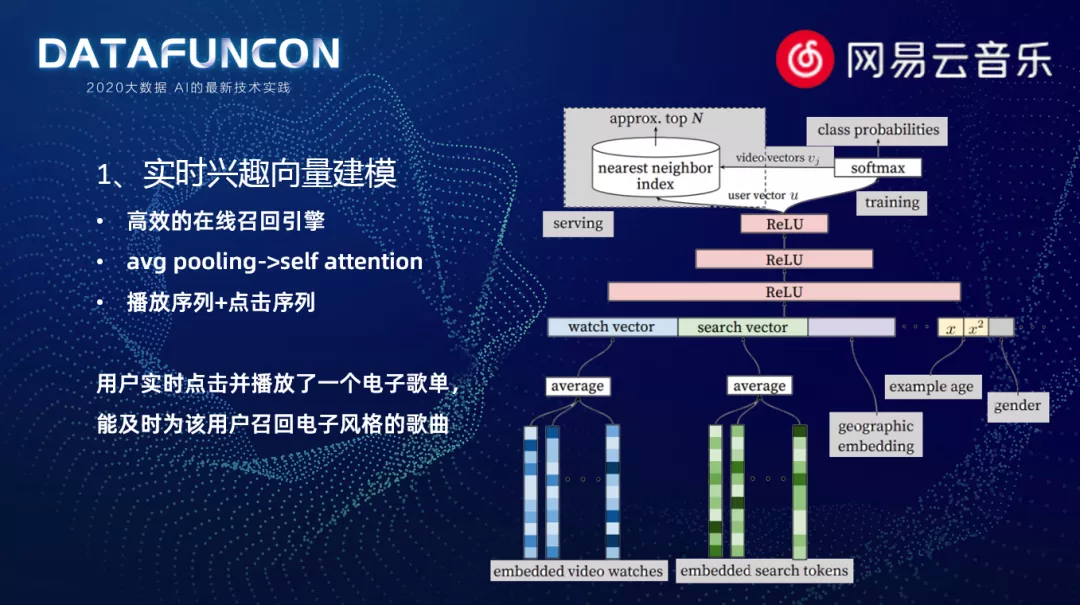
首先介绍实时兴趣向量召回模型。这个模型大家应该比较熟悉,原型就是 youtube 提出的视频召回模型。这个模型会将用户和歌曲映射到同一个低维度的向量空间中,计算用户和歌曲的相似值,取 top-k 作为最终的结果。这个模型首先会对性能有个比较大的要求,因为推荐的歌曲池比较大,所以要有一个比较高效的向量检索引擎。云音乐自研了 n-search 系统,给这些向量召回的模型提供了技术上的支持。
在这个模型上,我们做了一些优化:
其中一个优化是使用了 self-attention 来代替原有的 average-pooling。因为在云音乐里面,歌曲经常是以列表形式播放的,所以我们更需要关注的是列表中歌曲之间的关系。因此,我们使用了 self-attention 的网络结构来挖掘内部间的联系。
另一个优化是对于原有的搜索序列,我们会用点击的序列代替。因为我们最开始发现搜索这个序列,因为有 query 先验的信息,最终召回结果会非常依赖这个序列数据,很容易造成过拟合。所以我们转向了用户的另外一种主动形式,选择了用户点击歌曲的序列。因为从数据上会发现经常有些用户会将音乐一直播放着,成为一种背景音乐的形式,或者像是商场之类的公共场所,会不停地循环播放。但是,如果用户有点击,说明当前点击的歌曲是在用户主动意识下的一个行为,提高了置信度。
在这两点优化下,最后召回模型的效果比之前表现的会更加优异。例如,用户实时点击并播放了一个电子歌单,我们能及时给用户召回这个电子风格的歌曲。在模型中我们还对样本做了一些处理。比如说刚刚提到的商场播放歌曲,可以看作一种机器人行为。网易云音乐有为数众多的用户,他们的行为会非常的活跃,所以我们避免这些活跃的用户和机器人的行为影响最后的训练,我们会对每个用户限制样本的数据,避免负向影响。同时,我们在用户侧引入了非常丰富的用户画像信息,对于没有行为序列的用户,也可以触发这个召回模式,为这些用户召回歌曲。
2. 动态多兴趣建模
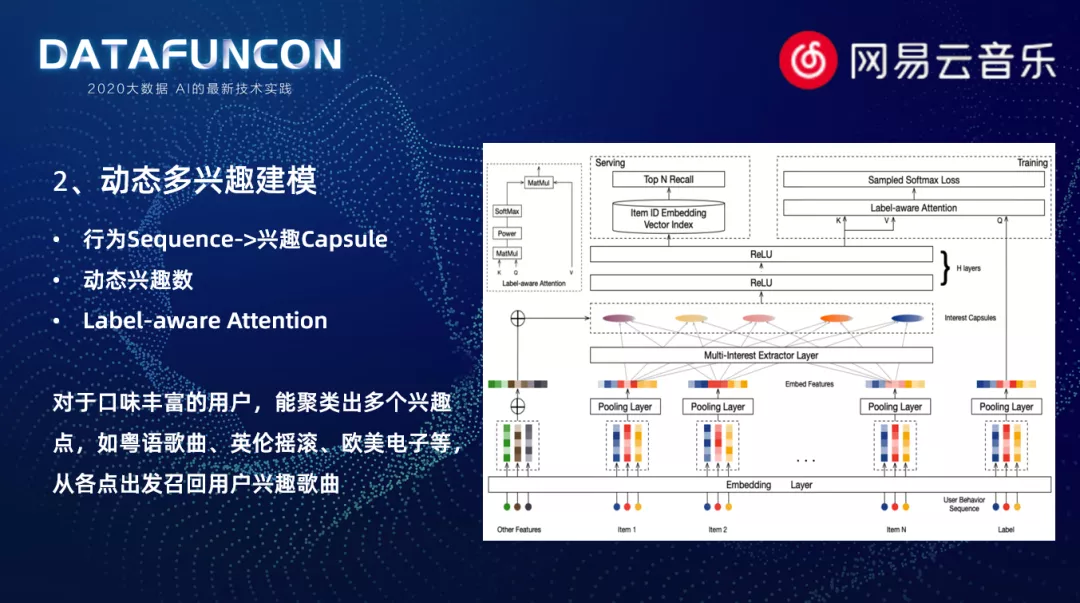
动态多兴趣挖掘模型:这个模型中,会将用户的行为序列作为输入,通过信息胶囊网络抽离出用户信息向量,也就是上图中间的网络结构。因为用户听歌记录其实是多样丰富的。比如说用户会在早上会听一些节奏比较欢快的歌曲,下午工作时可能会听一些舒缓的慢歌,周末可能会听一些摇滚的歌曲。所以我们需要通过建模,把用户内部的多个兴趣点挖掘出来。如果用户行为序列并没有那么丰富的话,可能它内部隐含的信息就相对比较少。此时,会选择动态的兴趣数,根据序列的长度来进行自适应的选择。这个模型在训练的过程中会使用 attention 的方式,把 target 信息利用起来。而在 serving 阶段,我们是没有 target 信息的。所以在这里对于用户的每个用户的兴趣向量,我们都将进行 topk 的召回。这个模型对于口味丰富的用户来说,能够训练出比较多的兴趣点,像粤语类的歌曲、英文的摇滚,欧美电子这一类的风格。
3. 音乐知识图谱
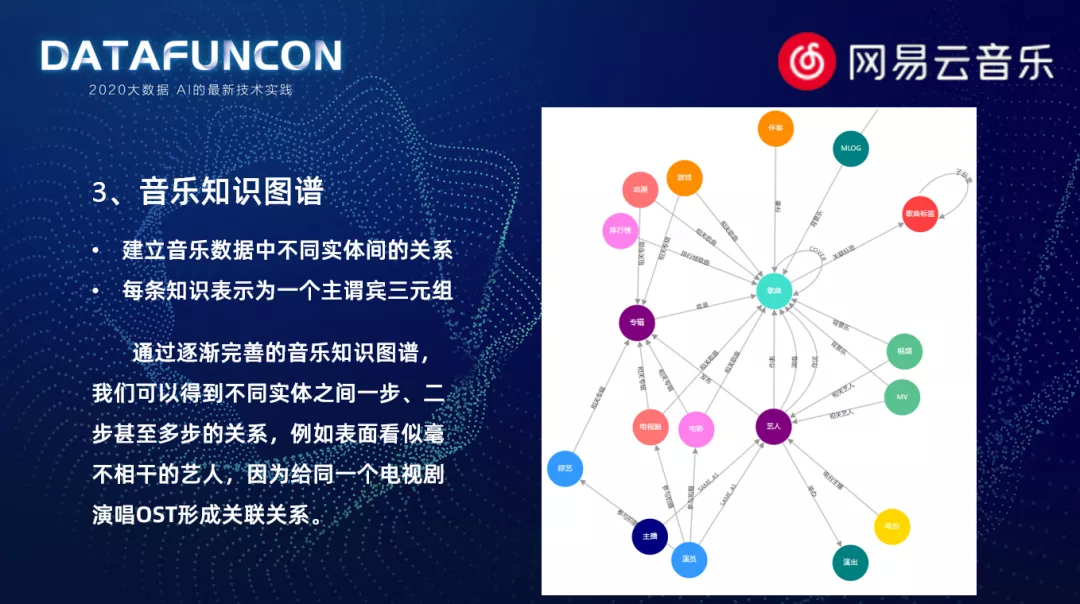
利用知识图谱的召回。我们的知识图谱,建立了音乐数据中不同实体之间的关系。这里面每一条知识表示主谓宾的三元组,比如说某一首歌曲是属于某张专辑的,而这张专辑又是某一个电视剧的原声音乐,这时我们会通曲库内部和外部的信息挖掘,逐步地把整个音乐知识图谱建立起来,可以得到不同实体之间一步两步甚至多步的关系,比如表面上看起来可能毫不相干的两个艺人,因为这两位艺人同时给同一个电视剧演唱的关系,就形成了一个关联关系。或者像一个综艺节目,例如我是歌手,参与不同季的歌手也可以形成关联关系。我们可以通过用户历史行为,关联到其他不同的实体歌曲,从而进行召回。而且音乐知识图谱中,不仅包含了歌曲这种实体。还包含视频、MV、MLOG 这些不同实体的信息,这些对于其他实体的推荐提供了有力的支持。
4. 长短期兴趣挖掘
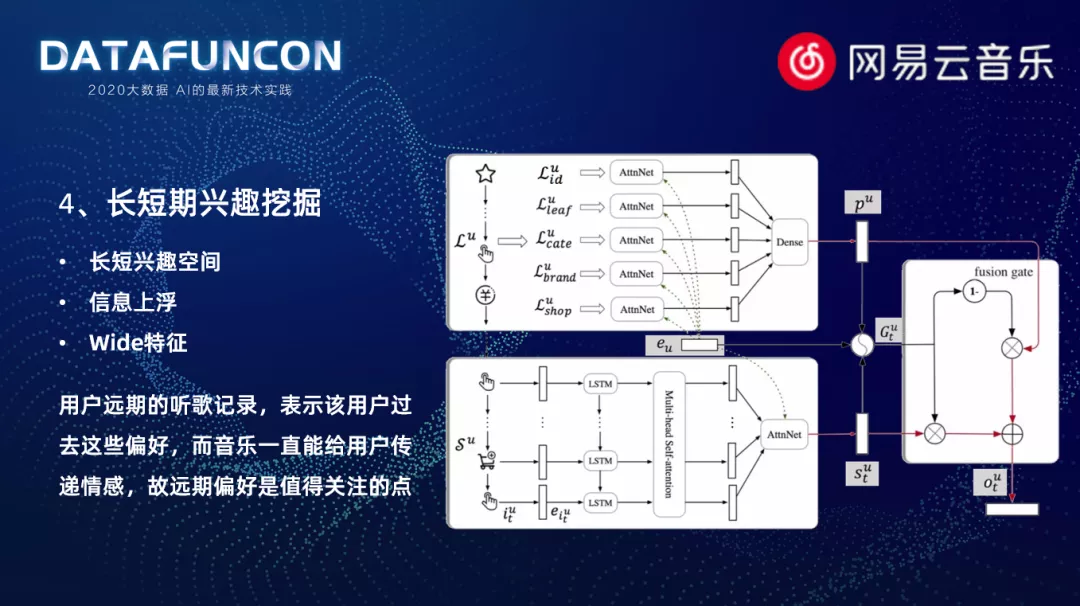
长短期兴趣挖掘模型:我们基于 SDM 模型进行了非常多的改进,在原始的 SDM 模式中,会通过一个门结构来进行长短期兴趣向量的加权。但在我们真实的实践中,发现了一个问题,我们把这个门结构中的权重打印出来,发现长期兴趣的权重非常小,最终用户加权的向量表示基本只包含了短期的兴趣,而对长期的兴趣影响非常小。这和我们最开始想要挖掘长期兴趣的目的是不符的。
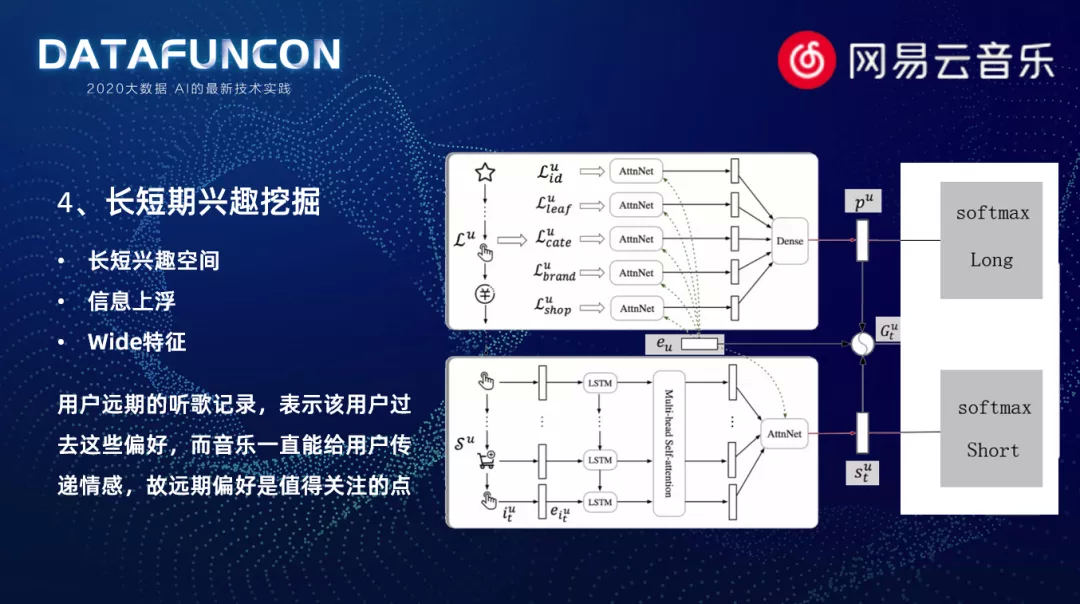
经过非常多的尝试后,我们最终将用户的性质分为长短两个兴趣空间。在长期兴趣空间和短期兴趣空间中,分别计算它的 loss,解决了我们最开始的问题。由于我们建了两个空间,我们在 side information 上做了比较多的尝试,扩充了非常多的 wide 类的特征。在整个建模过程中,我们对 feature 的输入也会进行一些优化。用户对一首歌曲,如果是具有重复播放的偏爱,他可能是因为喜欢演唱这首歌曲的歌手,或者喜欢这个歌曲的风格,或者语种是他非常感兴趣的。上层的信息一直影响用户感受,所以对于长期的信息建模过程中,我们将歌曲的信息进行了一个上浮,把歌曲的画像进行了详细的建模。这个模型,也是融入了云音乐算法团队很多的思考和对音乐本身的理解,最后有效的权衡了音乐传感器的兴趣。
5. 为什么需要多路融合召回?

除了以上介绍的召回模型,我们还有非常多的其他的召回方式。为什么音乐推荐需要多路融合召回?答案是我们算法对音乐的理解,因为音乐的本质是情感的寄托。可能这句话会比较抽象,从歌曲和用户两个角度来具体解释下:

歌曲会有非常多的标签,像常见的语种、风格,就有非常多的类别。而场景情感主题这些标签,是基于用户对这些歌曲的感受来分类的。而且同一首歌不同的用户也会听出不一样的感受,所以这就需要我们将歌曲的不同维度、用户的偏好来进行充分挖掘,精准的找到用户喜欢这首歌的点在哪。然后我们也可以从歌曲的评论区中,发现很多用户评论表达的一些情感,比如这里有用户说:"这首歌曲他听了非常多年,还是一直很喜欢"。所以说用户的情感是一直存在的,算法要做的就是对这些情感进行唤起,来加强用户对于情感的表达。
03 精排模型演化历程
下面分享云音乐在精排系统中关于用户行为序列的一些深度建模经验:
行为链路:
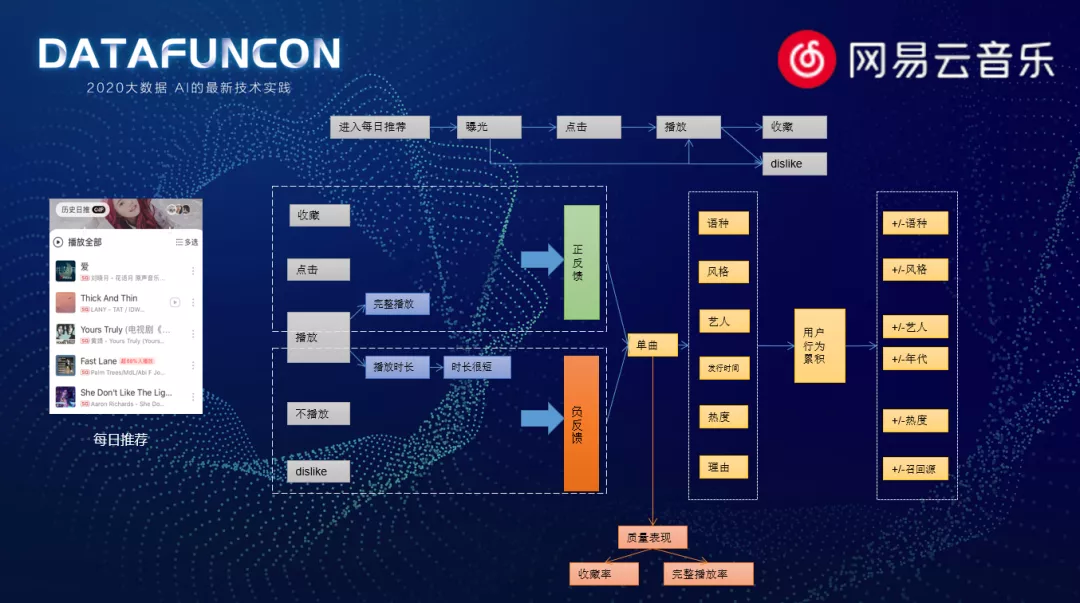
在具体介绍精排模型之前,简单介绍下用户在云音乐中的行为链路。我们以每日推荐场景来做具体的介绍。用户进入日推,首先歌曲会得到曝光。用户可能会点击某些歌曲,也可能直接进行了播放。在播放的过程中或者结束时,用户会进行显隐式的反馈。比如进行收藏行为或者是切歌的行为,甚至可以将歌曲标注为不感兴趣,当然也可以什么都不做,继续播放下一首。在用户整个行为里面,可以看到收藏、点击、完整播放,这些 action 是属于用户正向的反馈;而曝光不播放或者是曝光时间非常短,不感兴趣的,都是一些负反馈。对用户这些行为进行累积,我们可以对他之前的语种偏好、风格偏好、艺人、年代热度等等,进行重新调整,从而更好的进行下一次推荐。
云音乐精排模型迭代历程:

云音乐精排模型的迭代历程,时间跨度比较久。最开始从最简单的线性模型开始,有比较强的解释性,并且符合当时快速迭代的需求。但是它的缺点还是比较明显的:表达能力非常有限。所以在此基础上我们逐渐在这个方向进行优化。对于模型的拟合能力,希望有更进一步的加强。在后期,也逐渐的引入了外部的特征,我们做了比较多的特征交叉,使我们的特征维度达到了很高的级别。最后,利用参数服务器成功将 FTRL 模型在云音乐中得到了一个上限,模型记忆类的特征使得整个模型的刻画能力得到了非常大的加强,但因为特征维度过大,计算的复杂度很高,逐渐向深度神经网络进行发展。全连接网络和一些 cross 的操作使得模型的表达能力变得更强。我们慢慢将用户的行为序列考虑了进来,学习用户行为序列中隐藏的关系。
整个过程中,也是我们对业务理解逐渐加深的过程,所以模型也会复杂化。后面要分享的是我们在深度时序网络阶段中,结合用户相关的行为数据,做的一些创新和优化。
1. 用户行为序列建模
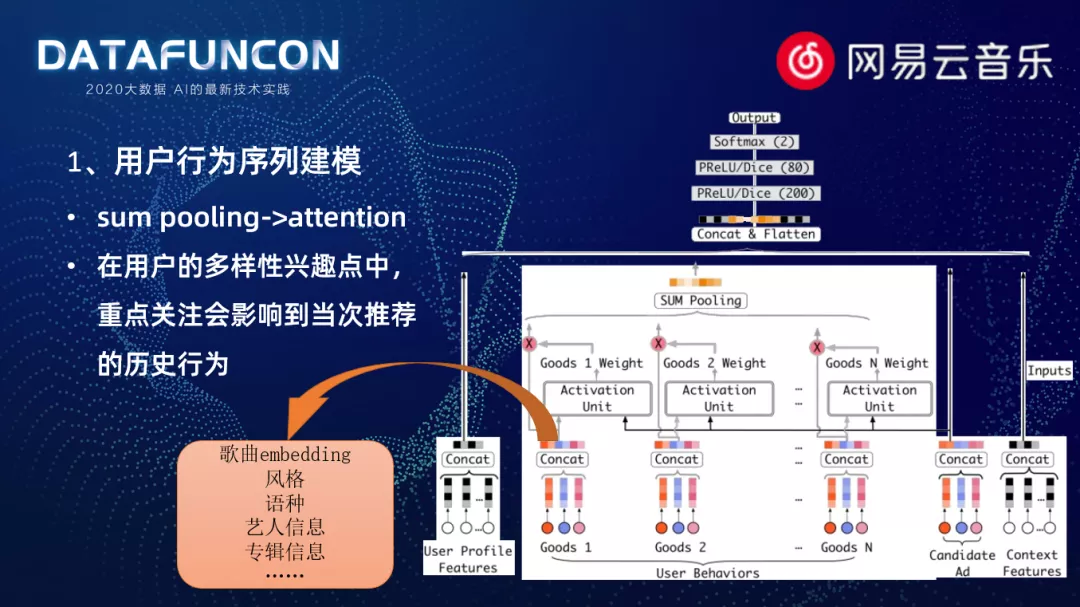
首先尝试的是深度兴趣网络模型,这个模型和之前所尝试的模型,一个比较大的突破,是在用户行为序列数据上的处理。之前会将用户序列行为的 embedding 向量进行 sum pooling 操作。这种压缩方式,会造成一些程度上的信息丢失。对于相当重要的 embedding 向量,可能就没有办法完全突出自己的信息。所以我们在建模的过程中引入了 attention 机制,attention 机制的本质可以认为是一个加强的求和,可以让模型更加关注到它认为有用的信息,着重的影响本次推荐的行为。每一首在行为序列中的歌曲,我们也会刻画的比较丰富。对于歌曲画像,我们会包含歌曲的 embedding 向量、风格、语种、艺人信息、专辑信息等等。丰富的歌曲画像,可以让模型更好的关注到用户本次点击的兴趣点在哪里。
2. 用户兴趣演化模型
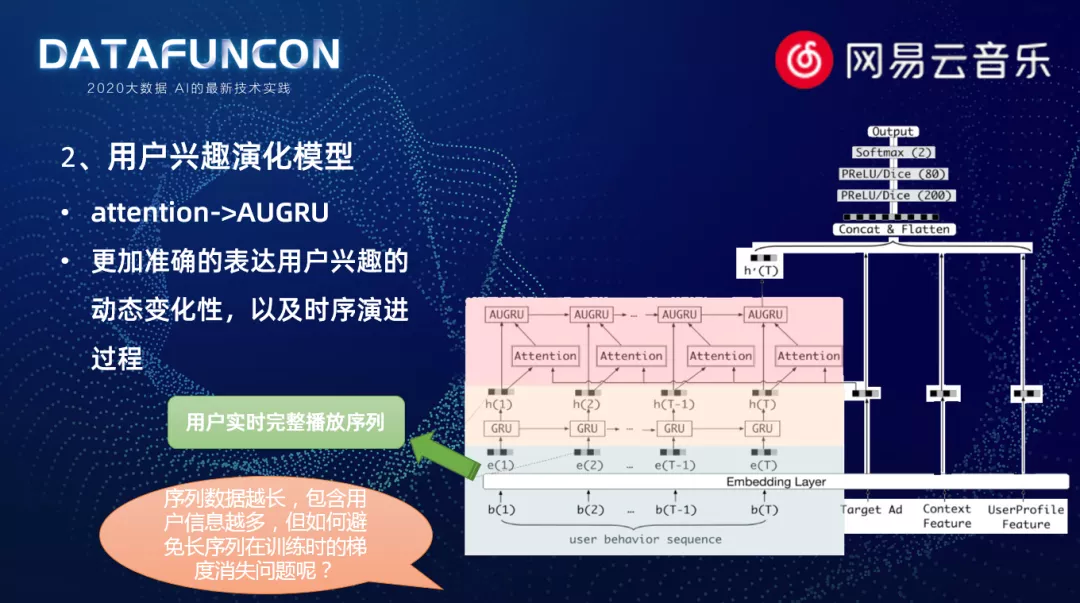
在做推荐系统的过程中,很容易体会到一个现象,就是用户越新的行为,能够反映用户当时的兴趣,对于推测之后的行为发挥的作用也是越大的;旧的行为发挥的作用就相对弱一些,这说明用户的兴趣是在不断变化的。特别是在音乐中,外界的流行趋势会发生非常大的改变。可能在几年内,甚至是几个月内流行的方向,就发生一次非常大的改变。同时,用户自身的兴趣,也会发生变化。所以我们在模型中,如何捕捉用户兴趣的演化路线?于是有了用户兴趣演化模型:
我们将 attention 机制继续延用了下来,并且加入了 ARGRU 网络结构。两者相结合,既保留了原先的注意力机制,又能捕获用户歌曲兴趣发展的路径。在这里我们使用的序列,是用户实时完整播放的序列。他使用了一个实时数据,所以在线上预测时,我们可以对用户实时的行为得到快速反馈。另外,我们在做播放序列长度时,也进行了一些探索。很明显,如果播放序列越多,包含的行为也就越多。但是过长的数据,在实训模型中容易造成梯度消失问题,如何将更多行为融入进来,是我们接下来要思考的一个方向。
3. 基于会话的多行为域模型
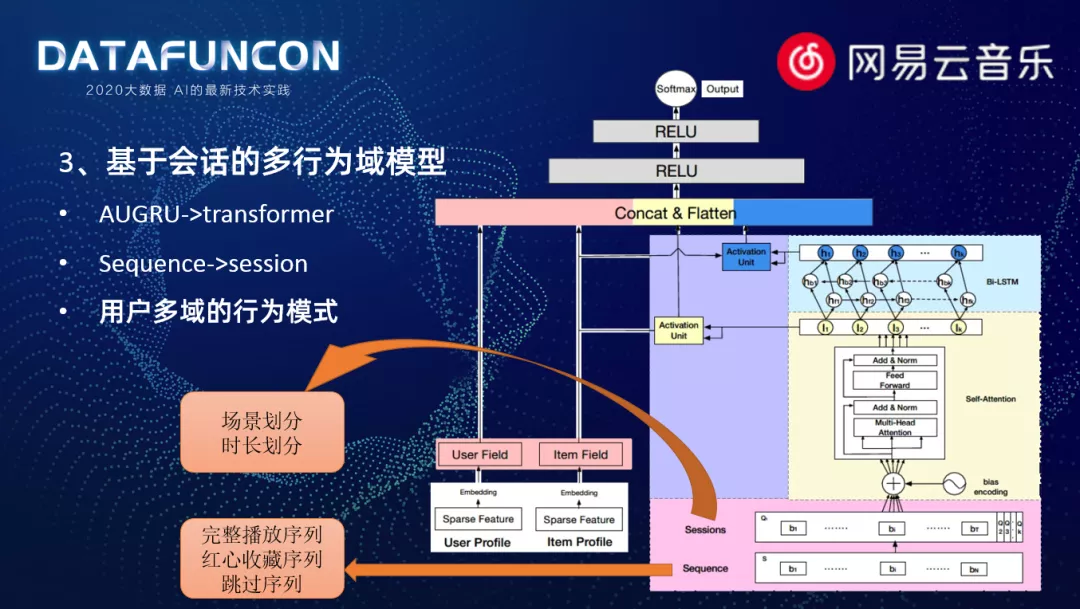
前面的学习建模过程中,我们使用的都是用户整体的行为训练,忽略了序列内部的机构。用户的行为序列是由多个会话组成的。然而往往用户会话序列内部,性质偏移比较小,目的性会比较一致。但是在会话之间有着比较明显的差异,所以我们会进行 session 划分。我们可以得到用户 session 内部的投入行为以及 session 之间的递归行为。这样的划分,从序列演化到 session,可以关注到更长远的行为数据。在音乐场景,我们对 session 的划分,主要分为两个点:
一个是因为音乐它有非常多的推荐场景,每一个推荐场景使用目的都是有差别的。用户选择不同的场景,都是基于用户主动意识,所以我们通过场景就可以将序列进行一个初步的划分
其次,听歌过程中,用户会有一定的疲劳感。如果时间过长的话用户的注意力可能就不会那么集中,所以我们对 session 的最大时长做了切割
这两点是我们对 section 数据的处理。

我们在模型中做了更大的尝试,考虑了用户更多行为域的行为模式。之前我们所使用的用户行为都是完整的播放歌曲序列,在这里我们加入了一个红星收藏序列和跳过序列。为什么我们要将用户不同的行为序列考虑进来。我们观察播放的整个详情页,里面有很多的控件,比如收藏按钮,表示用户将歌曲加入红心收藏歌单中,这是用户非常强烈的行为。同样下载歌曲或者分享,都是明显的正向行为。对于评论信息,我们要具体分析评论的内容,利用 NLP 技术进行情感分析,去判断用户真正情感。如果用户对这首歌曲标了不感兴趣,甚至是拉黑了歌曲或者艺人,那么这就是显著的负向行为。还有比较隐蔽的负向行为,就是用户在播放的过程中进行切割操作,这是一个没有消费完全的状态,对用户来说是不好的体验。所以我们会通过对用户行为的不断扩充,把用户正向和负向的行为,进行完整的刻画。
4. 再说音乐推荐 VS 电商推荐

回到最开始我们提到的,两个推荐系统的差异。这些问题,其实在刚刚介绍召回和精排系统中有提到。对于音乐资源我们会从各种维度进行偏好的分析,建立一个比较完善的歌曲画像。同时,虽然这次分享没有提到,但是云音乐也利用了 NLP、图像、音频等技术,从内容上去理解歌曲本身。对于是否可以重复消费这个问题上,我们会关注用户长期的兴趣偏好,达到长短期用户兴趣的动态平衡。对于用户的行为序列,进行显隐式的拆解,刻画用户真正的行为意图。对于长短期兴趣和用户行为确认这两个方向,还是有很多的发展空间的,这也是之后我们需要继续努力的研究方向。
04 音乐推荐场景 AI 思考

最后分享下在音乐推荐场景下对于 AI 算法的思考。音乐是反映人类现实生活中,一种情感的艺术;AI 是一个理性的产品,它为人们提供便利的生活。理性和感性的结合,并不是相互抵消的过程,反而能发挥出更大的效果。我们认为健康良性的音乐系统 ( 如图所示 ),通过 AI 技术,可以帮助用户去发现更多感兴趣的音乐,让用户能够沉浸在音乐带给他的快乐当中。更多用户的使用行为可以帮助我们挖掘更多长尾歌曲,挖掘那些小众但是优质的音乐,使优质的歌曲都能得到合理的分发。我们的推荐歌曲池也会变得更多更好,可以更好地服务给用户。以上,就是我们的网易云音乐推荐团队对 AI 和音乐的理解。
今天的分享就到这里,谢谢大家。
作者介绍:
章莺,网易云音乐资深算法工程师
毕业于浙江大学数学系,目前就职于网易云音乐,担任资深推荐算法工程师,主要负责音乐推荐系统相关算法工作,在召回、排序、歌曲分发上有丰富的经验。率先在云音乐实践百亿级别实时推荐模型,并在多目标训练和序列行为数据上有深入的研究。
本文来自 DataFunTalk
原文链接:




