文章概要:数据库领域的两位重量级人物 Michael Stonebraker 和 Andrew Pavlo 联合发表论文,以 20 年为周期洞悉数据库产业发展,盘点数据库领域的发展,本文是第二篇(https://db.cs.cmu.edu/papers/2024/whatgoesaround-sigmodrec2024.pdf),第一篇发表于 2004 年(https://books.google.com/books?hl)。文章结合近 2 年来 AI 蓬勃发展,给出了非常具体的辛辣“评论”。两位大神作者,帮助读者拨开迷雾,了解数据库领域发展的脉络,帮助读者看清数据技术的发展路线。Michael Stonebraker 和 Andrew Pavlo 的总结很有洞见,但笔者不完全同意文中对未来的预测观点,同时认为支撑 RDBMS 和 SQL 的核心支柱正在发生动摇:AI 的出现正在撼动数据库领域的“传统”模式。未来的数据架构和模式的演进,有更多可能性等待业界学者和产研专家们发掘。
引言:图灵奖得主联合撰写论文,洞悉数据库近 20 年发展脉络
最近,数据库领域的两位重量级人物 Michael Stonebraker 和 Andrew Pavlo 联合发表了一篇题为“What Goes Around Comes Around…and Around…”的论文。这篇文章可以看作是 Stonebraker 教授 2005 年那篇著名综述“What Goes Around Comes Around”的续篇,试图在新的时代背景下重新审视数据库技术的发展历程。
作者背景
Michael Stonebraker 教授是数据库领域的传奇人物,因在数据库管理系统方面的开创性贡献而获得 2014 年图灵奖。他参与创建了多个著名的数据库项目,包括 Ingres 和 PostgresSQL。
(图:作者 Michael Stonebraker, 维基百科)
另一位作者 Andrew Pavlo 则是卡内基梅隆大学计算机学院的教授,他的研究集中在数据库管理系统的设计和实现上。Pavlo 曾创立创业公司 OtterTune,提供自动数据库调优服务。(btw,上个月公司关门了)
(图:作者 Andrew Pavlo,维基百科)
2 论文的主要内容和观点
论文对过去 20 年数据库领域发展过程中出现的数据模式和查询语言做了完整的盘点,包括了以下领域 (1) MapReduce Systems, (2) Key-value Stores, (3) Document Databases, (4) Column Family / Wide-Column, (5) Text Search Engines, (6) Array Databases, (7) Vector Databases, and (8) Graph Databases。
两位作者简评了目前 DBMS 架构上的演进方向,包括:
(1) 列式系统 Columnar Systems 革命性地改变了 OLAP DBMS 架构
列存储数据库在分析场景下优于行存储,因为其可以获得更高的压缩率,并且只需读取查询相关的列,大大降低了 I/O 开销。现代列存储系统还引入了向量化执行、代码生成等查询优化技术,进一步提升了性能。
不过,列存储在事务处理等混合负载场景中难以发挥优势。因此,主流的行存储数据库也开始增加了对列存储的支持。未来,行存储与列存储很可能会进一步融合,以应对日益复杂多变的数据管理需求。
(2) 云数据库 Cloud Databases 让用户更方便的使用可扩展的数据库系统
云计算催生了一批专为云环境设计的云原生数据库系统,如 Redshift,BigQuery 等,它们能够充分利用云基础设施的弹性和高可用性。同时,传统的本地数据库也陆续推出了云托管版本,以期在云时代保持竞争力,但它们在云上的部署和管理仍然较为复杂。此外,云数据库普遍采用了按需付费的订阅制定价模式,这降低了用户的前期成本 ; 而数据库即服务 (DBaaS) 模式则让用户无需关注底层基础架构,进一步简化了管理。
不过,作者也指出云数据库引发了一些新的担忧,如供应商锁定、安全与隐私等问题。未来,开放中立的数据云平台如 Snowflake 或 Databricks(i.e. 国内如云器 Lakehouse,-- 编者按),以及配合相关标准规范的制定,或许可以缓解这些担忧。
(3) 数据湖和数据湖仓 Data Lakes / Lakehouses 基于云上的对象存储并使用开源的数据格式将是 OLAP DBMS 未来十年的架构趋势
数据湖和湖仓一体架构是大数据时代数据管理的重要发展趋势。数据湖支持存储各种结构化、半结构化和非结构化数据,为数据科学和分析提供了统一的数据源。但传统的数据湖方案在事务处理、元数据管理、数据治理等方面仍有不足。因此,Databricks 公司提出了湖仓一体架构的概念,旨在将数据仓库的结构化处理与数据湖的灵活性相结合。例如,Delta Lake 引入了 ACID 事务和模式演化等特性 ; 而 Apache Hudi 和 Apache Iceberg 等开源项目则侧重于数据湖上的增量处理和元数据管理。
不过,作者指出,湖仓一体架构的成熟度还有待提高,许多系统集成和性能优化的问题仍有待解决。同时,用户也需权衡湖仓一体架构的复杂性和引入成本。未来,数据湖与数据仓库的界限可能会逐渐模糊,两者的优势或将融合交汇,形成统一的大数据管理平台。
(4) 新型 SQL 系统 NewSQL Systems 有望在未来弥补 NoSQL 系统在事务支持方面的短板
NewSQL 作为数据库技术的一个新的发展方向,虽然目前还不如列式数据库和云数据库成熟,但有望在未来弥补 NoSQL 系统在事务支持方面的短板,在某些场景下提供更优的选择。不过,NewSQL 能否真正实现“鱼与熊掌兼得”,还有待时间的检验。
NewSQL Systems: They leverage new ideas but have yet to have the same impact as columnar and cloud DBMSs. It has led to new distributed DBMSs that support stronger ACID semantics as a counter
to NoSQL’s weaker BASE guarantees.作者认为 NewSQL 系统利用了新的理念,但尚未达到列式数据库和云数据库同等的影响力。NewSQL 的出现导致了新的分布式数据库管理系统的诞生,这些系统支持更强的 ACID 语义,与 NoSQL 的较弱的 BASE 保证形成对比。
但是客户对切换到 NewSQL 兴趣不大,背后的原因在于,对于当下而言,现有的数据库管理系统已经足够好了。这意味着,各组织不愿意承担将现有应用迁移到新技术所带来的成本和风险。
The reason for this lack- luster interest is that existing DBMSs were good enough for the time, which means organizations are unwilling to take on the costs and risk of migrating existing applica- tions to newer technologies.
(5) 硬件加速 Hardware Accelerators 并未见到更多落地案例
作者坦言,除了主要的云厂商在做相关尝试,并未见到更多特别的硬件加速的落地案例。尽管很多初创企业在这个领域还在不断尝试。
硬件加速器可以提升数据库的性能,尤其是在处理计算密集型任务时。不同类型的加速器,如 FPGA、GPU 和智能 SSD,都已经在一些数据库系统中得到应用。例如,Swarm64 DA 使用 FPGA 来加速 SQL 查询 ;Brytlyt 和 BlazingDB 等系统使用 GPU 来并行处理大规模数据 ; 而 Oracle、IBM 和 Samsung 等公司则探索了智能 SSD 在数据库中的应用。
但是,作者也指出了硬件加速器在数据库中应用的一些挑战,如硬件异构性、编程复杂性、可移植性差等。此外,加速器可能带来额外的成本和能耗。展望未来,作者认为硬件加速器与数据库的结合将成为长期趋势。数据库需要提供更好的抽象和接口,以充分利用加速器的性能优势,同时降低开发和维护成本。而加速器也需要在通用性、可编程性等方面进一步提升,以适应数据库的需求。
(6) 区块链数据库 Blockchain Databases 尚在寻找应用场景的低效技术
Stonebraker 和 Pavlo 对区块链数据库并不看好,称其是尚在寻找应用场景的低效技术。历史已经证明,这是一种错误的系统开发方式。
Blockchain Databases: An inefficient technology looking for an application. History has shown this is the wrong way to approach systems development.
作者基于过去 20 年的数据库领域经历,总结出以下“原则”
Never underestimate the value of good marketing for bad products.
不要低估市场营销的力量,可以延长“糟糕”产品的生命力
Beware of DBMSs from large non-DBMS vendors
警惕来自大型非数据库供应商的数据库管理系统。-- 说的就是你 Meta,Linkedin
Do not ignore the out-of-box experience
不要忽视(产品)开箱即用的体验(的价值)。
Developers need to query their database directly
开发人员需要直接查询他们的数据库。(尽管很多应用使用抽象层与数据库交互,但开发人员仍需要直接查询数据库,因此选择支持 SQL 的关系型数据库是更好的选择。)
The impact of AI/ML on DBMSs will be significant
人工智能 / 机器学习对数据库管理系统的影响将是巨大的
3 总结关系模型:数据库发展“轮回”的“主线”
纵观全文,Stonebraker 和 Pavlo 一起引领我们回顾了过去 20 年数据库系统 DBMS 发展的主要脉络,总结了这 20 年的发展趋势和技术演进方向,可以概括成以下四点:
关系模型是数据库领域持久稳定的"主线",新的数据模型最终都会回归或趋同于关系模型 ;
SQL 作为关系模型的标准查询语言,在表达能力和易用性方面还难以被取代 ;
底层架构的创新丰富了关系型数据库的应用场景,但没有动摇其核心地位 ;
未来也很难出现彻底颠覆关系模型的变革,新的研究热点可能是探索 AI 技术与关系数据库的结合。
恰如文章的标题“whats goes around comes around”,所有 goes around(发展出去的技术)最终 comes around(回归)到关系模型和 SQL 查询语言,这个主线上来。
4 未来仍是“轮回”?笔者略有不同观点
首先,要澄清的是笔者同意 Stonebraker 和 Pavlo 在论文中对过去技术演进的总结部分和评论观点,作者以独到的见地和高屋建瓴的洞察,对几十年间的技术创新有辛辣的点评,带给了读者深刻的反思与思考。
然而,笔者同意作者的前一半总结观点,不同意的是对未来发展脉络的预见:
尽管关系型数据库的应用场景确定不会消失,但主线地位不保
非关系型、AI 驱动的新模式正在崛起,或将成为撼动关系模型的关键要素
5 关系模型在过去历久弥新,因其易于“人”的理解和使用
关系模型以"关系"(即二维表格)作为数据的基本表示和操作单元,任何复杂的数据结构都可以转化为若干张规范化的表。这种抽象具有普适性,能够自然地对应到现实世界中的各种实体及其之间的联系。同时,二维也是一种简洁直观的数据形式,易于“人”的理解和使用。正是得益于关系模型在抽象层面的优雅,结合 SQL 所想即所得的描述型语言,两者结合能够被广泛接受,成为数据库领域事实上的通用语言。

(图:RDBMS 与 SQL 查询)
挑战一:AI 正在重塑数据的生产和消费方式
传统的数据库系统主要面向以“人”为中心的应用场景,数据的生产者和消费者都是人。然而,随着物联网和 AI 技术的普及,越来越多的数据是由机器生成,并被机器所“消费”。相比结构化的业务数据,机器生成的数据通常具有非结构化或半结构化的特点,而机器学习算法对数据的“消费”方式,也与 SQL 查询有着本质的不同。
以深度学习为例,神经网络模型通常需要将数据表示为高维向量或张量,并进行大规模的矩阵运算。这与关系模型的行存储方式和基于集合代数的查询语义有着天然的差异。对人来说最优的可理解的数据,对机器或 AI 来说或许就是“局限”。为了让 AI 系统高效地访问和处理数据,我们或需要重新设计数据的表示和操作方式,而这很可能不是适配关系模型的最佳范式。
挑战二:RDBMS 和 AI 模型的“比例”关系正在改变
过去 20 年来,关系模型始终处于数据库的主线,AI 作为单独场景的特殊处理方式,以 ML/DL 机器学习和深度学习的方式服务特定场景,并由专业的数据科学家主导领域的探索和落地应用。可以说,关系模型为主,AI 模型为细分场景为辅的架构模式。企业实践中,可能关系模型占比 80%,AI 模型占比 20%,这样的比例关系较为常见。然而随着 AI 和更强的算力 GPU 等技术的崛起,这个比例关系正在改变。
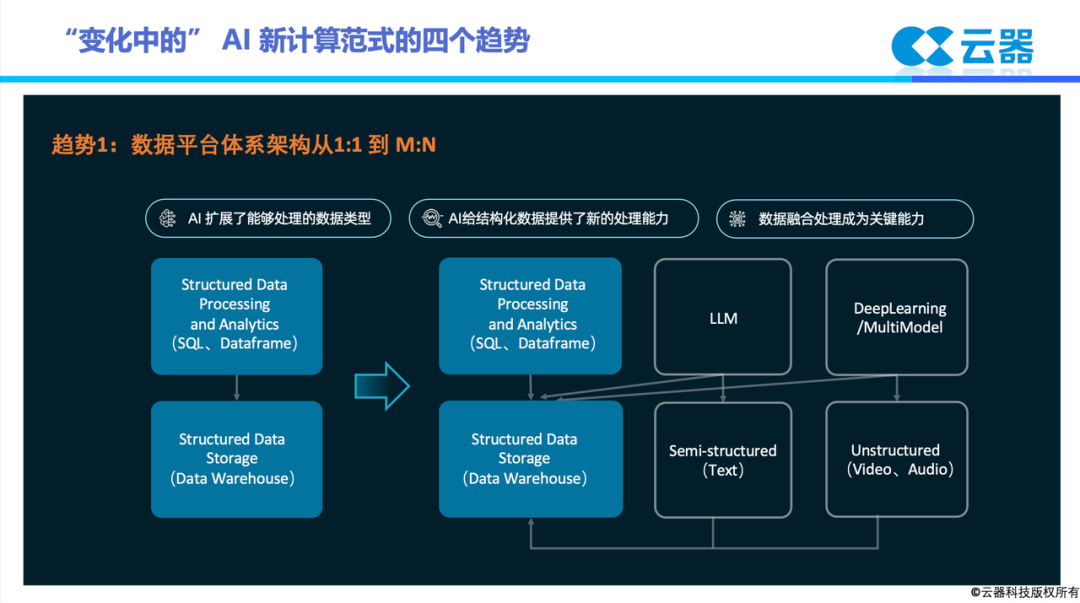
AI 正在全面取代“大数据”时代的传统模型和方法:
以智能汽车为例,Tesla 凭借积累的海量驾驶数据训练的车载模型,正在帮助其实现真正(L4+)的无人驾驶
Tesla 最新对北美开放 FSD 12.3.4 版本,或建立“L4 级别”自动驾驶体验

此外,更多实践案例正在发生,例如通过大模型实现电商商品推荐等
或者我们需要提出一个问题,原来通过传统“大数据”的方式解决的问题,今天是否可以通过 AI 大模型解决?效果是否更好?如果答案是肯定的——那么,我们正在目睹 AI 大模型取代传统大数据时代的解题方式。
2024 年,我们确信将见证更多 AI 能力在商业环境中落地实现。
挑战三:基于 RM 的数据分析平台与面向 AI 的数据平台,是什么关系?融合 or 分裂?
两大数据平台领域巨头给出了他们的答案——选择全面 AI 战略
面对 AI 浪潮的挑战,数据库领域的两大巨头 Databricks 和 Snowflake 已经分别给出明确的答案:全面拥抱 AI。在最近的产品发布会上,双方不约而同地推出了面向 AI 的新产品线。

Snowflake 发布了 Cortex AI,旨在将机器学习功能无缝集成到数据仓库中。通过 Cortex AI,用户可以直接在 Snowflake 平台上训练、部署和管理机器学习模型,实现数据管理和智能分析的一体化。
Databricks 宣布了 Mosaic AI,这是一个基于 Lakehouse 架构的智能计算平台。Mosaic AI 在 Databricks 的 Lakehouse 之上,提供了 AutoML、特征工程、模型服务等一系列 AI 工具,帮助用户简化机器学习的开发和部署流程。
除了在 AI 领域的布局,Databricks 还通过资本手段巩固了自己在开放的数据存储格式上的优势。近日,Databricks 收购了 Apache Iceberg 项目的商业化公司 Tabular。Apache Iceberg 是一个开源的数据湖表格式,与 Databricks 主推的 Delta Lake 形成竞争关系。此次收购不仅阻断了对手在数据格式上的优势,也为 Delta Lake 的发展扫清了障碍。笔者在早些时候的文章《暗战升级,Databricks 收购 Tabular,Iceberg 社区陷入动荡》中对此有更深入的分析。
Databricks 和 Snowflake 的这些动向表明,业界巨头已经开始积极适应 AI 时代的新需求。一方面,他们将 AI 能力与传统的数据仓库和数据湖进行深度融合,为用户提供端到端的智能分析解决方案。另一方面,他们也在数据存储、管理等底层技术上展开角逐,试图以新的数据格式和架构获得先发优势。
第三个巨头的选择,OpenAI 收购数据实时分析产品 Rockset
让业界意外也不意外的是,OpenAI 正式宣布收购 Rockset——这是一款以数据索引及查询功能而闻名的实时分析数据库。OpenAI 在其官方博客上发表的一篇文章中表示,它将整合 Rockset 的技术来“为其所有产品的基础设施提供支持”。
“数据巨头转向 AI,AI 巨头走向数据,是 Data+AI 时代的双向奔赴。”
6 结语:未来关系模型和非关系模型会如何发展,企业该如何选择
上个世纪初,物理学界曾经有两朵乌云笼罩。一个是黑体辐射问题,另一个是微观物质的波粒二象性。这两朵乌云挑战了当时牛顿经典力学所建立的物理世界观,最终催生了量子力学和相对论的诞生,彻底革新了人类对宇宙的理解。
今天,数据库领域何尝不是如此?RDBMS 关系型数据系统和 SQL,就像经典力学一样,已经主导了数据管理的大部分场景。Stonebraker 和 Pavlo 认为,未来也很可能会是关系型数据库的天下。然而,正如文中所言,人工智能技术的崛起,却像是悬挂在数据库世界上空的一朵乌云,预示着可能会有一场革命性的颠覆。
人工智能对数据的处理方式,对数据库的功能诉求,很可能会从根本上挑战关系模型的某些假设。AI 更加擅长处理非结构化数据,更加依赖数据的关联性和图形结构,更加需要数据库的自适应和自优化能力。这些需求,都可能催生出新的数据模型和数据库范式。
因此,未来的数据库世界,可能会像物理学一样,经历一场范式的革命。这场革命,也许会诞生出全新的数据模型,也许会重塑数据库的架构和生态。对于企业来说,在选择数据库时,不仅要看它在已知场景下的表现,更要评估它适应未知变化的潜力。
变革时代,企业应如何选择?
笔者建议:
对于数据业务偏传统的企业,保持关系模型的传统数据库方案,是最稳妥的选择。可根据自身情况选择传统 OnPrime 或云上数仓;
对于数据创新型企业,有将 Data+AI 应用的可能性的场景,此时是思考如何借赛道切换完成数据底座升级的时机;
让我们拭目以待,见证 AI 时代的风起云涌,见证下一个"量子力学"的诞生。
作者简介:
苏郡城,云器科技运营总监,云计算大数据领域专家。曾主导阿里云国际业务数据体系建设, 十余年一线数据化运营实战,助力企业实现数字化增长,热衷于技术社区分享。
专栏“云声数语”甄选云计算大数据前沿动态和实践干货,致力于启发数字化转型新思路。欢迎关注云器科技公众号,与数据对话与智慧同行,改变数据的使用方式!
今日好文推荐
德国再次拥抱Linux:数万系统从windows迁出,能否避开二十年前的“坑”?
15 年功臣、英伟达主任科学家在股价巅峰期黯然辞职:对不起自己拿的丰厚报酬
开源独角兽 GitLab 走上“卖身”路!前工程师拆台:赚钱的业务不好好运营,开发了一堆没用的功能