
1 问题由来
关于我们 Node 服务产生了什么问题,为什么会出现这些问题,以及为何需要采用 GraphQL 去解决这些问题,是一个值得探究的过程。下面,我将从服务架构入手,简单介绍一下项目背景,而后通过几个案例,让大家更形象的理解我们现在的问题是如何产生的。
1.1 服务架构简介
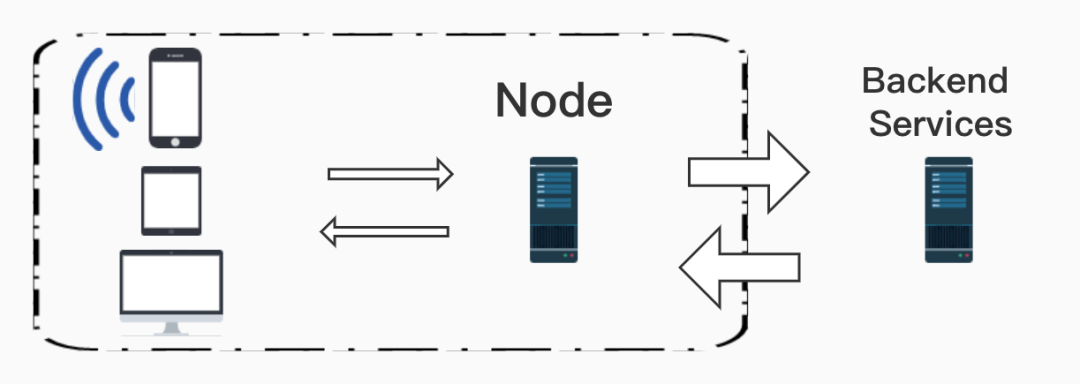
左边方框内属于我们前端团队的服务,右边属于后端服务。这里只是比较粗糙的架构,省略了一些负载均衡等细节,对于我司国内酒店服务来说,这里的图示就足以解释说明我们的问题。
而我们 Node 组,是处于承接上下游的一个位置,是属于直接服务于前端的后端,也就是所谓的 BFF 层,关于这个架构的形成过程,我后面会展开解释。
就目前而言,我们的主要职责是多端适配,UI 适配,版本控制,下发一些 AB 实验,日志收集等。
虽然我上面说了许多职能,但是我认为我们最核心的职能,其实就是负责给客户端同学输送数据,那么我们输送数据的过程中会产生什么问题?为什么会产生这些问题,下面让我来举例说明一下。
1.2 案例一:数据定制困难
我们都知道,我们的服务最早都是基于 PC 端而设计的,而随着时代的发展,移动端的各个终端变得越来越丰富,包括现在的 app、小程序、touch 等。所以如果不是拆分服务,我们注定要面临多端适配的一个演进过程。这其中一个典型例子,就是对于同一接口,不同端的需求可能是不同的。拿我们酒店系统举例:
对于酒店列表页展示:
在 PC 端和 APP 端我可以把一家酒店的很多信息都放到列表中展示,每一家酒店就会包含比较完整的酒店模型的字段,然而在一些情况下,比如小程序的这种场景下,可能我需要每家酒店只展示图片,报价,名称三个字段,客户端这种多变的需求是非常常见的,但是我们的接口都是同一个。
那么,我们 APP 端的代码大概会是这样的形式:
hotelInfo: { name: "酒店", price:232, imgUrl:"img.jpg", tags:[{ name:"亲子家庭" }], score:4.2, rank:"XX酒店排名第X名"}它将会把酒店模型下的所有字段直接返回给客户端。
而对于小程序端,我们就需要增加一个参数,判断请求来源是小程序,再去将模型中不显示的字段单独删除,才能达到这种字段级的控制。伪代码如下图:
if ( source === "XIAOCHENGXU" ) { hotelInfo.tags = undefined; hotelInfo.score = undefined; hotelInfo.rank = undefined;}假设现在我的小程序改版了,我新版本可能又想展示四个字段,老版本还是只展示三个,这时候我们就面临了版控问题。
作为服务端,我们有两个选择,不去管是新老版本的差异,冗余的返回四个字段,这样带来的好处就是开发简单,只增不减,没有风险。而另一种选择就是加一段这样的代码:
if ( source === "XIAOCHENGXU" ) { hotelInfo.tags = undefined; if( version <120 ){ hotelInfo.score = undefined; } hotelInfo.rank = undefined;}这样针对不同的版本,我们就可以保证返回不同的定制字段了,好处就是不会有冗余数据的传输。坏处也显而易见,让服务端代码的可读性逐渐下降,凌乱松散,可维护性也会越来越低。
假设我们上面这种需求,一周内出现 5-10 次,分配给不同的人开发,我们的字段改动有时就会非常频繁,而目前的接口文档还是靠 wiki 或 yapi 人工维护,这就使得我们很难保证这些同学都及时的更新接口文档,日积月累,服务与文档就产生了许多难以追踪的差异。
对于客户端的同学来说,因为这种文档与真实返回数据的不一致性,也直接导致客户端同学也许要不停的与服务端多次反复沟通,无形中增加了许多沟通成本,从而降低了整体的迭代效率,开发效率。
从服务端的角度讲,同一个接口,针对 restful 架构下,我们的解决方案通常就是根据客户端的诉求去增加判断,然后在服务端去过滤一遍数据,把不需要的字段删除,或把相同字段返回不同的值。然而由于我们每一个酒店的字段都非常多,要去做这样的开发显然对服务端增加了很多工作量,而且我这里只举了一个客户端的例子,而各种客户端如果每一个都有自己特殊的字段定制需求,我们在服务端就需要增加各种各样的判断,然后决定的也许只是一两个字段的返回情况,其本质操作其实都是大同小异,但却要让服务端同学的开发越来越困难和难以维护。
这种做法在 PC 时代,产品迭代相对频率较低的那个年代,是足够应付的,然而移动端到来后的时代,需求迭代频率明显升高,客户端种类也逐渐变多,各种各样的屏幕适配需求,字段的定制需求都不尽相同,加之每个客户端可能还涉及到很多的版本更迭。开发效率难免不下降,运维难度也增大,同时,由于历史更迭对字段的下线频率非常之低,现在线上也逐渐形成了许多冗余的字段。这些字段内容也因为版本更迭时对文档维护的不及时等历史原因,使得目前团队成员开发时也不敢轻易删除,总是自然而然的选择增加字段的保险做法,久而久之就形成了恶性循环,字段越来越多,可以说返回体中的冗余字段也给传输性能带来了一定负面的影响。
根据案例一总结的问题可以概况为:
数据定制困难
文档手动维护
冗余字段传输
1.3 案例二:多请求拼接
PC 上的酒店详情页:
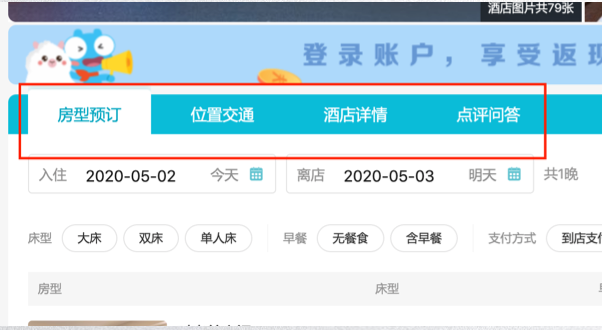
我们可以看到,PC 端酒店详情内,主要包括了房型、交通、详情、点评这四类资源,我们目前是通过两个接口拼接出来的。而在 APP 端,同样的酒店详情页,我们因为瀑布流的布局,可能除了以上内容,又多返回了周边推荐、住客秀两块资源。
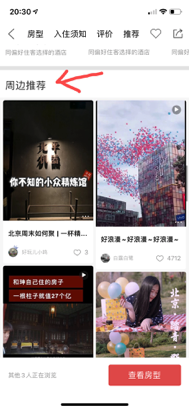
对于这种不同资源拼接在同一个页面的需求。基于 restful 的接口,我们通常有两种处理方式:
在客户端发多次请求
在服务端针对接口去做定制
第一种方式,我们可能会在原基础上,再增加两次请求,分别请求住客秀资源,以及周边推荐资源,再对数据进行处理。
// 方法1:/api/detail {交通,点评}/api/detailprice {房型,详情}/api/clientShow {住客秀}/api/recommendation {周边推荐}这种方式可以准确的请求到 APP 端想要的数据,各个接口职责明确,不用做修改,但是需要构造多次请求,使得客户端代码变得臃肿。
第二种方式,也就是根据不同的端,去变换我们某一接口的返回内容,在服务端去拼接不同资源,在 APP 的情况下,我们去拼接这两个资源,而这两个资源本身可能也是要在后端发两次请求而得来。
// 方法2:/api/detail {交通,点评}/api/detailpriceif( source === "APP" ){ return {房型,详情,住客秀,周边推荐}}return {房型,详情}这种方式的好处就是客户端减少了发请求的次数,但是它同时使得原本可以无关系的资源出现了强耦合,与 restful 设计时的初衷实际上相违背,在后续功能迭代和开发中,带来了隐患。比如我们如果修改了周边推荐里面的一些内容,也许他就会直接导致 detaiPrice 这个接口也需要有一个为了透传而产生的工作量。同时,这种做法也让 detailPrice 变得越来越臃肿复杂,提高了这个接口后续维护的困难。
1.4 问题归纳
那么,我们来总结一下以上案例中遇到的主要问题,并试图进行根本原因分析。我们在项目管理中,查找问题根本原因时有一些工具(比如鱼骨图、5why 分析、帕累托图)可以直观的帮助我们分析问题,如果感兴趣的同学可以去了解一下 PMP,ACP 的相关知识,这里我就不做展开。下面我就利用鱼骨图这个工具来分析一下我们这些问题的根本原因。
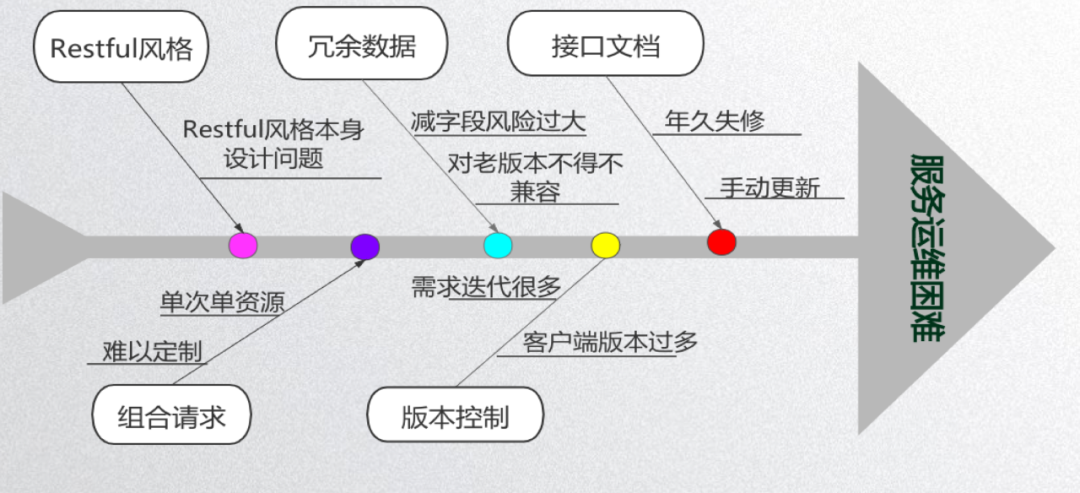
我们可以看到,我们右侧的鱼头部分,是我们面对的表面问题,而每一根鱼骨,反应了一个造成这个问题的主要原因,这些原因也许是不同纬度的原因。
比如我们项目目前运维困难,开发效率低下,性能下降的问题,它可能是由于接口文档方面,版控方面,多次请求设计方面,冗余数据方面这几个方面导致的,进而我们发现这些问题都是基于 restful 接口设计规范,在不停的需求迭代,众多的客户端页面变更中,逐渐产生且难以避免的问题,我们可以认为这是 restful 接口风格设计本身的问题,也就是说,导致这一系列问题的根本原因是需要找到更好的接口设计范式。
2 方案分析
2.1 GraphQL 简介
经过调研,我们发现,在 2012 年,facebook 就开始研究了一个叫 GraphQL 的技术解决方案,去解决服务端喂食给移动端数据的效率问题。他们的项目产生背景其实和我们所面临的过程十分类似,也就是始于 PC 端的服务,在移动端盛行后愈加丰富的需求变化下,传统 restful 设计效率下降后,他们想去解决这个效率问题,所以做出了这个方案。区别在于,facebook 很早就直接研发了这套标准,并且经过多年的实践,他们已经将这种模式锤炼的十分成熟了。而我们作为学习者,还是需要一个思想上的转变过程的。
那么怎么理解 GraphQL 呢?
字面介绍:GraphQL 是一种 API 查询语言,也是一种用于实现数据查询的运行时,或者说它只是一种规范。它通常基于 Http 协议。
光看定义,可能还是很抽象,GraphQL 到底是什么呢?它怎么集成在我们这个已经有些不堪重负的系统中呢?他是如何改变我们的开发模式呢?
2.2 Restful 到 GraphQL
通过我们上一章节的分析,我们已经看的 restful API 的设计风格在长周期,高速迭代的需求变化下逐渐显现出来的,一些难以避免的问题。下面我们就来看看这些问题在 GraphQL 下会如何呢?
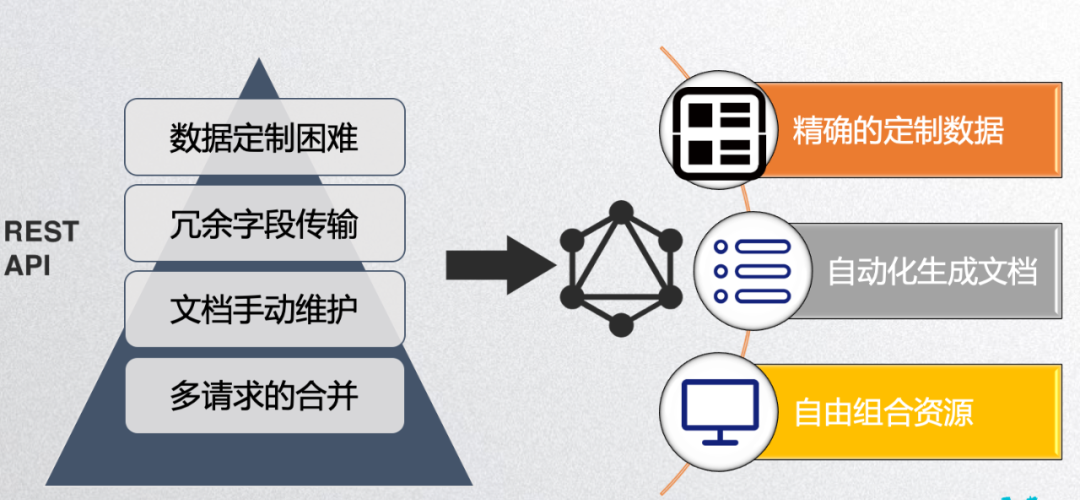
我们从官方文档上所看到的,GraphQL 具有:
精确的数据定制能力 ,也就是说客户端可以决定想要获取的数据,不多不少,精确定制。对应我们左边的第一二个问题,似乎迎刃而解。
自动化的文档生成能力 ,这点可以大大减少我们开发人员浪费在文档维护上的时间,解放精力,专注于业务开发上。
自由组合的资源能力 ,这点的意思就是,比如对于 restful 我们每一个 endpoint 都对应着一个资源,然而 GraphQL 下就只有一个 endpoint,我们想要查询什么,我们就直接自由组合不同的资源拼凑在一个请求里,同一个页面就不存在案例二中因资源组合而产生的请求合并设计困扰,避免了多次请求的问题。
2.3 GraphQL 的实施
下面,我们就来谈谈这个 GraphQL 的规范,是如何在我们现有系统中去落地并解决问题的。
第一步,就是定义 schema。
那么为了简化问题,还是以酒店系统的酒店模型为例,下图是酒店信息的对象,而我们定义 schema 所使用的 SDL 语言非常简单,作为强类型语言,它的写法与 TS 非常相像,所以说几乎没有学习成本。
hotelInfo:{ name: "xx酒店", price:232, imgUrl:"img.jpg", tags:[{"name":"亲子家庭"}], score:4.2, rank:"XX酒店排名第X名"}下图是将这种模型,抽象成 GraphQL 中 SDL 后的写法:
type Hotel { name: String! imgUrl: String! price: Int! tags: [Tag] score: Float rank: String} type Tag { name: String!}可以看到,定义 schema 的过程,就是一个视图模型整合过程。
第二步,编写 resolver 解析器。
这一步其实很好理解,当我们在服务端定义好了服务于业务的视图模型的全部字段以及类型后,我们自然而然的需要编写如何获得这些数据的方法。这一步其实对于已经存在的服务来说非常简单,你只需要在 resolver 中指明你定义的这个模型中的数据是从什么地方获取到的就可以了,而这些数据的获取方式,可以是异步函数,同步函数计算所得,读缓存得来,读数据库得来,调用三方 API 得来。可以说 GraphQL 这里就是做了一个聚合的工作,把更上游的数据,也许是微服务或是 restful 服务,在 GraphQL 层聚合起来。一个 reslover 的伪代码:
hoteReslober:( id: String ) => { return db.getHotel(id);}第三步,改造客户端的请求方式。
对于客户端也就是调用方来说,我们最大的变化,就是需要我们不再只是被动的处理某个接口返回的数据了,不会再面对 over-fetch 和 under-fetch 的问题。我们只需要描述清楚,我们在这个页面想要的那些内容,然后专注于数据处理,视图构造就可以了。
下图是 APP 端的一个 query 例子:
query: hotel (id: String ) => { name imgUrl price tags{ name } score rank}2.4 GraphQL 的实践改造过程
若要充分解释清楚我们项目的演进过程,我想在此还需要回顾一下历史架构演变过程。

我们可以看到,最开始的时候,我们的服务由客户端直接调用一个 Java 服务,那个时候的客户端还是 PC 为主,后来随着时代的发展,客户端的种类变多了,Java 这层就要负责许多业务以外的视图层的需求改动。由于这层服务本身也有一些业务层面的处理,它干的工作就越来越多,越来越杂,在一段时间里,这个服务常常成为影响开发进度的瓶颈,积压的需求也就越来越多。而为了赶工期,又要做到各种兼容,就更容易开发出一些 bug,产生一些失误,有些不堪重负。于是,随着时间的推移,大前端组决定迁移走这个 Service 中一部分视图层相关的工作,而 Node 组本身都是由原前端同学组成,所以自然而然的选择了 Node.JS,作为中间层服务技术方案。

服务其实已经存在了我第一章所提到的种种问题,虽然我们想通过 GraphQL 去改善,但是在我们同时面临迁移大量代码,不停兼顾新功能的上线,重构成 GraphQL 服务这三项挑战的时候,我们不可能一蹴而就。于是,为了不影响外部业务,又能够应用上这个技术,我们 Node 组先是进行了一个服务分层,将内部服务分成了两层。对外仍然是黑盒的 restful API,内部主要的负责视图层控制的大量逻辑,都改造成了 GraphQL 的服务,由自己的上层服务直接调用。

由于我们改造的工期较长,在这一步实现的过程中,我们小程序组也同步增加了一层自己的 GraphQL 服务,这层服务再转发调用我们 Node 服务的接口,小程序内部就已经在我们改造的同时,也完成了逐步的改造,并上线使用了 GraphQL 一段时间了。我们可以看到,GraphQL 其本身其实是很薄的一层架构,它的一般处理耗时在 20ms 以内,实际上如果你是 restful 的微服务架构,它主要充当的就是 gateway 的数据聚合层。对于已经成熟的业务,是可以平滑的进行逐步升级的。架构层面去应用它也是十分灵活的。不用拘泥于直接把服务一次性全面改造到位。

然后我们服务端将会进一步直接提供对外的 GraphQL 服务,届时,客户端也可以同步开展改造调用方式的开发。
下面是小程序利用 GraphQL 服务,对于同一接口调用,所节省的流量对比。我们可以看到,对于这种不同页面,同一资源的定制,如果利用得当,可以大幅减少我们的冗余数据,减小返回体带来的传输速度提升也是十分明显。

而对于开发流程。
传统流程下,我们是这样的。
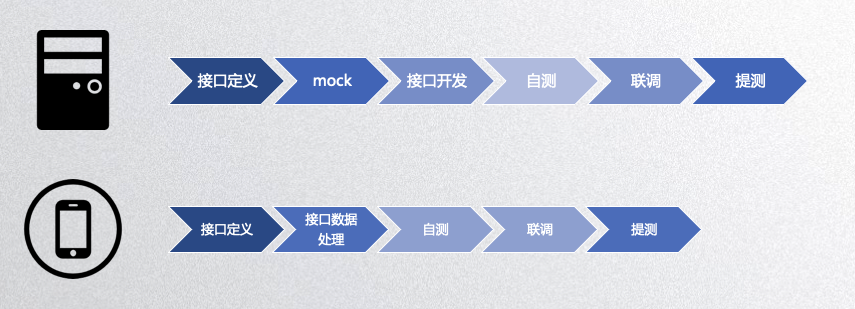
前后端同学要先定义接口,然后 mock 数据,分头开发,自测,然后再联调,自测,提测。期间联调可能要为了开发环境,版本约定,参数改变,接口文档返回不一致等问题进行数次沟通,浪费许多时间在开发以外。
而 GraphQL 下呢?

在 schema 里定义好了属性名和类型后,那么我们服务端同学就可以直接专注领域服务的开发了,开发完了可以直接升级,做到与前端基本解耦。
前端同学直接可以使用这个服务,不需要再和后端同学约定版本号让作为后端判断参数了,只需要查看最新的文档,编写好新的 query,就可以开始自测了。
两边同学都极大的缩减了中间无谓的联调,约定参数的沟通时间。
2.5 在实践中看到的一些问题
虽然 GraphqQL 具有以上诸多优点,但是我们都知道没有万能的银弹,下面我们来看看 GraphQL 开发中常见的问题。
增大了后端系统设计难度
传统的 restful API 在系统设计师更加简洁清晰,各个 endpoint 的职责会十分明确,减少了各个模块的互相依赖和干扰,所以在 GraphQL 的系统设计中,需要特别注意模块之间的耦合问题,不能把各个模块都搅合在一起,这对设计上提高了一定的难度。作为已经存在的系统,你可以在迁移时候按照纯 restful 风格去设计各视图模型的关系,让 GraphQL 继承 restful 的优势。
是否会带来后端性能问题
性能问题是后端最关注和担心的一个问题,会不会产生额外的数据库查询?如何优化查询性能?这些都给我们提出了优化和设计上的挑战。如果你是像我们一样的 Node 中间层,就不会面临这种问题,把数据库本身的优化仍然交给更后端的服务去做,避免 sql 的穿透。
迁移成本
对于已经存在的大型系统,如何完成迁移,是否需要改变语言?是否需要改变框架?如何平滑的实现迁移?这都是我们面临的直接成本,如何以最小的成本,最低的风险去实现改造,是我们需要着重思考的问题。
安全问题
由于客户端有很自由的查询方式,所以服务端不再是直接控制返回字段,而是需要限制请求方的一些例如查询深度,查询页数限制等。关于安全由于与 restful 方式略有不同,设计更安全合理的请求方案,也是一个值得思考的问题,我们目前采用的方案这里就暂不展开了。
所以总的来说,并不是我们就一定要用 GraphQL 完全替代 restful API,通常很多情况下都可以采用 GraphQL 调用 restful API 的改造方式。
3. 于公司的实用价值
我们大前端应用 GraphQL,其意义不仅仅是去解决我们前端团队的效率问题,我们希望这次尝试应该具有更深远的影响。
改造的应用场景
首先,这次经验告诉我们,GraphQL 适用的场景。
我们认为它不是 restful 的替代品,而是在我们目前这种,服务端提供视图层的服务,也就是 BFF 层,需要进行多端适配的架构下,我们去应用 GraphQL,才能发挥它更多的价值。
而且对于已经存在的大型系统,我们不能盲目的大刀阔斧的直接重构,可以灵活的应用架构上面的微调,去逐步实现我们最终应用 GraphQL 的改造,以达到用最低风险,最小成本去完成改造。
对于内部许多本身就是 restful 的服务,我们并不一定要去改造它,完全可以在外层用 GraphQL 服务去调用 restful 服务,保持 restful 服务开发在后端的优点。
拥抱变化的勇气
我们虽然有很多服务都是公司内部多年积累下来的遗产,有的仍然很好用,但有的服务其实技术层面和业务层面上已经比较老旧了,会带来很多难以避免的遗留问题。
而我认为公司系统是一个有机体,每个系统内部需要不断地自己更新重构,这个过程不仅仅提升各内部系统的性能,而可以通过各个环节效率的提升达到 1+1>2 的效果,从而让公司整体机能达到质变。
所以对于这种已经经过实践检验的技术方案,我个人是非常推崇的,如果我们有新的系统,符合我所说的需要经常性变更页面需求,且拥有一个 BFF 层去聚合处理数据,那么,请放心大胆的拥抱变化,选择 GraphQL 吧。
作者介绍:
孟晨,2019 年 11 月加入 Qunar,前端工程师,负责国内酒店服务前端应用 Node 服务的工程化、标准化推进。在技术应用方面,认为能解决落地业务场景的技术就是好技术,脱离业务场景谈技术是没意义的。
本文转载自公众号 Qunar 技术沙龙(ID:QunarTL)。
原文链接:




