
2020 年 11 月,我们开始了一次大规模的迁移,将 PostgreSQL 集群从 9.6 版本升级到 12.4 版本。在这篇文章中,我将概要地介绍下我们在 Coffee Meets Bagel 采用的架构,带你看一下我们在累计停机时间不到 30 分钟的情况下完成升级所采取的步骤,并分享一些经验教训。
本文最初发布于 Coffee Meets Bagel 工程博客,经原作者授权由 InfoQ 中文站翻译并分享。
架构
你可能不了解 Coffee Meets Bagel,我们是一个精心策划的约会应用。每天中午,约会者都会收到一定数量的高质量候选人。我们的负载模式具有非常好的可预见性。在撰写这篇文章的前一周,我们的平均交易数徘徊在每秒 3 万笔左右,而在更大的市场中,我们的最高交易数是每秒 6.5 万笔。
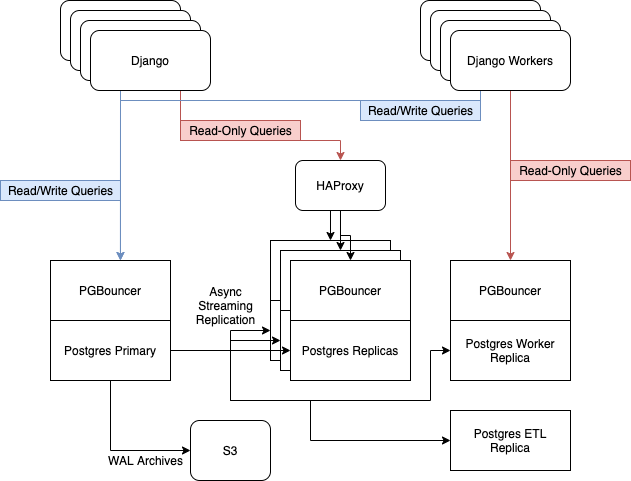
在升级之前,我们在 AWS i3.8xlarge 实例上运行了 6 个 Postgres 服务器。其中包扩一个主节点,三个服务于只读 Web 流量的副本(通过 HAProxy 实现负载均衡),一个专用于异步工作线程的服务器,还有一个用于 ETL 和 BI 的服务器。
我们使用 Postgres 内置的流复制来保证副本集群是最新的。
升级原因
在过去的几年里,在很大程度上,我们忽略了数据层,因此它们已经有点老迈了。特别是我们的主服务器已经积攒了很多问题——它在线已经有大约 3 年半的时间了,各种系统库和服务都打过补丁。

我提供给r/uptimeporn的数据
因此,它有许多让我们紧张的稀奇古怪的问题:新服务拒绝在 systemd 中运行(我们最后在一个 screen 会话中运行了一个 datadog 代理),有时当 CPU 使用率超过 50%,对 SSH 就完全无响应了(同时继续服务于查询)。
此外,我们的磁盘使用开始变得不稳定。正如我前面提到的,我们在 EC2 i3.8xlarge 实例上运行 Postgres,该实例带有 7.6TB 的 NVMe 存储。和 EBS 不同,它不能动态调整大小,所以有多大就是多大,而且磁盘的 75%已经填满。为了支持未来的增长,我们必须升级实例大小。
我们的需求
最小化停机时间——我们的目标是累计停机时间 4 小时,包括升级过程中的错误所导致的意外停机。
在新实例上构建一个新的数据库集群,以取代我们当前老化的服务器集群。
升级到 i3.16xlarge 实例,留下增长空间。
我们知道三种 Postgres 升级方法:典型的备份和还原过程、pg_upgrade 和逻辑复制。
我们很快就放弃了备份和还原方法,因为我们的数据集有 5.7TB,需要花费的时间太长了。pg_upgrade 虽然快,但它是就地升级,不满足条件 2 和 3。所以,我们下一步是进行逻辑复制。
过程
关于 pglogology 的安装和使用,已经有很多资料,所以我就不重复了,下面这些链接我认为非常有帮助:
https://www.depesz.com/2016/11/08/major-version-upgrading-with-minimal-downtime/
https://info.crunchydata.com/blog/upgrading-postgresql-from-9.4-to-10.3-with-pglogical
http://thedumbtechguy.blogspot.com/2017/04/demystifying-pglogical-tutorial.html
我们创建了一个 Postgres 12 服务器,它将成为我们新的主服务器,并使用 pglogical 来同步所有数据。一旦它复制完旧数据并开始复制传入的更改,我们就在它后面添加流副本。当我们每准备好一个新的流副本,就把它添加到 HAProxy 中,同时删除一个旧的 9.6 副本。我们就这样一直做,直到除了主服务器之外的所有 Postgres 9.6 服务器都已退出,此时,我们的状态如下:

在这种状态下,我们就会安排一个维护窗口来执行故障切换。同样,关于这个过程,网上有很好的文档,所以这里我只粗略地描述一下我们所做的事情:
将站点置于维护模式
将主数据库的 DNS 切换到新主机的 IP
强制同步所有主键序列
在旧的主数据库上手动运行 checkpoint
执行一些数据验证,测试下新的主数据库
将站点恢复到正常运行状态
总之,对于我们来说,这个过程很顺利。虽然这是一次规模比较大的基础设施迁移,但我们没有遇到任何意外的停机或者错误。
经验教训
虽然这个项目取得了很大的成功,但我们也遇到了一些问题。最可怕的是差点搞挂我们的 Postgres 9.6 Primary…
教训 #1:同步缓慢会很危险
首先是一些关于 pglogical 的背景信息:pglogical 的工作方式是,提供方数据库(在本例中是我们的旧 9.6 Primary)上的发送方进程将解码预写日志,提取逻辑更改,并将它们发送到订阅方数据库。
如果订阅方速度慢了,那么提供方的 WAL 段就会开始累积,这样,当订阅方赶上时就不会丢失任何数据。
当你向副本流添加表时,pglogical 首先需要同步表数据。这是使用 Postgres 的 COPY 命令完成的。然后,在提供方数据库上 WAL 段将开始累积,这样,在 COPY 开始后提交的更改可以在初始同步完成后传输到订阅方,确保数据不会丢失。
也就是说,在实践中,如果你正在一个写入/更新频繁的系统中同步一个较大的表,那么你需要密切关注磁盘使用情况。我们第一次尝试同步最大的表(4TB)时,初始 COPY 语句运行了一天多,在此期间,我们在提供方节点上累积了大约 1TB 的 WAL。
你可能还记得,我们在前面提到过,我们的旧数据库服务器只剩下大约 2TB 的空闲磁盘空间。从用户数据库的磁盘使用情况来看,只有约四分之一的表复制了,我们认定,我们将无法在磁盘空间耗尽之前完成,因此我们迅速取消了同步过程。
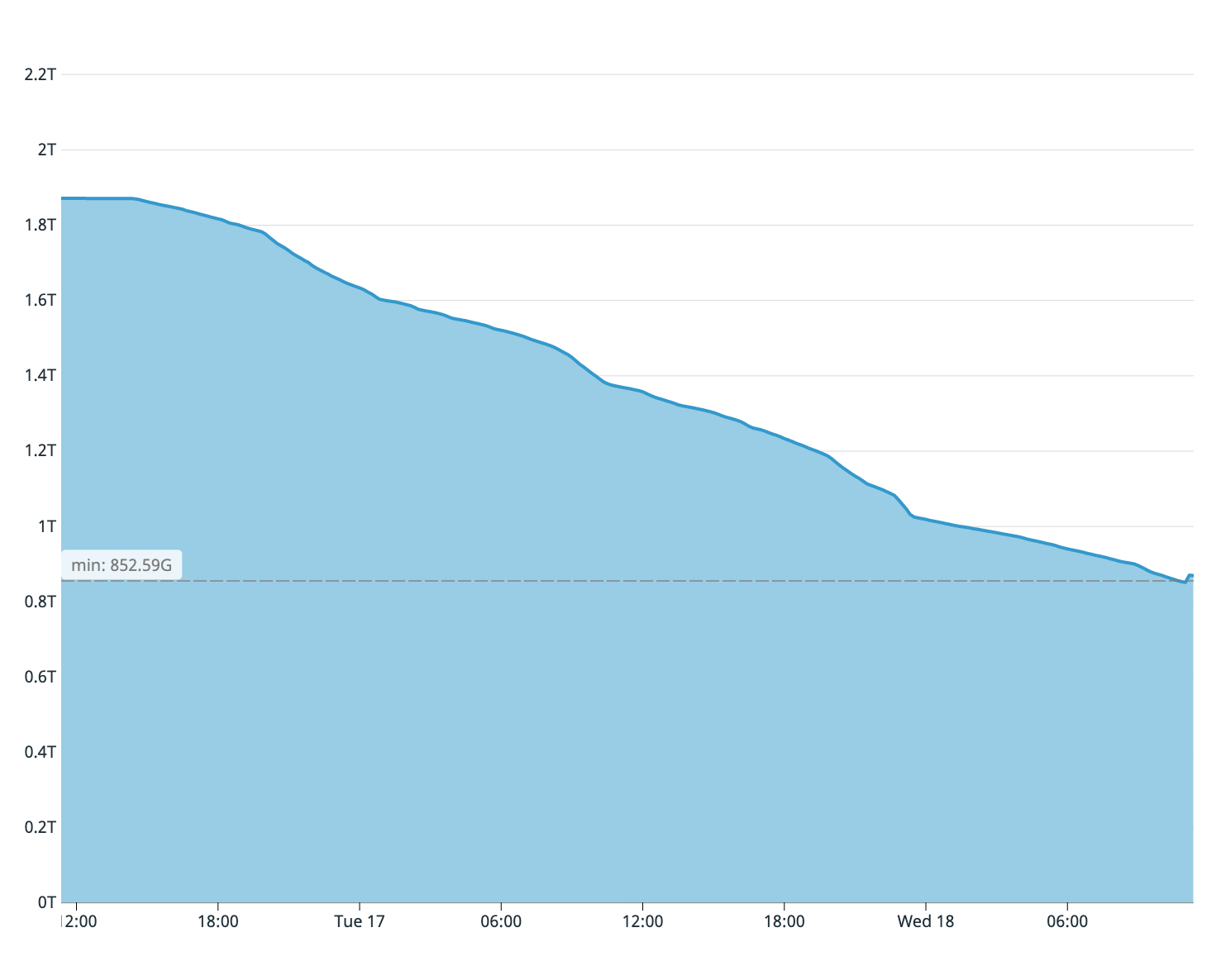
在初始同步期间,旧主数据库上的可用磁盘空间
然后,我们对订阅方数据库做了以下更改,以加快同步:
删除需要同步的表上的所有索引
关闭 fsync
将 max_wal_size 设为 50GB
将 checkpoint_timeout 设为 1h
这四个更改显著提高了订阅方数据库摄取数据的速度,我们在第二次尝试时用不到 8 小时就完成了表的同步。
教训 #2: 每个更新都被记录为冲突
当 pglologic 断定发生了冲突时,它会发出一条日志消息,比如“CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote”。
然而,我们观察到,订阅方处理的每个更新都会被记录为冲突。仅经过几个小时的复制,订阅方数据库就已经写入了 1GB 的冲突日志。
我们在 postgresql.conf 文件中加入 pglogical.conflict_log_level = DEBUG 将其关闭。
参与 Hacker News 讨论,请点击这里。
查看英文原文:Our Journey to PostgreSQL 12




