
作者 | 字节跳动基础架构团队
前言
VLDB 会议,全称 International Conference on Very Large Data Bases,是全球数据库系统领域最负盛名的三大顶会之一。从 1975 年开始举办,每年一次,全球各地顶尖高校的大量研究者、各大高科技公司都会将自己的学术研究进展或工业界成果以论文形式投递到 VLDB 组委会,而组委会会审阅并接收其中最前沿、最具影响力的一批,并召开线下会议,供论文作者们分享、交流。
今年的 VLDB 在 9 月 5 号到 9 号,在澳大利亚悉尼举办。字节跳动有三篇论文被 VLDB 接收:其中两篇来自 Graph 团队 ,一篇 ByteHTAP 系统。应 VLDB 组委会邀请,字节相关团队来到悉尼,与世界各地的数据领域专家学者分享交流。
为了让大家能对 VLDB 2022 有个快速的了解,我们总结了 VLDB 的论文分类、研究趋势以及工业界重点论文的摘要,当然啦,也包括字节跳动三篇论文简介。本文抛砖引玉,如果想深入了解学习,还是非常建议找到论文原文仔细研究。
论文分类概览
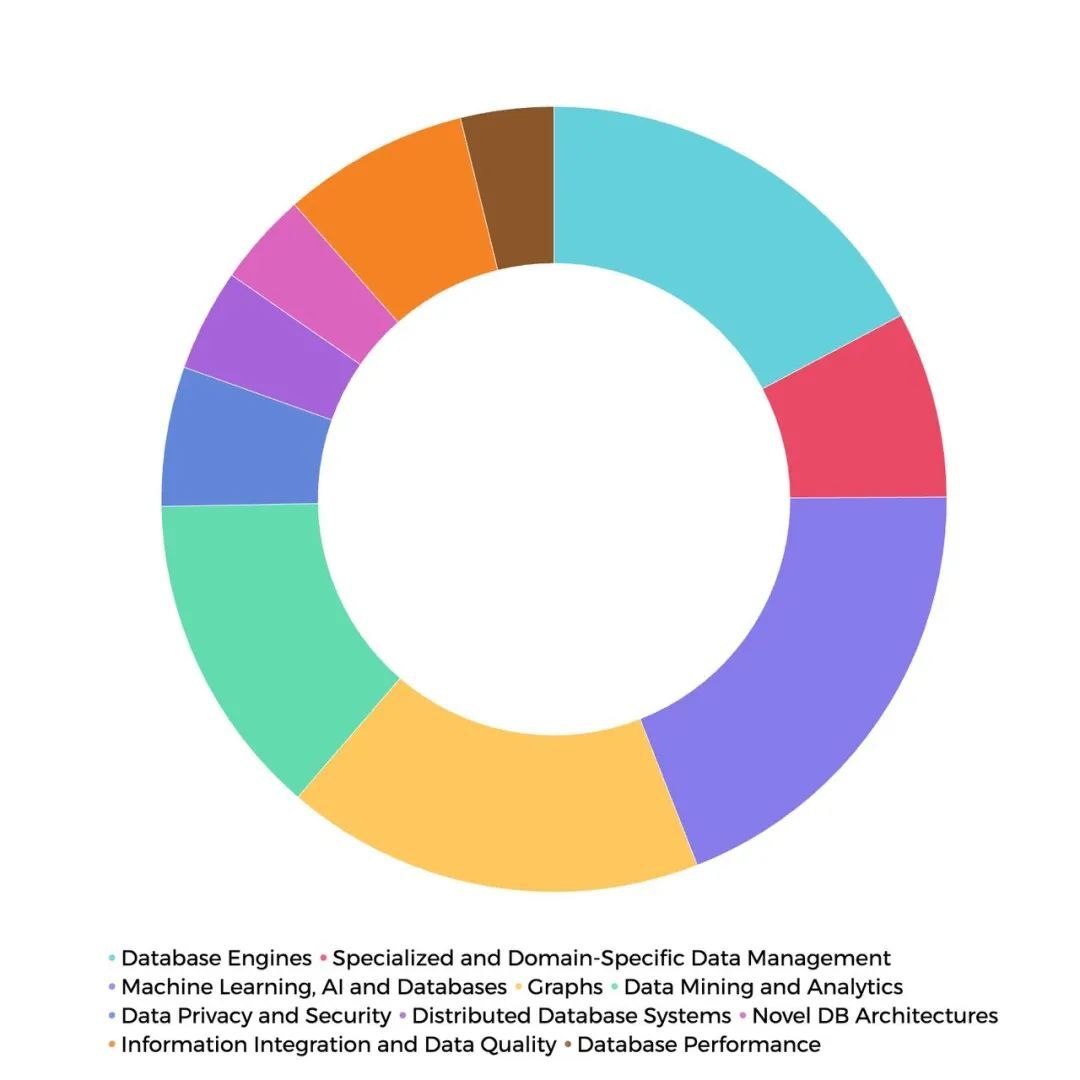
今年的 VLDB 会议日程中,将所有参会讨论的论文共划分成了以下几类:
Database Engines(45 篇)
Database Performance(10 篇)
Distributed Database Systems(11 篇)
Novel DB Architectures(10 篇)
Specialized and Domain-Specific Data Management(20 篇)
Machine Learning, AI and Databases(50 篇)
Data Mining and Analytics(35 篇)
Information Integration and Data Quality(20 篇)
Data Privacy and Security(15 篇)
Graphs(45 篇)
作为老牌系统会议,VLDB 既有传统的数据库管理系统的最新进展 80 篇左右,也有一些这些年来前沿的机器学习和系统结合领域的最新内容。此外,Graph 领域的论文依然收录了 45 篇之多,VLDB 延续这几年对 Graph 的重点关注。可以看出,VLDB 所收录的论文内容,从传统的数据库底层技术、性能分析,到机器学习、图、区块链这些新兴的数据库使用场景,再到最上层的数据隐私安全、数据分析,基本覆盖了数据的完整处理链路。
我们将不同领域的论文数量绘制成了饼状图,方便读者对不同领域的热度有大致了解:
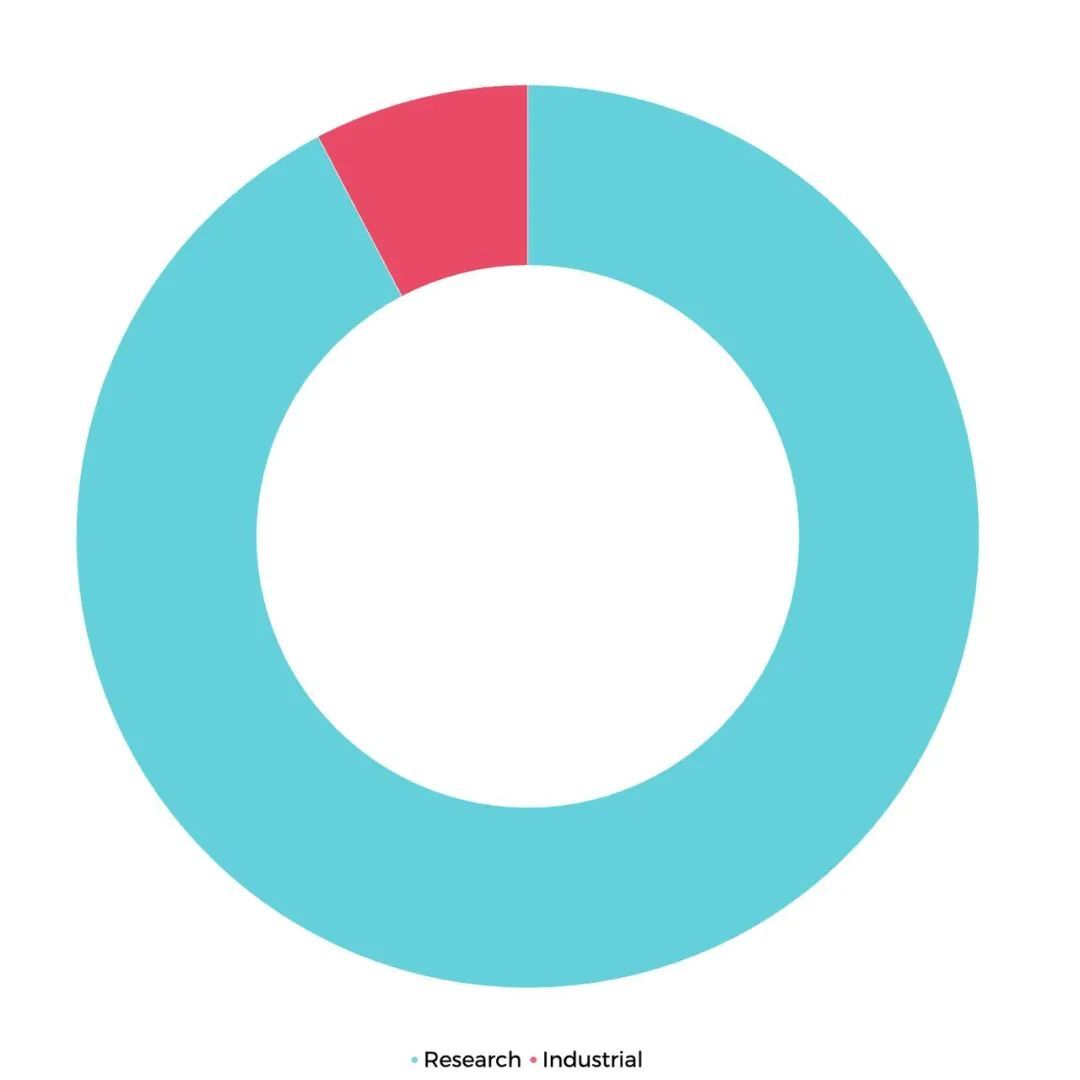
VLDB 历来重视学术界与工业界的融合和交流。因此,VLDB 专门将工业界论文和学术界论文进行了分类,分别是 research track paper 和 industrial track paper。工业界论文 industrial track 共有 22 篇,其中校企合作的论文 12 篇,企业独立发表的论文有 10 篇;这些论文中,包含了 Google、Meta、微软、字节跳动、阿里、腾讯等多家国内外知名互联网企业的成果。相比于 research track,industrial track 更偏向于已经落地实用的技术或者系统,这些成果中有相当一部分与大家在日常生活中所用到的应用息息相关,也是各大技术公司相关领域人员关注的重点。
2022 的趋势和启迪
从论文的分布领域,以及工业界论文的重点,我们能够分析和洞察出数据库业界的一些趋势,一家之言,欢迎大家交流讨论。
机器学习与数据库的结合在不断加深
机器学习是目前计算机学界最为热门的话题,这种热度自然也传导到了数据库领域。今年 VLDB 最为火爆的话题就是 Machine Learning, AI and Databases,收录了足足 50 篇论文,且 Best Regular Research Paper、Best Scalable Data Science Paper 均花落这个领域,在悉尼的现场中,听众人数最多的也是这个方向,挤满了整个屋子。
具体来说,机器学习与数据库的结合点又主要包含三个部分:机器学习框架和平台与数据库的深度融合、使用机器学习技术优化数据库性能以及自动化运维。其中,使用机器学习来优化数据库系统进而整个 infrastructure 系统是一个在工业界已经徐徐展开的方向,有显著的线上需求和收益,字节在这一方面也有团队在持续研究探索。
新硬件,软硬一体
在传统的 CPU、内存硬件的处理性能无法保持高速提升的大背景下,各大公司和学术界不约而同地将目光投向新硬件领域,包括 FPGA、GPU、PMem 等。如果充分利用 FPGA、GPU 进行计算加速,以及如何充分发挥 PMem 相比于内存的优势,是未知领域探索的低垂果实,自然成了近年研究的热点。本届 VLDB,有多篇工业界论文专题研究 FPGA 和 PMem,并且 SAP HANA 的 FPGA 加速论文荣获了此次工业界 best paper 的桂冠;学术界也有至少五篇论文讨论 GPU、PMem 的相关话题,热度可见一斑。
NoSQL 领域持续发展
过去十几年,随着互联网业务快速增长,丰富的业务场景和数据规模的爆炸增长,催生了 NoSQL 领域的蓬勃发展。对于涌现的各种 NoSQL 产品种类,都持续有新的技术思路体现在每年的 VLDB 中。在 2022 年的 VLDB,NoSQL 领域有工业界贡献的时空数据库、向量数据库和图数据库,也有关于 LSM 引擎的架构优化论文,继续保持了 NoSQL 欣欣向荣百花齐放的态势。
Graph 保持高热度
在数据爆炸时代,数据关联性的价值逐渐突显,学术界 Graph 早已火热多年。今年 VLDB 一共有 9 个 Graph Sessions,占到了整体比例的 20%,在论文数量上 Graphs 有 45 篇, 仅次于 Machine Learning, AI and Databases,与传统的 Database Engines 打平。在这 9 个 Graph Sessions 中,被接收的论文方向覆盖了:时序图(系统与算法),动态图(系统与算法),概率图(算法),图查询优化,Graph AI(系统与应用),子图匹配(算法优化与应用),图数据库系统,图计算系统等方向。不难看出,对图算法的研究远多于图系统,且图算法相关论文几乎都是各大学的独立研究成果。作为学术论文,创新性是最重要的,从算法角度探索新方法新问题,会比系统角度取得创新性周期更短依赖条件更少,因此高校偏爱算法也就不难理解了。其实,从小编来看,场景、算法、系统是三个密切联动的环节,需要互相促进来实现螺旋上升。因此,图领域需要加强工业界和学术界的进一步交流合作。
字节跳动论文介绍
字节今年共有三篇论文被收录,其中两篇关于图数据库 ByteGraph 以及 ByteGNN,一篇介绍了 ByteHTAP 系统,相信读者从名字就能看出论文介绍的系统类型。这些系统都广泛应用于字节业务丰富的业务场景,在实践中沉淀打磨推陈出新,相比有更强的实际参考意义,在悉尼现场,也吸引了大量研究人员关注和交流。
我们在此,对这三篇论文做简要介绍,也非常欢迎大家找来原文阅读。
ByteGraph: A High Performance Distributed Graph Database in ByteDance
论文链接:https://www.vldb.org/pvldb/vol15/p3306-li.pdf

本文介绍了在字节跳动内部广泛使用的图数据库系统 ByteGraph。在字节跳动内部,用户、视频、评论 / 点赞、商品等等多种类型元素及其之间联系可以用 Graph 模型来完美表达;这些图状数据上,有出度几亿的超级节点的存储查询挑战,也有 TP、AP 甚至大量 Serving 流量的混合挑战,ByteGraph 在多年支持这些场景中不断演进和迭代,本篇论文就详细介绍了 ByteGraph 的整体架构和设计,以及多年沉淀的一些场景问题及其方法探索。
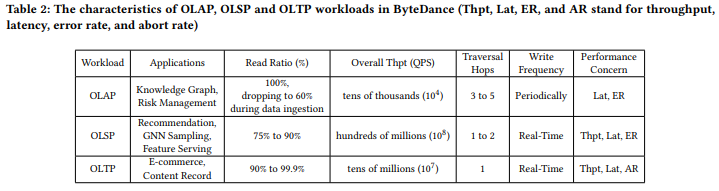
表 - 字节内部 Graph OLTP/OLAP/OLSP workloads 特点总结
ByteGraph 采用了计算存储分离的架构,支持 gremlin 分布式查询,可分层水平扩展到几百个节点规模。面向字节内部广泛存在的超级顶点问题、查询 workload 多样且经常变化的问题,采用了 EdgeTree 存储结构、自适应 Graph 索引等针对性设计,并对工程实践做了大量优化以提高并发性能。目前 ByteGraph 在内部已有数百个集群、上万台机器的部署规模,是全球最大部署规模的图数据库之一。
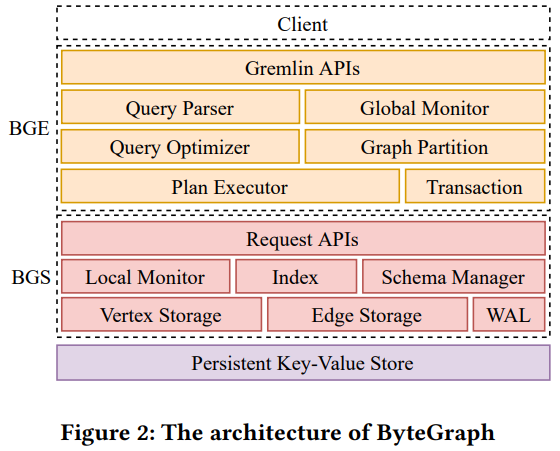
图 -ByteGraph 系统架构图
在查询层,ByteGraph 自研了 Gremlin 的查询引擎,支持了常见的 Gremlin step 并针对字节业务做了不少扩展。在海量的数据与并发的打磨下,做了基于 RBO/CBO 策略的查询优化以及列式数据格式等执行优化。但坦率讲,相比关系型数据库经过几十年里无数工程师和研究人员的努力建设,图数据库理论和实践都还有很多的路要走,也希望在未来能有机会 ByteGraph 能够继续通过顶会论文的方式作出自己的贡献,和大家交流学习。
图数据库的内存组织结构非常关键,不仅需要表达 Graph 的数据模型还需要支持高吞吐低延迟的访问性能。如图 4 所示,ByteGraph 分别使用 Vertex Storage 和 Edge Storage 在内存中缓存顶点和边。每个顶点及其属性都存储为 KV 对,其中键由唯一的 ID 和顶点类型编码,值是顶点的属性列表。为了有效地执行图遍历查询,边被组织为邻接表。为了减少在图遍历中访问超顶点后产生大量中间结果的可能性,邻接表根据边类型和方向进一步划分。为了处理超顶点和频繁更新,减少边的插入带来的写入放大以及在整个列表扫描期间产生更少的磁盘 I/O。每个邻接表都存储为一个树结构,称为 edge-tree。edge-tree 由三种类型的节点组成,即 Root node、meta node 和 edge node,每一种节点都存储为 KV 对。
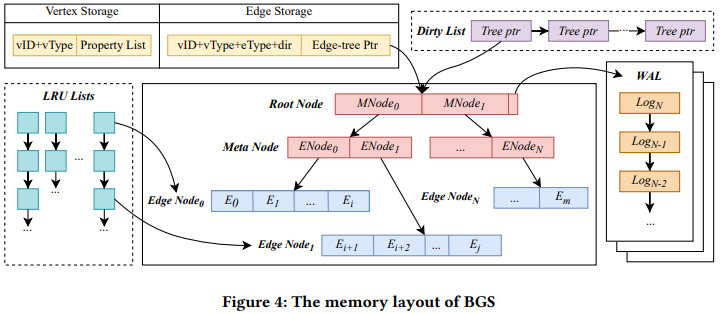
关于 ByteGraph 更多细节,欢迎大家查阅论文或者联系 ByteGraph 团队同学交流讨论。
ByteGNN : Efficient Graph Neural Network Training at Large Scale
论文链接:https://www.vldb.org/pvldb/vol15/p1228-zheng.pdf
Graph AI 方向是近几年大热的一个系统方向,比如上届 OSDI 会议连续有 4 篇 GNN 相关的论文被发表,SOSP/EuroSys/ATC/MLSys 每年也有很多有关于如何高效设计 GNN 训练 / 推理系统的文章被接收。今年 VLDB 上有关于 GNN 系统设计,优化以及应用的文章也不少。
图神经网络(GNN)作为新兴的机器学习方法,广泛应用于字节的推荐、搜索、广告、风控等业务场景中。面对字节海量的数据,采用分布式 GNN 系统提升训练的可扩展性和训练效率变得至关重要。然而,现有的分布式 GNN 训练系统存在各种性能问题,包括网络通信成本高、CPU 利用率低和端到端性能差。ByteGNN 通过三个关键设计解决了现有分布式 GNN 系统的局限性:
(1)将 mini-batch based 图采样的逻辑抽象成计算图以支持并发处理
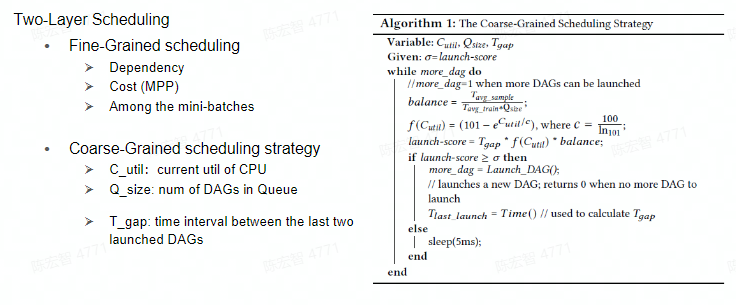
(2)粗粒度和细粒度的调度策略以提高资源利用率并减少端到端 GNN 训练时间
(3)为 GNN workloads 量身定制的图分区算法。实验表明,ByteGNN 的性能优于最先进的分布式 GNN 系统(i.e., DistDGL, Euler, GraphLearn), 端到端执行速度提高了 3.5-23.8 倍,CPU 利用率提高了 2-6 倍,网络通信成本降低了大约一半。

ByteGNN 为了显著降低网络开销,首先从系统架构层面将采样与训练这两个阶段作了解耦,让不同执行器分别负责一次 mini-batch 中的采样与训练:
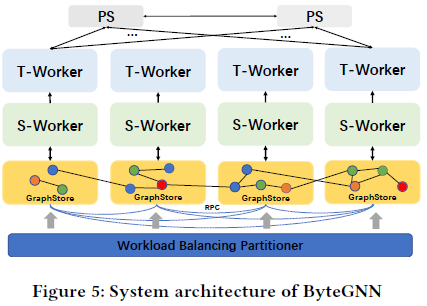
同时,ByteGNN 提供了一套自定义的采样编程接口,不同 GNN 模型将统一用该接口来实现不同的采样逻辑。系统后端基于该接口自动地将采样逻辑解析成为一个计算图 DAG。采样计算图化的好处是可以充分利用 CPU 利用率,动态地将分布式采样过程抽象成更细粒度的小 task 并将其流水线化。
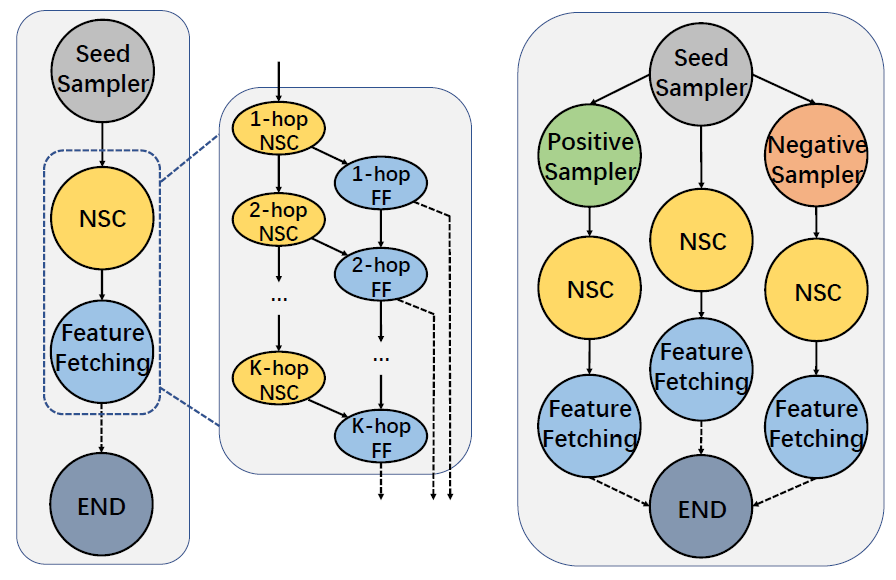
ByteGNN 也做了一层中间调度层,将采样计算图和训练计算图“软连接”到了一起,通过一个调度器动态地平衡采样与训练这两个阶段的资源消耗和消费速率,目标使得系统的 CPU 利用率和内存开销达到最优:
ByteHTAP: ByteDance’s HTAP System with High Data Freshness and Strong Data Consistency
论文链接:https://www.vldb.org/pvldb/vol15/p3411-chen.pdf
近年来,在公司业务中,我们看到越来越多的场景需要对新导入的数据进行复杂的分析,并同时强调事务支持和数据强一致性。因此在论文中,我们重点描述了字节跳动的自研 HTAP 系统 ByteHTAP 的构建过程。ByteHTAP 是具有高数据新鲜度和强数据一致性的 HTAP 系统,采用分离引擎和共享存储架构。
其模块化系统设计充分利用了字节跳动现有的 OLTP 系统和开源 OLAP 系统。通过这种方式,我们节省了大量资源和开发时间,并允许将来轻松地扩展,例如用其他替代方案替换计算引擎。
ByteHTAP 可以提供高数据新鲜度(数据从 OLTP 写入到 OLAP 查询可见,相隔不到 1 秒),这为我们的客户带来了许多新的能力。客户还可以根据业务需求配置不同的数据新鲜度阈值。
ByteHTAP 还通过其 OLTP 和 OLAP 系统的全局时间戳提供强大的数据一致性,减轻业务开发人员自行处理复杂的数据一致性问题的负担。
此外,文中还描述了我们对 ByteHTAP 引入的一些重要的性能优化,例如将计算推送到存储层,以及使用删除位图(Delete Bitmap)来高效处理删除。
最后,依惯例我们在文中分享了生产环境中开发和运行 ByteHTAP 的经验教训和最佳实践。
ByteHTAP 的高层架构如下图所示,在共享存储系统上搭建了两个彼此分离的计算引擎。ByteHTAP 使用了字节的自研 OLTP 数据库 ByteNDB 作为 OLTP 负载的计算和存储引擎,并使用 Apache Flink 作为 OLAP 负载的计算引擎。ByteHTAP 支持一个统一的,兼容 ANSI SQL 标准的用户入口并拥有一个智能代理层,DML,DDL 和 OLTP 负载的典型查询(如点查)会被发送给 OLTP 计算引擎,而复杂查询(如多重联接,大量聚合)会被发送给 OLAP 的计算引擎。这样的组织架构将 OLTP 和 OLAP 负载发给更合适的处理引擎,并能够有效防止这两类负载之间的串扰。
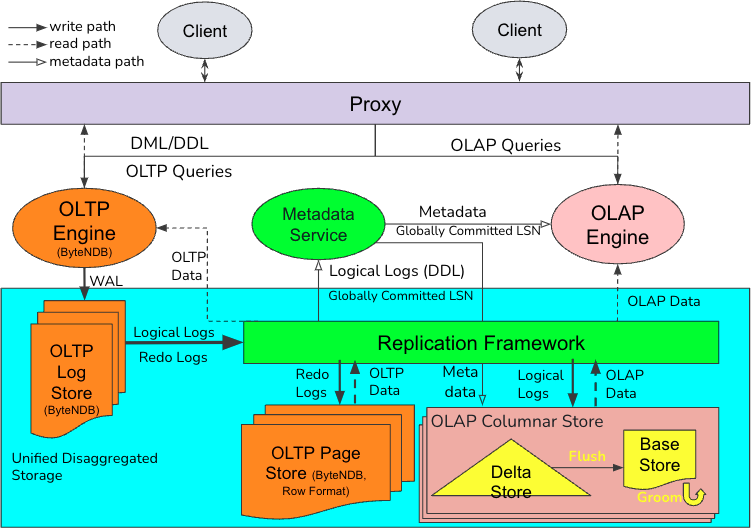
图 -ByteHTAP 系统架构图
作为 ByteHTAP OLTP 侧的计算和存储引擎,ByteNDB 遵循“log is database”的理念。用户数据的插入,更新和删除的日志在其 LogStore 存储组件持久化之后即完成提交,并通过一个分布式数据复制框架可靠地按数据分区分发至各存储节点(PageStore)回放为行存数据页面。ByteHTAP 扩展了 ByteNDB 的复制框架,已提交 的 DML 事务的逻辑日志(即 MySQL 二进制日志)根据用户表中定义的分区方案被连续分发到列存储节点,以构建列存格式的数据存储,该存储可能存储在与其对应的行存不同的存储节点上。ByteHTAP 的列存存储由内存中的 Delta Store 和持久化的 Base Store 组成。OLAP 查询使用指定的 LSN 作为其快照版本来扫描基量存储和增量存储。集中式元数据服务 Metadata Service 负责为 OLAP 的查询优化器和存储节点提供元数据信息,会消费 DDL 信息并构建多版本元数据,持久化并将元数据缓存在内存中供查询。
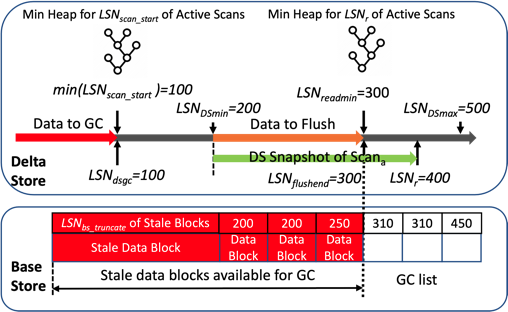
图 -ByteHTAP 列存前后台数据操作及其一致性协调示意图
上述的共享存储设计保证了从 OLTP 存储侧分发的逻辑日志可以马上进入 OLAP 的内存存储 Delta Store,从而马上对 OLAP 的用户查询可见,从而保证了 ByteHTAP 的高数据新鲜度。而 ByteHTAP 通过为其查询提供一致的数据快照来保证强数据一致性。每个 DML 和 DDL 语句都会在系统中生成一个全局唯一的 LSN(日志序号)。同一事务中的语句会被包装在一起并以原子方式分发到目标节点。元数据服务 Metadata Service 负责将最新的“全局提交 LSN” 发送给 OLAP 计算引擎,我们的设计保证了 LSN 小于此“全局提交 LSN” 的所有日志都已经被 OLAP 列存接收并持久化。OLAP 查询引擎中的 Metadata Service 客户端会定期从 Metadata Service 获取最新的全局提交 LSN 并缓存。OLAP 查询引擎将根据缓存了的全局提交的 LSN 为每个用户查询分配一个 read LSN,此 read LSN 会被下发到各 OLAP 列存存储节点,并用以确定数据可见性。在 OLAP 存储内部存在着大量的并发前后台数据操作,他们之间的数据一致性也由这一套 LSN 系统来进行保证。在大多数情况下,ByteHTAP 数据更改之后不到一秒即可提供给 OLAP 侧的用户查询。
实验和线上数据均表明,ByteHTAP AP 侧的性能达到业界优秀水平,并在 TP 侧数据吞吐量显著增加(客户连接数 0-64,数据吞吐量 2k-60k tpmC)时保持查询性能稳定(劣化小于 5%)。同样的,ByteHTAP 在数据吞吐量较大的情况下(182MB/s) 依然保持着远小于 1s (606ms)的数据新鲜度。
部分工业界论文介绍
工业论文主要来自头部企业,这些企业拥有超大规模的数据和系统,也聚集了高水平的系统开发人员,在多年的场景积累下,能够持续探索新的方法解决有挑战的问题,也自然是 VLDB 青睐的对象。
Hardware Acceleration of Compression and Encryption in SAP HANA(Best Industrial paper)
使用 FPGA 等专有硬件进行加速是一个热门的研究课题,多家公司都尝试过类似的 approach 来加速各系统中的瓶颈环节。FPGA 的专项性能要强于 CPU,且减少了 CPU 与 I/O 链路中的损耗,能够为系统提供不错的性能优势。来自 ETH Zurich 和 SAP 的这篇论文,就来自这个领域。主要介绍了使用 FPGA 加速 SAP HANA 的压缩与加密流程,有效提高了系统吞吐,并在实验中,具体展示了分析型数据库引擎的应用场景和各个重要性能参数中的 trade-off。本文介绍了 FPGA 在 HANA 这样一个工业级内存数据库的落地情况,并对相关性能场景进行了进行了较为详细的测试,数据翔实,best paper 当之无愧。
文中主要 offload 的部分是压缩与解压缩,加密与解密,整体的 pipeline 结构如下
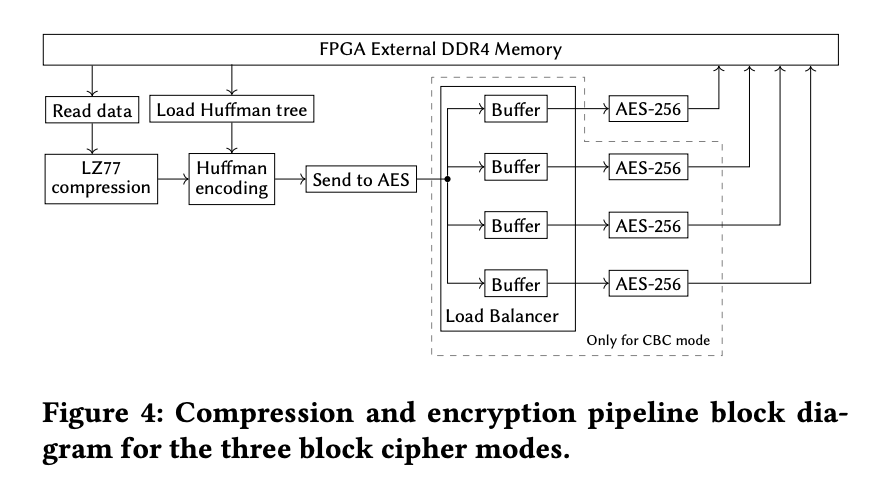
具体的实现方法是,将 OpenCL 作为一个库整合到系统内核中以函数调用的方法提供支持,压缩部分已经已经整合到了 OpenCL 中,而加密部分则使用 VHDL 实现,即图中的 AES-256 算法。
通过测试,我们发现 FPGA 的加入带来了几大优势:压缩与加密流程被显著加速;CPU 计算资源部分释放;数据传输更加安全;加密过程由数据库引擎控制,而不是云服务提供商;存储空间和网络流量有所减少。详细测试数据可以参见论文。
Tair-PMem: a Fully Durable Non-Volatile Memory Database
本文出自阿里巴巴,主要介绍了基于傲腾的 Tair-PMem 内存数据库设计。Tair-PMem 解决了传统内存数据库不能胜任完全持久化的问题,并通过巧妙的设计缓解了 NVM 的性能开销,减少了 NVM 编程的复杂性,获得了极低的尾部延迟以及更低成本的优势。同时也满足了内存数据库对大数据存储等需求的负载。
傲腾的核心特性主要体现在与传统 DDR 内存相比,容量更大,且数据断电后不丢失,但整体的时延表现与内存相比是其数倍。又由于这些不同于传统内存的特性,其编程难度也有所提升。
对于此文,我们可以着重看一下他的架构设计:
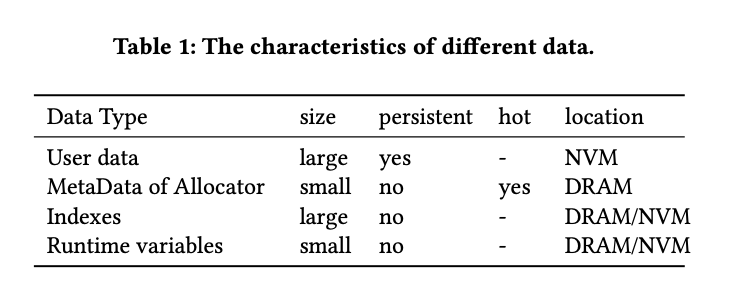
为了让傲腾提供与 DRAM 近似的性能,Tair-Pmem 设计了一个高可控的数据放置逻辑,其会根据数据的持久性,访问频次和大小来决定数据和其对应的元数据的存放位置。
在设计上使用了统一的 API 来解决 Pmem 的编程困难问题。
整体的模块化改造保持了代码的低侵入性,提高了系统整体的稳定性。
使用 Pmem 的 byte addressable 特性增强了数据库的基本能力。例如通过 Pmem 的持久化特性,Tair-Pmem 系统的 recovery 速度远超传统实现。
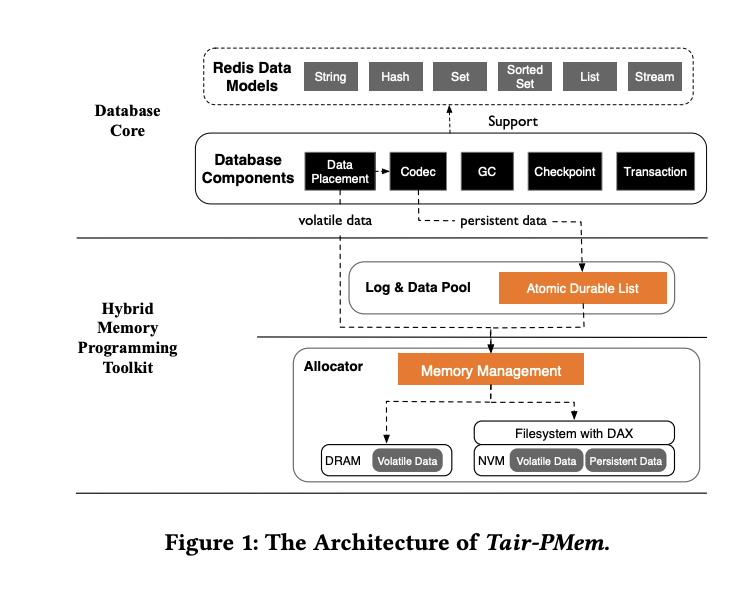
在整个 Toolkit 中,最重要的两个核心组件是 Allocator 和 Log & data pool:Allocator 的整体设计与传统的 jemalloc 类似,都使用了 slab 来管理内存,这里比较特别的是尽量将元数据存放在 DRAM 中。在真实分配内存的过程中,Allocator 会根据申请的内存类别和预定义的 DRAM-NVM 使用比例来分配。而对于 Log & data pool,其选择了链表的变种 ES-linked list 来管理,并在其上构建了一些基础数据结构的支持。
从实验的结果来看 Tair-Pmem 系统的整体吞吐和长尾时延表现都很优秀,且从成本角度考虑其提供的性能也十分惊艳。
CloudJump: Optimizing Cloud Database For Cloud Storage
近十年来,数据库领域的一个重要的架构发展趋势就是存储计算分离。在存算分离的系统中,数据通常会放置在某种云存储中,而非传统的本地存储。阿里云的存算分离数据库 PolarDB 已经进行了多年的发展与探索,实践中积累了大量思考与经验,本文就介绍了在设计一个适用于存算分离数据库的云存储时,需要考虑的设计原则,值得一读。
首先,文中梳理了云存储相比本地 SSD 的性能指标差异,以及这些差异对不同种类的存储引擎(B-Tree,LSM Tree)所产生的技术挑战和影响。
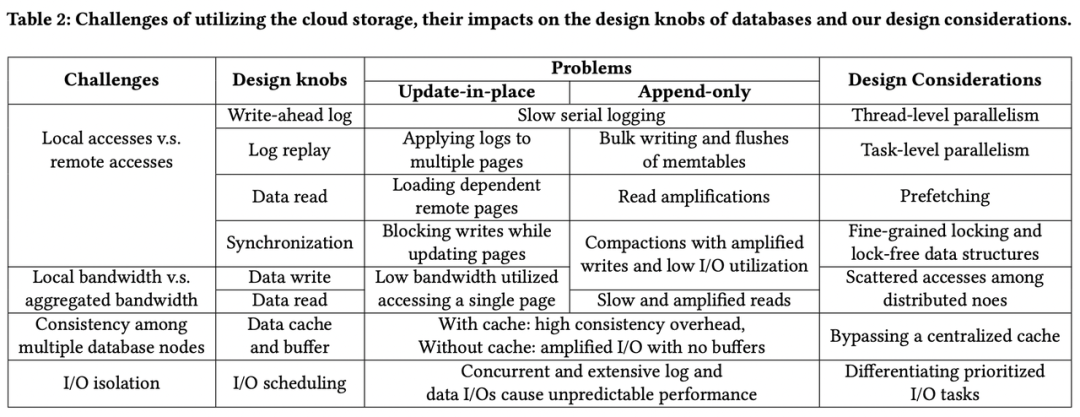
基于这些问题,文中提出了一些解决的思路和设计原则。例如,云存储场景应当尽量利用多机优势,将数据、大 IO 请求和 recover 带宽打散到不同节点上;通过预读、数据聚合、压缩、过滤等方式,尽量减少单次请求路径上的 IO 次数;需要考虑请求之间的资源隔离性,等等。
最后,论文结合 PolarDB 和 rocksdb 在云上的实现,举例说明了上述设计原则如何付诸具体实践,由于篇幅限制,这里只简单介绍 polardb 的相关内容。针对 redo log,polardb 将 redo log 按修改的 page 进行了分片,使得 redo log 被打散,能够获得写入性能优势;对于单个 redo log 分片,还会进一步拆分为多个物理 chunk,使得单个大的 log IO 任务可以被拆分开来,并发执行。得益于 redo log 的打散,recovery 过程也可以并发执行,另外 polardb 还会将元信息维护在统一的 superblock 中,减少读取次数。
除了 log 拆分之外,polardb 还引入了新的预取策略,降低请求延迟;针对 innodb 的锁使用进行优化,避免加锁 IO,降低锁冲突;针对不同写入路径上的 IO 任务,区分优先级和多队列,确保高优先级任务(比如写 WAL)能够优先执行;IO 请求进行对齐,等等。
Ganos: A Multidimensional, Dynamic, and Scene-Oriented Cloud-Native Spatial Database Engine
本文出自阿里巴巴,主要介绍了阿里巴巴出品的最新一代地理信息数据库引擎。在智慧城市、电子地图、卫星遥感、物联网、车联网 / 智能交通、互联网出行、智慧物流、传感网与实时 GIS 等众多领域都有较为广泛的应用场景。
Ganos 设计、实现上高度兼容 PostGIS 语法和接口,可以无缝对接支持 PostGIS 的各类软件生态,架构上基于 PolarDB 实现主流的存储计算分离架构,实现计算 / 内存 / 存储组件解耦,形成可独立伸缩的资源池。
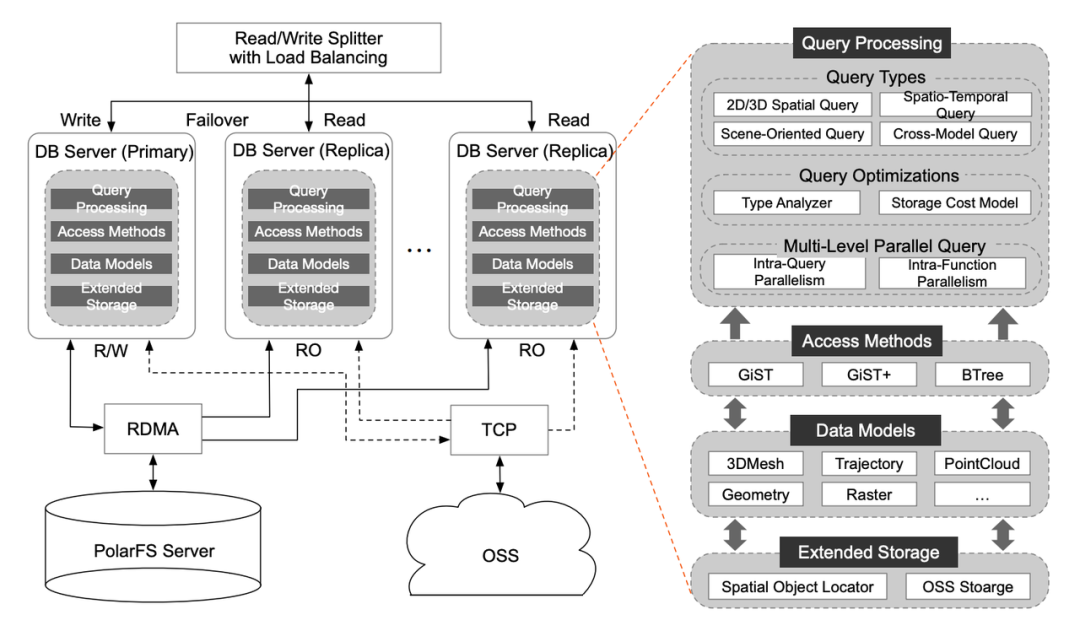
引入拓展存储 (Extended storage) 设计 :时空数据是很复杂的数据模型,相比于传统的关系型数据,数据结构更丰富、需要占用更多的存储资源,并且在使用过程中具有明显的冷热数据分离问题,为此 Ganos 采用了分布式共享存储 + 拓展存储(OSS Alibaba Cloud Object Storage Service)的方案,很好的平衡了存储成本、数据访问性能需求。

支持多级并行计算加速:跨节点并行 (IQP intra-query parallelism)+ 节点内并行 (IFP intra-function parallelism) 加速计算。其中 IQP 将一个 query 要处理的数据切分成数据片,分发给多个 RO 节点进行独立的计算;而 IFP 将超大的单个时空数据片切分成一个个的小时空单元,然后通过多线程并行计算达到计算加速效果。在 benchmark 测试中对比 PostgreSQL,Ganos 通过多级并行计算获得显著的加速。
Magma: A high data density storage engine used in Couchbase
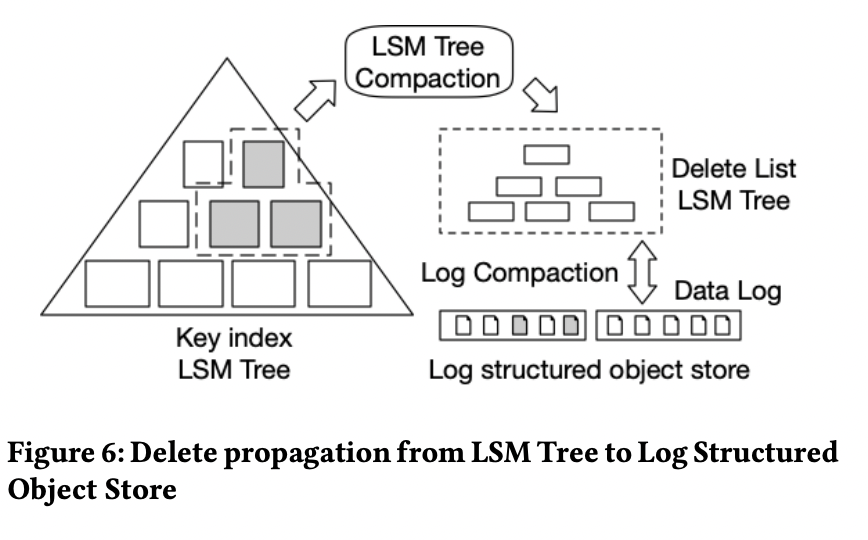
本文是 Couchbase 公司贡献,总结了 couchbase 作为文档数据库对于 KV 引擎的使用方式和痛点,并介绍了其下一代存储引擎 magma。magma 在设计上仍是基于 LSM Tree 结构的 KV 存储引擎,采用 KV 分离的设计,但做了很多有趣的创新设计,其中 key 存储在 key SST 中,value 维护在按照 sequence id 有序排列、切分为多个文件的 value log 中。
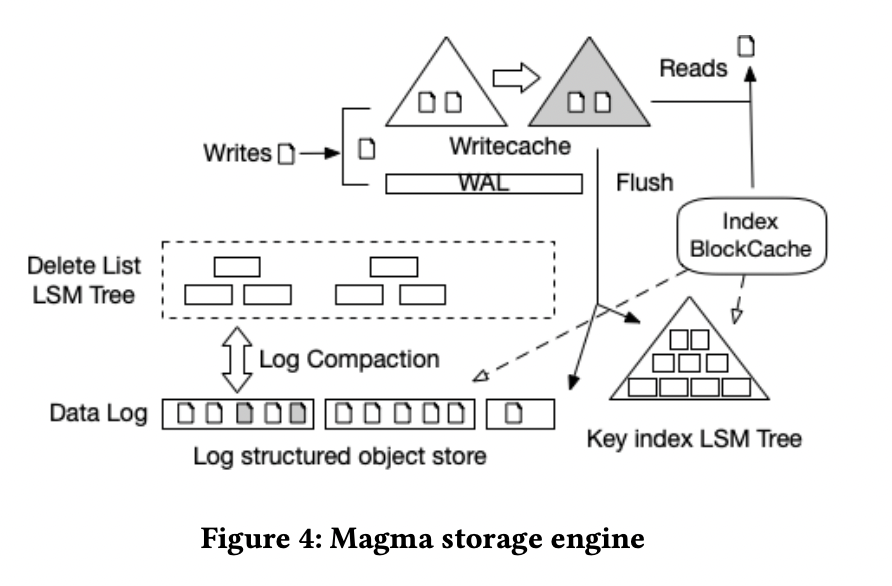
相比于经典的 WiscKey,这篇论文最大的贡献在于 GC 的设计,其不需要像 WiscKey 在 GC 时扫描整个 value log 并进行 point get 查询,而是首先对 key sst 进行 compact 产生 deleted key set,再根据 deleted key set 中记录的 value sequence id 计算得出每段 value log 对应的垃圾数据的比例,只需要对垃圾比例较高的 value log 段与邻接段进行 merge 即可。这样既可以避免 WiscKey GC 时的大量 point get,也可以根据垃圾比例对 value log 进行分段 compact,降低写入放大。
Manu: A Cloud Native Vector Database Management System
Manus(Milvus 2.0 版本产品代号)是 Zilliz 公司发布的一款 “面向向量数据管理而设计的云原生数据库系统”。向量数据管理系统是用于存储、检索向量数据的数据库系统。向量数据库广泛应用于现在 AI 各种系统中,例如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理等场景,使用深度学习的方法将这些非结构化数据映射成向量表示,然后在使用时就需要到巨大的向量集合中检索和某个向量距离(各种内积、欧氏距离等相似度计算方法)最近的 top-k 个向量。这类系统的开山鼻祖是 Facebook 开发的 Faiss,之后各大公司都研发自己的向量检索系统,而 Milvus 则是业界专业广受认可的开源向量检索系统。该系统的设计主要针对以下几方面痛点 :
灵活的一致性策略,系统提供可见性 / 时效性配置功能,用户可以根据业务的需求,来指定插入数据在可被查询到前所能容忍的最大时延,从而平衡系统执行开销和业务时效性;
支持组件级的弹性扩展能力,对于不同类型的任务,根据对不同组件运行开销的不同,针对性给系统瓶颈部分添加资源;
简单高效的事务处理模型,因为系统处理的是向量数据,不需要像关系数据库那样提供多表的复杂事务支持,可以对单表行上的事务做特定的性能优化。
系统的整体架构如下图所示,Manu 采用了一个四层的架构来实现对读 / 写、计算 / 存储以及有状态 / 无状态组件的分离:
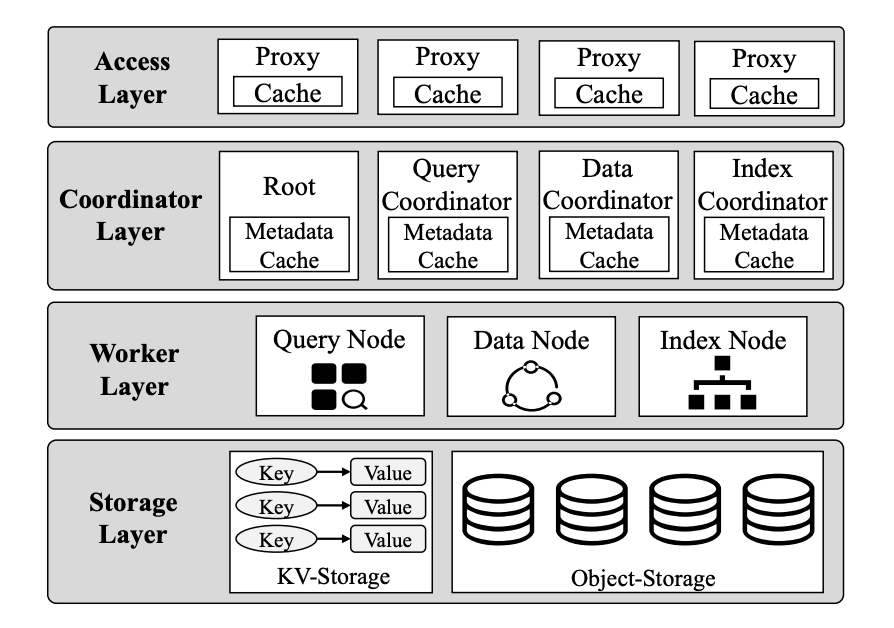
Access layer 是访问层, 由若干个无状态的 proxy 组成,这些 proxy 负责接收用户请求,将处理过的请求转发给系统内的相关组件进行处理,并将处理结果收集整理好之后返回给用户。
Coordinator layer 任务协调管理器,负责维护元数据以及协调各个功能组件完成各类系统任务。其中 Root Coordinator 负责处理数据集创建 / 删除等数据管理类型的请求;Data Coordinator 负责管理系统中数据的持久化工作,协调各个 data node 处理数据更新请求;Index Coordinator 负责管理系统中数据索引的相关工作,协调各个 index node 完成索引任务;Query Coordinator 负责管理各个 query node 的状态,并根据负载的变化调整数据和索引在各 query node 上的分配情况。上面各种 Coordinator 通常都有多个实例,从而提高组件的可靠性。
worker layer 负责执行系统中的各类任务。所有的 worker node 都被设计成无状态执行的的,它们读取数据的只读副本并进行相关的操作,并且 worker node 之间不需要通信协作,从而实现 worker node 的数量可以根据不同场景的负载差异进行调整,弹性增加必要的技术资源。
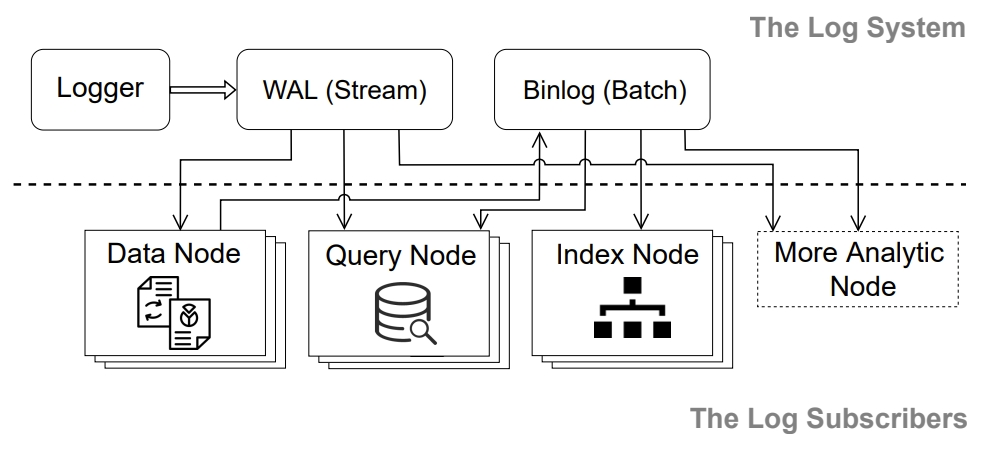
值得重点关注的是存储层 (Storage Layer) 设计,Manu 采用了“日志即数据(log as data)”的设计理念,将日志作为系统主干用来连接各个组件。基于对延迟、容量和成本等方面的考虑,Manu 实现了 WAL(write ahead log) 和 binlog 两类日志流,存量数据被被组织在 Binlog 当中,而增量部分则被组织在 WAL 中。Data node 消费 WAL 中的内容并对数据进行处理后产出到 Binlog 中,query node、index node 则仅需消费处理 Binlog 日志流中的数据。从而各个 worker node 实现互相独立的关系。
SQLite: Past, Present, and Future
SQLite 的大名在数据库领域可谓是如雷贯耳,本篇论文由 SQLite 的开发者和威斯康辛大麦迪逊分校联合出品,介绍了 SQLite 的 workload、近二十年中所处环境的变化以及未来的展望。在硬件方面,近年来硬件领域有了长足的进步,很难想象目前的低端移动设备(树莓派 4)在性能上也远超 SQLite 最早运行的设备(Palm Pilot);在 workload 上 SQLite 的用户存在大量不同比例的读写混合的场景,以及类 KV 的 blob point get 使用场景,近年来随着数据分析领域的发展,还存在一些 OLAP 的查询,这些都与 SQLite 最早设计时的假设有偏差。
文中花较大篇幅,对 SQLite 在 OLAP 方面的性能和优化进行了讨论,并与 DuckDB 进行了对比。在 OLAP benchmark 之后,作者对 SQLite 的执行情况进行了分析,提出了针对 equijoin 使用预购建 bloomfilter 对原有的 nested loop join 进行优化的方案,并进行了实现;除此之外,还提出了对提取记录中特定列的流程的优化,但是由于复杂度较高、涉及到兼容性问题,没有进行实践。
小编认为,文章的美中不足之处在于,所有 benchmark 都是针对 duckdb 进行对比,包括写入相关的测试和 blob 使用场景的测试,但是 duckdb 针对这两种场景并没有什么独特的设计,因此文中也没有针对这两种场景对 SQLite 进行优化。
Velox: Meta’s Unified Execution Engine
为了处理特定的,非常个性化的数据负载,业务经常需要临时开发新的专用计算引擎,但这实际上创建了一个又一个孤立的数据环境。通常,这些引擎之间几乎没有共享,难以维护、发展和优化,最终导致数据用户提供了体验不一致。为了解决这些问题,Meta 创建了 Velox,一个新颖的开源 C++ 数据库加速库。Velox 提供可重用、可扩展、高性能且与程序方言无关的数据处理组件,用于构建执行引擎和增强数据管理系统。该库依赖于矢量化执行和自适应性,并由 Meta 的工程师从头开始设计,以支持对复杂数据类型的高效计算,并适应无处不在的现代计算负载。Velox 目前已与 Meta 的十几个数据系统集成或正在集成,包括 Presto 和 Spark 等分析查询引擎、流处理平台、消息总线和数据仓库的数据摄取架构、用于特征工程和数据预处理的机器学习系统(PyTorch)等。它在以下方面提供了好处:(a) 通过泛用化以前仅适用于单个引擎中的优化来提高效率,(b) 为用户提高数据一致性,以及 © 通过提高可重用性来加强工程效率。
OceanBase: A 707 Million tpmC Distributed Relational Database System
OceanBase 是由蚂蚁金服自主研发的分布式关系数据库系统,已经设计开发了超过十年。OceanBase 是一个横向扩展的多租户系统,提供基于 shared-nothing 架构的跨地域高可用性。除了与其他分布式 DBMS 共享许多相似的目标,例如水平可扩展性、高可用性等,我们的设计还受到其他需求的驱动,例如对典型 RDBMS 的兼容性,以及同时适应客户内部和外部部署。OceanBase 实现了其设计目标。它实现了某些主流经典 RDBMS 的显著特性,这些 RDBMS 承载的大部分应用程序都可以在 OceanBase 上运行,只需稍加修改甚至不加改动。在支付宝等众多商业业务中已经部署了数万台 OceanBase 服务器。它还成功通过了 TPC-C 基准测试,并以超过 7.07 亿的 tpmC 夺得第一。本文介绍了 OceanBase 的目标、设计标准、基础设施和关键组件,包括其用于存储和事务处理的引擎。此外,它详细介绍了 OceanBase 是如何在一个分布式集群中达到上述领先的 TPC-C 基准测试的结果的,该集群拥有 1,500 多台服务器,分布在 3 个区域上。文章还描述了蚂蚁团队十多年来在构建 OceanBase 中所学到的经验教训,这对构建工业级的分布式数据库来说,有非常宝贵的学习和借鉴价值。
总结
在当前数据智能时代,数据存储计算技术已经成为社会信息化的核心引擎,VLDB 等顶会无疑是数据技术创新殿堂的明珠,持续汇集全世界的新方法新思路,指引和启迪学术界和工业界不断攀登突破。
服务全球用户的字节,既有数据创新技术的土壤也依赖技术赋能产品,从而更好的服务亿万用户。相信 VLDB 2022 收录的 Graph 和 HTAP 领域论文只是一个开始,未来字节会有更多技术创新突破通过各种形式为技术创新社会进步做出自己的贡献。同时,也非常欢迎大家加入我们( https://job.toutiao.com/s/6snYofd),一起在 NoSQL、数据库等相关领域解决世界级挑战,拓展未知技术边界。




