
截至 12 月 23 日美股收盘,美国知名影视公司奈飞(Netflix)市值 2720 亿美元(约合 17318.8 亿元人民币)。据悉,奈飞是利用 A/B 测试做出决策,以不断对产品做出改进。
做决策很容易,难的是做正确的决策
奈飞的创作理念是将消费者的选择和控制放在娱乐体验的中心,作为一家公司,我们不断改善我们的产品,以改进这一价值主张。
例如,奈飞的用户界面(UI)在过去十年中经历了一次彻底的变革。早在 2010 年,用户界面是静态的,只有有限的导航选项,以及一个受视频租赁商店展示启发的演示。现在,用户界面是沉浸式的,具有视频转发功能,导航选项也更丰富且不那么突兀,盒子展位(box art)展示更充分地利用了数字体验。
从 2010 年的体验过渡到今天,奈飞需要做出无数的决策。比如,单个剧集的大显示区域与显示更多剧集之间的平衡是什么?视频比静态图片更好吗?我们如何在受限的网络上提供无缝的视频转发体验?我们如何选择要显示的剧集?导航菜单应该放在哪里,它们应该包含些什么?这样的例子不胜枚举。
做决策很容易——难的是做正确的决策。我们如何才能确信我们的决策能为我们现有的会员提供更好的产品体验,并帮助新会员发展业务呢?奈飞可以通过多种方式来决策如何改进我们的产品,从而为我们的会员带来更多的乐趣:
让领导做所有的决策。
聘请一些设计、产品管理、用户体验、流媒体交付以及其他领域的专家,然后采用他们最好的想法。
进行内部辩论,让我们最有魅力的同事的观点占据上风。
模仿竞赛。

在上面介绍的每种范式中,有助于决策的观点和视角都是有限的。领导小组很小,小组辩论的规模也就这么大,而奈飞在我们需要做出决策的每个领域中也都只有这么几位专家。也许有几十种流媒体或相关服务可以作为我们的灵感来源。此外,这些范例并没有提供一种系统化的方法来做出决策或解决相互冲突的观点。
在奈飞,我们相信有一种更好的方式能来决策如何改善我们向会员提供的体验:我们使用 A/B 测试。实验让我们所有的会员都有机会投票,用他们的行动来决策如何继续发展他们愉悦的奈飞体验,而不是由高管或专家组成的小组来做决策。
更广泛地说,A/B 测试以及准实验(quasi-experimentation)等其他因果推理方法是奈飞使用科学方法为决策提供信息的方式。我们形成假设,收集经验数据,包括来自实验的数据,为我们的假设提供支持或反对的证据,然后得出结论并产生新的假设。
正如我的同事 Nirmal Govind所解释的那样,实验在支撑科学方法的推理(从一般原则中得出具体结论)和归纳(从具体的结果和观察中形成一般原则)的迭代循环过程中起着关键的作用。
A/B 测试
A/B 测试是一种简单的对照实验。比如说(这是一个假设!),我们想了解在电视用户界面中倒置所有盒子展位(boxart)的新产品体验是否对我们的会员有益。
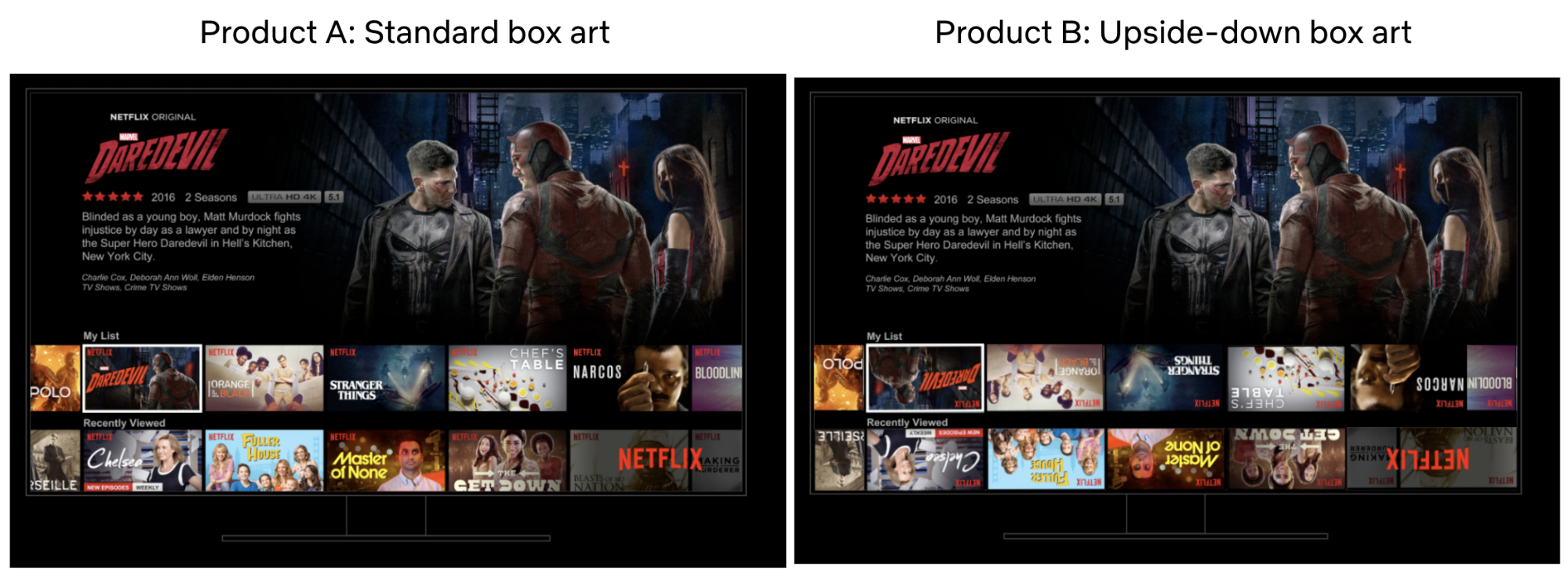
为了进行实验,我们从我们的会员中抽取一个子集,通常是一个简单的随机样本,然后使用随机分配将该样本平均分成两组。
“A”组通常被称为“对照组”(Control Group),继续接受基本的奈飞用户界面体验,而“B”组通常被称为“实验组”(Treatment Group),根据关于改善会员体验的特定假设(下文将详细介绍这些假设)来获得不同的体验。在这里,B 组接受倒置的盒子展位。
我们比较 A 组和 B 组的各种度量指标值,一些指标将特定于给定的假设。
对于用户界面(UI)实验,我们将研究新特性的不同变体的用户粘性。对于一个旨在在搜索体验中提供更多相关结果的实验来说,我们将衡量会员是否通过搜索找到了更多值得关注的内容。在其他类型的实验中,我们可能会关注更多的技术指标,比如应用程序的加载时间,或者我们在不同网络条件下能够提供的视频质量。
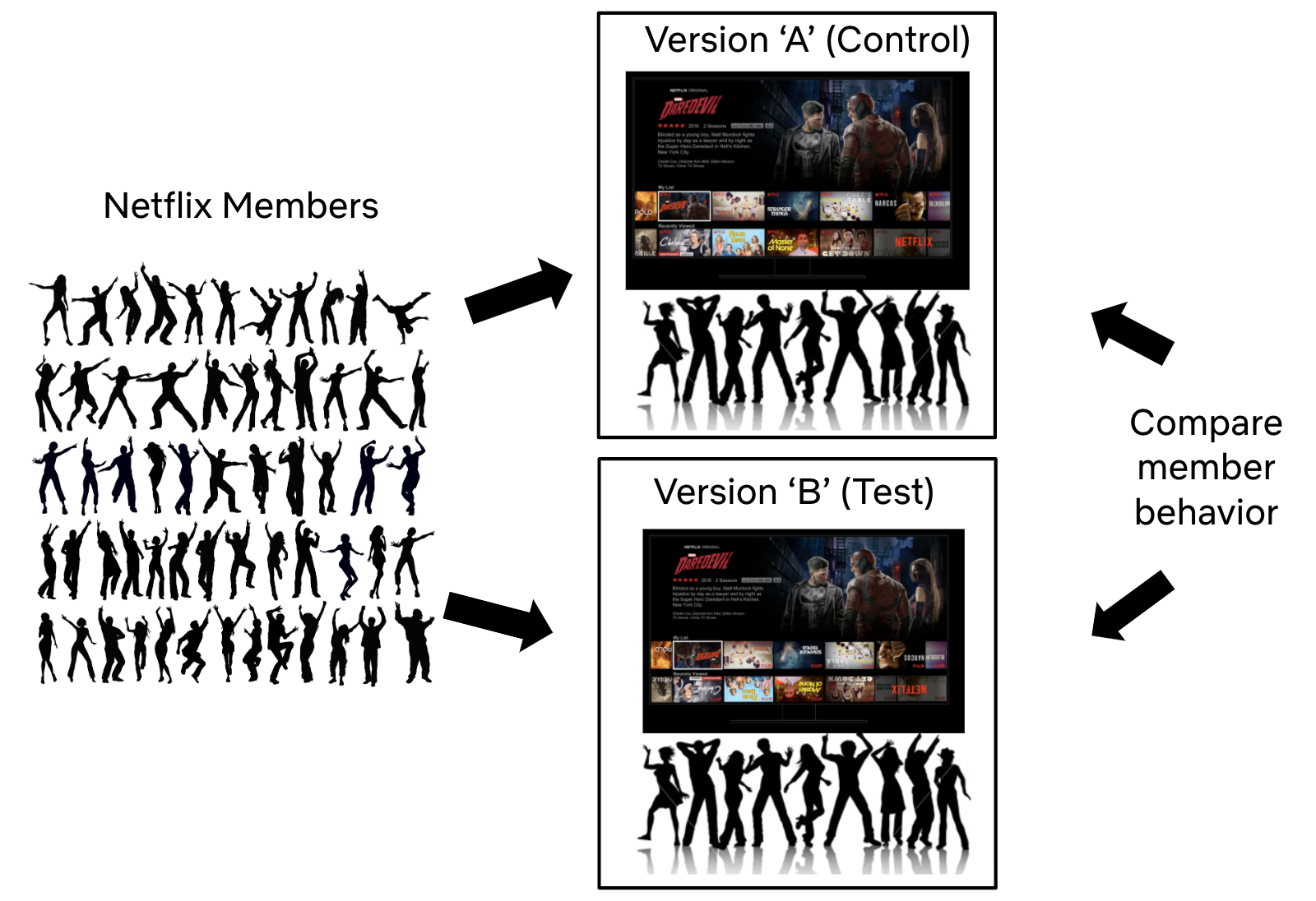
通过许多实验,包括倒置盒子展位的例子,我们需要仔细考虑我们的指标告诉了我们什么。
假设我们查看点击率,衡量每次体验中点击剧集的会员比例。这一指标本身可能是衡量这个新用户界面是否成功的一个误导性指标,因为会员可能只是为了更容易阅读而点击倒置产品体验中的剧集。在这种情况下,我们可能还需要评估有哪些会员随后会选择离开该剧集,而不是继续播放它。
此外,我们还将关注更多的通用指标,这些指标旨在捕捉奈飞为我们的会员带来的欢乐和满足感。
这些指标包括会员与奈飞互动的程度:我们正在测试的想法是否有助于会员在任何特定的夜晚都会选择奈飞作为他们娱乐的目的地?
这还涉及到了大量的统计数据——有多大的差异会被认为是显著的?在一次测试中,我们需要多少个会员才能检测到给定大小的影响?我们如何才能最有效地分析数据?本文会重点放在高层次的直观感受上。
保持其他因素不变
因为我们是使用随机分配来创建对照组(“A”)和实验组(“B”)的,所以我们可以确保这两个组中的个体,平均而言,在可能对测试有意义的所有维度上都是平衡的。
例如,随机分配可以确保奈飞会员的平均长度在对照组和实验组之间没有显著的差异,内容偏好、主要语言的选择等也没有显著的差异。两组之间唯一的差异是我们正在测试的新体验,确保我们对新体验影响的估计没有任何偏差。
为了理解这有多重要,让我们考虑另一种我们可以做决策的方式:我们可以把新的倒置盒子展位体验(如上所讨论的)推给所有的奈飞会员,看看我们的度量指标是否有很大的变化。如果有证据表明该改变是积极的或者是没有任何意义的,我们将保留新的体验;如果有证据表明该改变是负面的,我们将回滚到之前的产品体验。
假设我们这样做了(再说一遍——这是一个假设!),并在每个月的第 16 天将开关切换到上下倒置的体验。如果我们收集到了以下的数据,你会怎么做呢?
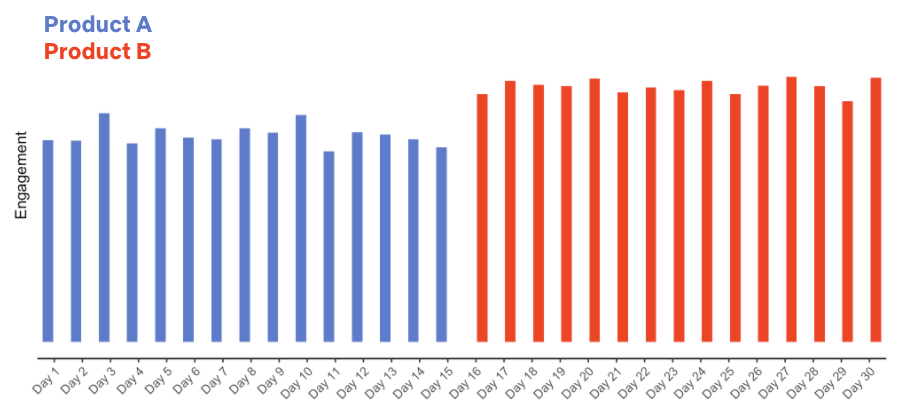
数据看起来不错:我们发布了新的产品体验,会员粘性大大提高了!但是,如果你有了这些数据,再加上知道产品 B 将用户界面中的所有盒子展位倒置了,那么你对新产品的体验真的对我们的会员有益有多大的信心呢?
我们真的知道新产品体验是导致用户粘性增加的原因吗?还有其他可能的解释吗?
如果你还知道奈飞在推出新的倒置产品体验的同一天还推出了一部热门剧集,比如《怪奇物语》(Stranger Things)或《布里奇顿》(Bridgerton)的新一季,或者一部热门电影,比如《活死人军团》(Army of the Dead),会怎么样呢?
现在对于用户粘性的增加,有不止一种可能的解释:可能是新的产品体验,可能是社交媒体上的热门剧集,也可能是两者兼而有之。或者完全是别的什么东西。关键的一点是,我们不知道新的产品体验是否导致了用户粘性的增加。
相反,如果我们使用倒置盒子展位的产品体验来进行 A/B 测试,让一组会员在整个月内都接受当前的产品(“A”),另一组会员接受倒置产品(“B”),并收集到了以下的数据,会怎么样呢?
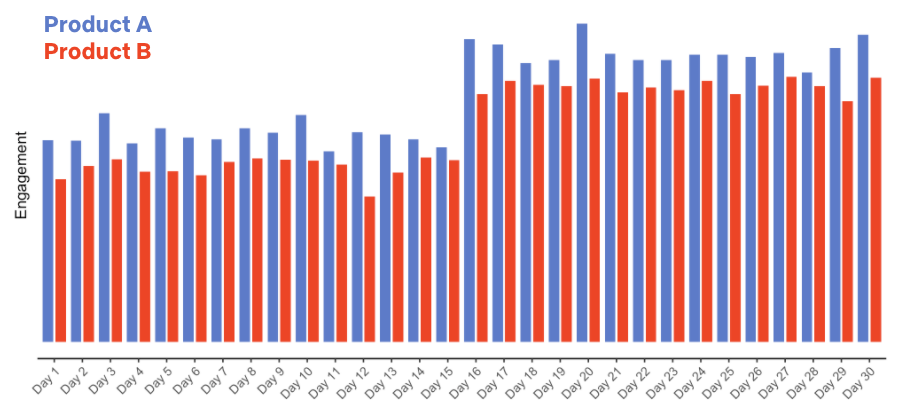
在这种情况下,我们得出了一个不同的结论:倒置的产品通常会导致较低的用户粘性(这并不奇怪!),并且随着大剧集的发布,两组的用户粘性都在增加。
A/B 测试让我们做出了原因陈述。我们只在 B 组中引入了倒置的产品体验,并且由于我们将会员随机分配到了 A 组和 B 组,所以这两组之间的其他一切都保持不变。因此,我们可以很可能地得出结论(更多细节将在下次讨论),即倒置的产品导致了用户粘性的下降。
这个假设例子是极端的,但它告诉我们,总有一些事情是我们无法控制的。
如果我们将一种体验推给所有人,并简单地在改变前后衡量单一指标,那么这两个时间段之间可能存在相关差异,从而阻止我们做出因果推论。也许它是一部很受欢迎的新剧集。也许它是一种新的产品合作关系,可以让更多会员享受到奈飞的乐趣。总有一些事情是我们不知道的。
在可能的情况下,进行 A/B 测试,能让我们证实因果关系,并在知道我们的会员已经通过他们的行动投票支持他们的情况下自信地对产品进行更改。
一切都始于一个想法
A/B 测试始于一个想法——我们可以对用户界面、帮助会员查找内容的个性化系统、新会员的注册流程或奈飞体验的任何其他部分进行一些更改,我们相信这些更改将为会员带来积极的结果。我们测试的一些想法是渐进式创新,比如改进出现在奈飞产品中的文本副本的方法;有些则更为雄心勃勃,比如奈飞现在在用户界面上展示的“前 10”(Top 10)剧集的测试。
与所有向奈飞全球会员推出的创新一样,“前 10”最初只是一个想法,后来变成了一个可验证的假设。在这里,核心思想是,在每个国家都受欢迎的剧集将在两个方面都有利于我们的会员。首先,通过呈现热门内容,我们可以帮助会员分享经验,并通过对热门剧集的讨论来相互联系。其次,我们可以通过满足人们参与共享对话的内在愿望,来帮助会员选择一些精彩的内容。

接下来,我们将这个想法转化为一个可检验的假设,即“如果我们做出改变 X,它将以某种方式改善会员体验,从而使指标 Y 得到改善。”
对于“前 10”的例子,假设是:“向会员展示前 10 的体验将帮助他们找到值得观看的内容,从而增加会员的愉悦和满意度。”这项测试(以及许多其他测试)的主要决策指标是衡量会员对奈飞的用户粘性:我们正在测试的想法是否有助于我们的会员在任何特定的夜晚都选择奈飞作为他们娱乐的目的地?
我们的研究表明,从长远来看,这一指标(细节省略)与会员保留订阅的概率相关。我们进行测试的其他业务领域,如注册页面体验或服务器端基础设施,使用了不同的主要决策指标,但原则是一样的:在测试期间,我们可以衡量哪些方面,才能长期为我们的会员提供更多的价值?
除了测试的主要决策度量指标外,我们还考虑了一些次要的度量指标,以及它们将如何受到我们正在测试的产品特性的影响。这里的目标是阐明因果链,从用户行为如何响应新产品体验的变化,到我们主要决策度量指标的变化。
阐明产品变化与主要决策度量指标变化之间的因果链,并沿着这条链监控次要度量指标,有助于我们建立信心,即主要度量指标的任何变化都是我们假设的因果链的结果,而不是新特性导致的意想不到的后果(或者误报)。
对于“前 10”的测试,用户粘性是我们的主要决策指标——但我们也会关注一些其他指标,如前 10 列表中出现的剧集的剧集浏览率,来自该行的浏览率与用户界面其他部分浏览率的比例关系,等等。
如果根据假设,“前 10”的体验真的对我们的会员有益,那么我们希望实验组能够显示出“前 10”剧集的浏览量是有所增加的,并且这一行的用户粘性普遍比较高。
最后,因为并不是所有我们测试的想法都能使我们会员成为赢家(有时新特性也有 bug!)我们还研究了充当“护栏”的指标。
我们的目标是限制任何负面影响,并确保新的产品体验不会对会员体验产生意想不到的影响。例如,我们可以比较对照组和实验组的客户服务联系率,以检查新特性是否增加了联系率,这可能表明会员会感到困惑或不满意。
总结
这篇文章的重点是建立直观认识:A/B 测试的基础知识,为什么运行 A/B 测试比推出特性更重要,为什么要查看更改前后的度量指标,以及我们如何将一个想法转化为可检验的假设。
参考链接:
https://netflixtechblog.com/decision-making-at-netflix-33065fa06481
https://netflixtechblog.com/what-is-an-a-b-test-b08cc1b57962




